Vysoká dostupnost je v dnešní době nutností, protože většina organizací si nemůže dovolit přijít o svá data. Vysoká dostupnost je však vždy spojena s cenovkou (která se může značně lišit.) Jakákoli nastavení, která vyžadují téměř okamžitou akci, by obvykle vyžadovala drahé prostředí, které by přesně odráželo nastavení výroby. Existují však další možnosti, které mohou být levnější. Ty sice neumožňují okamžitý přechod na cluster pro obnovu po havárii, ale stále umožňují kontinuitu podnikání (a nevyčerpají rozpočet.)
Příkladem tohoto typu nastavení je prostředí DR ve „studeném pohotovostním režimu“. To vám umožní snížit vaše náklady a zároveň budete moci vytvořit nové prostředí na externím místě, pokud by katastrofa udeřila. V tomto příspěvku na blogu si ukážeme, jak takové nastavení vytvořit.
Počáteční nastavení
Předpokládejme, že máme v našem vlastním datovém centru poměrně standardní nastavení replikace MySQL Master / Slave. Je vysoce dostupné nastavení s ProxySQL a Keepalived pro manipulaci s virtuální IP. Hlavním rizikem je nedostupnost datového centra. Je to malý DC, možná je to jen jeden ISP bez BGP. A v této situaci budeme předpokládat, že pokud by obnovení databáze trvalo hodiny, je to v pořádku, pokud je možné ji vrátit.
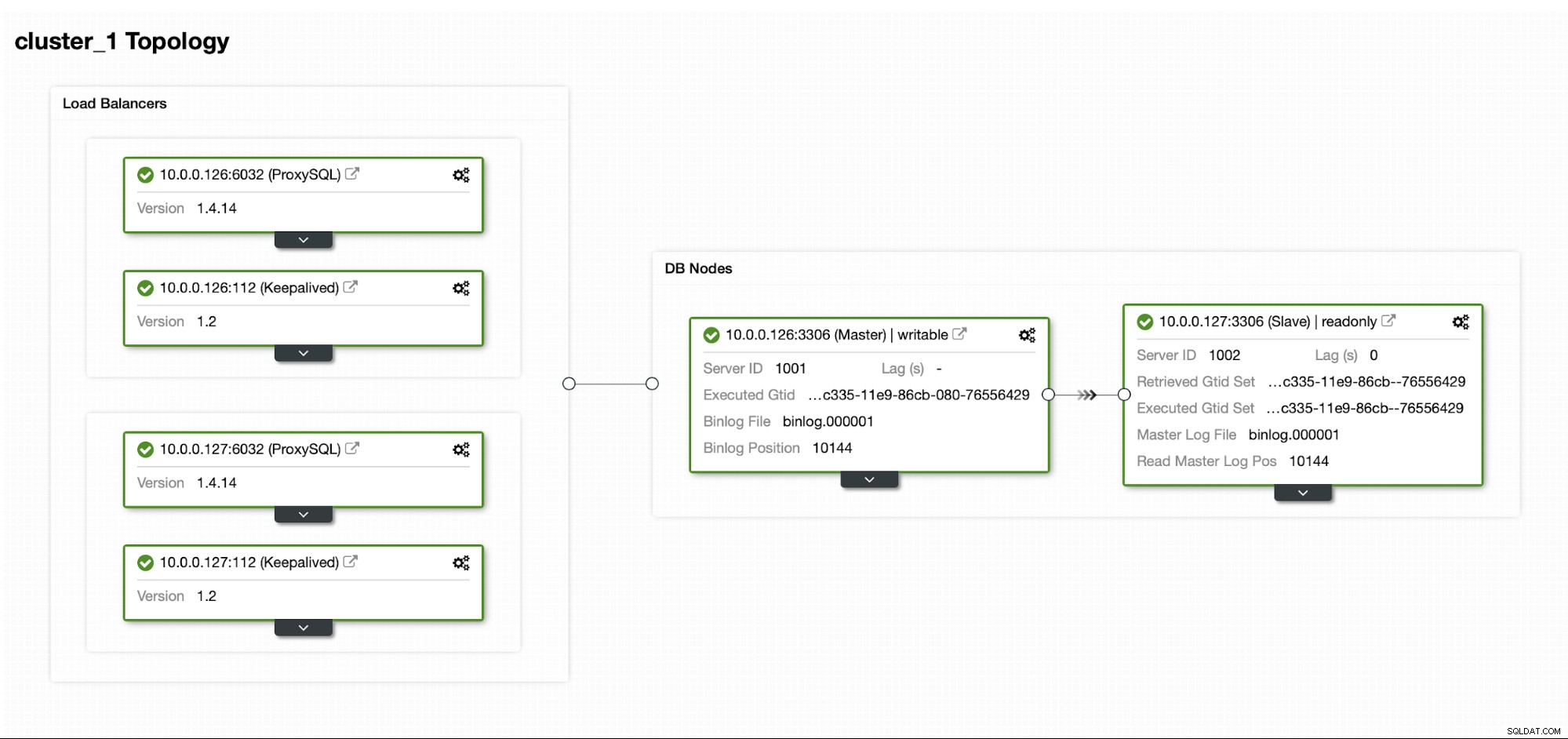
K nasazení tohoto clusteru jsme použili ClusterControl, který si můžete zdarma stáhnout. Pro naše prostředí DR použijeme EC2 (ale může to být i jakýkoli jiný poskytovatel cloudu.)
Výzva
Hlavní problém, se kterým se musíme vypořádat, je, jak bychom měli zajistit, abychom měli čerstvá data pro obnovu naší databáze v prostředí zotavení po havárii? Samozřejmě, v ideálním případě bychom měli v EC2 spuštěný replikační slave... ale pak za to musíme zaplatit. Pokud jsme napjatí na rozpočet, mohli bychom to zkusit obejít pomocí záloh. Toto není dokonalé řešení, protože v nejhorším případě nikdy nebudeme schopni obnovit všechna data.
Pojmem „nejhorší scénář“ rozumíme situaci, kdy nebudeme mít přístup k původním databázovým serverům. Pokud se k nim budeme moci dostat, data by nebyla ztracena.
Řešení
Chystáme se použít ClusterControl k nastavení plánu zálohování, abychom snížili pravděpodobnost ztráty dat. K nahrávání záloh do cloudu využijeme také funkci ClusterControl. Pokud nebude datové centrum dostupné, můžeme doufat, že vybraný cloudový poskytovatel bude dostupný.
Nastavení plánu zálohování v ClusterControl
Nejprve budeme muset nakonfigurovat ClusterControl pomocí našich cloudových přihlašovacích údajů.
Můžeme to provést pomocí „Integrace“ z nabídky na levé straně.
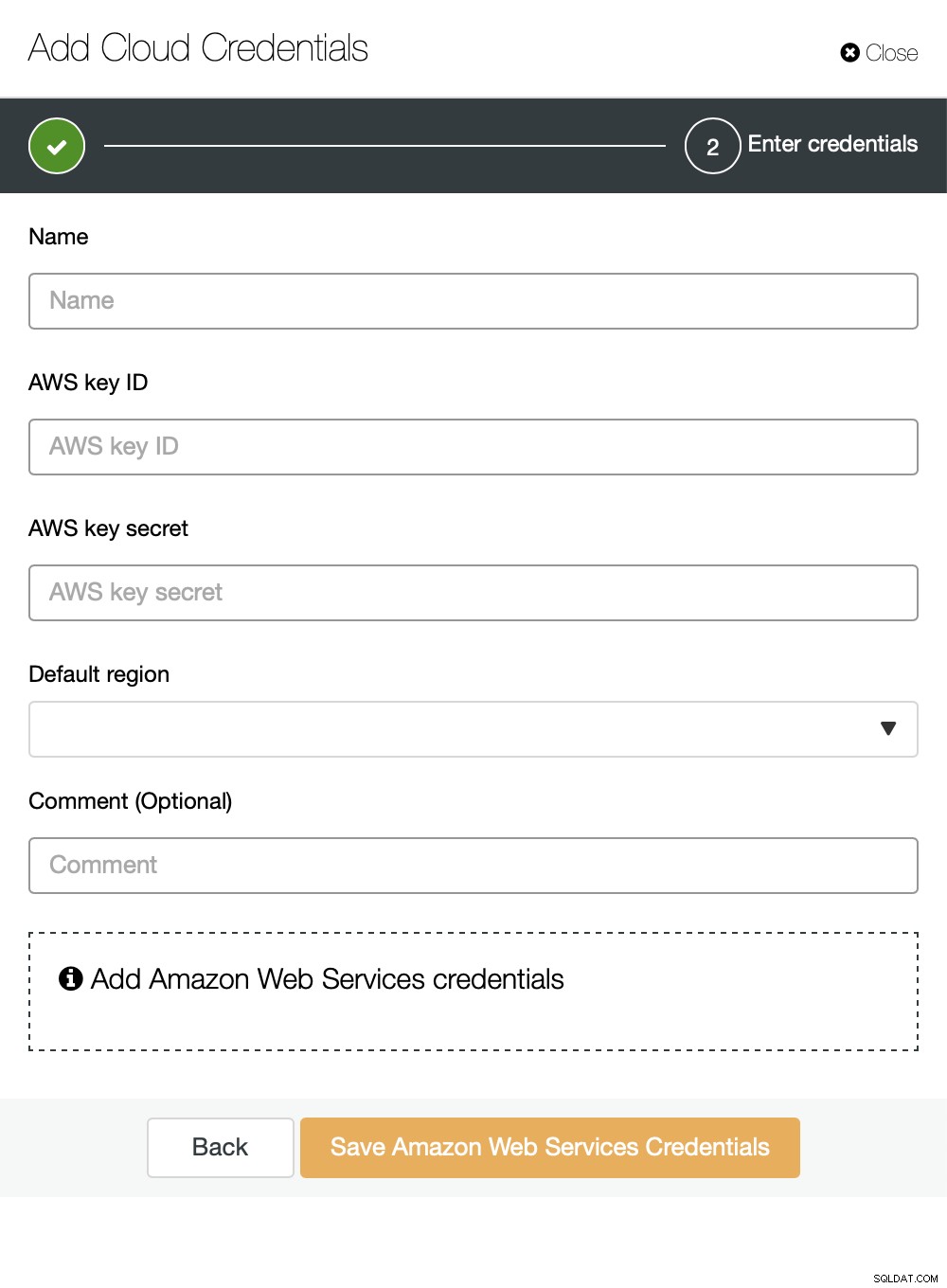
Jako cloud si můžete vybrat Amazon Web Services, Google Cloud nebo Microsoft Azure do kterého chcete ClusterControl nahrávat zálohy. Budeme pokračovat s AWS, kde ClusterControl použije S3 k ukládání záloh.
Potom musíme předat ID klíče a tajemství klíče, vybrat výchozí oblast a vyberte název pro tuto sadu přihlašovacích údajů.
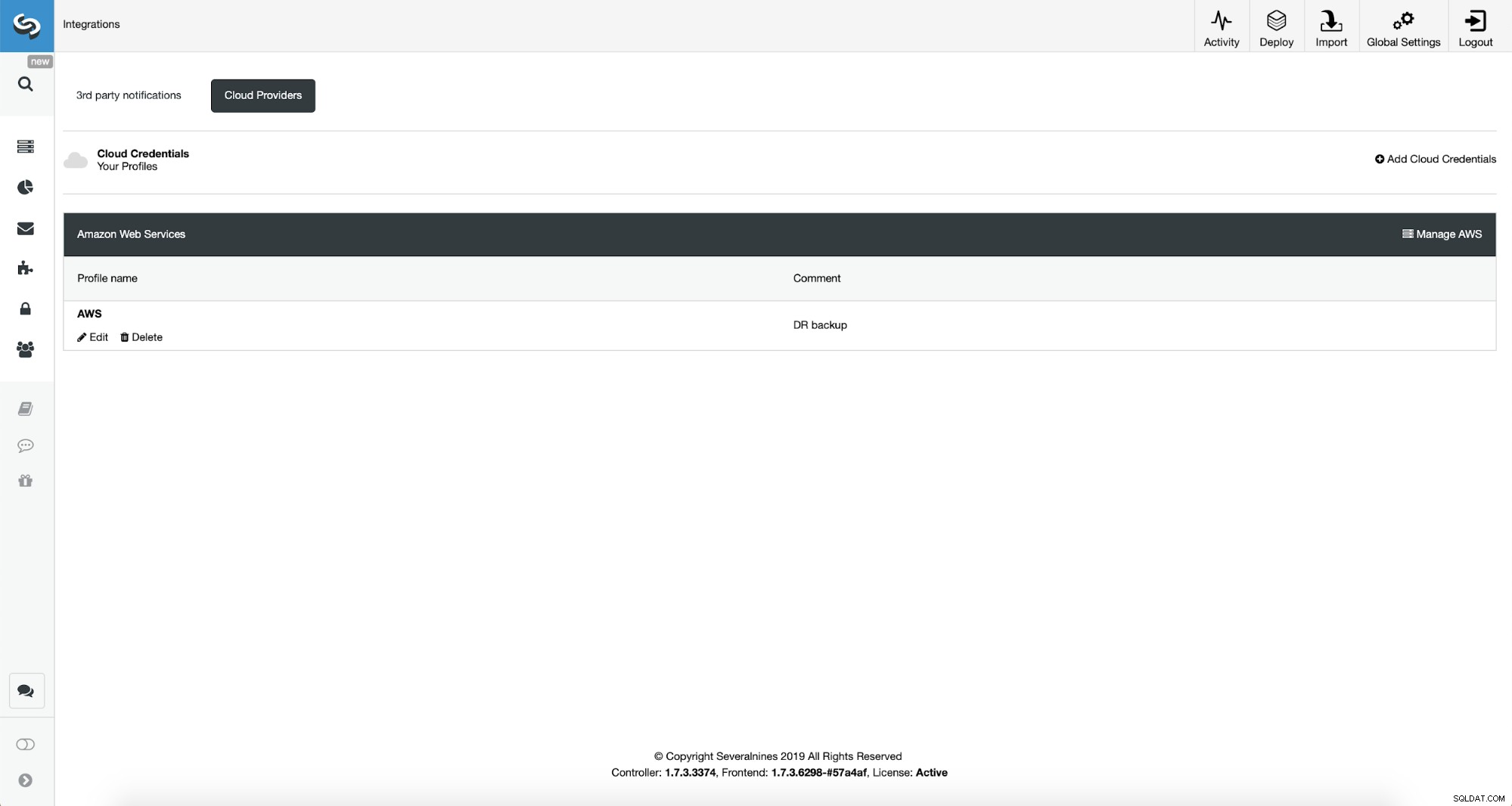
Jakmile to provedeme, můžeme vidět přihlašovací údaje, které jsme právě přidali, uvedené v ClusterControl.
Nyní budeme pokračovat v nastavení plánu zálohování.
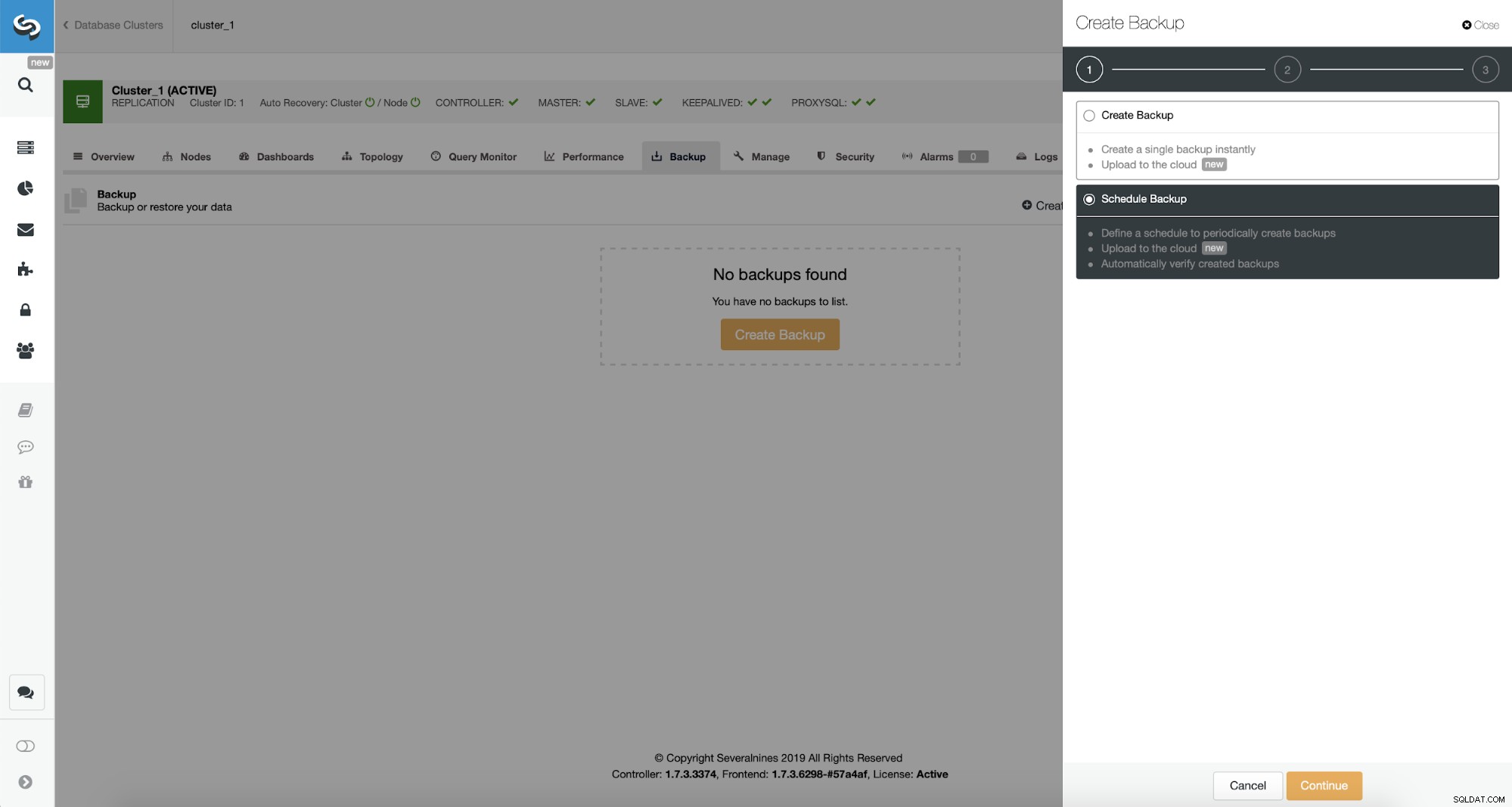
ClusterControl vám umožňuje buď vytvořit zálohu okamžitě, nebo ji naplánovat. Přistoupíme k druhé možnosti. Chceme vytvořit následující plán:
- Úplná záloha vytvořená jednou denně
- Přírůstkové zálohy vytvářené každých 10 minut.
Tato myšlenka je následující. V nejhorším případě ztratíme jen 10 minut provozu. Pokud bude datové centrum nedostupné zvenčí, ale bude fungovat interně, mohli bychom se pokusit zabránit ztrátě dat tím, že počkáme 10 minut, zkopírujeme nejnovější přírůstkovou zálohu na nějaký notebook a poté ji můžeme ručně odeslat do naší databáze DR pomocí tetheringu telefonu. a celulární připojení, které obchází selhání ISP. Pokud po nějakou dobu nebudeme schopni dostat data ze starého datového centra, má to za cíl minimalizovat množství transakcí, které budeme muset ručně sloučit do databáze DR.
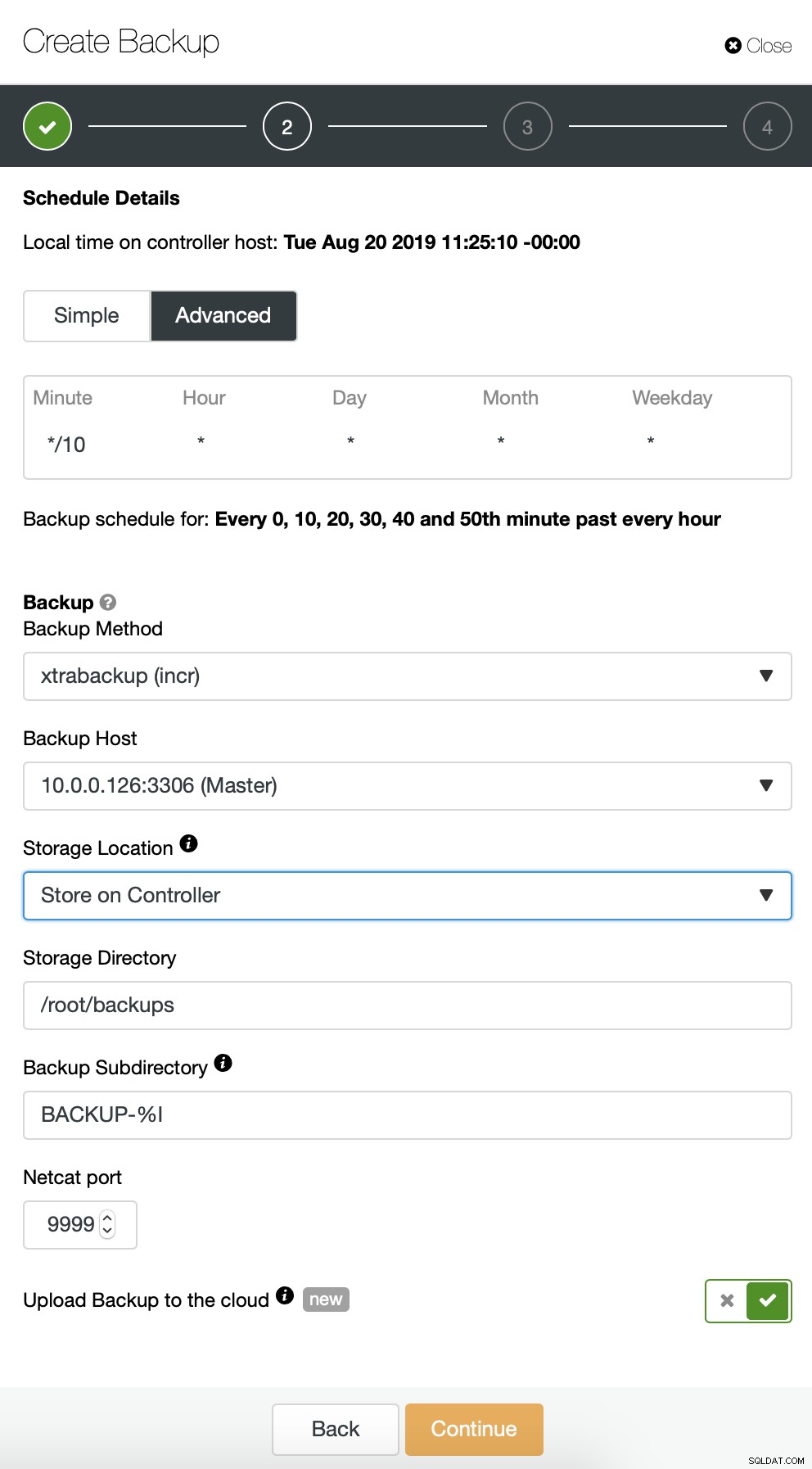
Začneme s úplnou zálohou, která bude probíhat denně ve 2:00. Pro přebírání zálohy použijeme master, uložíme ji na řadič v adresáři /root/backups/. Povolíme také možnost „Nahrát zálohu do cloudu“.
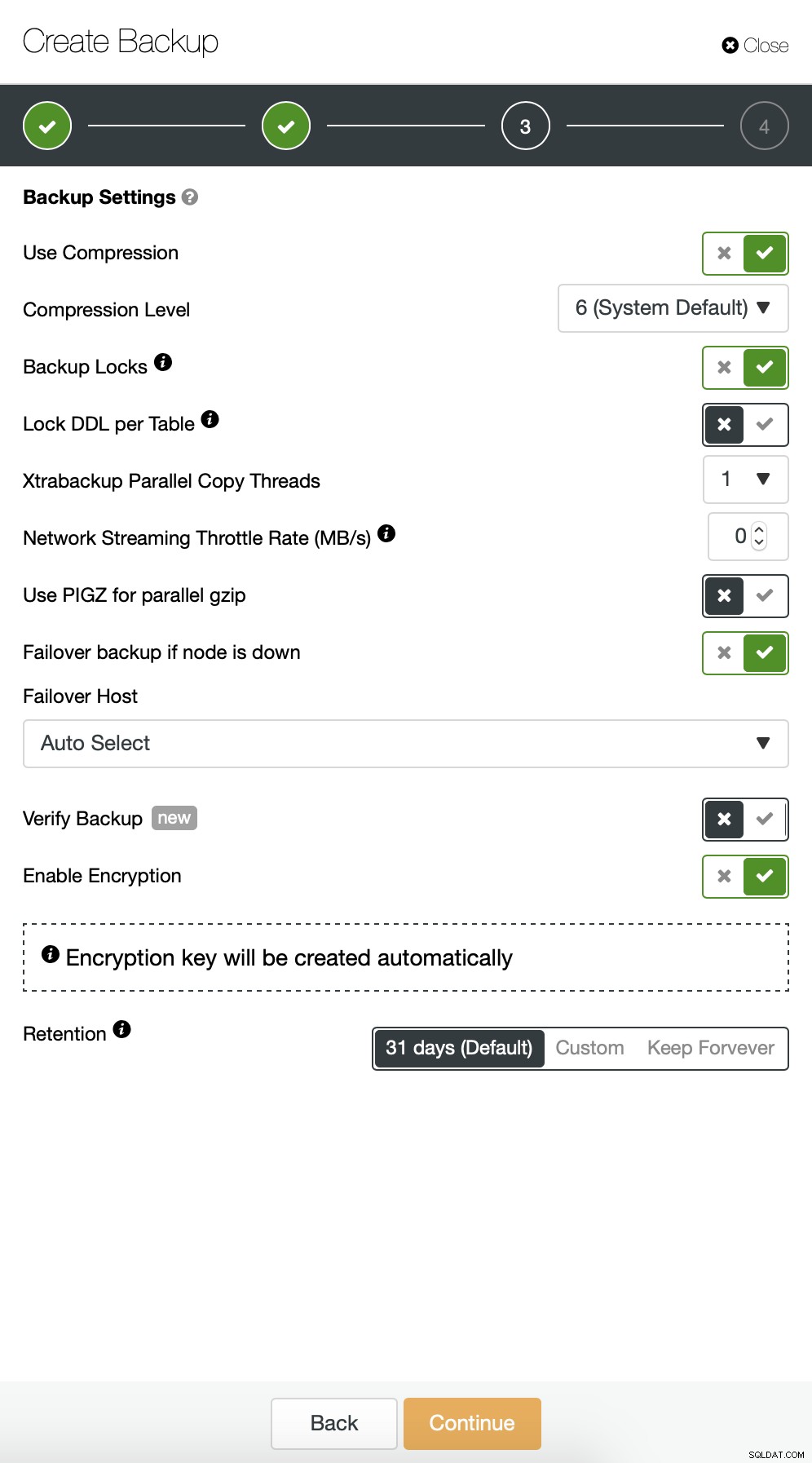
Dále chceme provést nějaké změny ve výchozí konfiguraci. Rozhodli jsme se jít s automaticky vybraným failover hostitelem (v případě, že by náš master nebyl dostupný, ClusterControl použije jakýkoli jiný dostupný uzel). Chtěli jsme také povolit šifrování, protože naše zálohy budeme posílat přes síť.
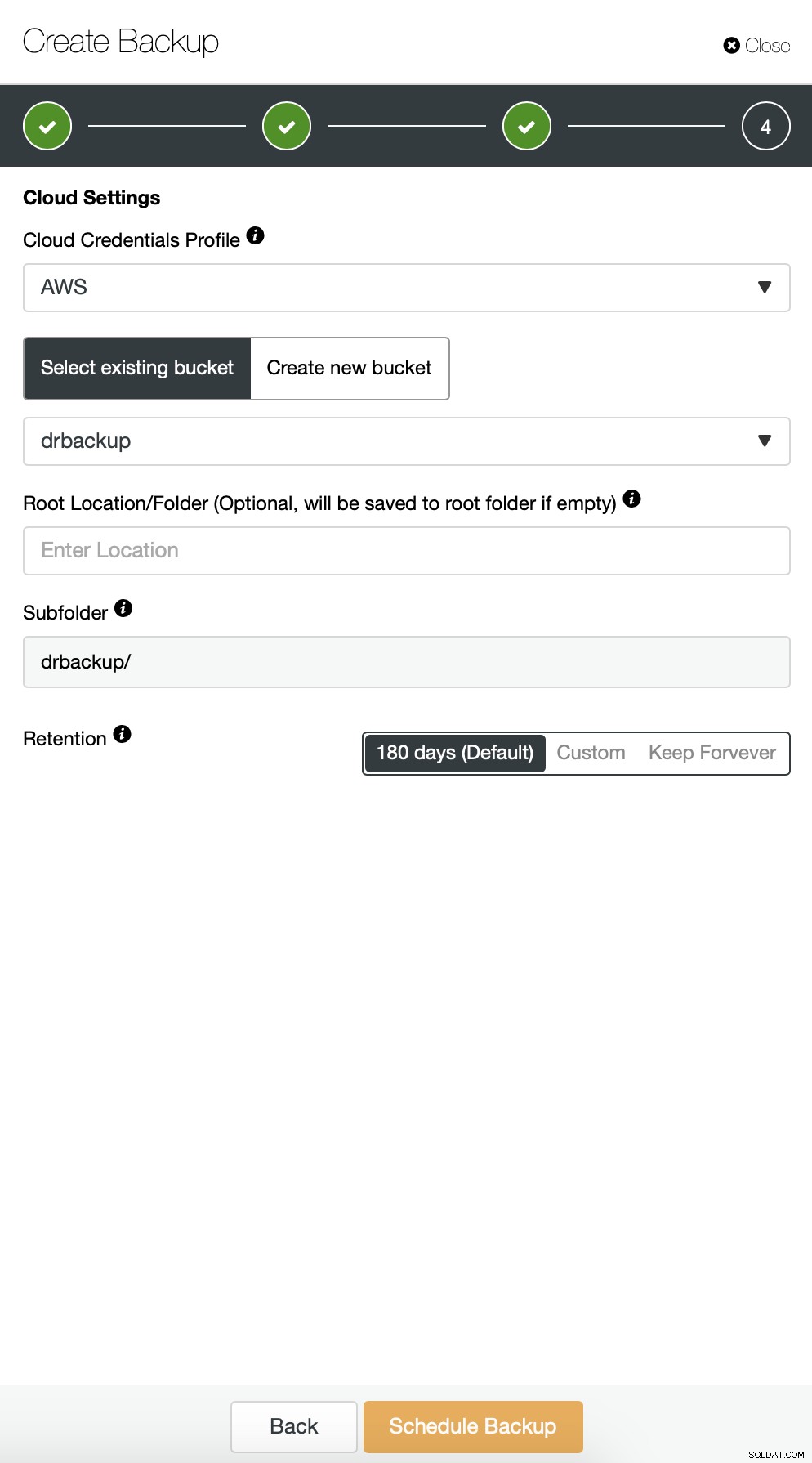
Potom musíme vybrat přihlašovací údaje, vybrat stávající segment S3 nebo vytvořit v případě potřeby nový.
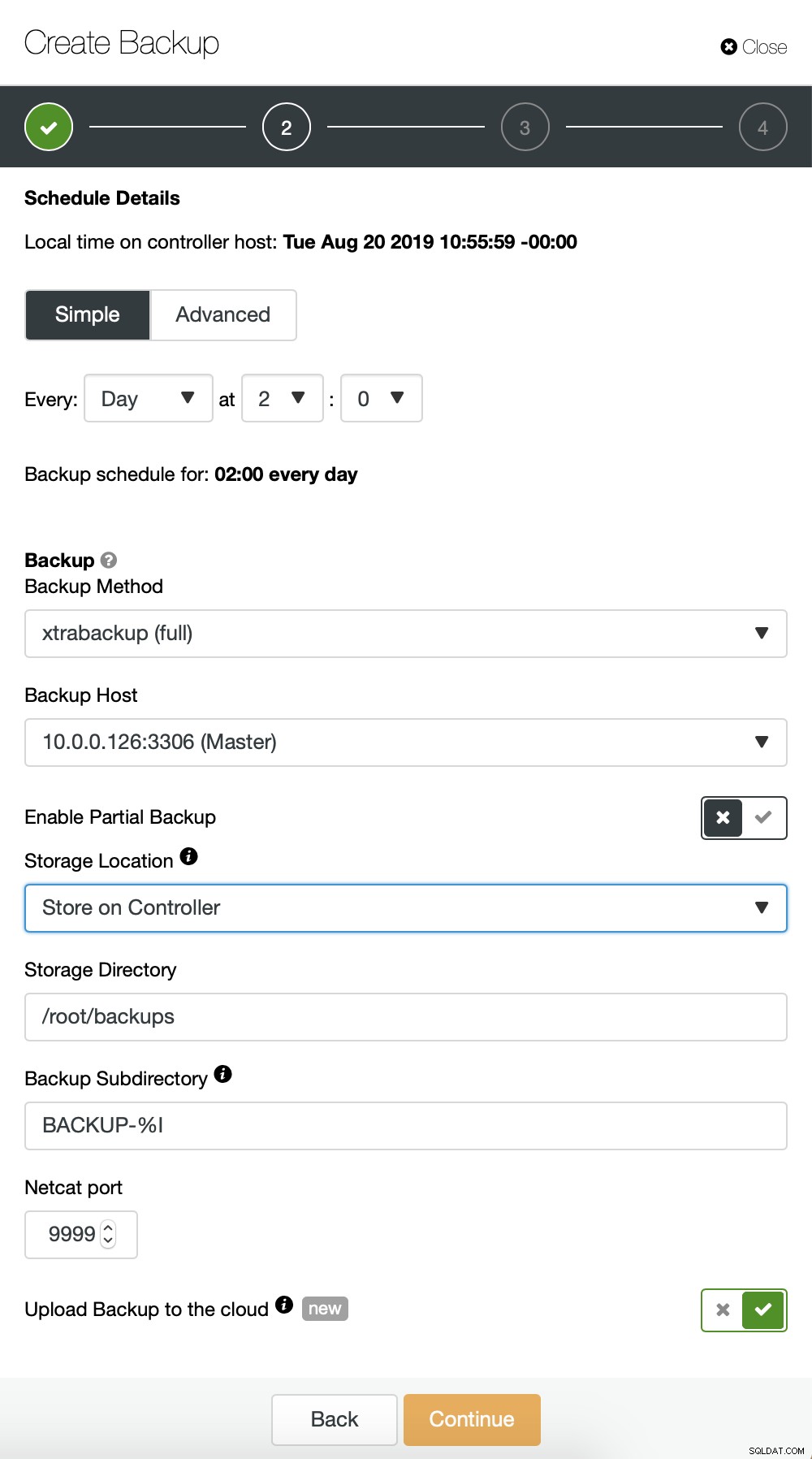
V podstatě opakujeme proces pro přírůstkové zálohování, tentokrát jsme použili dialogu „Advanced“ pro spuštění zálohování každých 10 minut.
Zbytek nastavení je podobný, můžeme také znovu použít bucket S3.
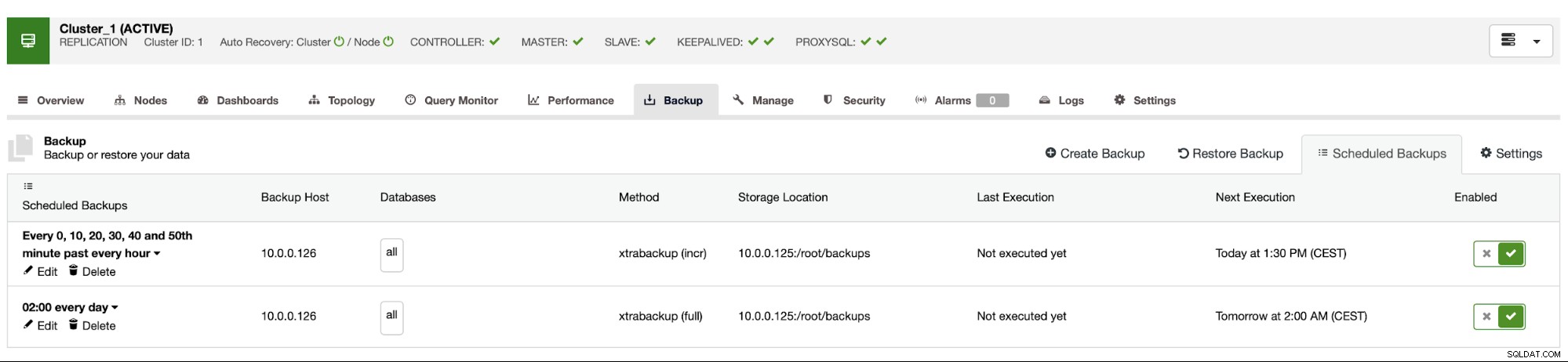
Plán zálohování vypadá jako výše. Nemusíme spouštět plnou zálohu ručně, ClusterControl spustí přírůstkové zálohování podle plánu a pokud zjistí, že není k dispozici žádná plná záloha, spustí plnou zálohu místo přírůstkové.
S takovým nastavením můžeme s jistotou říci, že můžeme obnovit data na jakémkoli externím systému s 10minutovou přesností.
Ruční obnovení zálohy
Pokud se stane, že budete muset obnovit zálohu na instanci zotavení po havárii, musíte provést několik kroků. Důrazně doporučujeme, abyste tento proces čas od času otestovali, abyste se ujistili, že funguje správně a že jste zběhlí v jeho provádění.
Nejprve musíme na náš cílový server nainstalovat nástroj příkazového řádku AWS:
example@sqldat.com:~# apt install python3-pip
example@sqldat.com:~# pip3 install awscli --upgrade --userPotom jej musíme nakonfigurovat se správnými přihlašovacími údaji:
example@sqldat.com:~# ~/.local/bin/aws configure
AWS Access Key ID [None]: yourkeyID
AWS Secret Access Key [None]: yourkeySecret
Default region name [None]: us-west-1
Default output format [None]: jsonNyní můžeme otestovat, zda máme přístup k datům v našem bucketu S3:
example@sqldat.com:~# ~/.local/bin/aws s3 ls s3://drbackup/
PRE BACKUP-1/
PRE BACKUP-2/
PRE BACKUP-3/
PRE BACKUP-4/
PRE BACKUP-5/
PRE BACKUP-6/
PRE BACKUP-7/Nyní musíme stáhnout data. Vytvoříme adresář pro zálohy – nezapomeňte, že musíme stáhnout celou sadu záloh – počínaje plnou zálohou až po poslední přírůstek, který chceme použít.
example@sqldat.com:~# mkdir backups
example@sqldat.com:~# cd backups/Nyní jsou dvě možnosti. Můžeme buď stahovat zálohy jednu po druhé:
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-1/ BACKUP-1 --recursive
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
Completed 30.4 MiB/36.2 MiB (4.9 MiB/s) with 1 file(s) remaining
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256
example@sqldat.com:~# ~/.local/bin/aws s3 cp s3://drbackup/BACKUP-2/ BACKUP-2 --recursive
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256Můžeme také, zvláště pokud máte napjatý plán rotace, synchronizovat veškerý obsah bucketu s tím, co máme lokálně na serveru:
example@sqldat.com:~/backups# ~/.local/bin/aws s3 sync s3://drbackup/ .
download: s3://drbackup/BACKUP-2/cmon_backup.metadata to BACKUP-2/cmon_backup.metadata
download: s3://drbackup/BACKUP-4/cmon_backup.metadata to BACKUP-4/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/cmon_backup.metadata to BACKUP-3/cmon_backup.metadata
download: s3://drbackup/BACKUP-6/cmon_backup.metadata to BACKUP-6/cmon_backup.metadata
download: s3://drbackup/BACKUP-5/cmon_backup.metadata to BACKUP-5/cmon_backup.metadata
download: s3://drbackup/BACKUP-7/cmon_backup.metadata to BACKUP-7/cmon_backup.metadata
download: s3://drbackup/BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 to BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/cmon_backup.metadata to BACKUP-1/cmon_backup.metadata
download: s3://drbackup/BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 to BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256
download: s3://drbackup/BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256 to BACKUP-7/backup-incr-2019-08-20_123008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256 to BACKUP-6/backup-incr-2019-08-20_122008.xbstream.gz.aes256
download: s3://drbackup/BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256 to BACKUP-5/backup-incr-2019-08-20_121007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256 to BACKUP-4/backup-incr-2019-08-20_120007.xbstream.gz.aes256
download: s3://drbackup/BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 to BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256Jak si pamatujete, zálohy jsou šifrované. Musíme mít šifrovací klíč, který je uložen v ClusterControl. Ujistěte se, že máte jeho kopii uloženou někde v bezpečí, mimo hlavní datové centrum. Pokud se k němu nedostanete, nebudete moci dešifrovat zálohy. Klíč naleznete v konfiguraci ClusterControl:
example@sqldat.com:~# grep backup_encryption_key /etc/cmon.d/cmon_1.cnf
backup_encryption_key='aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM='Je zakódována pomocí base64, takže ji musíme nejprve dekódovat a uložit do souboru, než začneme zálohu dešifrovat:
echo "aoxhIelVZr1dKv5zMbVPLxlLucuYpcVmSynaeIEeBnM=" | openssl enc -base64 -d> pass
Nyní můžeme tento soubor znovu použít k dešifrování záloh. Nyní řekněme, že provedeme jednu plnou a dvě přírůstkové zálohy.
mkdir 1
mkdir 2
mkdir 3
cat BACKUP-1/backup-full-2019-08-20_113009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/1/
cat BACKUP-2/backup-incr-2019-08-20_114009.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/2/
cat BACKUP-3/backup-incr-2019-08-20_115005.xbstream.gz.aes256 | openssl enc -d -aes-256-cbc -pass file:/root/backups/pass | zcat | xbstream -x -C /root/backups/3/Data máme dešifrovaná, nyní musíme pokračovat v nastavení našeho serveru MySQL. V ideálním případě by to měla být přesně stejná verze jako na produkčních systémech. Pro MySQL použijeme Percona Server:
cd ~
wget https://repo.percona.com/apt/percona-release_latest.generic_all.deb
sudo dpkg -i percona-release_latest.generic_all.deb
apt-get update
apt-get install percona-server-5.7Nic složitého, jen běžná instalace. Jakmile bude připraven a připraven, musíme jej zastavit a odstranit obsah jeho datového adresáře.
service mysql stop
rm -rf /var/lib/mysql/*K obnovení zálohy budeme potřebovat Xtrabackup – nástroj, který CC používá k jejímu vytvoření (alespoň pro Perona a Oracle MySQL, MariaDB používá MariaBackup). Je důležité, aby byl tento nástroj nainstalován ve stejné verzi jako na produkčních serverech:
apt install percona-xtrabackup-24To je vše, co musíme připravit. Nyní můžeme začít s obnovou zálohy. U přírůstkových záloh je důležité mít na paměti, že je musíte připravit a aplikovat na základní zálohu. Musí být také připravena záloha základny. Je důležité spustit přípravu s možností ‚--apply-log-only‘, aby xtrabackup nespustil fázi vrácení. Jinak nebudete moci použít další přírůstkovou zálohu.
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/
xtrabackup --prepare --apply-log-only --target-dir=/root/backups/1/ --incremental-dir=/root/backups/2/
xtrabackup --prepare --target-dir=/root/backups/1/ --incremental-dir=/root/backups/3/V posledním příkazu jsme umožnili xtrabackup spustit vrácení nedokončených transakcí – poté už nebudeme používat žádné další přírůstkové zálohy. Nyní je čas naplnit datový adresář zálohou, spustit MySQL a zjistit, zda vše funguje podle očekávání:
example@sqldat.com:~/backups# mv /root/backups/1/* /var/lib/mysql/
example@sqldat.com:~/backups# chown -R mysql.mysql /var/lib/mysql
example@sqldat.com:~/backups# service mysql start
example@sqldat.com:~/backups# mysql -ppass
mysql: [Warning] Using a password on the command line interface can be insecure.
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.26-29 Percona Server (GPL), Release '29', Revision '11ad961'
Copyright (c) 2009-2019 Percona LLC and/or its affiliates
Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show schemas;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| proxydemo |
| sbtest |
| sys |
+--------------------+
6 rows in set (0.00 sec)
mysql> select count(*) from sbtest.sbtest1;
+----------+
| count(*) |
+----------+
| 10506 |
+----------+
1 row in set (0.01 sec)Jak vidíte, vše je v pořádku. MySQL se spustilo správně a měli jsme k němu přístup (a data tam jsou!) Úspěšně se nám podařilo uvést naši databázi zpět do provozu na samostatném místě. Celková potřebná doba závisí striktně na velikosti dat – museli jsme data z S3 stáhnout, dešifrovat a dekomprimovat a nakonec připravit zálohu. Přesto se jedná o velmi levnou možnost (musíte platit pouze za data S3), která vám poskytuje možnost kontinuity podnikání v případě katastrofy.