Mzdový datový model vám umožňuje snadno vypočítat mzdu vašich zaměstnanců. Jak tento model funguje?
Bez ohledu na to, zda provozujete malou nebo velkou společnost, potřebujete nějaké řešení mzdové agendy. Zde se hodí aplikace pro výplatu mezd. Navíc, čím větší společnost, tím těžší je zvládnout výpočty mezd zaměstnanců; zde se mzdová aplikace stává nutností. Abychom vám pomohli porozumět všem datům potřebným pro takovou aplikaci, provedeme vás souvisejícím datovým modelem.
Pojďme se podívat, jak funguje náš mzdový datový model!
Datový model
Při vytváření tohoto datového modelu jsem se snažil vytvořit model, který je obecně použitelný pro každé podnikání. Samozřejmě vždy budou existovat rozdíly v předpisech, firemních politikách atd., které budou vyžadovat přizpůsobení modelu tak, aby pokryl potřeby konkrétního mzdového účtu. Principy stanovené v tomto modelu by však měly být relevantní pro většinu organizací.
Je třeba poznamenat, že tento model byl vytvořen s několika předpoklady:
- Platy sjednané v pracovní smlouvě jsou za rok.
- Čisté mzdy (tj. s určitými částkami odečtenými na daních atd.) jsou vypláceny zaměstnancům.
- Platy jsou vypláceny měsíčně.
Datový model se skládá ze čtrnácti tabulek a je rozdělen do dvou tematických oblastí:
EmployeesSalaries
Pro lepší pochopení modelu je nutné důkladně projít každou tematickou oblast.
Zaměstnanci
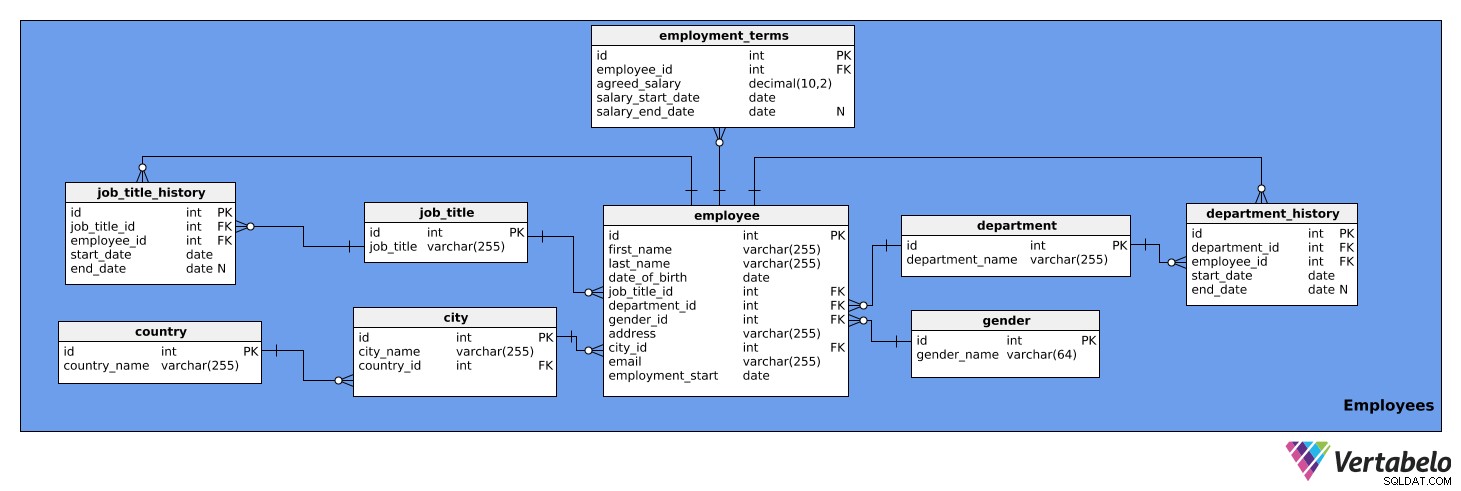
Tato tematická oblast obsahuje podrobné informace o zaměstnancích. Skládá se z devíti tabulek:
employeeemployment_termsjob_titlejob_title_historydepartmentdepartment_historycitycountrygender
První tabulka, na kterou se podíváme, je employee stůl. Obsahuje seznam všech zaměstnanců a jejich relevantní údaje. Atributy tabulky jsou:
id– Jedinečné ID pro každého zaměstnance.first_name– Křestní jméno zaměstnance.last_name– Příjmení zaměstnance.job_title_id– Odkazuje najob_titlestůl.department_id– Odkazuje nadepartmentstůl.gender_id– Odkazuje nagenderstůl.address– Adresa zaměstnance.city_id– Odkazuje nacitystůl.email– E-mail zaměstnance.employment_start– Datum zahájení zaměstnání této osoby.
Všimněte si, že sloupce job_title_id a department_id jsou nadbytečné, protože informace o aktuálních pracovních názvech a odděleních jsou dostupné z job_title_history a department_history tabulky. Pro rychlejší přístup k informacím však tyto dva sloupce v této tabulce ponecháme.
Níže jsou uvedeny employment_terms stůl. Uchovává údaje o platu každého zaměstnance, jak bylo dohodnuto v pracovní smlouvě, a o tom, jak se měnil v průběhu času. Atributy tabulky jsou:
id– Jedinečné ID pro každou sadu pracovních podmínek.employee_id– Odkazuje naemployeestůl.agreed_salary– Mzda uvedená v pracovní smlouvě.salary_start_date– Datum nástupu do sjednané mzdy.salary_end_date– Datum ukončení sjednané mzdy. To může být NULL, protože plat nemusí mít žádnou plánovanou změnu.
job_title tabulka je seznam pracovních pozic, které lze přiřadit různým zaměstnancům společnosti, např. analytik, řidič, sekretářka, ředitel atd. Tabulka má následující atributy:
id– Jedinečné ID pro každou pracovní pozici.job_title– Název pracovní pozice. Toto je alternativní klíč.
Potřebujeme také tabulku pro uložení historie pracovních pozic každého zaměstnance. Potřebujeme to, protože zaměstnanci mohou být v rámci společnosti povýšeni, degradováni nebo přeřazeni. job_title_history tabulka bude spravovat tyto informace a bude sestávat z následujících atributů:
id– Jedinečné ID pro záznam historie pracovní pozice.job_title_id– Odkazuje najob_titlestůl.employee_id– Odkazuje naemployeestůl.start_date– Datum, kdy zaměstnanec poprvé zastával dané pracovní zařazení.end_date– Když zaměstnanec přestal mít toto pracovní zařazení. Může mít hodnotu NULL, protože zaměstnanec může aktuálně zastávat tuto pracovní pozici.
Kombinace job_title_id , employee_id a start_date je alternativní klíč pro výše uvedenou tabulku. Zaměstnanec může mít k danému datu přiřazen pouze jeden pracovní název.
Další tabulka je department stůl. Toto jednoduše zobrazí seznam všech oddělení společnosti, jako je IT, Účetnictví, Právní atd. Obsahuje dva atributy:
id– Jedinečné ID pro každé oddělení.department_name– Název každého oddělení. Toto je alternativní klíč.
Zaměstnanci mohou také měnit oddělení v rámci společnosti. Proto potřebujeme mít department_history stůl. V této tabulce bude uloženo následující:
id– Jedinečné ID historické položky daného oddělení.department_id– Odkazuje nadepartmentstůl.employee_id– Odkazuje naemployeestůl.start_date– Datum, kdy zaměstnanec začal pracovat v oddělení.end_date- Datum, kdy zaměstnanec přestal pracovat v tomto oddělení. To může být NULL, protože tam zaměstnanec může stále pracovat.
Kombinace department_id , employee_id a start_date je alternativní klíč. Zaměstnanec může pracovat vždy pouze v jednom oddělení.
Další tabulka, o které budeme mluvit, je city stůl. Toto je seznam všech relevantních měst. Má následující atributy:
id– Jedinečné ID pro každé město.city_name– Název města.country_id– Odkazuje nacountrystůl.
country tabulka je další v našem modelu. Je to jednoduše seznam zemí a obsahuje následující informace:
id– Jedinečné ID pro každou zemi.country_name– Název země. Toto je alternativní klíč.
Poslední tabulka v této oblasti je gender stůl. Tato tabulka obsahuje seznam všech pohlaví. Obsahuje následující atributy:
id– Jedinečné ID pro každé pohlaví.gender_name– Jméno pohlaví.
Pojďme nyní analyzovat druhou předmětovou oblast.
Platy
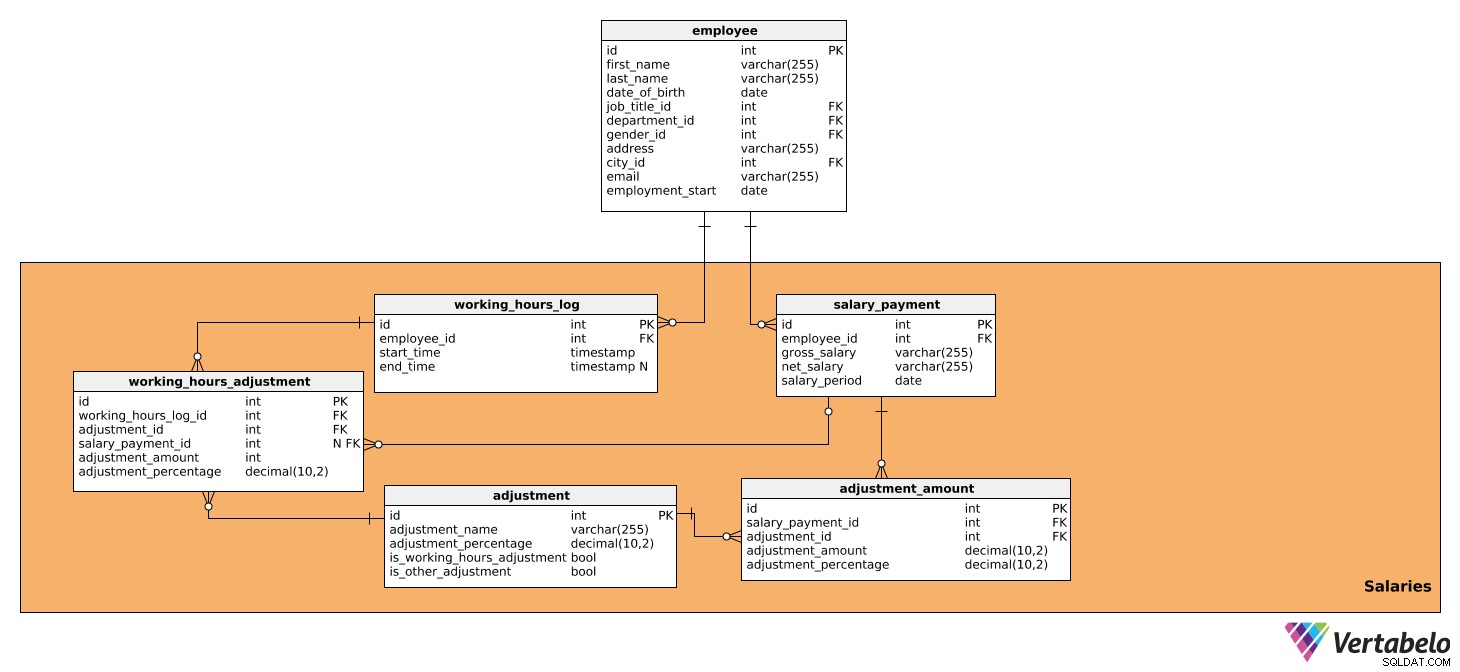
Tato oblast se skládá z tabulek, které obsahují všechny údaje, které přímo ovlivňují výpočty mezd za každé období a také částku k výplatě. Skládá se z pěti tabulek:
salary_paymentworking_hours_logworking_hours_adjustmentadjustmentadjustment_amount
Nyní se podívejme na jednotlivé tabulky.
První tabulka je salary_payment . Obsahuje všechny relevantní podrobnosti o mzdě vyplácené každému zaměstnanci a má následující atributy:
id– Jedinečné ID pro každý plat.employee_id– Odkazuje naemployeestůl.gross_salary– hrubá mzda, která bude základem pro další úpravy.net_salary– Čistá mzda (tj. částka, kterou zaměstnanec obdrží po různých srážkách).salary_period– Období, za které se vypočítává a vyplácí mzda.
Druhým je working_hours_log stůl. Obsahuje údaje o počtu odpracovaných hodin každého zaměstnance, což může ovlivnit určité úpravy mezd. Tato tabulka má následující atributy:
id– Jedinečné ID pro každou položku protokolu.employee_id– Odkazuje naemployeestůl.start_time– Čas, kdy se zaměstnanec přihlásil, tj. v daný den začal pracovat.end_time– Když se zaměstnanec odhlásil. Může být NULL, protože nebudeme znát přesný čas, dokud se zaměstnanec neodhlásí.
Další tabulka, kterou budeme analyzovat, je working_hours_adjustment . Tato tabulka bude použita pouze při výpočtu úprav na základě odpracovaných hodin, tj. těch, které mají hodnotu PRAVDA v is_working_hours_adjustment v adjustment stůl. Atributy jsou následující:
id– Jedinečné ID pro každou úpravu.working_hours_log_id– Odkazuje naworking_hours_logstůl.adjustment_id- Odkazuje naadjustmentstůl.salary_payment_id– Odkazuje nasalary_paymentstůl. Tato hodnota může mít hodnotu NULL, protožesalary_payment_idse použije pouze jednou za měsíc, kdy zahájíme výpočet mzdy.adjustment_amount– Částka úpravy.adjustment_percentage– Procentuální částka úpravy. Toto bude použito pro historické účely, protože procento se může v průběhu času měnit.
Další tabulka, o které budeme mluvit, je adjustment stůl. Obsahuje informace o všech úpravách použitých pro výpočet mzdy, tedy o všech daních a odvodech, které mají vliv na výši mzdy. Také bude obsahovat všechny úpravy, které závisí na odpracovaných a neodpracovaných hodinách, jako jsou prémie, přesčasy, nemocenská a mateřská/otcovská dovolená. K tomu potřebujeme následující údaje:
id– Jedinečné ID pro každou úpravu.adjustment_name– Název popisující tuto úpravu.adjustment_percentage– Procentuální částka konkrétní úpravy.is_working_hours_adjustment– Jedná se o označení vlajky, pokud úprava přímo závisí na pracovní době, např. přesčas, nemocenská atd.is_other_adjustment– Jedná se o úpravu označení příznakem, které není přímo závisí na odpracovaných hodinách, jako jsou daňové odpočty, příspěvky na sociální zabezpečení, příspěvky zaměstnavatele atd.
Poté potřebujeme adjustment_amount stůl. Použije se k výpočtu všech úprav platů kromě těch, které jsou již v working_hours_adjustment , tj. ty, které mají hodnotu TRUE v is_other_adjustment v adjustment stůl. Tabulka obsahuje následující atributy:
id– Jedinečné ID pro každý záznam částky úpravy.salary_payment_id– Odkazuje nasalary_paymentstůl.adjustment_id– Odkazuje naadjustmentstůl.adjustment_amount– Částka každé vypočítané úpravy.adjustment_percentage- Procentuální částka úpravy. Bude použit pro historické účely, protože procento se může v průběhu času měnit.
Dovolte mi uvést příklad, jak tabulky working_hours_log , working_hours_adjustment , adjustment a adjustment_amount spolupracovat na výpočtu mzdy. Zaměstnanec každý den zaznamenává příchod a odchod do práce. Tato data lze zobrazit v working_hours_log stůl. Řekněme, že náš zaměstnanec odpracoval 10 hodin přesčas po dobu jednoho měsíce a podle firemní politiky mu bude za každou hodinu přesčasu vypláceno o 20 % více. Odkazem na adjustment tabulky, budeme schopni najít požadovanou úpravu, tedy přesčasy, které budou mít určitou procentní výši (20 %). Budeme mít také is_working_hours_adjustment nastaveno na TRUE. Pomocí dat z těchto dvou tabulek budeme schopni vypočítat úpravu a uložit ji do working_hours_adjustment stůl.
Nyní můžeme vypočítat všechny ostatní úpravy, které není závisí na odpracovaných hodinách. To bude provedeno v adjustment_amount stůl. Stejně jako výše budeme odkazovat na adjustment tabulku a najdeme úpravy, které potřebujeme – např. daňový odpočet, příspěvek na sociální zabezpečení nebo příspěvek zaměstnavatele – a jejich příslušná procenta. is_other_adjustment příznak v adjustment tabulka bude pro tyto úpravy nastavena na hodnotu TRUE.
Na základě těchto výpočtů můžeme uložit údaje o hrubé a čisté mzdě do salary_payment stůl.
Procházením tohoto příkladu jsme pokryli vše v našem datovém modelu!
Líbil se vám datový model mezd?
Snažil jsem se vytvořit model, který by se dal použít téměř ve všech situacích. Do takto dlouhého článku však nelze zahrnout všechny konkrétní parametry, které ovlivňují výpočet mzdy. Pokrytím obecných principů jsem se pokusil tento model učinit užitečným jako pevný základ pro váš model mzdových dat.
Co si myslíte o mzdovém datovém modelu? Je to použitelné jako řešení pro vaše mzdové potřeby? Přišel jsi na něco jiného? Zjistili jste nějaké konkrétní problémy, které by výrazně změnily datový model? Vyjádřete svůj názor v sekci komentářů.