Seskupování je důležitou funkcí, která pomáhá organizovat a uspořádat data. Existuje mnoho způsobů, jak to udělat, a jednou z nejúčinnějších metod je klauzule SQL GROUP BY.
SQL GROUP BY můžete použít k rozdělení řádků ve výsledcích do skupin pomocí agregační funkce . Zní to jednoduše sečtením, průměrem nebo počítáním záznamů.
Ale děláte to správně?
„Správně“ může být subjektivní. Když běží bez kritických chyb se správným výstupem, je to považováno za v pořádku. Musí to však být také rychlé.
V tomto článku bude zvážena také rychlost. Uvidíte mnoho analýz dotazů pomocí logických čtení a plánů provádění ve všech bodech.
Začněme.
1. Filtr včas
Pokud si nejste jisti, kdy použít WHERE a HAVING, tato je pro vás. Protože v závislosti na zadané podmínce mohou obě poskytnout stejný výsledek.
Ale jsou jiní.
HAVING filtruje skupiny pomocí sloupců v klauzuli SQL GROUP BY. WHERE filtruje řádky před seskupením a agregací. Pokud tedy filtrujete pomocí klauzule HAVING, dojde k seskupení pro všechny řádky vráceny.
A to je špatně.
Proč? Krátká odpověď zní:je to pomalé. Dokažme to 2 dotazy. Podívejte se na kód níže. Před spuštěním v SQL Server Management Studio stiskněte nejprve Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analýza
Výše uvedené 2 příkazy SELECT vrátí stejné řádky. Oba mají pravdu v vracení objednávek produktů podle měsíců v roce 2012. Ale první SELECT trval 136 ms. spustit na mém notebooku, zatímco jinému to trvalo 764 ms.!
Proč?
Nejprve zkontrolujeme logická čtení na obrázku 1. STATISTICS IO vrátil tyto výsledky. Poté jsem jej vložil do StatisticsParser.com pro formátovaný výstup.
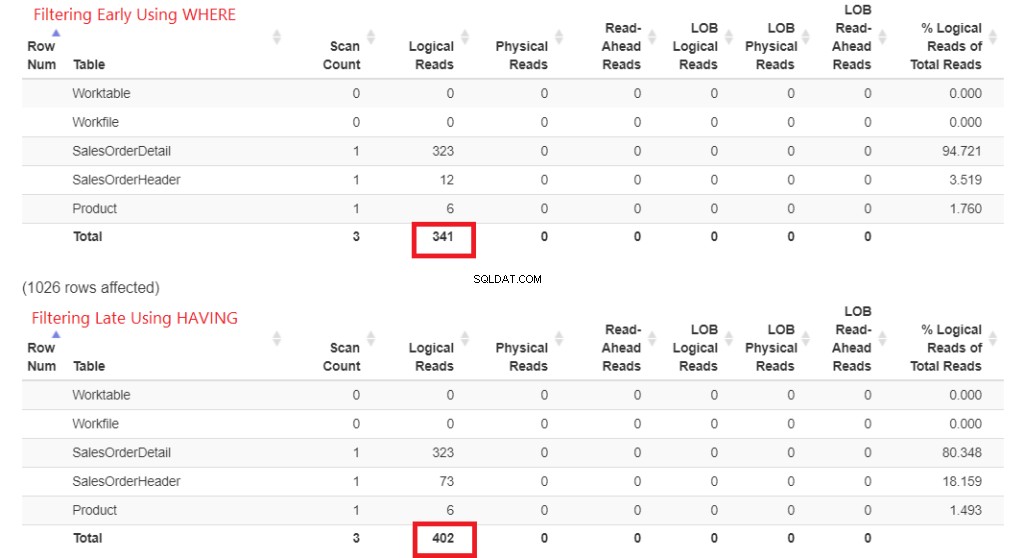
Obrázek 1 . Logické čtení časného filtrování pomocí WHERE vs. pozdní filtrování pomocí HAVING.
Podívejte se na celkové logické čtení každého z nich. Abyste těmto číslům porozuměli, čím logičtější čtení to trvalo, tím pomalejší bude dotaz. Takže to dokazuje, že použití HAVING je pomalejší a filtrování včas pomocí WHERE je rychlejší.
To samozřejmě neznamená, že MÍT je zbytečné. Jednou výjimkou je použití HAVING s agregací jako HAVING SUM(sod.Linetotal)> 100000 . V jednom dotazu můžete zkombinovat klauzuli WHERE a klauzuli HAVING.
Viz plán provádění na obrázku 2.
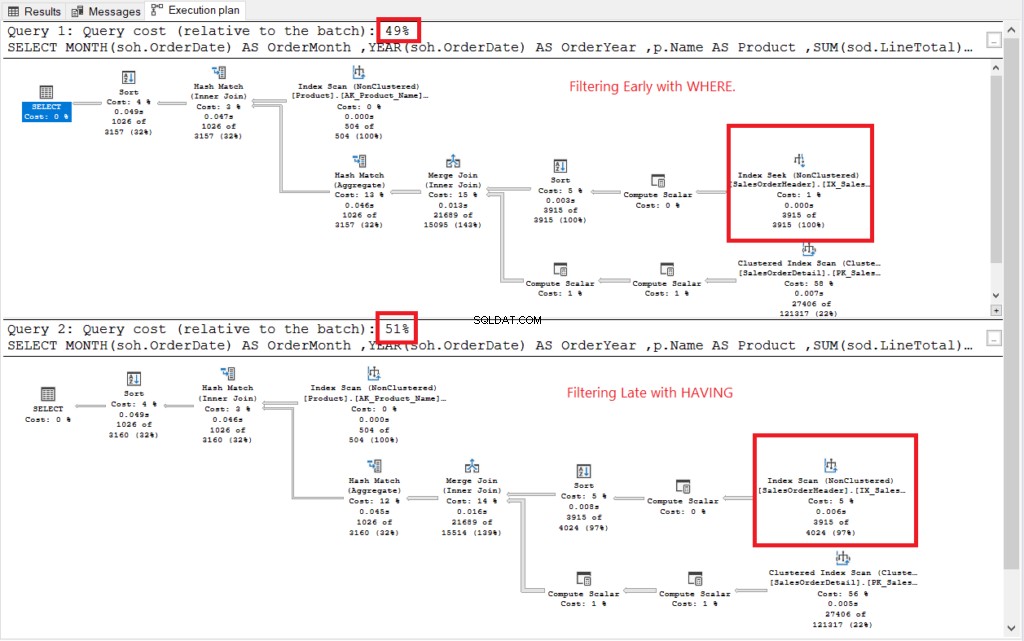
Obrázek 2 . Prováděcí plány filtrování brzy vs. filtrování pozdě.
Oba prováděcí plány vypadaly podobně, s výjimkou těch, které jsou označeny červeně. Filtrování dříve používalo operátor Index Seek, zatímco jiné používalo Index Scan. Hledání je rychlejší než skenování ve velkých tabulkách.
Ne te: Včasné filtrování má nižší náklady než pozdní filtrování. Základem je tedy včasné filtrování řádků, které může zlepšit výkon.
2. Nejprve seskupit, připojit se později
Výkon může zlepšit také připojení některých tabulek, které budete potřebovat později.
Řekněme, že chcete mít měsíční prodeje produktů. Ve stejném dotazu musíte také získat název produktu, číslo a podkategorii. Tyto sloupce jsou v jiné tabulce. A všechny je třeba přidat do klauzule GROUP BY, aby byla úspěšná realizace. Zde je kód.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Tohle poběží dobře. Ale existuje lepší a rychlejší způsob. To nebude vyžadovat přidání 3 sloupců pro název produktu, číslo a podkategorii do klauzule GROUP BY. To však bude vyžadovat trochu více stisknutí kláves. Tady to je.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analýza
Proč je to rychlejší? Připojení k produktu a Podkategorie produktu jsou provedeny později. Oba nejsou součástí klauzule GROUP BY. Dokažme to čísly ve STATISTICS IO. Viz obrázek 4.
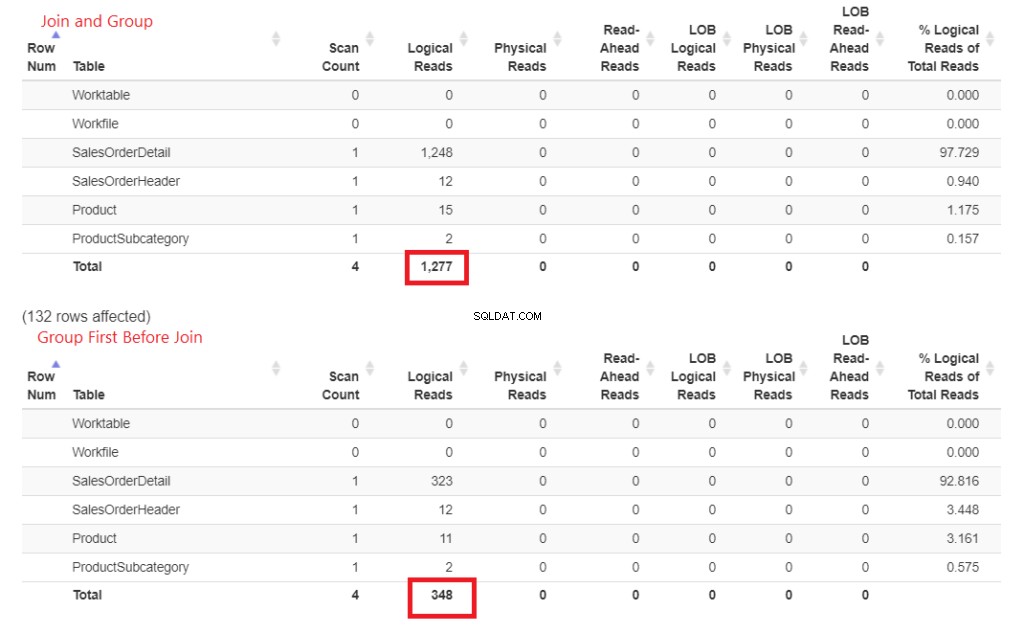
Obrázek 3 . Včasné připojení a seskupování spotřebovalo více logických čtení než pozdější připojení.
Vidíte ta logická čtení? Rozdíl je velký a vítěz je zřejmý.
Porovnejme plán provádění 2 dotazů, abychom viděli důvod výše uvedených čísel. Nejprve se podívejte na obrázek 4, kde je uveden plán provádění dotazu se všemi tabulkami spojenými při seskupení.
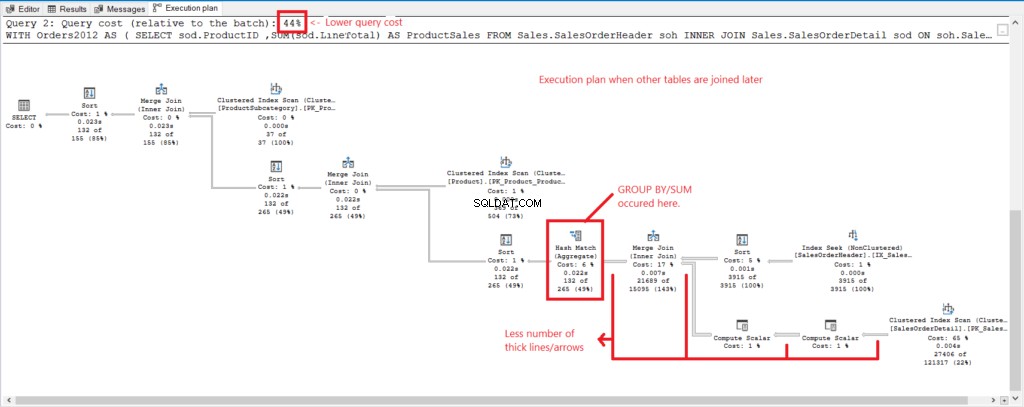
Obrázek 4 . Plán provádění, když jsou všechny stoly spojeny.
A máme následující postřehy:
- GROUP BY a SUM byly provedeny pozdě v procesu po připojení všech stolů.
- Mnoho tlustších čar a šipek – to vysvětluje 1 277 logických čtení.
- Tyto dva dotazy dohromady tvoří 100 % nákladů na dotaz. Plán tohoto dotazu má však vyšší náklady na dotaz (56 %).
Nyní je zde plán realizace, kdy se nejprve seskupíme a připojíme se k produktu a Podkategorie produktu tabulky později. Podívejte se na obrázek 5.
Obrázek 5 . Plán provedení, kdy je nejprve skupina, připojte se později.
A na obrázku 5 máme následující pozorování.
- GROUP BY a SUM skončily brzy.
- Menší počet tlustých čar a šipek – to vysvětluje pouze 348 logických čtení.
- Nižší náklady na dotaz (44 %).
3. Seskupit indexovaný sloupec
Kdykoli se provádí SQL GROUP BY na sloupci, měl by mít tento sloupec index. Jakmile seskupíte sloupec s indexem, zvýšíte rychlost provádění. Upravme předchozí dotaz a místo data objednávky použijte datum odeslání. Sloupec datum odeslání nemá žádný index v SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Stiskněte Ctrl-M a spusťte výše uvedený dotaz v SSMS. Poté vytvořte neklastrovaný index v Datum odeslání sloupec. Všimněte si logického čtení a plánu provádění. Nakonec znovu spusťte výše uvedený dotaz na jiné kartě dotazu. Všimněte si rozdílů v logických čteních a plánech provádění.
Zde je srovnání logických čtení na obrázku 6.
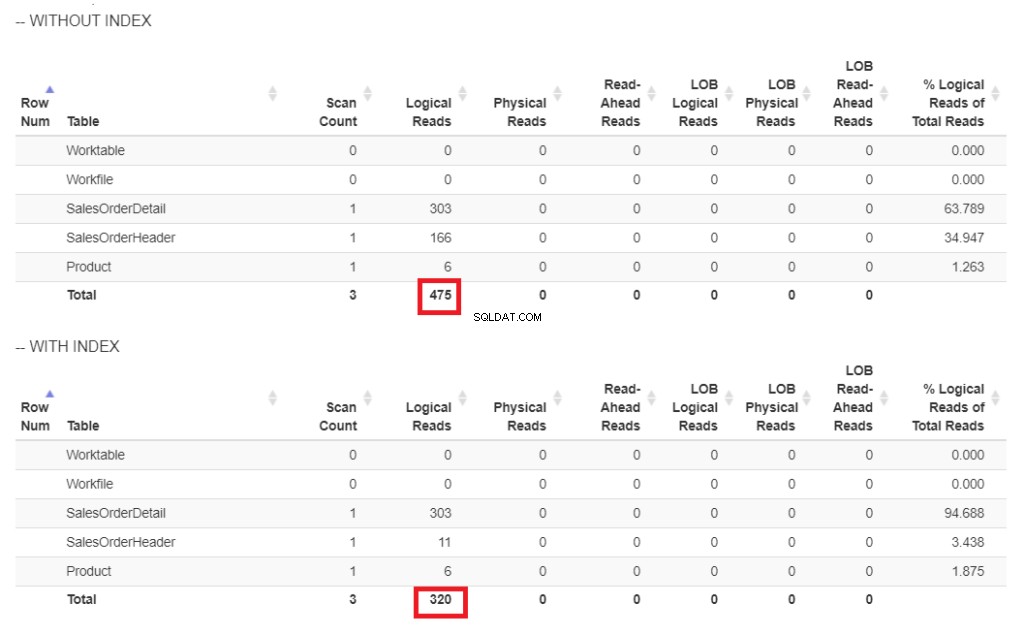
Obrázek 6 . Logické čtení našeho příkladu dotazu s indexem a bez indexu na ShipDate.
Na obrázku 6 jsou vyšší logické čtení dotazu bez indexu v Datum odeslání .
Nyní máme plán provádění, když Datum odeslání není žádný index existuje na obrázku 7.
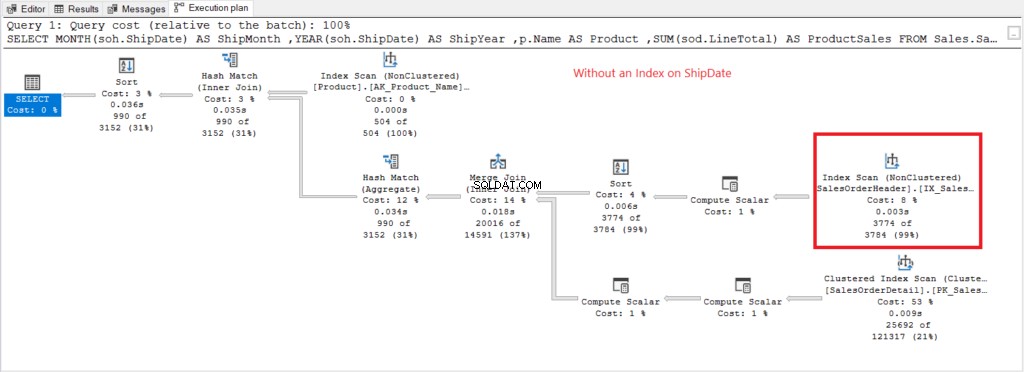
Obrázek 7 . Plán provádění při použití GROUP BY na Datum odeslání není indexován.
Skenování indexu operátor použitý v plánu na obrázku 7 vysvětluje vyšší logická čtení (475). Zde je plán provedení po indexování Datum odeslání sloupec.
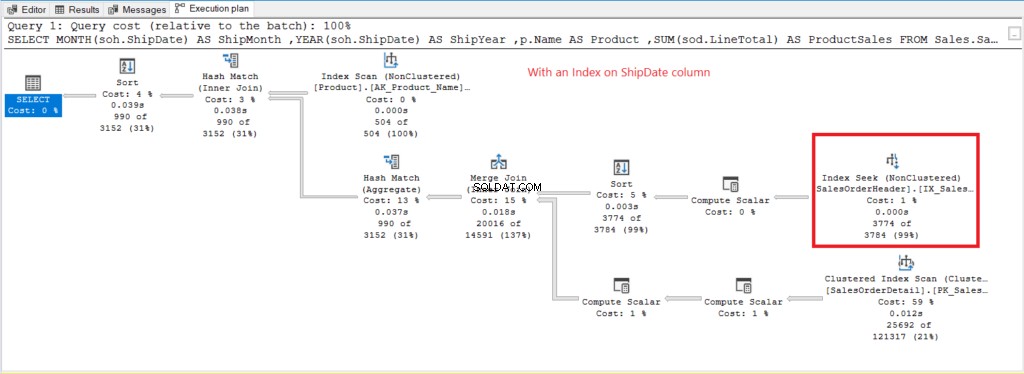
Obrázek 8 . Plán provádění při použití GROUP BY na indexování Datum odeslání.
Namísto skenování indexu se po indexování Datum odeslání použije hledání indexu sloupec. To vysvětluje spodní logické čtení na obrázku 6.
Chcete-li tedy zlepšit výkon při použití GROUP BY, zvažte indexování sloupců, které jste použili pro seskupování.
Poznámky v používání SQL GROUP BY
SQL GROUP BY se snadno používá. Ale musíte udělat další krok, abyste nepřekročili sumarizaci dat pro přehledy. Zde jsou znovu body:
- Filtrovat včas . Odstraňte řádky, které nepotřebujete sumarizovat pomocí klauzule WHERE namísto klauzule HAVING.
- Nejprve seskupit, připojit se později . Někdy budete muset přidat sloupce kromě sloupců, které seskupujete. Místo toho, abyste je zahrnuli do klauzule GROUP BY, rozdělte dotaz pomocí CTE a později připojte další tabulky.
- Použijte GROUP BY s indexovanými sloupci . Tato základní věc se může hodit, když je databáze rychlá jako šnek.
Doufám, že vám to pomůže zvýšit úroveň vaší hry ve výsledcích seskupování.
Pokud se vám tento příspěvek líbí, sdílejte jej na svých oblíbených platformách sociálních médií.