Narazili jste někdy na situaci, kdy potřebujete řídit stav subjektu, který se v čase mění? Existuje mnoho příkladů. Začněme tím jednoduchým:sloučením záznamů zákazníků.
Předpokládejme, že slučujeme seznamy zákazníků ze dvou různých zdrojů. Mohlo by dojít k některému z následujících stavů:Identifikace duplikátů – systém nalezl dvě potenciálně duplicitní entity; Potvrzené duplikáty – uživatel ověří, že tyto dvě entity jsou skutečně duplikáty; nebo Potvrzené jedinečné – uživatel rozhodne, že tyto dvě entity jsou jedinečné. V kterékoli z těchto situací má uživatel na výběr pouze ano-ne.
Ale co složitější situace? Existuje způsob, jak definovat skutečný pracovní postup mezi státy? Čtěte dále…
Jak se věci mohou snadno pokazit
Mnoho organizací potřebuje spravovat žádosti o zaměstnání. V jednoduchém modelu můžete mít tabulku nazvanou JOB_APPLICATION a mohli byste sledovat stav aplikace pomocí referenční datové tabulky obsahující hodnoty, jako jsou tyto:
| Stav aplikace |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Tyto hodnoty lze kdykoli vybrat v libovolném pořadí. Spoléhá na koncové uživatele, kteří zajistí, že v každé fázi bude proveden logický a správný výběr. Nic nezakazuje nelogický sled stavů.
Řekněme například, že žádost byla zamítnuta. Aktuální stav by zjevně byl APPLICATION_REJECTED . Na úrovni aplikace nelze udělat nic, co by nezkušenému uživateli zabránilo v následném výběru INVITED_TO_INTERVIEW nebo nějaký jiný nelogický stav.
Je potřeba něco, co uživatele povede k výběru dalšího logického stavu, něco, co definuje logický pracovní postup .
A co když máte různé požadavky na různé typy žádostí o zaměstnání? Některá zaměstnání mohou například vyžadovat, aby uchazeč absolvoval zkoušku způsobilosti. Jistě, můžete do seznamu přidat další hodnoty, aby je pokryly, ale v aktuálním návrhu není nic, co by koncovému uživateli nebránilo v nesprávném výběru typu dané aplikace. Realita je taková, že existují různé pracovní postupy pro různé kontexty .
Další bod k zamyšlení:jsou uvedené možnosti skutečně všechny stavy ? Nebo jsou některé ve skutečnosti výsledky ? Například nabídku práce může uchazeč přijmout nebo odmítnout. Proto JOB_OFFER_MADE skutečně má dva výsledky:JOB_OFFER_ACCEPTED a JOB_OFFER_DECLINED .
Dalším výsledkem může být stažení pracovní nabídky. Možná budete chtít zaznamenat důvod, proč byl stažen, pomocí kvalifikátoru. Pokud pouze přidáte tyto důvody do výše uvedeného seznamu, nic nevede koncového uživatele k logickému výběru.
Takže skutečně, čím složitější jsou stavy, výsledky a kvalifikátory, tím více musíte definovat pracovní postup procesu .
Organizace procesů, stavů a výsledků
Než se pokusíte je modelovat, je důležité porozumět tomu, co se s vašimi daty děje. Zpočátku se můžete přiklánět k názoru, že zde existuje přísná hierarchie typů:
Když se blíže podíváme na výše uvedený příklad, uvidíme, že INVITED_TO_INTERVIEW a JOB_OFFER_MADE státy sdílejí stejné možné výsledky, jmenovitě ACCEPTED a DECLINED . To nám říká, že existuje vztah mnoho k mnoha mezi stavy a výsledky. To často platí pro jiné stavy, výsledky a kvalifikátory.
Na koncepční úrovni se tedy s našimi metadaty vlastně děje toto:
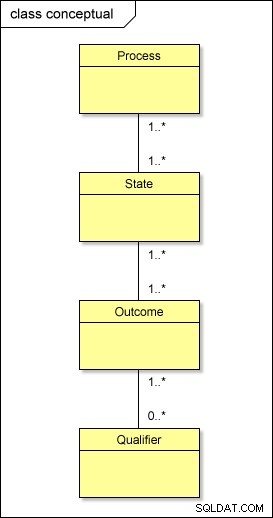
Pokud byste tento model transformovali do fyzického světa pomocí standardního přístupu, měli byste tabulky nazvané PROCESS , STATE , OUTCOME a QUALIFIER; budete také potřebovat střední tabulky mezi nimi – PROCESS_STATE , STATE_OUTCOME a OUTCOME_QUALIFIER – vyřešit vztahy mnoho k mnoha . To komplikuje design.
I když musí být zachována logická hierarchie úrovní (proces → stav → výsledek → kvalifikátor), existuje jednodušší způsob, jak fyzicky uspořádat naše metadata.
Vzor pracovního postupu
Níže uvedený diagram definuje hlavní součásti databázového modelu pracovního postupu:
Žluté tabulky nalevo obsahují metadata pracovního postupu a modré tabulky napravo obsahují obchodní data.
První věc, kterou je třeba zdůraznit, je, že může být spravována jakákoli entita bez nutnosti zásadních změn tohoto modelu. YOUR_ENTITIY_TO_MANAGE tabulka je ta pod správou workflow. V našem příkladu by to byla JOB_APPLICATION stůl.
Dále musíme jednoduše přidat wf_state_type_process_id sloupec do jakékoli tabulky, kterou chceme spravovat. Tento sloupec ukazuje na skutečný proces pracovního postupu používá k řízení entity. Toto není výhradně sloupec cizího klíče, ale umožňuje nám rychle dotazovat WORKFLOW_STATE_TYPE pro správný proces. Tabulka, která bude obsahovat historii stavu je MANAGED_ENTITY_STATE . Zde byste si opět vybrali svůj vlastní konkrétní název tabulky a upravili jej podle svých vlastních požadavků.
Metadata
Různé úrovně pracovního postupu jsou definovány v WORKFLOW_LEVEL_TYPE . Tato tabulka obsahuje následující:
| Typový klíč | Popis |
|---|---|
| PROCESOVAT | Proces pracovního postupu na vysoké úrovni. |
| STATE | Stav v procesu. |
| VÝSLEDEK | Jak stav skončí, jeho výsledek. |
| KVALIFIKÁTOR | Volitelný, podrobnější kvalifikátor pro výsledek. |
WORKFLOW_STATE_TYPE a WORKFLOW_STATE_HIERARCHY tvoří klasickou strukturu kusovníku (BOM) . Tato struktura, která velmi dobře popisuje skutečný výrobní kusovník, je v datovém modelování zcela běžná. Může definovat hierarchie nebo být aplikován na mnoho rekurzivních situací. Využijeme to zde k definování naší logické hierarchie procesů, stavů, výsledků a volitelných kvalifikátorů.
Než budeme moci definovat hierarchii, musíme definovat jednotlivé komponenty. To jsou naše základní stavební kameny. Budu je pouze odkazovat pomocí TYPE_KEY (což je unikátní) z důvodu stručnosti. Pro náš příklad máme:
| Typ úrovně pracovního postupu | Klíč stavu pracovního postupu Type.Type |
|---|---|
| VÝSLEDEK | PROSTĚNO |
| VÝSLEDEK | SELHALO |
| VÝSLEDEK | PŘIJÍMÁNO |
| VÝSLEDEK | ODMÍTNUTO |
| VÝSLEDEK | CANDIDATE_CANCELLED |
| VÝSLEDEK | EMPLOYER_CANCELLED |
| VÝSLEDEK | ZAMÍTNUTO |
| VÝSLEDEK | EMPLOYER_WITHDRAWER |
| VÝSLEDEK | NO_SHOW |
| VÝSLEDEK | NAJATO |
| VÝSLEDEK | NOT_HIRED |
| STATE | APPLICATION_RECEIVED |
| STATE | APLIKACE_REVIEW |
| STATE | INVITED_TO_INTERVIEW |
| STATE | ROZHOVOR |
| STATE | TEST_APTITUDE |
| STATE | SEEK_REFERENCES |
| STATE | MAKE_OFFER |
| STATE | APPLICATION_UZAVŘENA |
| PROCESOVAT | STANDARD_JOB_APPLICATION |
| PROCESOVAT | TECHNICAL_JOB_APPLICATION |
Nyní můžeme začít definovat naši hierarchii. Zde bereme naše stavební kameny a definujeme naši strukturu. Pro každý stav definujeme možné výsledky. Ve skutečnosti je pravidlem tohoto systému pracovních postupů, že každý stav musí skončit s výsledkem:
| Typ rodiče – STÁTY | Typ dítěte – VÝSLEDKY |
|---|---|
| APPLICATION_RECEIVED | PŘIJÍMÁNO |
| APPLICATION_RECEIVED | ZAMÍTNUTO |
| APLIKACE_REVIEW | PROSTĚNO |
| APLIKACE_REVIEW | SELHALO |
| INVITED_TO_INTERVIEW | PŘIJÍMÁNO |
| INVITED_TO_INTERVIEW | ODMÍTNUTO |
| ROZHOVOR | PROSTĚNO |
| ROZHOVOR | SELHALO |
| ROZHOVOR | CANDIDATE_CANCELLED |
| ROZHOVOR | NO_SHOW |
| MAKE_OFFER | PŘIJÍMÁNO |
| MAKE_OFFER | ODMÍTNUTO |
| SEEK_REFERENCES | PROSTĚNO |
| SEEK_REFERENCES | SELHALO |
| APPLICATION_CLOSED | NAJATO |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | PROSTĚNO |
| TEST_APTITUDE | SELHALO |
Naše procesy jsou jednoduše souborem stavů, z nichž každý existuje po určitou dobu. V níže uvedené tabulce jsou uvedeny v logickém pořadí, které však nedefinuje skutečné pořadí zpracování.
| Rodičovský typ – PROCESY | Typ dítěte – STÁTY |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APLIKACE_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | ROZHOVOR |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_UZAVŘENA |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APLIKACE_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | ROZHOVOR |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_UZAVŘENA |
V souvislosti s hierarchií kusovníku je třeba uvést důležitý bod. Stejně jako fyzický kusovník definuje sestavy a podsestavy až po nejmenší komponenty, máme podobné uspořádání v naší hierarchii. To znamená, že můžeme znovu použít „sestavy“ a „podsestavy“.
Jako příklad:Oba STANDARD_JOB_APPLICATION a TECHNICAL_JOB_APPLICATION procesy mít INTERVIEW stát . Na druhé straně INTERVIEW stát má PASSED , FAILED , CANDIDATE_CANCELLED a NO_SHOW výsledky pro to definované.
Když použijete stav v procesu, automaticky s ním získáte jeho podřízené výsledky, protože se již jedná o sestavení. To znamená, že v INTERVIEW existují stejné výsledky pro oba typy žádostí o zaměstnání etapa. Pokud chcete různé výsledky pohovorů pro různé typy žádostí o zaměstnání, musíte definovat, řekněme, TECHNICAL_INTERVIEW a STANDARD_INTERVIEW uvádí, že každý z nich má své vlastní specifické výsledky.
V tomto příkladu je jediný rozdíl mezi těmito dvěma typy žádostí o zaměstnání v tom, že technická žádost o zaměstnání obsahuje test způsobilosti.
Než odejdete
Část 1 tohoto dvoudílného článku představila vzor databáze pracovního postupu. Ukázal, jak jej můžete začlenit do správy životního cyklu jakékoli entity ve vaší databázi.
Část 2 vám ukáže, jak definovat skutečný pracovní postup pomocí dalších konfiguračních tabulek. Zde budou uživateli předloženy další povolené kroky. Předvedeme také techniku, jak obejít striktní opětovné použití „sestav“ a „podsestav“ v kusovnících.