Integrovaná doprava je něco, o čem často slýcháme na internetu nebo ve zprávách. I když to není nic nového, je to rozhodně pokračující proces s neustálými změnami. Dnes se podíváme na datový model, který by mohl zpracovávat informace o zónách, cestujících a jízdenkách.
Pojďme se ponořit přímo do našeho integrovaného datového modelu dopravy, začněme myšlenkou za tím vším.
Nápad
Integrace dopravy je nezbytná pro maximalizaci její efektivity a pro zákazníky i její snadné použití. Integrace souvisí s náklady, ale také s časem, dostupností, pohodlím a bezpečností. To platí jak pro větší města, tak pro menší. Cílem je využít stávající dopravní infrastrukturu a optimalizovat ji pro lepší výsledky; to může znamenat přicházet s novými jízdními řády, upozorněními, linkami nebo stanicemi. Možná vám stačí mít nějaké informace k tomu, abyste se rozhodli počkat na autobus, půjčit si kolo nebo jednoduše dojít do cíle pěšky.
Vysvětleme to na dvou příkladech.
V případě velkého města je obvykle k dispozici mnoho různých dopravních prostředků:autobusy, taxíky, tramvaje, železnice, metro atd. To může vést k mnoha různým soukromým společnostem poskytujícím různé dopravní služby. Kombinace byť jen několika z těchto služeb by rozhodně prospěla cestujícím a společnostem, protože by snížila náklady, zvýšila efektivitu a poskytla více služeb na letenku.
Podobné výhody jsou i pro menší město. Nemusí existovat stejný počet možností, které lze kombinovat, ale mohly by být uspořádány tak, aby bylo dosaženo maximální efektivity.
Tento článek se zaměří především na integrované systémy odbavení přepravy. Nebudeme se zaměřovat na všechny aspekty integrace a různé druhy dopravy; to by bylo příliš složité.
S ohledem na to přejděme k našemu modelu.
Datový model
Model se skládá ze dvou tematických oblastí:
Cities & companiesTickets
Popíšeme je v pořadí, v jakém jsou uvedeny.
Města a společnosti
V první tematické oblasti uložíme všechny tabulky potřebné k nastavení dopravních zón ve městech.
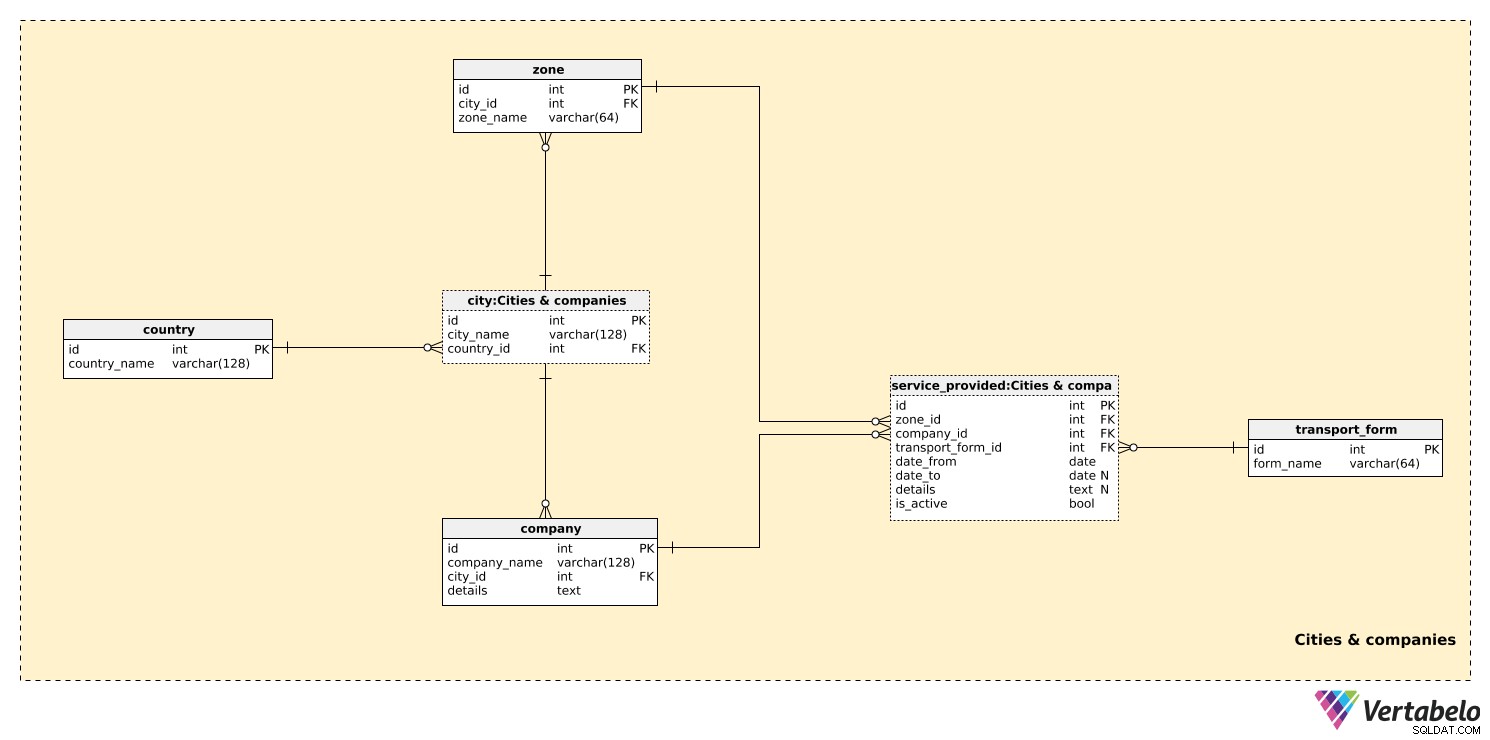
country tabulka obsahuje seznam UNIKÁTNÍCH country_name hodnoty. Tato tabulka se používá pouze jako reference v city stůl. I když můžeme očekávat, že náš model bude pokrývat přepravu pouze v jedné zemi, chceme mít možnost zahrnout více zemí. Pro každé město uložíme UNIKÁTNÍ kombinaci city_name – country_id .
Menší města budou mít pravděpodobně pouze jednu zónu, zatímco větší města budou mít více zón. Seznam všech možných zón je uložen v zone stůl. Pro každou zónu uložíme její zone_name a odkaz na příslušné město. Tento pár tvoří alternativní klíč této tabulky.
Můžeme očekávat, že náš systém bude ukládat informace o více dopravních společnostech. Společnosti budou vydávat jízdenky vlastní, ale budou moci vydávat jízdenky i společně s jinými společnostmi. Pro každou company , uložíme UNIKÁTNÍ kombinaci company_name a city_id kde se nachází. Veškeré potřebné dodatečné informace lze uložit do textových details pole.
Poslední věc, kterou musíme definovat, je forma dopravy, kterou každá společnost poskytuje. Některé očekávané hodnoty jsou „autobus“, „tramvaj“, „metro“ a „železnice“. Pro každou hodnotu v transport_form tabulky, uložíme UNIKÁTNÍ název_formy.
zone_id– Odkazuje nazonetabulka a označuje oblast, kde tuto formu přepravy tato společnost zajišťuje.company_id– Odkazuje nacompanyposkytování této služby v této zóně.transport_form_id– Odkazuje natransport_formtabulka a označuje typ poskytované služby.date_fromadate_to– Doba, po kterou byla tato služba touto společností poskytována. Všimněte si, žedate_tomůže obsahovat hodnotu NULL, pokud je tato služba stále dostupná a/nebo nemá žádné očekávané datum vypršení platnosti.details– Všechny ostatní podrobnosti v nestrukturovaném textovém formátu.is_active– Jestli je tato služba aktivní (probíhající) nebo ne. Toto je jednoduchý vypínač, který můžeme v některých případech použít místodate_from–date_tointerval servisní činnosti. Nejlepší použití tohoto atributu by bylo zjednodušit dotazy, tj. otestovat tuto hodnotu namísto testování intervalu data a „hraní si“ s hodnotami NULL.
Vstupenky
Předchozí předmět byl jen přípravou na to hlavní:vstupenky. A to je to, co tato oblast pokryje.
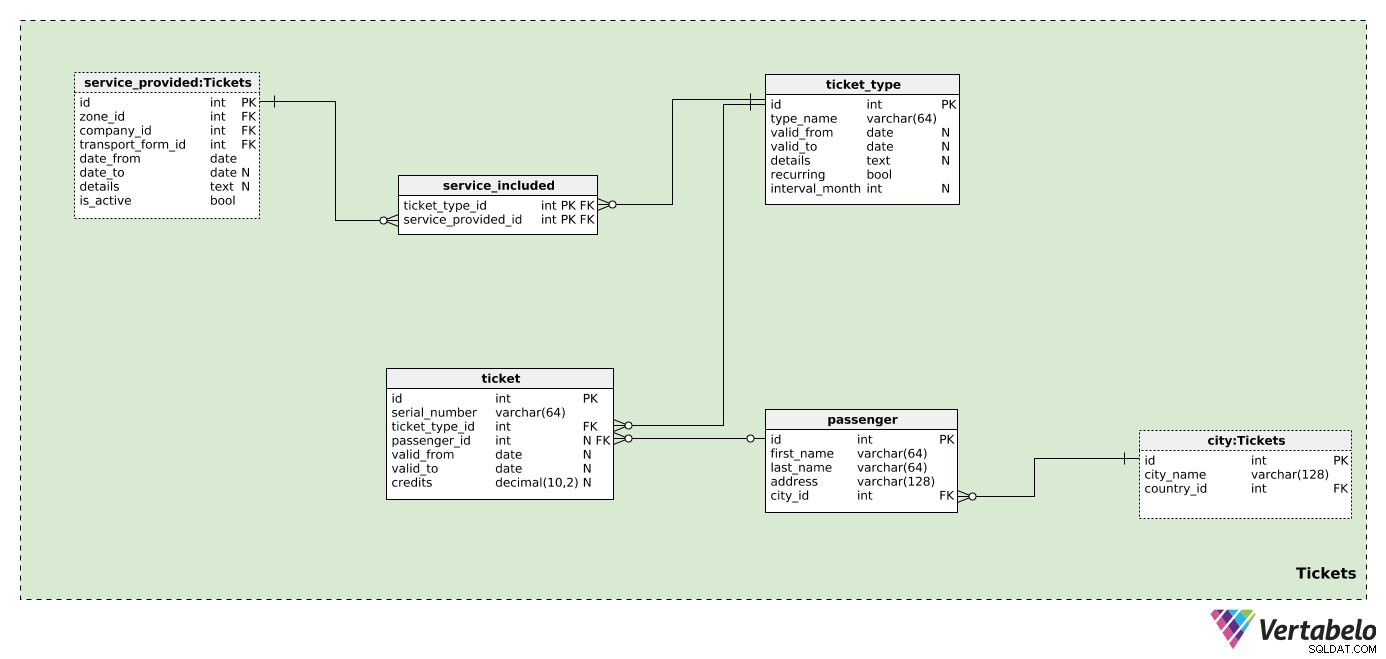
Definovali jsme společnosti, zóny a formy dopravy, ale nemáme žádné ustanovení pro cestující a jízdenky – jádro tohoto modelu. Budeme předpokládat, že jeden lístek by mohl být použit pro jednu nebo více zón pokrytých jednou nebo více společnostmi.
Proto musíme nejprve definovat každý ticket_type . V této tabulce uvedeme všechny možné typy vstupenek prodávaných společnostmi v naší databázi. Pro každý typ uložíme následující hodnoty:
type_name– Název JEDINEČNĚ označující tento typ.valid_fromavalid_to– Období, kdy je (nebo byl) tento typ tiketu platný. Obě pole mohou mít hodnotu null; hodnota NULL znamená, že neexistuje žádné počáteční (nebo koncové) datum, kdy to bylo platné.details– Veškeré potřebné podrobnosti v nestrukturovaném textovém formátu.recurring– Příznak označující, zda se tento typ lístku opakuje (např. ročně, měsíčně) či nikoli.interval_month– Pokud je typ lístku opakující se, bude tento atribut obsahovat interval v měsících, kdy se opakuje (např. „1“ pro měsíční lístek, „12“ pro roční lístek).
Nyní jsme připraveni definovat zóny pokryté jednotlivými typy lístků. V service_included tabulky, uložíme pouze UNIKÁTNÍ pár ticket_type_id – service_available_id . Ten také uvede společnost a zónu, kde lze tuto jízdenku použít. Tato tabulka nám umožňuje definovat více zón na tiket; zóny mohou patřit různým společnostem. Protože se jedná o předdefinované typy jízdenek, každý typ jízdenky bude mít zóny definované zde (ne pro každého jednotlivého cestujícího).
V tomto modelu nebudeme ukládat příliš mnoho podrobností o cestujících. Pro každého passenger , uložíme pouze jejich first_name , last_name , address a odkaz na město, kde žijí. Všechny tyto údaje se zobrazí na tiketu.
Poslední tabulkou v našem modelu je ticket stůl. Na jednorázové jízdenky se zde nezaměříme; spíše se postaráme o předplatné a předplacené vstupenky. Tyto vstupenky budou mít zůstatek, datum platnosti nebo obojí. To se může výrazně lišit v závislosti na společnosti a jejích pravidlech. Pokud se několik společností rozhodne vydat tiket, můžeme to podpořit v této tabulce – budeme znát všechny důležité podrobnosti. U každé vstupenky uložíme:
serial_number– UNIKÁTNÍ označení pro každou vstupenku. Může to být kombinace čísel a písmen.ticket_type_id– Odkazuje na typ tohoto lístku.passenger_id– Odkazuje na cestujícího, pokud existuje, který je vlastníkem této jízdenky. V případě předplacené vstupenky nemůže být vlastník.valid_fromavalid_to– Označuje dobu, po kterou je tato jízdenka platná. Hodnoty NULL označují, že neexistuje žádná spodní ani horní hranice.credits– Kredity (jako číselná hodnota) aktuálně dostupné na tomto tiketu. Pokud se jedná o předplacenou jízdenku, můžeme předpokládat, že si cestující zakoupí další kredity na jízdenku. Pokud je vstupenka platná po celý měsíc (nebo jiné časové období) bez jakýchkoli omezení použití, může být tato hodnota NULL.
Vylepšení datového modelu integrované dopravy
Můžete si všimnout, že tento model byl značně zjednodušen. Je to proto, že integrovaná doprava je prostě příliš velká na to, aby byla pokryta jedním článkem. Existuje několik věcí, o kterých si myslím, že by se v tomto modelu daly změnit:
- Zóny jsou příliš zjednodušené; měli bychom být schopni je definovat dynamičtěji.
- Nepokrýváme linky (např. autobusové linky). Co když přecházejí z jedné zóny do druhé atd.?
- Historie využití vstupenek neukládáme.
- Pro společnosti a cestující neexistuje žádná registrace.
To vše by vedlo k tomu, že bychom postrádali důležitá data a nemohli bychom provést žádnou hlubší analýzu. Tak co si myslíte? Co tento model potřebuje? Co byste přidali nebo odstranili? Podělte se o své nápady v komentářích.