IGNORE_DUP_KEY volba pro jedinečné indexy určuje, jak SQL Server odpoví na pokus o INSERT duplicitní hodnoty:Vztahuje se pouze na tabulky (nikoli na pohledy) a pouze na vložky. Jakákoli část vložení MERGE příkaz ignoruje jakýkoli IGNORE_DUP_KEY nastavení indexu.
Když IGNORE_DUP_KEY je OFF , první nalezený duplikát vede k chybě a nebudou vloženy žádné nové řádky.
Když IGNORE_DUP_KEY je ON , vložené řádky, které by porušovaly jedinečnost, jsou zahozeny. Zbývající řádky byly úspěšně vloženy. Upozornění místo chyby se zobrazí zpráva:
Shrnutí článku
IGNORE_DUP_KEY možnost indexu lze zadat pro jedinečné indexy seskupené i neshlukované. Jeho použití na seskupeném indexu může mít za následek mnohem horší výkon než pro neklastrovaný jedinečný index.
Velikost rozdílu ve výkonu závisí na tom, kolik porušení jedinečnosti bylo zjištěno během INSERT úkon. Čím více porušení, tím horší je výkon seskupeného jedinečného indexu ve srovnání. Pokud nedojde k žádným porušením, může vložení seskupeného indexu dokonce fungovat lépe.
Sdružené jedinečné indexové vložky
Pro seskupený jedinečný index s IGNORE_DUP_KEY jsou duplikáty zpracovávány úložným modulem .
Velká část práce při vkládání každého řádku se provádí před detekcí duplikátu. Například Vložení seskupeného rejstříku Operátor projde b-stromem seskupeného indexu dolů do bodu, kam by se dostal nový řádek, přičemž vezme zámky stránky a obvyklou hierarchii zámků, než objeví duplicitní klíč.
Když je detekován stav duplicitního klíče, zobrazí se chyba je zvednutý. Namísto zrušení provádění a vrácení chyby klientovi je chyba zpracována interně. Problematický řádek není vložen a provádění pokračuje a hledá další řádek k vložení. Pokud tento řádek narazí na duplicitní klíč, je vyvolána a zpracována další chyba a tak dále.
Výjimky jsou velmi drahé na házení a chytání. Značný počet duplikátů velmi znatelně zpomalí provádění.
Nezahrnuté jedinečné vložky indexu
Pro neklastrovaný jedinečný index s IGNORE_DUP_KEY jsou duplikáty zpracovávány procesorem dotazů . Před každým pokusem o vložení jsou detekovány duplikáty a vydá se varování.
Procesor dotazů odstraňuje duplikáty z vloženého proudu a zajišťuje, že úložný stroj neuvidí žádné duplikáty. V důsledku toho nejsou vyvolány nebo interně zpracovány žádné jedinečné chyby porušení klíče.
Výměna
Existuje kompromis mezi náklady na detekci a odstranění duplicitních klíčů v prováděcím plánu oproti nákladům na provedení významné práce související s vkládáním a házením a zachycováním chyb, když je nalezen duplikát.
Pokud se očekává, že duplikáty budou velmi vzácné řešení úložiště (shlukovaný index) může být efektivnější. Když jsou duplikáty méně vzácné, přístup procesoru dotazů se pravděpodobně vyplatí. Přesný bod křížení bude záviset na faktorech, jako je efektivita běhu komponent plánu provádění používaných k detekci a odstranění duplikátů.
Zbytek tohoto článku poskytuje ukázku a podrobněji se zabývá tím, proč může přístup úložiště úložiště fungovat tak špatně.
Ukázka
Následující skript vytvoří dočasnou tabulku s milionem řádků. Má 1 000 jedinečných hodnot a 1 000 řádků pro každou jedinečnou hodnotu. Tato datová sada bude použita jako zdroj dat pro vložení do tabulek s různými konfiguracemi indexu.
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); Výchozí hodnota
Následující vložení do proměnné tabulky s nejedinečným seskupeným indexem trvá přibližně 900 ms :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
Všimněte si, že chybí IGNORE_DUP_KEY na proměnné cílové tabulky.
Shlukovaný jedinečný index
Vkládání stejných dat do jedinečného shluku indexovat pomocí IGNORE_DUP_KEY nastavte ON trvá přibližně 15 900 ms — téměř 18krát horší:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Nezahrnutý jedinečný index
Vkládání dat do jedinečného neshlukovaného indexovat pomocí IGNORE_DUP_KEY nastavte ON trvá přibližně 700 ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; Přehled výkonu
Základní test trvá 900 ms vložit všech jeden milion řádků. Neklastrovaný indexový test trvá 700 ms vložit pouze 1 000 různých klíčů. Test clusterového indexu trvá 15 900 ms vložit stejných 1 000 jedinečných řádků.
Tento test je záměrně nastaven tak, aby upozornil na špatnou výkonnost implementace úložného jádra tím, že generuje 999 jednotek zbytečné práce (zámky, zámky, zpracování chyb) pro každý úspěšný řádek.
Zamýšlená zpráva není IGNORE_DUP_KEY bude vždy fungovat špatně na klastrovaných indexech, právě to by mohlo, a mezi klastrovanými a neklastrovanými indexy může být velký rozdíl.
Plán provádění seskupených indexů
V plánu vložení seskupeného indexu toho není moc vidět:
Do vložení seskupeného rejstříku se předává 1 000 000 řádků operátor, který je zobrazen jako „vracející“ 1 000 řádků. Když se podíváme do podrobností plánu, můžeme vidět:
- 1 244 008 logických čtení na operátoru vložení.
- Velkou většinu času provádění stráví Vložit operátor.
- 11 ms z
SOS_SCHEDULER_YIELDčeká (tj. žádné další čekání).
Nic, co by skutečně vysvětlilo těch 15 900 ms uplynulého času.
Proč je výkon tak slabý
Je zřejmé, že tento plán bude muset udělat hodně práce pro každý řádek:
- Procházejte úrovněmi seskupeného indexového b-stromu, zachycujte a zamykejte tak, jak to jde, abyste našli bod vložení pro nový záznam.
- Pokud některá z potřebných stránek indexu není v paměti, bude nutné ji načíst z disku.
- Vytvořte nový řádek b-stromu v paměti.
- Připravte záznamy protokolu.
- Pokud je nalezen duplikát klíče (nejedná se o duplicitní záznam), vyvolejte chybu, ošetřete ji interně, uvolněte aktuální řádek a pokračujte ve vhodném bodě kódu, aby se zpracoval další kandidátský řádek. li>
To je celkem dost práce a pamatujte, že se to všechno děje pro každý řádek .
Část, na kterou se chci soustředit, je vyvolávání chyb a jejich zpracování, protože je to extrémní drahý. Zbývající aspekty uvedené výše již byly co nejlevnější díky použití proměnné tabulky a dočasné tabulky v ukázce.
Výjimky
První věc, kterou chci udělat, je ukázat, že Clustered Index Insert operátor skutečně vyvolá výjimku, když narazí na duplicitní klíč.
Jedním ze způsobů, jak to přímo ukázat, je připojení debuggeru a zachycení trasování zásobníku v místě vyvolání výjimky:
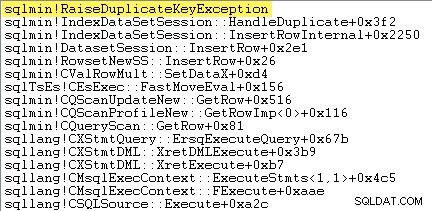
Důležitým bodem je, že házení a chytání výjimek je velmi drahé.
Monitorování SQL Server pomocí Windows Performance Recorder během testu a analýza výsledků ve Windows Performance Analyzer ukazuje:
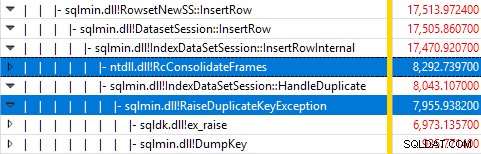
Téměř veškerý čas provádění dotazu je stráven v sqlmin!IndexDataSetSession::InsertRowInternal jak by se dalo očekávat u dotazu, který kromě vkládání řádků nedělá nic jiného.
Překvapením je, že 45 % tohoto času je věnováno vyvolávání výjimek prostřednictvím sqlmin!RaiseDuplicateKeyException a dalších 47 % je vynaloženo v přidruženém bloku zachycení výjimek (ntdll!RcConsolidateFrames hierarchie).
Abych to shrnul:Zvyšování a zachycování výjimek tvoří 92 % doby provedení našeho testovacího dotazu na vložení seskupeného indexu.
Problémy se shromažďováním dat
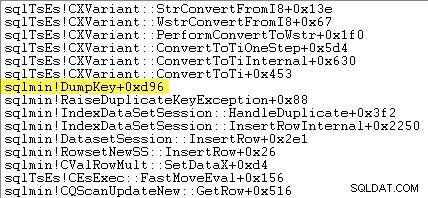
Bystrozrací čtenáři si mohou všimnout značného množství – asi 12 % – času na zvýšení výjimek stráveného v sqlmin!DumpKey v grafu Windows Performance Analyzer. Toto stojí za to rychle prozkoumat, spolu s několika souvisejícími položkami.
V rámci vyvolání výjimky musí SQL Server shromáždit některá data, která jsou dostupná pouze v době, kdy došlo k chybě. Číslo chyby spojené s výjimkou duplicitního klíče je 2627. Text zprávy v sys.messages pro toto číslo chyby je:
Informace k naplnění těchto značek míst je třeba shromáždit v době, kdy dojde k chybě – později nebudou k dispozici! To znamená vyhledat a naformátovat typ omezení, jeho název, úplný název cílového objektu a konkrétní hodnotu klíče. Všechno to chce čas.
Následující trasování zásobníku ukazuje, jak server během DumpKey formátuje hodnotu duplicitního klíče jako řetězec Unicode zavolejte:
Zpracování výjimek také zahrnuje zachycení trasování zásobníku:
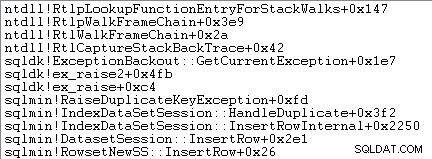
SQL Server také zaznamenává informace o výjimkách (včetně rámců zásobníku) do malé kruhové vyrovnávací paměti, jak ukazuje následující:
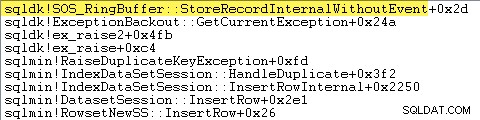
Tyto položky kruhové vyrovnávací paměti můžete zobrazit pomocí příkazu jako:
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; Následuje příklad záznamu xml pro výjimku duplicitního klíče. Všimněte si rámečků zásobníku:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> Všechny tyto práce na pozadí se odehrávají u každé výjimky. V našem testu to znamená, že se to stane 999 000krát — jednou pro každý řádek, který narazí na duplicitní porušení klíče.
Existuje mnoho způsobů, jak to zjistit, například spuštěním trasování Profiler pomocí Výjimky událost v Chyby a varování třída. V našem testovacím případě to nakonec bude vytvořit 999 000 řádků pomocí TextData prvky jako tento:
Porušení omezení UNIQUE KEY 'UQ__#AC166DE__3213663B8B6E2E0E'Nelze vložit duplicitní klíč do objektu 'dbo.@T'.
Duplicitní hodnota klíče je (173).
Připojení Profileru znamená, že každá událost zpracování výjimek získává velké množství dodatečné režie, protože se shromažďují a formátují další potřebná data. Výchozí data zmíněná dříve se shromažďují vždy, i když je nikdo aktivně nespotřebovává.
Aby bylo jasno:Údaje o výkonu uvedené v tomto článku byly získány bez připojeného ladicího programu a bez aktivního dalšího sledování.
Neclustered Index Execution Plan
Navzdory tomu, že je mnohem rychlejší, je plán vložení neshlukovaného indexu o něco složitější, takže ho rozdělím na dvě části.
Obecným tématem je, že tento plán je rychlejší, protože eliminuje duplikáty před pokoušíte se je vložit do cílové tabulky.
Část 1
Nejprve pravá strana plánu neshlukovaného indexu:
Tato část plánu odmítne všechny řádky, které mají klíčovou shodu v cílové tabulce pro jedinečný index pomocí IGNORE_DUP_KEY nastavte ON .
Možná očekáváte, že uvidíte Anti Semi Join zde, ale SQL Server nemá potřebnou infrastrukturu k odeslání požadovaného upozornění na duplicitní klíč pomocí Anti Semi Join operátor. (Pokud to již nedává smysl, mělo by to brzy být.)
Místo toho dostáváme plán s řadou zajímavých funkcí:
- Skenování seskupeného indexu je
Ordered:Trueposkytnout vstup pro Sloučit levou částečnou spojku seřazeno podle sloupcec1v#Datastůl. - Prohledávání indexů proměnné tabulky je
Ordered:False - Položka Řadit seřadí řádky podle sloupce
c1v proměnné tabulky. Tuto objednávku mohl poskytnout objednaný skenování indexu proměnné tabulky nac1, ale o Řazení rozhoduje optimalizátor je nejlevnější způsob, jak zajistit požadovanou úroveň Halloweenské ochrany. - Proměnná tabulky Prohledávání indexu má interní
UPDLOCKaSERIALIZABLErady použité k zajištění stability cíle během provádění plánu. - Připojení levé části ke sloučení kontroluje shodu v proměnné tabulky pro každou hodnotu
c1vráceno z#Datastůl. Na rozdíl od běžného semi spojení vysílá každý řádek přijatý na svém horním vstupu. Nastaví příznak ve sloupci sondy pro označení, zda aktuální řádek našel shodu nebo ne. Sloupec sondy je vysílán z Merge Left Semi Join jako výraz s názvemExpr1012. - Prohlášení operátor kontroluje hodnotu sloupce sondy
Expr1012. Když poprvé uvidí řádek s nenulovou hodnotou sloupce sondy (označující, že byla nalezena shoda klíče indexu), vyšle zprávu „Duplicitní klíč byl ignorován“ zpráva. - Prohlášení předává pouze řádky, kde je sloupec sondy null. To eliminuje příchozí řádky, které by způsobovaly chybu duplicitního klíče.
To vše se může zdát složité, ale je to v podstatě tak jednoduché jako nastavení příznaku, pokud je nalezena shoda, vyslání varování při prvním nastavení příznaku a pouze předání řádků směrem k vložení, které ještě neexistují v cílové tabulce. .
Část 2
Druhá část plánu navazuje na Assert operátor:
Předchozí část plánu odstranila řádky, které měly shodu v cílové tabulce. Tato část plánu odstraní duplikáty v sadě vložek .
Představte si například, že v cílové tabulce nejsou žádné řádky, kde by c1 = 1 . Stále můžeme způsobit chybu duplicitního klíče, pokud se pokusíme vložit dva řádky s c1 = 1 ze zdrojové tabulky. Musíme se tomu vyhnout, abychom dodrželi sémantiku IGNORE_DUP_KEY = ON .
Tento aspekt řeší Segment a Nahoře operátory.
Segment operátor nastaví nový příznak (označený Segment1015 ), když narazí na řádek s novou hodnotou pro c1 . Protože řádky jsou uvedeny v c1 objednávka (díky příkazu Sloučit zachovávající pořadí ), plán se může spolehnout na všechny řádky se stejným c1 hodnota přicházející v souvislém proudu.
Nahoře operátor předá jeden řádek pro každou skupinu duplikátů, jak je označeno Segmentem vlajka. Pokud je Nahoře operátor narazí na více než jeden řádek pro stejný segment skupina (c1 hodnota), vydá „Duplicitní klíč byl ignorován“ varování, pokud je to poprvé, co plán narazí na tento stav.
Výsledkem toho všeho je, že operátorům vložení je předán pouze jeden řádek pro každou jedinečnou hodnotu c1 a v případě potřeby se vygeneruje varování.
Plán provádění nyní eliminoval všechna potenciální duplicitní porušení klíčů, takže zbývající Vložení tabulky a Vložení indexu Operátoři mohou bezpečně vkládat řádky do haldy a indexu bez klastrů bez obav z chyby duplicitního klíče.
Pamatujte, že UPDLOCK a SERIALIZABLE rady aplikované na cílovou tabulku zajišťují, že se sada nemůže během provádění změnit. Jinými slovy, souběžný příkaz nemůže změnit cílovou tabulku tak, aby došlo k chybě duplicitního klíče v Insert operátory. To zde není problém, protože používáme soukromou proměnnou tabulky, ale SQL Server stále přidává rady jako obecné bezpečnostní opatření.
Bez těchto rad by souběžný proces mohl do cílové tabulky přidat řádek, který by generoval duplicitní porušení klíče, a to navzdory kontrolám provedeným částí 1 plánu. SQL Server si musí být jistý, že výsledky kontroly existence zůstávají platné.
Zvědavý čtenář může vidět některé z výše popsaných funkcí, když povolí příznaky trasování 3604 a 8607, aby viděl výstupní strom optimalizátoru:
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
Závěrečné myšlenky
IGNORE_DUP_KEY možnost indexu není něco, co většina lidí bude používat velmi často. Přesto je zajímavé podívat se, jak je tato funkce implementována a proč mohou existovat velké rozdíly ve výkonu mezi IGNORE_DUP_KEY na seskupených a neklastrovaných indexech.
V mnoha případech se vyplatí řídit se vzorem dotazovacího procesoru a snažit se psát dotazy, které duplikáty explicitně eliminují, než se spoléhat na IGNORE_DUP_KEY . V našem příkladu by to znamenalo napsat:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; To se provede za přibližně 400 ms , jen pro pořádek.