Jako každý programovací jazyk má T-SQL svůj podíl běžných chyb a úskalí, z nichž některé způsobují nesprávné výsledky a jiné způsobují problémy s výkonem. V mnoha z těchto případů existují osvědčené postupy, které vám mohou pomoci vyhnout se problémům. Dotazoval jsem se na další Microsoft Data Platform MVP, kteří se ptali na chyby a úskalí, se kterými se často setkávají nebo které prostě považují za obzvláště zajímavé, a na osvědčené postupy, které používají, aby se jim vyhnuli. Mám spoustu zajímavých případů.
Mnohokrát děkujeme Erlandu Sommarskogovi, Aaronovi Bertrandovi, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Miloš Radivojevič, Simon Sabin, Adam Machanic, Thomas Grohser a Chan Ming Man za sdílení vašich znalostí a zkušeností!
Tento článek je prvním ze série na toto téma. Každý článek se zaměřuje na určité téma. Tento měsíc se zaměřím na chyby, úskalí a osvědčené postupy, které souvisejí s determinismem. Deterministický výpočet je takový, u kterého je zaručeno, že poskytne opakovatelné výsledky při stejných vstupech. Existuje mnoho chyb a úskalí, které vyplývají z použití nedeterministických výpočtů. V tomto článku se zabývám důsledky použití nedeterministického pořadí, nedeterministických funkcí, vícenásobných odkazů na tabulkové výrazy s nedeterministickými výpočty a použití výrazů CASE a funkce NULLIF s nedeterministickými výpočty.
V mnoha příkladech v této sérii používám ukázkovou databázi TSQLV5.
Nedeterministické pořadí
Jedním z běžných zdrojů chyb v T-SQL je použití nedeterministického pořadí. To znamená, že vaše objednávka podle seznamu neidentifikuje jednoznačně řádek. Může se jednat o objednávání prezentací, TOP/OFFSET-FETCH objednávání nebo objednávání oken.
Vezměte si například klasický scénář stránkování pomocí filtru OFFSET-FETCH. Musíte zadat dotaz na tabulku Sales.Orders a vrátit jednu stránku o 10 řádcích najednou, seřazených podle data objednávky, sestupně (nejnovější jako první). Pro jednoduchost použiji konstanty pro prvky offset a načtení, ale obvykle se jedná o výrazy založené na vstupních parametrech.
Následující dotaz (nazývejte ho Dotaz 1) vrátí první stránku 10 nejnovějších objednávek:
Plán pro Dotaz 1 je znázorněn na obrázku 1.
 Obrázek 1:Plán pro dotaz 1
Obrázek 1:Plán pro dotaz 1
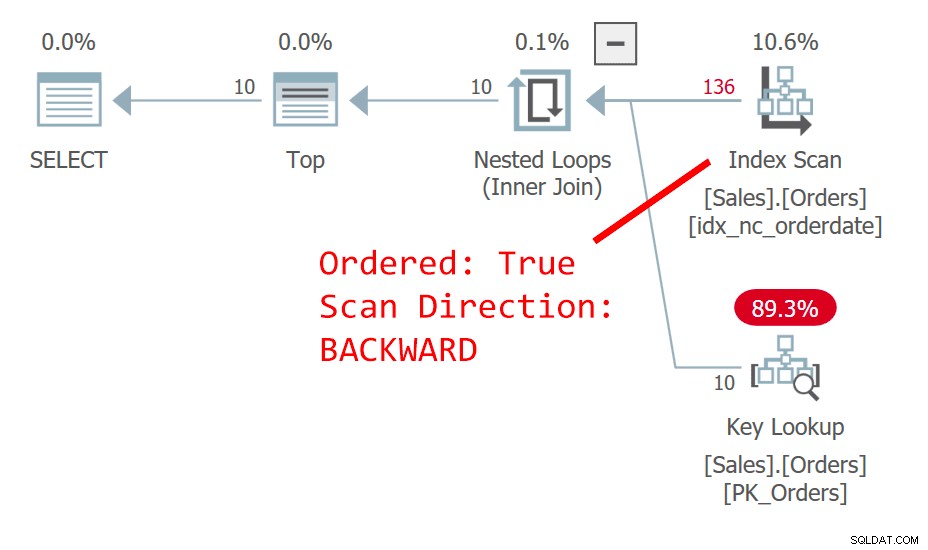
Dotaz seřadí řádky podle data objednávky sestupně. Sloupec datum objednávky jednoznačně neidentifikuje řádek. Toto nedeterministické pořadí znamená, že koncepčně neexistuje žádná preference mezi řádky se stejným datem. V případě remíz určuje, který řádek bude SQL Server preferovat, věci jako výběr plánu a fyzické rozvržení dat – ne něco, na co se můžete spolehnout jako na opakovatelné. Plán na obrázku 1 skenuje index k datu objednávky seřazený zpětně. Stává se, že tato tabulka má seskupený index na orderid a v seskupené tabulce je klíč seskupeného indexu použit jako lokátor řádků v indexech bez klastrů. Ve skutečnosti se implicitně umístí jako poslední klíčový prvek ve všech indexech bez klastrů, i když jej teoreticky mohl SQL Server umístit do indexu jako zahrnutý sloupec. Takže implicitně je index bez klastrů k datu objednávky ve skutečnosti definován dne (orderdate, orderid). V důsledku toho je v našem uspořádaném zpětném skenování indexu mezi svázanými řádky na základě data objednávky přístup k řádku s vyšší hodnotou orderid před řádkem s nižší hodnotou orderid. Tento dotaz generuje následující výstup:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 4019-05-05 20 11071 2019-2019-01 80 *** 11068 2019-05-04 62
Dále použijte následující dotaz (nazývejte ho Dotaz 2), abyste získali druhou stránku o 10 řádcích:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Plán pro Query je znázorněn na obrázku 2.
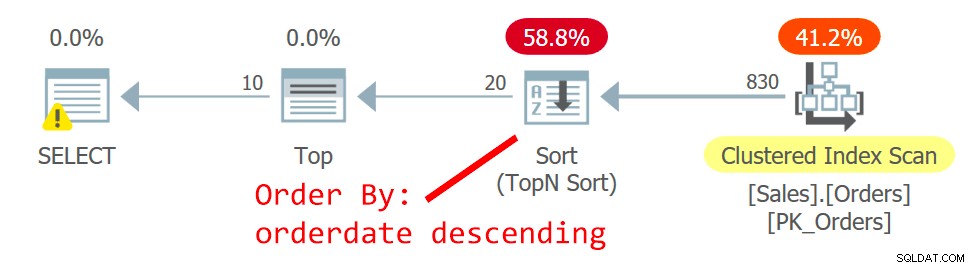
Obrázek 2:Plán pro dotaz 2
Optimalizátor zvolí jiný plán – jeden prohledá seskupený index neuspořádaným způsobem a použije TopN Sort k podpoře požadavku operátora Top na zpracování filtru offset-fetch. Důvodem změny je to, že plán na obrázku 1 používá neshlukovaný nezakrývající index a čím dále je stránka, po které se pohybujete, tím více vyhledávání je potřeba. S požadavkem na druhou stránku jste překročili bod zvratu, který opravňuje použití nepokrývajícího indexu.
Přestože skenování seskupeného indexu, který je definován s orderid jako klíčem, je neuspořádané, úložiště používá skenování pořadí indexu interně. To souvisí s velikostí indexu. Až do 64 stránek úložiště obecně upřednostňuje skenování pořadí podle indexu před skenováním s pořadím přidělení. I když byl index větší, pod úrovní izolace potvrzení pro čtení a daty, která nejsou označena jako pouze pro čtení, používá úložný modul skenování pořadí indexu, aby se zabránilo dvojímu čtení a přeskakování řádků v důsledku rozdělení stránek, ke kterým dochází během skenovat. Za daných podmínek v praxi mezi řádky se stejným datem tento plán přistupuje k řádku s nižším orderid před řádkem s vyšším orderid.
Tento dotaz generuje následující výstup:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -105-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11962 26 04-29 53 11058 2019-04-29 6
Všimněte si, že i když se základní data nezměnila, skončili jste se stejnou objednávkou (s ID objednávky 11069) vrácenou na první i druhé stránce!
Doufejme, že nejlepší postup je zde jasný. Přidejte nerozhodný výsledek do své objednávky podle seznamu, abyste získali deterministické pořadí. Například seřadit podle data objednávky sestupně, ID objednávky sestupně.
Zkuste znovu požádat o první stránku, tentokrát s deterministickým pořadím:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ŘÁDKŮ NAČÍST POUZE DALŠÍCH 10 ŘÁDKŮ;
Získáte následující zaručený výstup:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 4019-05-05 20 11071 2019-2019-01 80 11068 2019-05-04 62
Požádejte o druhou stránku:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
Získáte následující zaručený výstup:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-2019 67 11058 2019-04-29 6
Dokud nedošlo k žádným změnám v podkladových datech, máte zaručeno, že získáte po sobě jdoucí stránky bez opakování nebo přeskakování řádků mezi stránkami.
Podobným způsobem pomocí funkcí okna, jako je ROW_NUMBER s nedeterministickým pořadím, můžete získat různé výsledky pro stejný dotaz v závislosti na tvaru plánu a skutečném pořadí přístupu mezi vazbami. Zvažte následující dotaz (nazývejte ho Dotaz 3), který implementuje požadavek na první stránku pomocí čísel řádků (vynucuje použití indexu k datu objednávky pro ilustrační účely):
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER (ORDER BY orderdate DESC) AS n FROM Sales. Orders WITH (INDEX(idx_nc_orderdate)) ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 A 10;
Plán pro tento dotaz je znázorněn na obrázku 3:
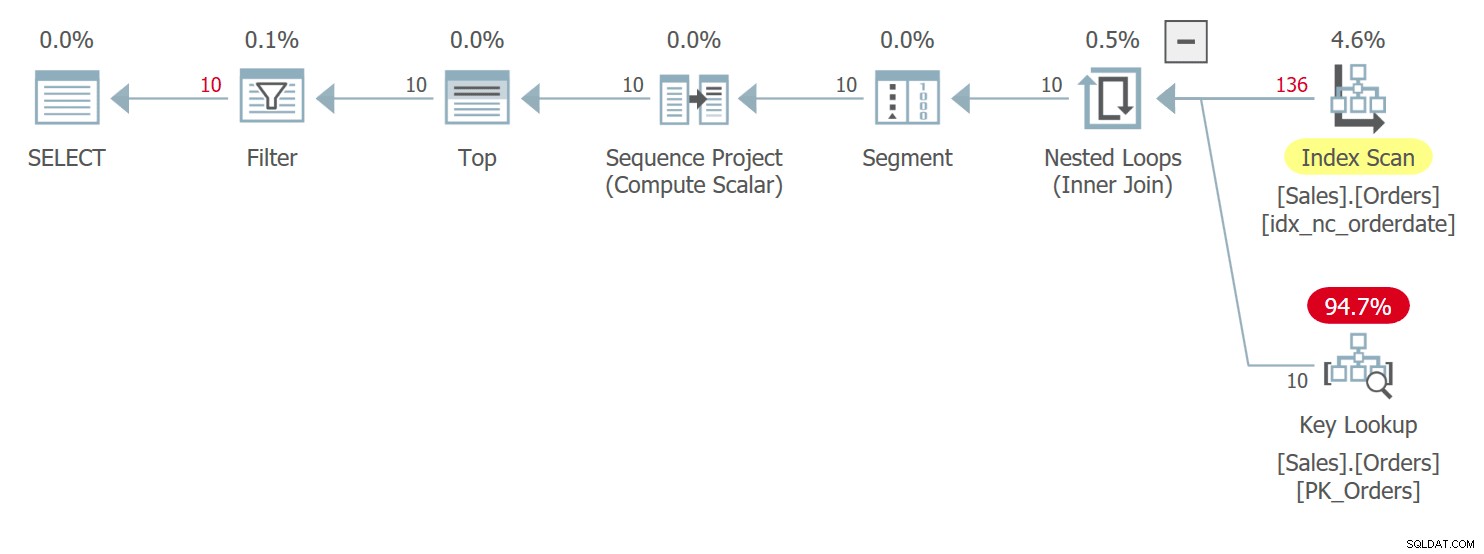
Obrázek 3:Plán pro dotaz 3
Máte zde velmi podobné podmínky jako ty, které jsem popsal dříve pro Dotaz 1 s jeho plánem, který byl znázorněn dříve na obrázku 1. Mezi řádky se shodnými hodnotami orderdate tento plán přistupuje k řádku s vyšší hodnotou orderid před řádkem s nižší hodnotou orderid hodnotu. Tento dotaz generuje následující výstup:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 4019-05-05 20 11071 2019-2019-01 80 *** 11068 2019-05-04 62
Dále spusťte dotaz znovu (nazývejte ho Dotaz 4) s požadavkem na první stránku, ale tentokrát vynucte použití seskupeného indexu PK_Orders:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders)) ) SELECT orderid, orderdate, custid FROM C WHERE n MEZI 1 A 10;
Plán pro tento dotaz je znázorněn na obrázku 4.

Obrázek 4:Plán pro dotaz 4
Tentokrát máte velmi podobné podmínky jako ty, které jsem popsal dříve pro Dotaz 2 s jeho plánem, který byl znázorněn dříve na obrázku 2. Mezi řádky se shodnými hodnotami orderdate tento plán přistupuje k řádku s nižší hodnotou orderid před řádkem s vyšší objednávková hodnota. Tento dotaz generuje následující výstup:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-2019-01 17 *** 11068 2019-05-04 62
Všimněte si, že tato dvě provedení přinesla odlišné výsledky, i když se v podkladových datech nic nezměnilo.
Opět platí, že nejlepší postup je zde jednoduchý – použijte deterministické pořadí přidáním nerozhodného výsledku, například takto:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n BETWEEN 1 AND 10;Tento dotaz generuje následující výstup:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 4019-05-05 20 11071 2019-2019-01 80 11068 2019-05-04 62Je zaručeno, že vrácená sada bude opakovatelná bez ohledu na tvar plánu.
Pravděpodobně stojí za zmínku, že protože tento dotaz nemá ve vnějším dotazu pořadí prezentace podle klauzule, neexistuje zde žádné zaručené pořadí prezentace. Pokud takovou záruku potřebujete, musíte přidat objednávku prezentace po doložce, například takto:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid OD C WHERE n MEZI 1 A 10 ORDER BY n;Nedeterministické funkce
Nedeterministická funkce je funkce, která má stejné vstupy a může vracet různé výsledky v různých provedeních funkce. Klasické příklady jsou SYSDATETIME, NEWID a RAND (při vyvolání bez vstupního zdroje). Chování nedeterministických funkcí v T-SQL může být pro některé překvapivé a v některých případech může vést k chybám a úskalím.
Mnoho lidí předpokládá, že když vyvoláte nedeterministickou funkci jako součást dotazu, funkce se vyhodnotí samostatně na řádek. V praxi je většina nedeterministických funkcí vyhodnocena jednou za odkaz v dotazu. Jako příklad zvažte následující dotaz:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;Protože v dotazu existuje pouze jeden odkaz na každou z nedeterministických funkcí SYSDATETIME a RAND, je každá z těchto funkcí vyhodnocena pouze jednou a její výsledek se opakuje ve všech řádcích výsledků. Při spuštění tohoto dotazu jsem dostal následující výstup:
orderid dt rnd ----------- --------------------------- ------ 2--------------- 11008 2019-02-04 17:03:07.9229177 0,962042872007464 11019 2019-02-04 17:03:0772922 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0,962042872007464 11059 2019-02-04 17:03:07.9229177 0,96204287200777464 11061777746204291777746204287777464 110617774664 110617774664 1106117774664 1106117774664 11061177746464228720074664 110617774646428720074664 11061177746464228720074664 11061177746464228720074664 110.Jako příklad, kdy nepochopení tohoto chování může vést k chybě, předpokládejme, že potřebujete napsat dotaz, který vrátí tři náhodné objednávky z tabulky Sales.Orders. Běžným počátečním pokusem je použít TOP dotaz s řazením na základě funkce RAND, přičemž se předpokládá, že funkce bude vyhodnocena samostatně na řádek, například takto:
VYBERTE TOP (3) orderid FROM Sales.Orders ORDER BY RAND();V praxi se funkce vyhodnotí pouze jednou za celý dotaz; všechny řádky proto získají stejný výsledek a řazení není zcela ovlivněno. Ve skutečnosti, pokud zkontrolujete plán pro tento dotaz, neuvidíte žádný operátor řazení. Když jsem tento dotaz spustil vícekrát, stále jsem dostával stejný výsledek:
orderid ----------- 11008 11019 11039Dotaz je ve skutečnosti ekvivalentní dotazu bez klauzule ORDER BY, kde není zaručeno pořadí prezentace. Technicky je tedy pořadí nedeterministické a teoreticky různá provedení mohou vést k odlišnému pořadí, a tedy k odlišnému výběru horních 3 řádků. Pravděpodobnost je však nízká a nemůžete si představit toto řešení jako vytvoření tří náhodných řádků v každém provedení.
Výjimkou z pravidla, že nedeterministická funkce je vyvolána jednou na odkaz v dotazu, je funkce NEWID, která vrací globálně jedinečný identifikátor (GUID). Při použití v dotazu tato funkce je vyvolán samostatně na řádek. To ukazuje následující dotaz:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;Tento dotaz vygeneroval následující výstup:
orderid mynewid ----------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...Samotná hodnota NEWID je zcela náhodná. Pokud nad něj použijete funkci KONTROLNÍ SOUČET, získáte celočíselný výsledek s ještě lepším náhodným rozdělením. Takže jeden způsob, jak získat tři náhodné objednávky, je použít TOP dotaz s řazením na základě CHECKSUM(NEWID()), například takto:
VYBERTE TOP (3) orderid FROM Sales.Orders ORDER BY CHEKSUM(NEWID());Spusťte tento dotaz opakovaně a všimněte si, že pokaždé získáte jinou sadu tří náhodných objednávek. V jednom provedení jsem získal následující výstup:
orderid ----------- 11031 10330 10962A následující výstup v jiném provedení:
orderid ----------- 10308 10885 10444Co když kromě NEWID potřebujete v dotazu použít nedeterministickou funkci, jako je SYSDATETIME, a potřebujete ji vyhodnotit samostatně na řádek? Jedním ze způsobů, jak toho dosáhnout, je použít uživatelem definovanou funkci (UDF), která vyvolá nedeterministickou funkci, například takto:
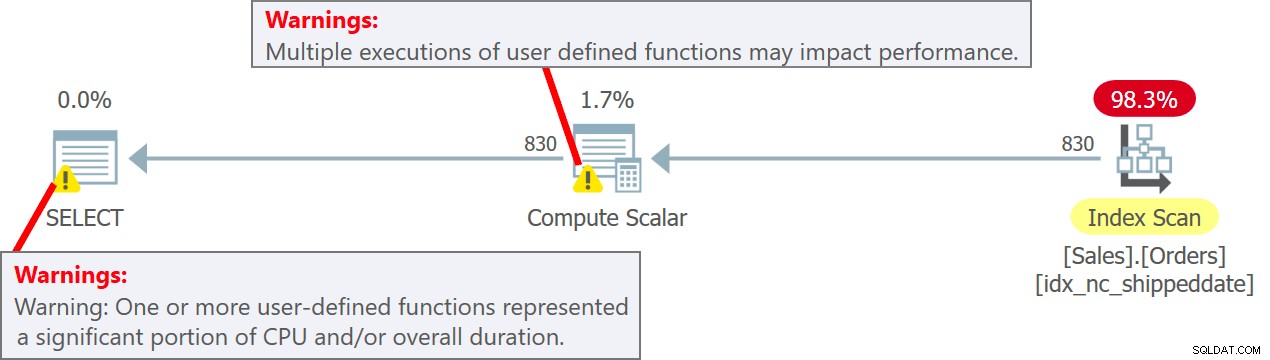
VYTVOŘIT NEBO ZMĚNIT FUNKCI dbo.MySysDateTime() VRACÍ DATETIME2 JAKO BEGIN RETURN SYSDATETIME(); KONEC; GOPotom vyvoláte UDF v dotazu takto (nazývejte to Dotaz 5):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;UDF se tentokrát provede na řádek. Musíte si však být vědomi toho, že s prováděním UDF na řádek je spojena docela ostrá penalizace výkonu. Kromě toho je vyvolání skalárního T-SQL UDF inhibitorem paralelismu.
Plán pro tento dotaz je znázorněn na obrázku 5.
Obrázek 5:Plán pro dotaz 5V plánu si všimněte, že UDF se skutečně vyvolá na zdrojový řádek v operátoru Compute Scalar. Všimněte si také, že SentryOne Plan Explorer vás varuje před potenciálním omezením výkonu spojeným s použitím UDF jak v operátoru Compute Scalar, tak v kořenovém uzlu plánu.
Při provádění tohoto dotazu jsem získal následující výstup:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251-2019-71:10251 202319-04 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03,7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:07:03.7241304. .Všimněte si, že výstupní řádky mají ve sloupci mydt několik různých hodnot data a času.
Možná jste slyšeli, že SQL Server 2019 řeší běžný problém s výkonem způsobený skalárními T-SQL UDF vložením takových funkcí. UDF však musí splňovat seznam požadavků, aby mohl být inlineabilní. Jedním z požadavků je, že UDF nevyvolá žádnou nedeterministickou vnitřní funkci, jako je SYSDATETIME. Důvodem tohoto požadavku je, že jste možná vytvořili UDF přesně proto, abyste získali provedení na řádek. Pokud by byl UDF vložen, základní nedeterministická funkce by byla provedena pouze jednou pro celý dotaz. Ve skutečnosti byl plán na obrázku 5 vygenerován v SQL Server 2019 a můžete jasně vidět, že UDF nebyl vložen. To je způsobeno použitím nedeterministické funkce SYSDATETIME. Můžete zkontrolovat, zda je UDF inlineable v SQL Server 2019 dotazem na atribut is_inlineable v zobrazení sys.sql_modules, například takto:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Tento kód vygeneruje následující výstup, který vám sdělí, že UDF MySysDateTime nelze vložit:
is_inlineable ------------- 0Abychom demonstrovali UDF, které je inlineable, zde je definice UDF nazvaná EndOfyear, která přijímá vstupní datum a vrací příslušné datum konce roku:
VYTVOŘIT NEBO ZMĚNIT FUNKCI dbo.EndOfYear(@dt JAKO DATUM) VRACÍ DATUM JAKO ZAČÁTEK VRÁCENÍ DATEADD(rok, DATEDIFF(rok, '18991231', @dt), '18991231'); KONEC; GONejsou zde žádné nedeterministické funkce a kód splňuje i další požadavky na vkládání. Můžete ověřit, že UDF je inlineable pomocí následujícího kódu:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Tento kód generuje následující výstup:
is_inlineable ------------- 1Následující dotaz (nazývaný Dotaz 6) používá UDF EndOfYear k filtrování objednávek, které byly zadány k datu konce roku:
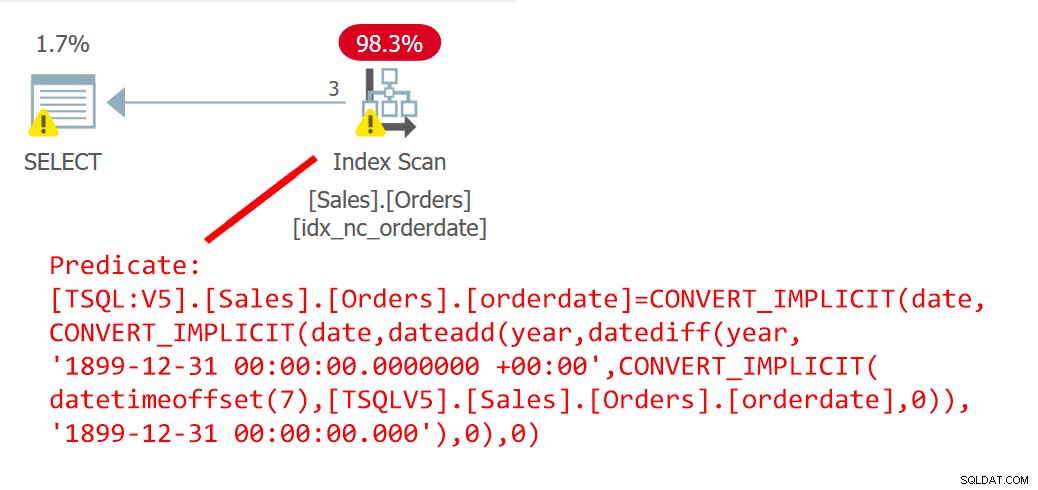
SELECT orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Plán pro tento dotaz je znázorněn na obrázku 6.
Obrázek 6:Plán pro dotaz 6Plán jasně ukazuje, že UDF se zařadila.
Tabulkové výrazy, nedeterminismus a vícenásobné odkazy
Jak již bylo zmíněno, nedeterministické funkce jako SYSDATETIME jsou vyvolány jednou na odkaz v dotazu. Ale co když na takovou funkci odkazujete jednou v dotazu v tabulkovém výrazu, jako je CTE, a pak máte vnější dotaz s více odkazy na CTE? Mnoho lidí si neuvědomuje, že každý odkaz na tabulkový výraz se rozšiřuje samostatně a vložený kód má za následek více odkazů na základní nedeterministickou funkci. S funkcí, jako je SYSDATETIME, v závislosti na přesném načasování každého z provedení, můžete skončit pro každý jiný výsledek. Někteří lidé považují toto chování za překvapivé.
To lze ilustrovat následujícím kódem:
DECLARE @i AS INT =1, @rc AS INT =NULL; KDYŽ 1 =1 ZAČÁTEK; WITH C1 AS ( SELECT SYSDATETIME() AS dt ), C2 AS ( SELECT dt FROM C1 UNION SELECT dt FROM C1 ) SELECT @rc =COUNT(*) FROM C2; IF @rc> 1 BREAK; SET @i +=1; KONEC; SELECT @rc AS odlišné hodnoty, @i AS iterace;Pokud by oba odkazy na C1 v dotazu v C2 představovaly totéž, výsledkem tohoto kódu by byla nekonečná smyčka. Protože se však tyto dva odkazy rozšiřují samostatně, když je načasování takové, že každé vyvolání probíhá v jiném 100 nanosekundovém intervalu (přesnost výsledné hodnoty), výsledkem spojení jsou dva řádky a kód by se měl oddělit od smyčka. Spusťte tento kód a přesvědčte se sami. Ve skutečnosti se po několika iteracích zlomí. V jedné z exekucí jsem získal následující výsledek:
iterace různých hodnot -------------- ----------- 2 448Nejlepším postupem je vyhnout se používání tabulkových výrazů, jako jsou CTE a zobrazení, když vnitřní dotaz používá nedeterministické výpočty a vnější dotaz odkazuje na tabulkový výraz vícekrát. To je samozřejmě, pokud nerozumíte důsledkům a nejste s nimi v pořádku. Alternativní možností může být uchování vnitřního výsledku dotazu, řekněme v dočasné tabulce, a následné dotazování na dočasnou tabulku, kolikrát potřebujete.
Chcete-li demonstrovat příklady, kdy vás nedodržení osvědčených postupů může dostat do problémů, předpokládejme, že potřebujete napsat dotaz, který náhodně spáruje zaměstnance z tabulky HR.Employees. Přijdete s následujícím dotazem (nazývejte ho dotaz 7), abyste úkol zvládli:
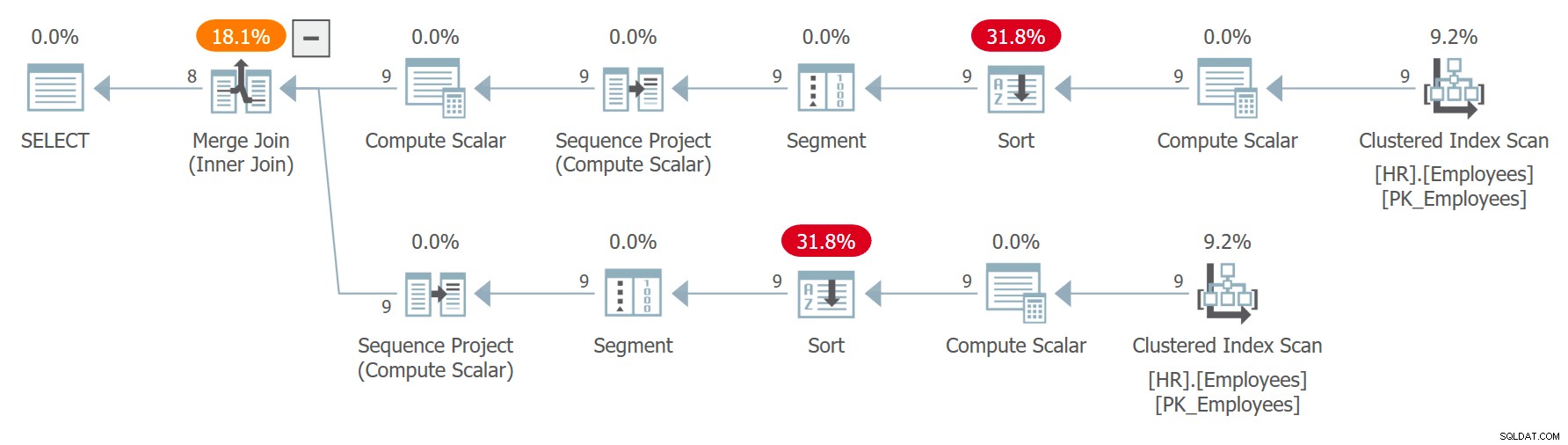
WITH C AS ( SELECT empid, jmeno, prijmeni, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. příjmení AS příjmení1, C2.empid AS empid2, C2.jméno AS jméno2, C2.příjmení AS příjmení2 OD C JAKO C1 VNITŘNÍ PŘIPOJENÍ C JAKO C2 ON C1.n =C2.n + 1;Plán pro tento dotaz je znázorněn na obrázku 7.
Obrázek 7:Plán pro dotaz 7Všimněte si, že dva odkazy na C jsou rozbaleny samostatně a čísla řádků se počítají nezávisle pro každý odkaz uspořádaný nezávislým vyvoláním výrazu CHECKSUM(NEWID()). To znamená, že u stejného zaměstnance není zaručeno, že ve dvou rozšířených referencích získá stejné číslo řádku. Pokud zaměstnanec dostane řádek číslo x v C1 a řádek číslo x – 1 v C2, dotaz ho spáruje s ním. Například v jedné z exekucí jsem získal následující výsledek:
empid1 jméno1 příjmení1 empid2 jméno2 příjmení2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Russell King ***Všimněte si, že zde existují tři případy samopárování. To je snazší vidět, když k vnějšímu dotazu přidáte filtr, který konkrétně hledá vlastní páry, například:
WITH C AS ( SELECT empid, jmeno, prijmeni, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. prijmeni JAKO prijmeni1, C2.empid JAKO empid2, C2.jméno JAKO jmeno2, C2.prijmeni JAKO prijmeni2 Z C JAKO C1 VNITŘNÍ PŘIPOJENÍ C JAKO C2 ZAP C1.n =C2.n + 1 KDE C1.empid =C2.empid;Možná budete muset tento dotaz spustit několikrát, abyste viděli problém. Zde je příklad výsledku, který jsem získal při jedné z poprav:
empid1 jméno1 příjmení1 empid2 jméno2 příjmení2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkPodle osvědčeného postupu je jedním ze způsobů, jak tento problém vyřešit, ponechat výsledek vnitřního dotazu v dočasné tabulce a poté podle potřeby dotazovat více instancí dočasné tabulky.
Další příklad ilustruje chyby, které mohou vyplývat z použití nedeterministického pořadí a více odkazů na tabulkový výraz. Předpokládejme, že se potřebujete dotazovat na tabulku Sales.Orders a chcete-li provést analýzu trendů, chcete spárovat každou objednávku s další na základě objednávky podle data objednávky. Vaše řešení musí být kompatibilní se systémy staršími než SQL Server 2012, což znamená, že nemůžete používat zřejmé funkce LAG/LEAD. Rozhodnete se použít CTE, který vypočítává čísla řádků k umístění řádků na základě pořadí podle data objednávky, a poté spojíte dvě instance CTE a spárujete objednávky na základě posunu 1 mezi čísly řádků, jako je tento (nazývejte tento dotaz 8):
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 OD C JAKO C1 LEVÝ VNĚJŠÍ SPOJ C JAKO C2 NA C1.n =C2.n + 1;Plán pro tento dotaz je znázorněn na obrázku 8.
Obrázek 8:Plán pro dotaz 8
Řazení podle čísla řádku není deterministické, protože datum objednávky není jedinečné. Všimněte si, že dva odkazy na CTE se rozšiřují samostatně. Je zajímavé, že protože dotaz hledá jinou podmnožinu sloupců z každé z instancí, optimalizátor se rozhodne použít v každém případě jiný index. V jednom případě používá uspořádané zpětné skenování indexu k datu objednávky, efektivně skenuje řádky se stejným datem na základě sestupného řazení podle orderid. V druhém případě prohledá seskupený index, seřadí false a pak seřadí, ale efektivně mezi řádky se stejným datem přistupuje k řádkům ve vzestupném pořadí orderid. Je to kvůli podobným úvahám, které jsem uvedl v části o nedeterministickém pořadí dříve. To může mít za následek, že stejný řádek získá číslo řádku x v jedné instanci a řádek číslo x – 1 v jiné instanci. V takovém případě spojení skončí spárováním objednávky se sebou samým namísto s další, jak by mělo.
Při provádění tohoto dotazu jsem získal následující výsledek:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- - ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 101076 9 101076 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 0019-05-05 46 11973 2011 05 *** ...Ve výsledku sledujte samoshody. Problém lze opět snáze identifikovat přidáním filtru, který hledá vlastní shody, například takto:
WITH C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 OD C JAKO C1 LEVÝ VNĚJŠÍ SPOJ C JAKO C2 ON C1.n =C2.n + 1 KDE C1.orderid =C2.orderid;Z tohoto dotazu jsem dostal následující výstup:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-046 2019-046 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...Zde je osvědčeným postupem zajistit, že použijete jedinečné pořadí pro zaručení determinismu přidáním rozhodovacího prvku, jako je orderid, do klauzule pořadí okna. Takže i když máte více odkazů na stejný CTE, čísla řádků budou v obou stejná. Pokud se chcete vyhnout opakování výpočtů, můžete také zvážit zachování vnitřního výsledku dotazu, ale pak musíte vzít v úvahu dodatečné náklady na takovou práci.
CASE/NULLIF a nedeterministické funkce
Když máte v dotazu více odkazů na nedeterministickou funkci, každý odkaz se vyhodnotí samostatně. Co by mohlo být překvapivé a dokonce vést k chybám, je to, že někdy napíšete jednu referenci, ale ta se implicitně převede na více referencí. Taková je situace u některých použití výrazu CASE a funkce IIF.
Zvažte následující příklad:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Sudy' WHEN 1 THEN 'Liché' KONEC;Zde je výsledkem testovaného výrazu nezáporná celočíselná hodnota, takže musí být buď sudá, nebo lichá. It cannot be neither even nor odd. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Závěr
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!