Ve svém posledním příspěvku jsem demonstroval, že při malých objemech může TVP s optimalizovanou pamětí poskytnout podstatné výhody z hlediska výkonu typických vzorců dotazů.
Pro testování v mírně větším měřítku jsem vytvořil kopii SalesOrderDetailEnlarged tabulku, kterou jsem díky tomuto skriptu Jonathana Kehayiase (blog | @SQLPoolBoy) rozšířil na zhruba 5 000 000 řádků).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Vytvořil jsem také tři in-memory verze této tabulky, každou s jiným počtem kbelíků (lovící „sweet spot“) – 16 384, 131 072 a 1 048 576. (Můžete použít kulatější čísla, ale stejně se zaokrouhlí nahoru na další mocninu 2.) Příklad:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Všimněte si, že jsem změnil velikost kbelíku oproti předchozímu příkladu (256). Při sestavování tabulky chcete vybrat „sweet spot“ pro velikost segmentu – chcete optimalizovat hash index pro vyhledávání bodů, což znamená, že chcete co nejvíce segmentů s co nejmenším počtem řádků v každém segmentu. Samozřejmě, pokud vytvoříte ~5 milionů bucketů (protože v tomto případě, možná ne příliš dobrý příklad, existuje ~5 milionů jedinečných kombinací hodnot), budete se muset vypořádat s určitými kompromisy ohledně využití paměti a garbage collection. Pokud se však pokusíte nacpat ~5 milionů jedinečných hodnot do 256 bucketů, budete mít také problémy. V každém případě tato diskuse přesahuje rozsah mých testů pro tento příspěvek.
Pro testování se standardní tabulkou jsem vytvořil podobné uložené procedury jako v předchozích testech:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Nejprve se tedy podíváme na plány řekněme 1000 řádků vložených do proměnných tabulky a poté spustíme procedury:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Tentokrát vidíme, že v obou případech optimalizátor zvolil hledání clusteru indexu proti základní tabulce a spojení vnořených smyček proti TVP. Některé metriky nákladů se liší, ale jinak jsou plány docela podobné:
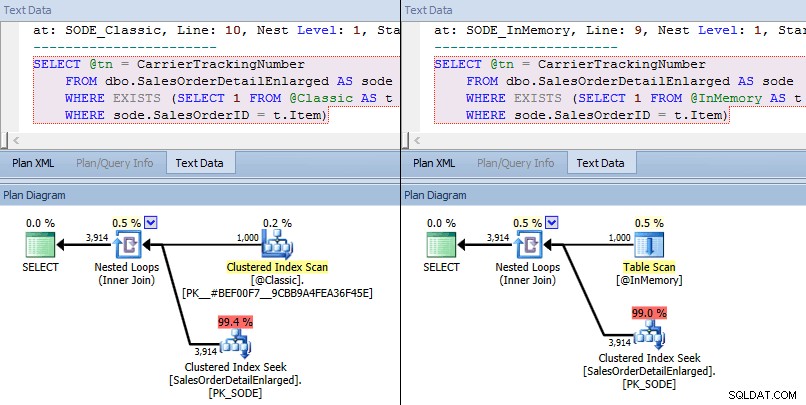 Podobné plány pro in-memory TVP vs. klasické TVP ve vyšším měřítku
Podobné plány pro in-memory TVP vs. klasické TVP ve vyšším měřítku
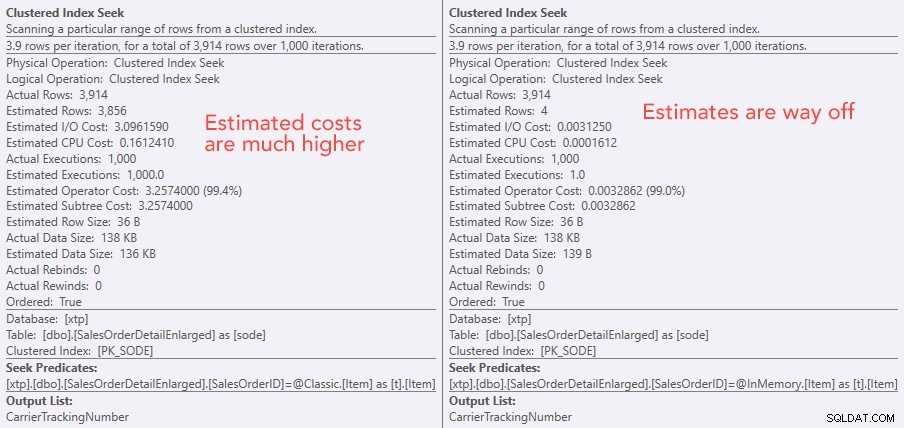 Porovnání nákladů operátora vyhledávání – vlevo klasický, vpravo In-Memory
Porovnání nákladů operátora vyhledávání – vlevo klasický, vpravo In-Memory
Z absolutní hodnoty nákladů se zdá, že klasický TVP by byl mnohem méně efektivní než In-Memory TVP. Ale zajímalo mě, jestli to bude v praxi pravda (zvláště proto, že údaj Odhadovaný počet exekucí napravo vypadal podezřele), takže jsem samozřejmě provedl nějaké testy. Rozhodl jsem se zkontrolovat hodnoty 100, 1 000 a 2 000, které mají být odeslány do procedury.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Výsledky výkonu ukazují, že při větším počtu vyhledávání bodů vede použití TVP v paměti k mírně klesajícím výnosům, které jsou pokaždé o něco pomalejší:
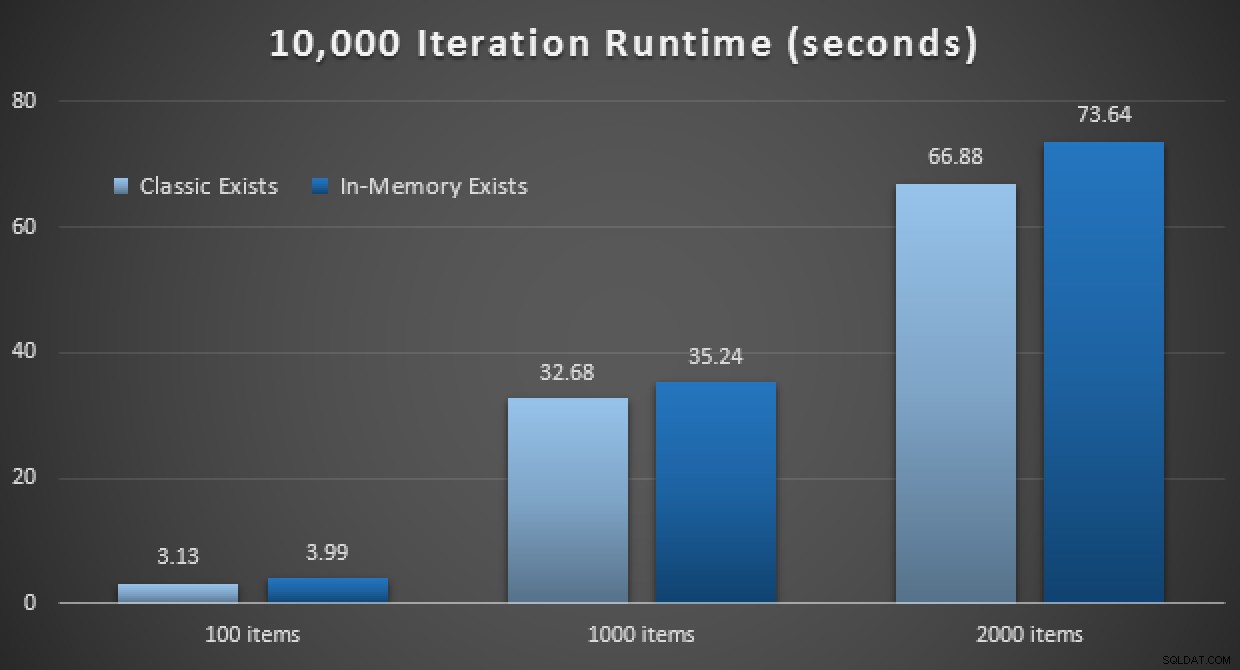
Výsledky 10 000 spuštění pomocí klasických a in-memory TVPs
Takže na rozdíl od dojmu, který jste si mohli vzít z mého předchozího příspěvku, použití in-memory TVP není nutně výhodné ve všech případech.
Dříve jsem se také podíval na nativně zkompilované uložené procedury a tabulky v paměti v kombinaci s in-memory TVP. Mohlo by to tady něco změnit? Spoiler:rozhodně ne. Vytvořil jsem tři procedury, jako je tento:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Další spoiler:Nebyl jsem schopen provést těchto 9 testů s počtem iterací 10 000 – trvalo to příliš dlouho. Místo toho jsem prošel a provedl každou proceduru 10krát, provedl jsem tuto sadu testů 10krát a vzal jsem průměr. Zde jsou výsledky:
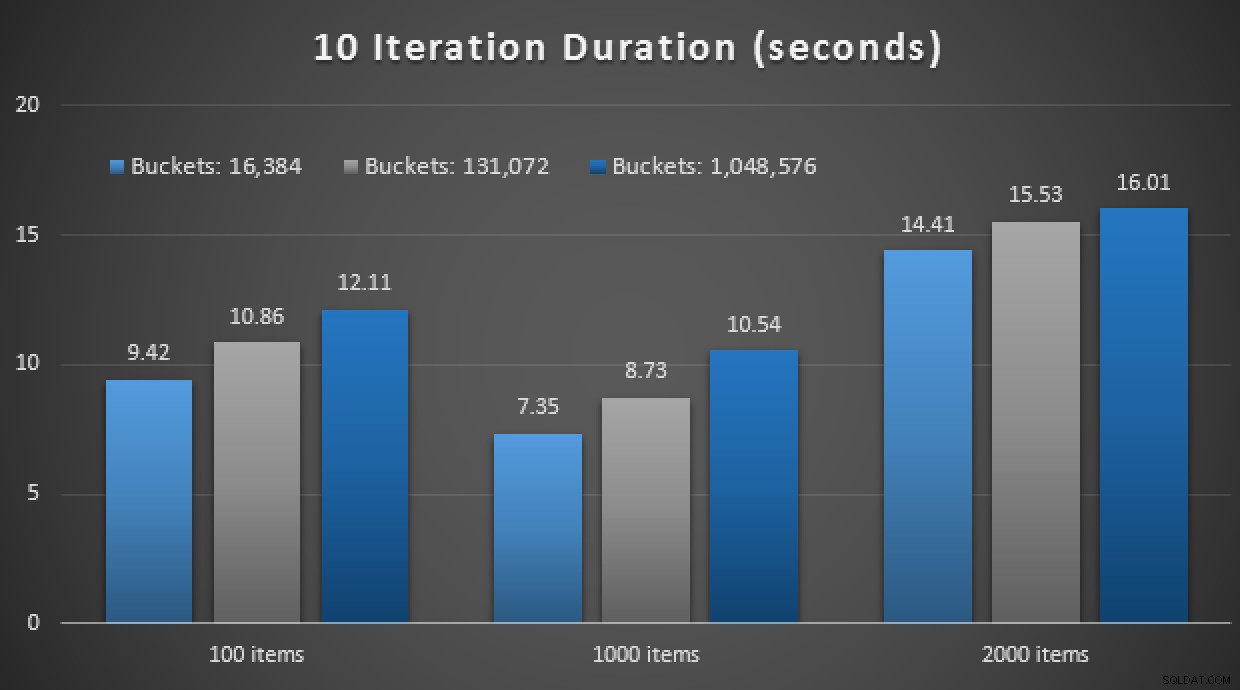
Výsledky 10 spuštění pomocí in-memory TVPs a nativně zkompilovaných uložených postupy
Celkově byl tento experiment spíše zklamáním. Jen při pohledu na pouhou velikost rozdílu s tabulkou na disku bylo volání průměrné uložené procedury dokončeno v průměru za 0,0036 sekundy. Když však vše používalo technologie v paměti, průměrné volání uložené procedury bylo 1,1662 sekundy. Au . Je vysoce pravděpodobné, že jsem si pro ukázku vybral špatný případ použití, ale v té době to vypadalo jako intuitivní „první pokus“.
Závěr
V tomto scénáři je ještě spousta věcí k testování a mám další blogové příspěvky, které musím sledovat. Ještě jsem neidentifikoval optimální případ použití pro in-memory TVP ve větším měřítku, ale doufám, že tento příspěvek slouží jako připomenutí, že i když se řešení zdá být v jednom případě optimální, nikdy není bezpečné předpokládat, že je stejně použitelné. na různé scénáře. Přesně tak by se mělo přistupovat k In-Memory OLTP:jako k řešení s úzkou sadou případů použití, které je bezpodmínečně nutné před implementací do výroby ověřit.