Funkce TRIM serveru SQL Server je navržena tak, aby odstranila úvodní a koncové mezery ze znakového řetězce. Úvodní mezera je mezera, která se vyskytuje před skutečným řetězcem. Po se objeví mezera na konci.
V tomto článku se podíváme na funkci TRIM a ilustrujeme její použití na praktických příkladech. Začněme tedy od základů.
Funkce TRIM v SQL Server
SQL TRIM je vestavěná funkce, která nám umožňuje oříznout nepotřebné znaky na obou stranách řetězce jednou akcí. Nejčastěji jej používáme k odstranění mezer. Tato funkce se objevila v SQL Server 2017 a nyní je přítomná také v Azure SQL Database.
Syntaxe funkce SQL TRIM je následující:
TRIM ( [ znaků FROM ] řetězec )
- postavy FROM je volitelné parametr, který definuje, které znaky máme smazat. Ve výchozím nastavení se tento parametr vztahuje na mezery na obou stranách našeho řetězce.
- řetězec je povinné parametr, který určuje řetězec, kde se potřebujeme zbavit mezer/jiných nepotřebných znaků.
Vráceným výstupem je řetězec bez těch znaků, které jsme určili jako oříznuté na začátku a na konci. Viz příklad:
SELECT TRIM( ' example ') AS Result;Výstup je:
příklad
Jak jsme zmínili, funkce TRIM dokáže odstranit i další znaky. Podívejte se na příklad, kde chceme vyčistit řetězec od nepotřebných znaků a mezer:
SELECT TRIM( '.,# ' FROM '# ! example .') AS Result;Výstup je:
! příklad
Funkce SQL TRIM je k dispozici na SQL Serveru počínaje verzí 2017, ale úlohu bylo možné provést i před tímto vydáním. Uživatelé mohou použít SQL LTRIM a SQL RTRIM funkcí. Jsou přítomny ve všech podporovaných verzích SQL Server.
Funkce LTRIM v SQL Server
SQL LTRIM Funkce slouží k odstranění zbytečných mezer na levé straně řetězce. Syntaxe je následující:
LTRIM( řetězec )
řetězec je povinný parametr, který určuje cílový řetězec znaků, které potřebujeme oříznout na levé straně. Výstupem je kopie zadaného řetězce, ale bez mezer na začátku:
SELECT LTRIM(' SQL Function');Výstup:
‚Funkce SQL‘
Funkce RTRIM v SQL Server
SQL RTRIM funkce funguje stejně jako LTRIM – rozdíl je v tom, že odstraňuje mezery na pravé straně řetězce. Syntaxe je níže:
RTRIM(řetězec)
řetězec je povinný parametr, který ukazuje na řetězec znaků, kde potřebujeme odstranit koncové mezery.
SELECT RTRIM('SQL Server ');Výstup:
„SQL Server“
Současné použití LTRIM a RTRIM
Při práci s SQL Serverem často potřebujeme odstranit mezery pouze z jedné strany řetězce. Přesto existují případy, kdy potřebujeme vyčistit provázek na obou stranách. Funkce TRIM, kterou jsme popsali dříve, tomuto cíli slouží, ale jak si pamatujeme, je k dispozici pouze v SQL Server 2017 a vyšších.
Existuje způsob, jak odstranit počáteční i koncové mezery pro jeden řetězec bez funkce TRIM? Ano. Můžeme použít LTRIM a RTRIM společně v jednom dotazu.
Syntaxe je:
LTRIM(RTRIM(řetězec))
řetězec definuje cílový řetězec znaků, který chceme vyčistit od zbytečných mezer na obou stranách. Všimněte si také, že LTRIM a RTRIM můžeme umístit v libovolném pořadí .
SELECT LTRIM(RTRIM(' SQL Server '));Výstup:
„SQL Server“
Nyní, když jsme objasnili podstatu všech těchto funkcí SQL (TRIM, LTRIM a RTRIM), pojďme se ponořit hlouběji.
Proč na mezerách záleží
Někdo by se mohl zeptat, proč by mohlo být důležité takové prostory odstranit. Jednoduše řečeno, je to proto, že mohou být na obtíž, například při srovnávání hodnot. Bílé znaky samotné jsou považovány za součást řetězce, pokud tam jsou, takže je lepší se o takové problémy starat.
Pojďme si tyto funkce pořádně prozkoumat.
Nejprve vytvoříme jednoduchou tabulku pro typy databází provozované v našem podniku. Naše tabulka má tři sloupce. Prvním z nich je sloupec ID potřebný k jedinečné identifikaci každého řádku. Druhým je DBTypeNameA . Třetí je DBTypeNameB .
Poslední dva sloupce se liší typem dat. DBTypeNameA nejprve použije VARCHAR datový typ a DBTypeNameB používá CHAR datový typ.
Pro oba sloupce alokujeme délku dat 50.
- Listing 1: Create a Simple Table
USE DB2
GO
CREATE TABLE DBType (
ID INT IDENTITY(1,1)
,DBTypeNameA VARCHAR (50)
,DBTypeNameB CHAR (50))
GO
Všimněte si rozdílu mezi těmito datovými typy.
- Pro sloupec VARCHAR SQL Server nepřiděluje místo pro 50 znaků, které očekáváme ve sloupci ab initio. Říkáme, že sloupec by měl umožňovat maximum 50 znaků, ale přidělte prostor podle potřeby.
- U sloupce CHAR je toto ustanovení stanoveno na 50 znaků při každém vložení řádku, bez ohledu na to, zda skutečná hodnota potřebuje tento prostor nebo ne.
Použití VARCHAR (Variable Characters) je tedy způsob, jak ušetřit místo.
Po vytvoření tabulky naplníme stejnou pomocí kódu ve výpisu 2.
-- Listing 2: Populate the Table
USE DB2
GO
INSERT INTO DBType VALUES ('SQL Server','SQL Server');
INSERT INTO DBType VALUES (' SQL Server ',' SQL Server ');
INSERT INTO DBType VALUES (' SQL Server ',' SQL Server ');
INSERT INTO DBType VALUES ('Oracle','Oracle');
INSERT INTO DBType VALUES (' Oracle ',' Oracle ');
INSERT INTO DBType VALUES (' Oracle ',' Oracle ');
INSERT INTO DBType VALUES ('MySQL','MySQL');
INSERT INTO DBType VALUES (' MySQL ',' MySQL ');
INSERT INTO DBType VALUES (' MySQL ',' MySQL ');
Při naplňování naší tabulky jsme záměrně zadali hodnoty s mezerami na začátku a na konci. Použijeme je v naší ukázce.
Když se dotazujeme na tabulku (viz Výpis 3), můžeme vidět „zkreslení“ v datech vykreslených v SSMS (obrázek 1).
-- Listing 3: Query the Table
USE DB2
GO
SELECT * FROM DBType;
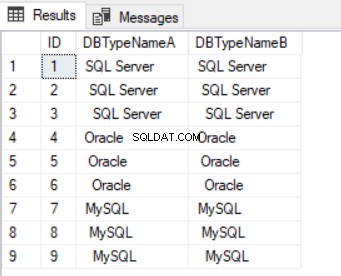
Toto zkreslení je viditelné, protože máme přední mezery. Koncové prostory jsou obtížněji vizualizovatelné tímto způsobem.
Dotaz je Výpis 4 poskytuje hlubší pohled na toto „zkreslení“. Představuje funkce LEN a DATALENGTH:
- LEN() vrací počet znaků v řetězci bez mezer na konci.
- DATALENGTH() vrací počet bajtů použitých k vyjádření výrazu.
-- Listing 4: Query the Table
USE DB2
GO
SELECT DBTypeNameA
, LEN(DBTypeNameA) LenVarcharCol
, DATALENGTH(DBTypeNameA) DataLenVarcharCol
, DBTypeNameB
, LEN(DBTypeNameB) LenCharCol
, DATALENGTH(DBTypeNameB) DataLenCharCol
FROM DBType;
Obrázek 2 ukazuje odchylky v délce výrazů jako „SQL Server“, „Oracle“ a „MySQL“ kvůli mezerám na začátku a na konci.
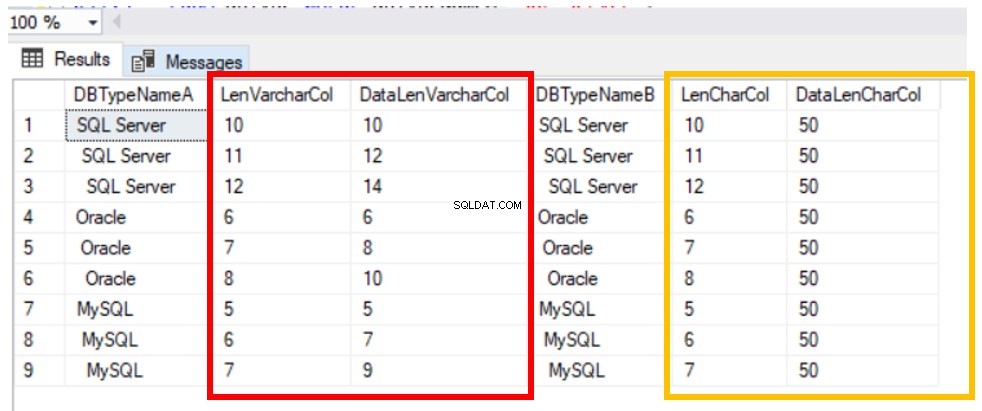
To znamená, že tyto výrazy nejsou stejné, pokud jde o dotazovací stroj SQL Server. Můžeme to jasně vidět spuštěním kódu ve výpisu 5.
-- Listing 5: Query for Specific
USE DB2
GO
SELECT * FROM DBType WHERE DBTypeNameA='SQL Server';
SELECT * FROM DBType WHERE DBTypeNameA='Oracle';
SELECT * FROM DBType WHERE DBTypeNameA='MySQL';
DataLenCharCol pole představuje výstup funkce DATALENGTH() ve sloupci CHAR. Proto jedním z důsledků tohoto rozdílu mezi „SQL Serverem“ a „SQL Serverem“ je výsledek dotazu zobrazený na obrázku 3.
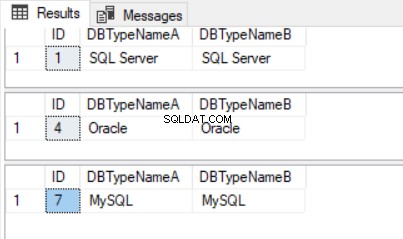
Vidíme, že i když máme tři řádky s každým typem databáze, naše dotazy vracejí pouze jeden z každého, protože počáteční a koncové mezery rozlišují hodnoty.
Řešení problému
Získání správných výsledků pro dotaz ve výpisu 5 je proveditelné a snadné. Potřebujeme funkci SQL Server TRIM(), jak je uvedeno ve výpisu 6.
-- Listing 6: Query for Specific
USE DB2
GO
SELECT * FROM DBType WHERE TRIM(DBTypeNameA)='SQL Server';
SELECT * FROM DBType WHERE TRIM(DBTypeNameA)='Oracle';
SELECT * FROM DBType WHERE TRIM(DBTypeNameA)='MySQL';
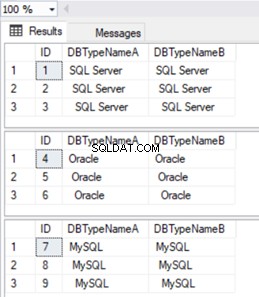
Bez této funkce TRIM() bychom mohli v některých scénářích získat špatné výsledky.
Můžeme to udělat dále načtením dat do samostatné tabulky, za předpokladu, že jsme chtěli problém vyřešit trvale (svým způsobem vyčištění dat).
-- Listing 7: Query for Specific
USE DB2
GO
SELECT ID, TRIM(DBTypeNameA) DBTypeNameA, TRIM(DBTypeNameB) DBTypeNameB FROM DBType;
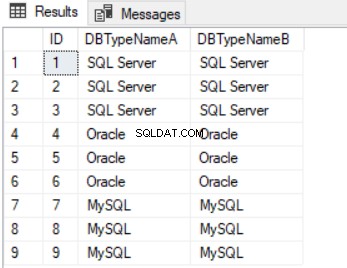
Porovnejte výsledky výpisu 7 (obrázek 5) s výsledky výpisu 3 (obrázek 1). Můžeme také vytvořit další tabulku s touto sadou výsledků, abychom data vyčistili (viz Výpis 8).
-- Listing 8: Create a New Table (Data Cleanup)
USE DB2
GO
SELECT ID, TRIM(DBTypeNameA) DBTypeNameA, TRIM(DBTypeNameB) DBTypeNameB INTO DBType_New FROM DBType;
SELECT * FROM DBType_New;
Tímto způsobem můžeme trvale vyřešit naše problémy a odstranit režii spouštění funkcí pokaždé, když potřebujeme extrahovat data z naší tabulky.
Závěr
Funkce SQL Server TRIM() lze použít k odstranění úvodních i koncových mezer z řetězců. LTRIM a RTRIM jsou dvě varianty této funkce, které se zaměřují na úvodní (LEFT) a koncové (RIGHT) mezery.
Můžeme použít TRIM() za běhu, abychom udělali pořádek v sadě výsledků a zajistili získání správné sady výsledků. Můžeme jej také použít k odstranění mezer a úhledně přesunout data z jedné tabulky do druhé.
Související články
Jak analyzovat řetězce jako profesionál pomocí funkce SQL SUBSTRING()?