Cluster Galera vynucuje silnou konzistenci dat, kde jsou všechny uzly v clusteru těsně propojeny. Přestože je podporována segmentace sítě, výkon replikace je stále vázán dvěma faktory:
-
Doba zpáteční cesty (RTT) do nejvzdálenějšího uzlu v clusteru od uzlu původce.
-
Velikost sady zápisů, která má být přenesena a certifikována pro případ konfliktu v uzlu příjemce.
I když existují způsoby, jak zvýšit výkon Galery, není možné obejít tyto dva omezující faktory.
Naštěstí byl Galera Cluster postaven na MySQL, který také přichází s vestavěnou funkcí replikace (duh!). Replikace Galera i replikace MySQL existují ve stejném serverovém softwaru nezávisle. Tyto technologie můžeme využít ke spolupráci, kdy veškerá replikace v datovém centru bude probíhat na Galeře, zatímco replikace mezi datovými centry bude probíhat na standardní replikaci MySQL. Slave server může fungovat jako hot-standby web, připravený poskytovat data, jakmile jsou aplikace přesměrovány na záložní web. Tomu jsme se věnovali v předchozím blogu o architekturách MySQL pro obnovu po havárii.
Replikace mezi clustery byla zavedena v ClusterControl ve verzi 1.7.4. V tomto příspěvku na blogu ukážeme, jak jednoduché je nastavit replikaci mezi dvěma clustery Galera (PXC 8.0). Poté se podíváme na náročnější část:řešení poruch na úrovni uzlů i clusteru pomocí ClusterControl; Operace převzetí služeb při selhání a navrácení služeb při selhání jsou zásadní pro zachování integrity dat v celém systému.
Nasazení clusteru
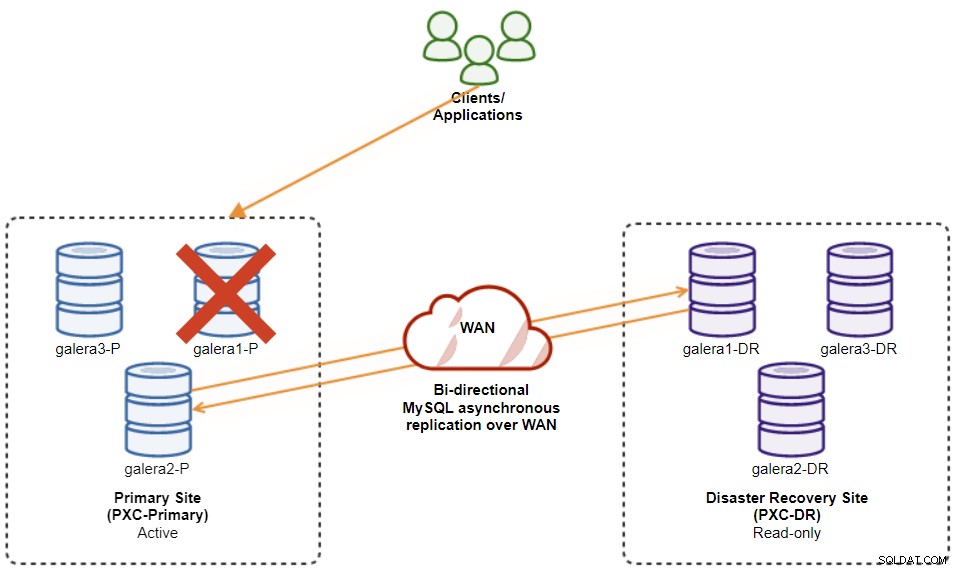
Pro náš příklad budeme potřebovat alespoň dva clustery a dva weby – jeden pro primární a druhý pro sekundární. Funguje podobně jako tradiční replikace MySQL master-slave, ale ve větším měřítku se třemi databázovými uzly na každém místě. S ClusterControl toho dosáhnete nasazením primárního klastru a následným nasazením sekundárního klastru na webu pro obnovu po havárii jako replikovaného klastru, replikovaného obousměrnou asynchronní replikací.
Následující diagram znázorňuje naši konečnou architekturu:

Máme celkem šest uzlů databáze, tři na primárním webu a další tři na webu zotavení po havárii. Pro zjednodušení reprezentace uzlů použijeme následující zápisy:
-
Primární web:
-
galera1-P – 192.168.11.171 (master)
-
galera2-P – 192.168.11.172
-
galera3-P – 192.168.11.173
-
-
Místo obnovy po havárii:
-
galera1-DR – 192.168.11.181 (slave)
-
galera2-DR – 192.168.11.182
-
galera3-DR – 192.168.11.183
-
Nejprve jednoduše nasaďte první cluster a nazýváme ho PXC-Primary. Otevřete uživatelské rozhraní ClusterControl → Deploy → MySQL Galera a zadejte všechny požadované podrobnosti:
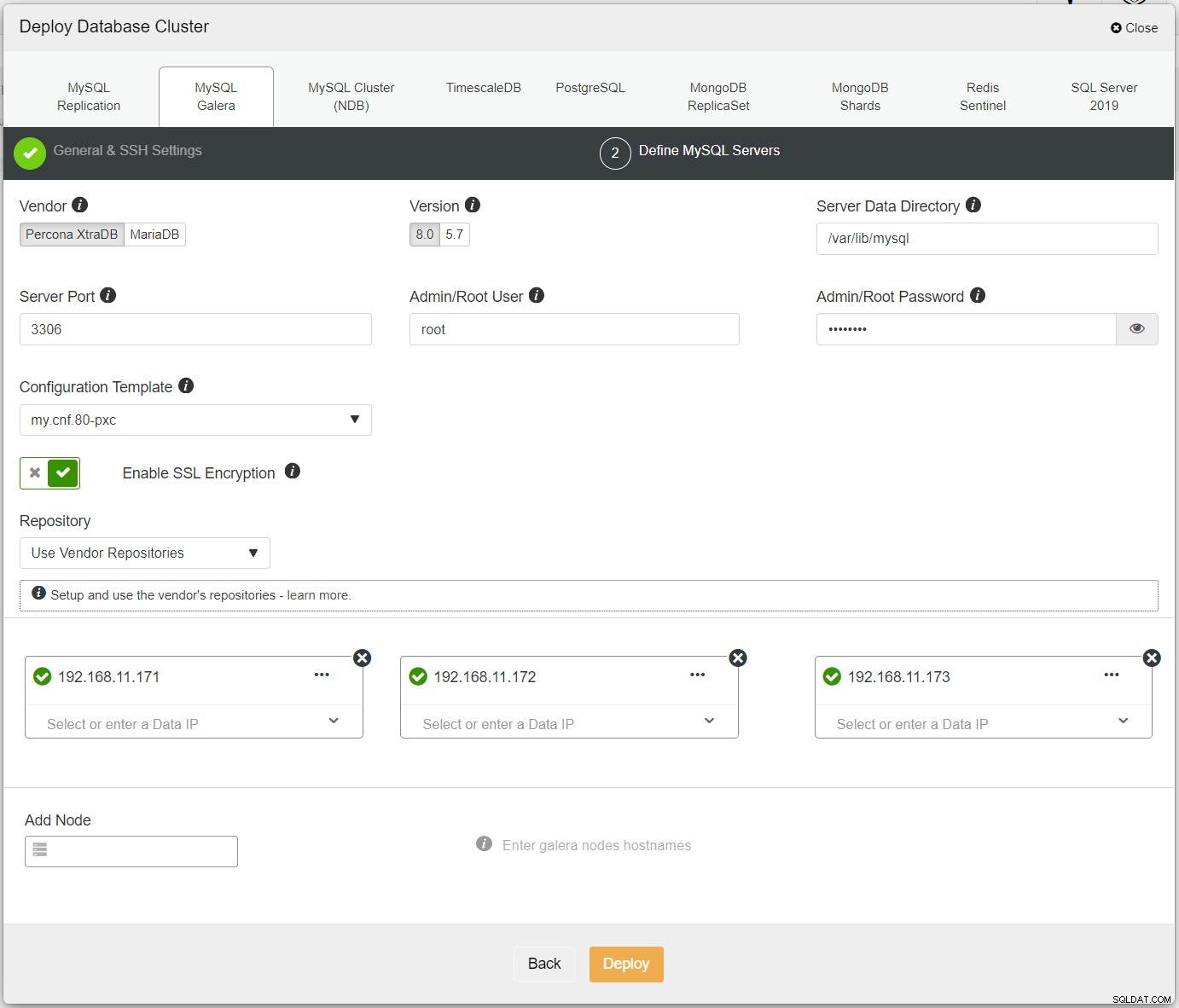
Ujistěte se, že každý zadaný uzel má vedle sebe zelené zaškrtnutí, což znamená, že ClusterControl se může připojit k hostiteli přes SSH bez hesla. Klikněte na Nasadit a počkejte na dokončení nasazení. Po dokončení byste měli vidět následující cluster uvedený na stránce řídicího panelu clusteru:
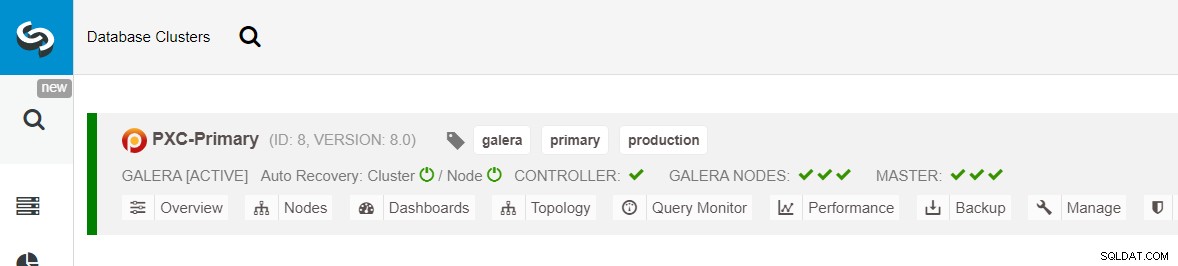
Dále použijeme funkci ClusterControl s názvem Create Replica Cluster, která je dostupná z rozevírací nabídka Akce clusteru:
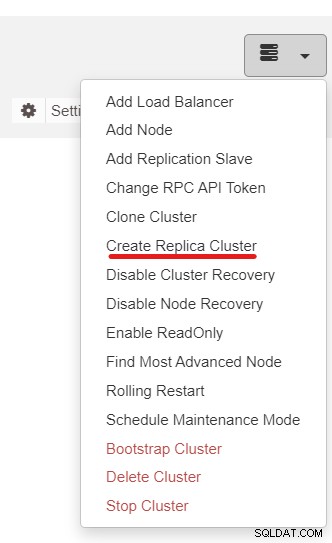
Zobrazí se následující vyskakovací okno postranního panelu:
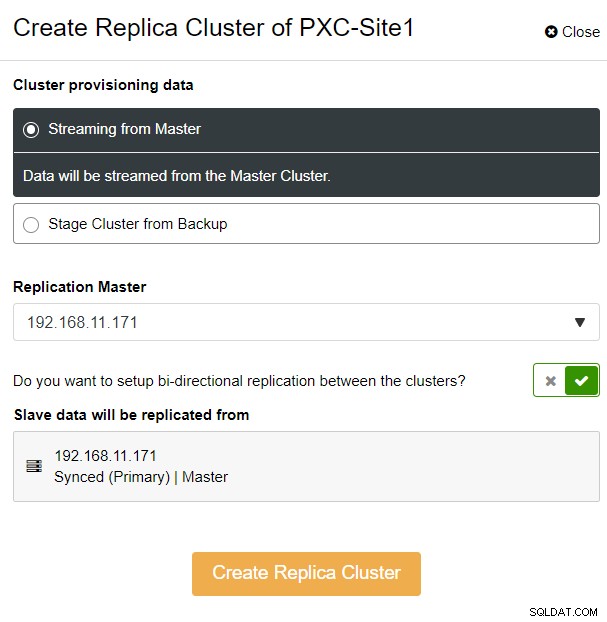
Zvolili jsme možnost „Streaming from Master“, kde ClusterControl použije vybraný master pro synchronizaci replikovaného klastru a konfiguraci replikace. Věnujte pozornost možnosti obousměrné replikace. Pokud je povoleno, ClusterControl nastaví obousměrnou replikaci mezi oběma místy (kruhová replikace). Vybraný hlavní server se bude replikovat z prvního hlavního serveru definovaného pro replikační cluster a naopak. Toto nastavení minimalizuje dobu potřebnou k přípravě při obnově po převzetí služeb při selhání nebo navrácení po selhání. Klikněte na „Vytvořit replikační cluster“, kde ClusterControl otevře nového průvodce nasazením pro replikovaný cluster, jak je znázorněno níže:
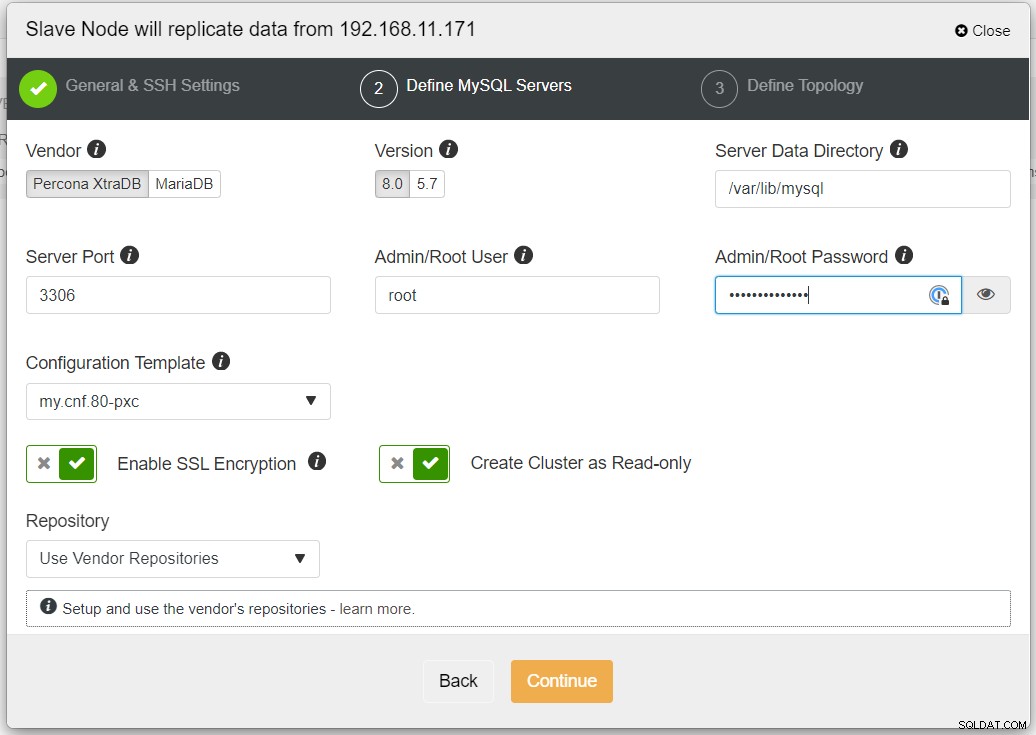
Pokud replikace zahrnuje nedůvěryhodné sítě, jako je WAN, doporučujeme povolit šifrování SSL, netunelované sítě nebo internet. Také se ujistěte, že je přepnuto "Vytvořit cluster jako pouze pro čtení"; toto je ochrana proti náhodnému zápisu a dobrý indikátor pro snadné rozlišení mezi aktivním clusterem (čtení-zápis) a pasivním clusterem (pouze pro čtení).
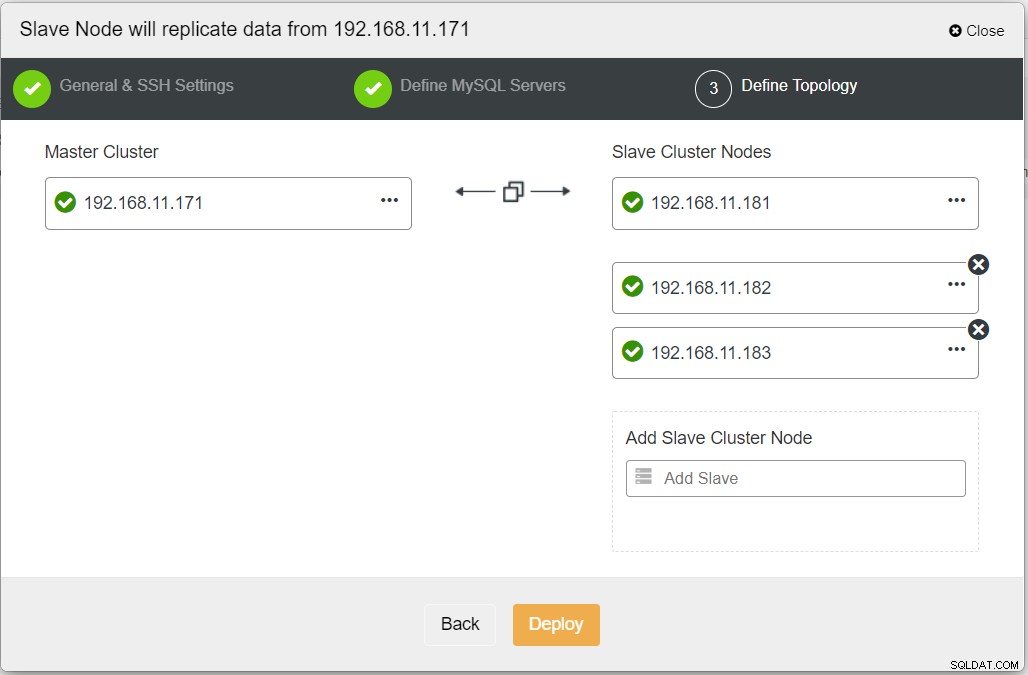
Při vyplňování všech nezbytných informací byste se měli dostat do následující fáze k definování topologie replikovaného clusteru:
Po dokončení nasazení byste na řídicím panelu ClusterControl měli vidět Web DR má obousměrnou šipku spojenou s primárním webem:
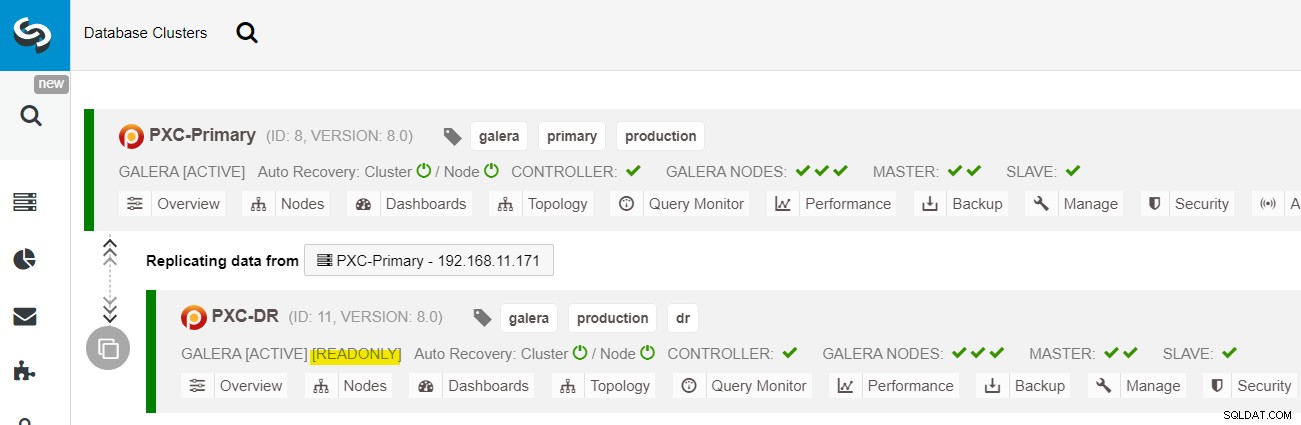
Nasazení je nyní dokončeno. Aplikace by měly odesílat zápisy pouze na primární web, protože toto je aktivní web a web DR je nakonfigurován pouze pro čtení (zvýrazněno žlutě). Čtení lze odesílat na oba weby, ačkoli u webu DR hrozí, že bude zaostávat kvůli povaze asynchronní replikace. Toto nastavení způsobí, že primární a servery pro obnovu po havárii budou na sobě nezávislé a budou volně propojeny s asynchronní replikací. Jeden z uzlů Galera v lokalitě DR bude slave, který se replikuje z jednoho z uzlů Galera (master) v primární lokalitě.
Nyní máme systém, kde selhání clusteru na primárním webu neovlivní záložní web. Z hlediska výkonu nebude mít latence WAN vliv na aktualizace v aktivním clusteru. Ty jsou odesílány asynchronně na místo zálohování.
Jako vedlejší poznámku, je také možné mít vyhrazenou podřízenou instanci jako replikační relé namísto použití jednoho z uzlů Galera jako podřízeného.
Procedura převzetí služeb při selhání uzlu Galera
V případě, že aktuální hlavní server (galera1-P) selže a zbývající uzly na primárním serveru jsou stále aktivní, měl by být podřízený server na webu pro obnovu po havárii (galera1-DR) přesměrován na všechny dostupné hlavní servery na primárním webu, jak ukazuje následující diagram:
Ze seznamu clusterů ClusterControl můžete vidět, že stav clusteru je snížen a pokud přejedete myší na ikonu vykřičníku, uvidíte chybu pro daný uzel (galera1-P):
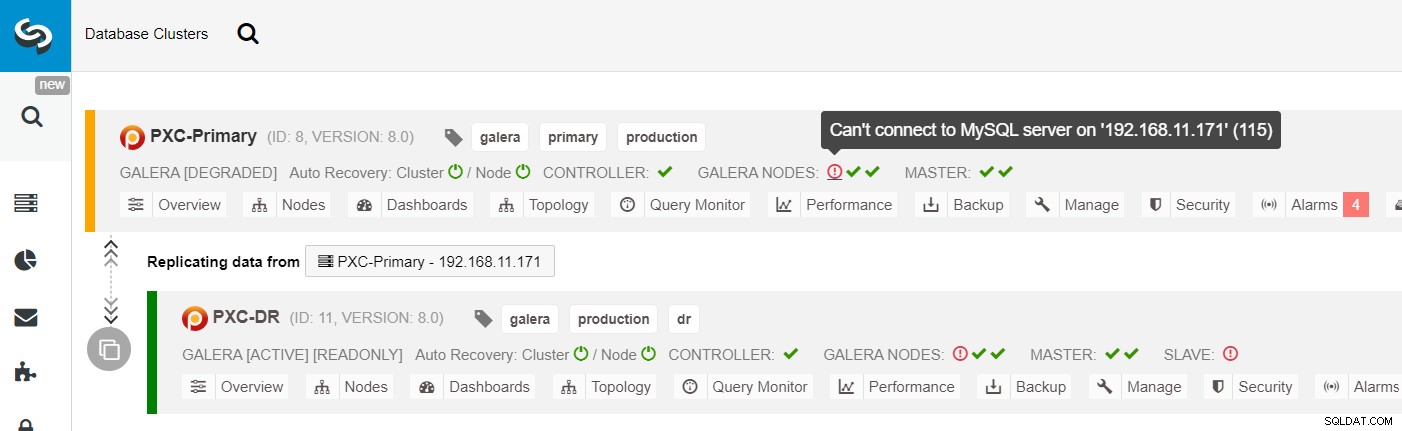
S ClusterControl můžete jednoduše přejít do PXC-DR cluster → Nodes → vybrat galera1-DR → Node Actions → Rebuild Replication Slave a zobrazí se vám následující konfigurační dialog:
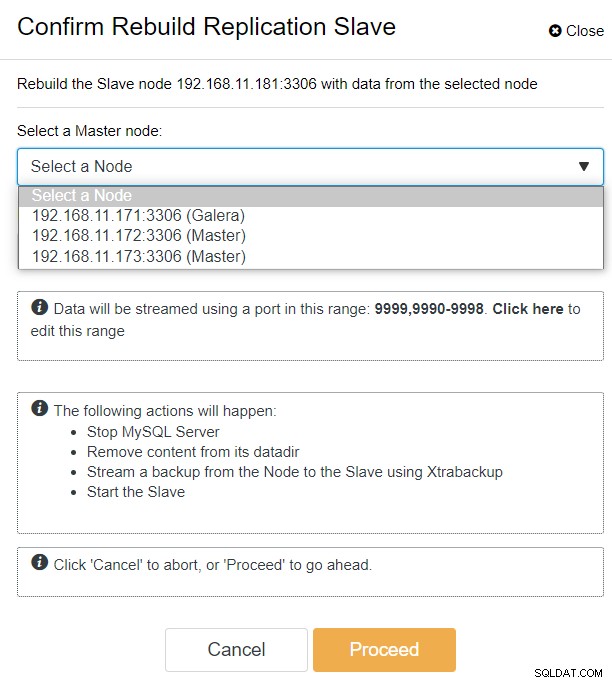
Můžeme vidět všechny uzly Galera na primárním webu (192.168.11.17x ) z rozevíracího seznamu. Vyberte sekundární uzel 192.168.11.172 (galera2-P) a klikněte na Pokračovat. ClusterControl poté nakonfiguruje topologii replikace tak, jak má být, a nastaví obousměrnou replikaci z galera2-P na galera1-DR. Můžete to potvrdit na stránce řídicího panelu clusteru (zvýrazněno žlutě):
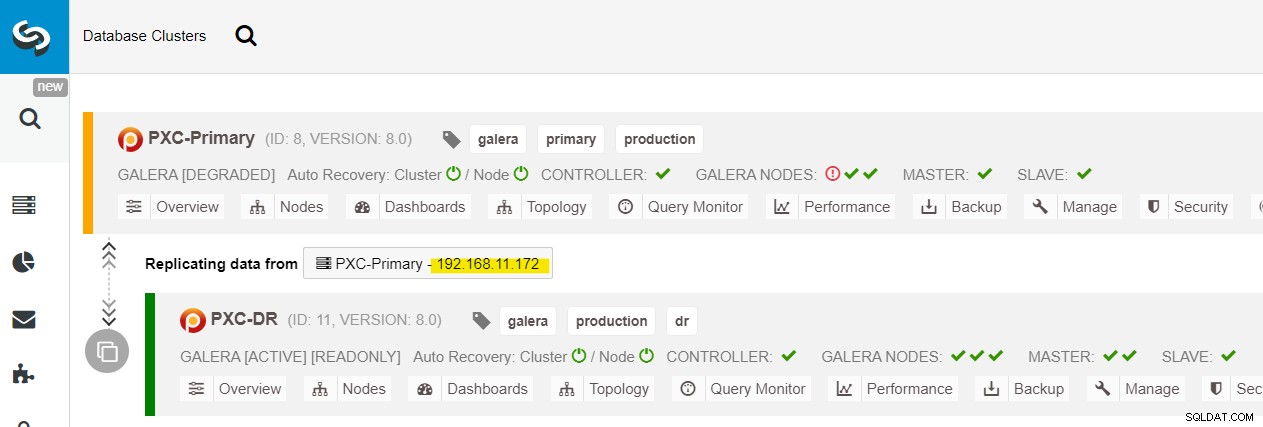
V tuto chvíli primární cluster (PXC-Primary) stále funguje jako aktivní cluster pro tuto topologii. Nemělo by to mít vliv na dobu provozu databázových služeb primárního klastru.
Postup při selhání clusteru Galera
Pokud primární cluster selže, zhroutí se nebo jednoduše ztratí konektivitu z hlediska aplikace, aplikace může být přesměrována na web DR téměř okamžitě. SysAdmin jednoduše potřebuje zakázat pouze čtení na všech uzlech Galera na webu obnovy po havárii pomocí následujícího příkazu:
mysql> SET GLOBAL read_only = 0; -- repeat on galera1-DR, galera2-DR, galera3-DRPro uživatele ClusterControl můžete použít ClusterControl UI → Nodes → vybrat uzel DB → Node Actions → Disable Read-only. K dispozici je také rozhraní ClusterControl CLI provedením následujících příkazů v uzlu ClusterControl:
$ s9s node --nodes="192.168.11.181" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.182" --cluster-id=11 --set-read-write
$ s9s node --nodes="192.168.11.183" --cluster-id=11 --set-read-writePřechod při selhání na web DR je nyní dokončen a aplikace mohou začít odesílat zápisy do clusteru PXC-DR. V uživatelském rozhraní ClusterControl byste měli vidět něco takového:
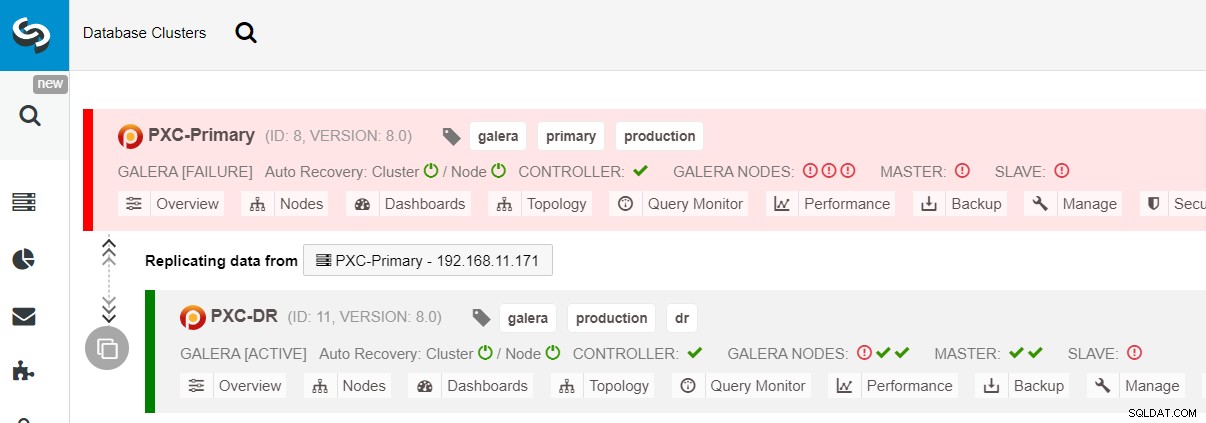
Následující diagram ukazuje naši architekturu po selhání aplikace na web DR :
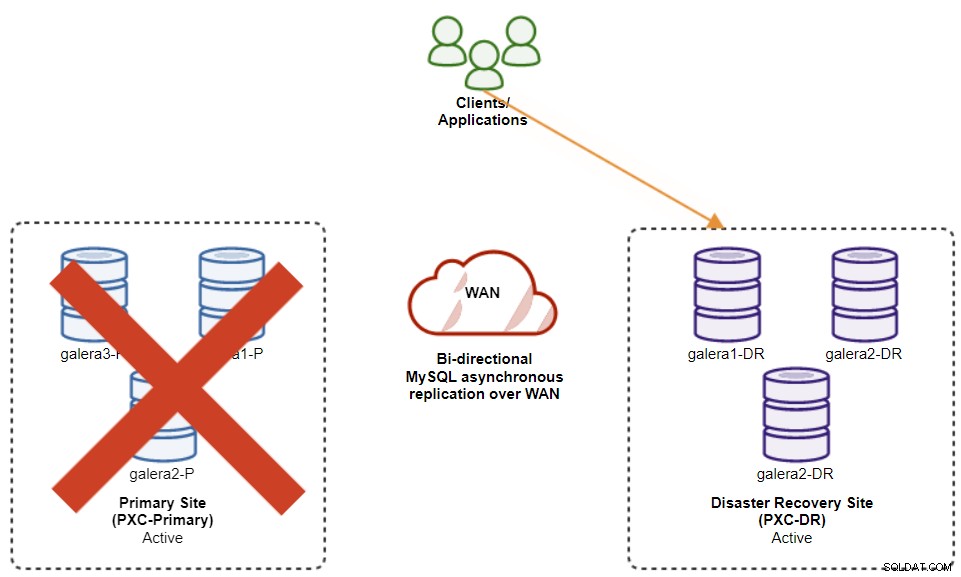
Za předpokladu, že primární web je stále mimo provoz, v tuto chvíli neexistuje replikace mezi lokalitami, dokud se primární lokalita nevrátí.
Postup při selhání clusteru Galera
Po spuštění primárního webu je důležité poznamenat, že primární cluster musí být nastaven na pouze pro čtení, takže víme, že aktivním clusterem je cluster na webu pro obnovu po havárii. Z ClusterControl přejděte do rozevírací nabídky clusteru a zvolte „Povolit pouze pro čtení“, což povolí pouze pro čtení na všech uzlech v primárním clusteru a shrnuje aktuální topologii, jak je uvedeno níže:
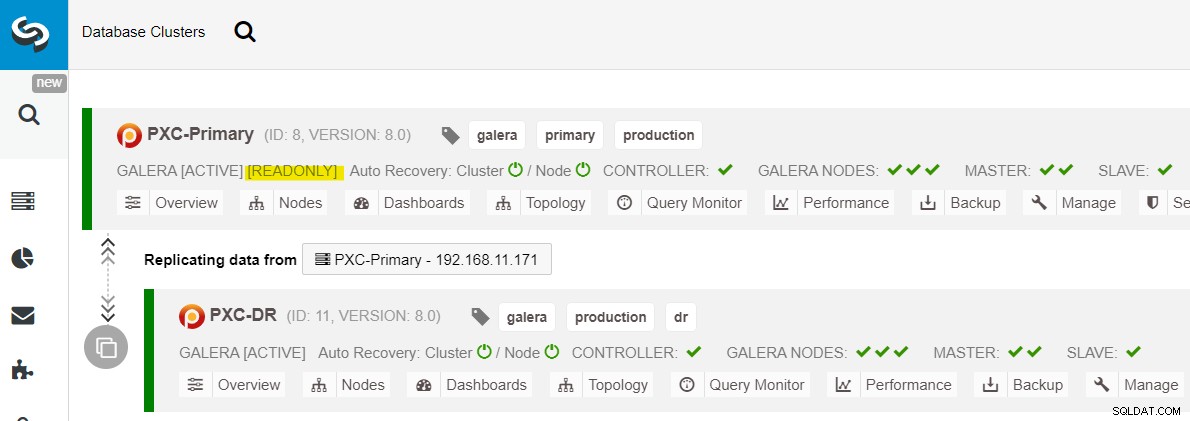
Před plánováním spuštění procedury obnovení klastru se ujistěte, že je vše zelené (zelené znamená, že všechny uzly jsou aktivní a vzájemně synchronizované). Pokud je uzel ve zhoršujícím se stavu, například replikující se uzel stále zaostává nebo byly dosažitelné pouze některé z uzlů v primárním clusteru, počkejte, dokud se cluster plně neobnoví, buď čekáním na automatické obnovovací postupy ClusterControl. dokončit nebo ruční zásah.
V tomto okamžiku je aktivním clusterem stále cluster DR a primární cluster funguje jako sekundární. Následující diagram znázorňuje aktuální architekturu:
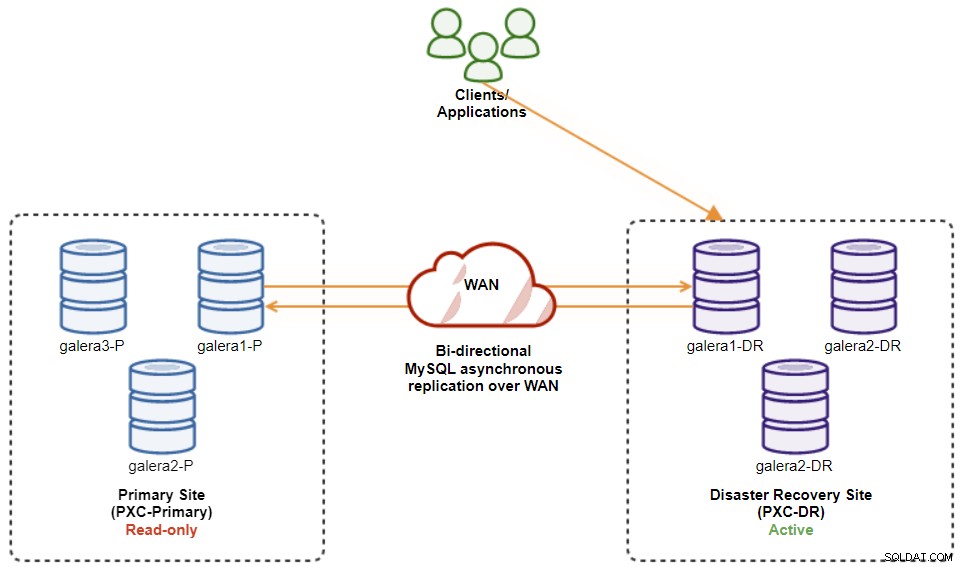
Nejbezpečnějším způsobem obnovení na primární web je nastavení pouze pro čtení na clusteru DR a následně deaktivace pouze pro čtení na primárním webu. Přejděte do uživatelského rozhraní ClusterControl → PXC-DR (rozbalovací nabídka) → Povolit pouze pro čtení. To spustí úlohu, která nastaví pouze pro čtení na všech uzlech v clusteru DR. Poté přejděte do uživatelského rozhraní ClusterControl → PXC-Primary → Nodes a zakažte pouze pro čtení na všech databázových uzlech v primárním clusteru.
Výše uvedené postupy můžete také zjednodušit pomocí rozhraní ClusterControl CLI. Případně spusťte následující příkazy na hostiteli ClusterControl:
$ s9s cluster --cluster-id=11 --set-read-only # enable cluster-wide read-only
$ s9s node --nodes="192.168.11.171" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.172" --cluster-id=8 --set-read-write
$ s9s node --nodes="192.168.11.173" --cluster-id=8 --set-read-writePo dokončení se směr replikace vrátí zpět do původní konfigurace, kde PXC-Primary je aktivní cluster a PXC-DR je záložní cluster. Následující diagram znázorňuje konečnou architekturu po operaci navrácení služeb při selhání clusteru:
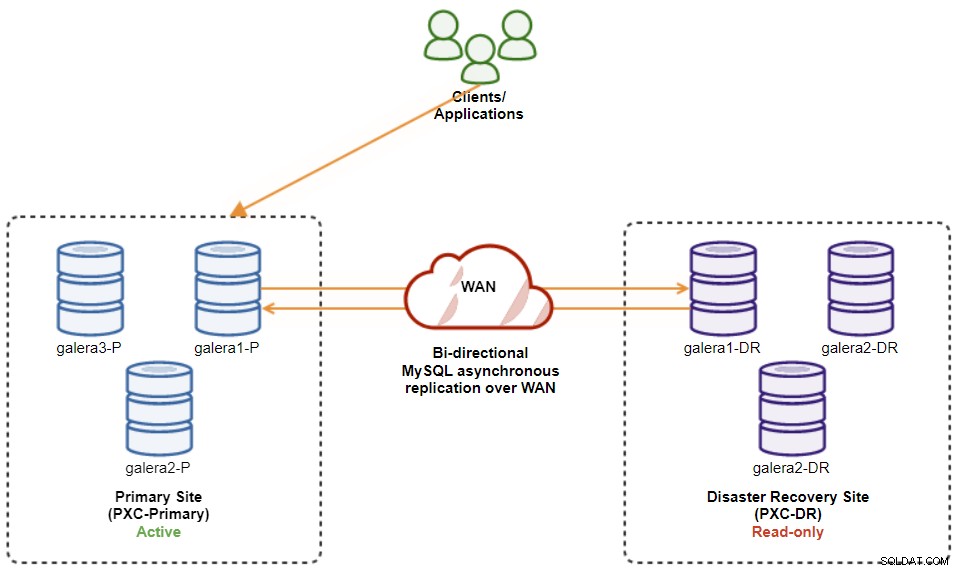
V tuto chvíli je nyní bezpečné přesměrovat aplikace, na které lze zapisovat primární web.
Výhody asynchronní replikace cluster-to-cluster
Cluster-to-cluster s asynchronní replikací přináší řadu výhod:
-
Minimální prostoje během operace převzetí služeb při selhání databáze. V zásadě můžete zápis přesměrovat téměř okamžitě na podřízený web, pouze pokud můžete chránit zápisy, aby se nedostaly na hlavní web (protože tyto zápisy by nebyly replikovány a pravděpodobně budou přepsány při opětovné synchronizaci z webu DR).
-
Žádný dopad na výkon primárního webu, protože je nezávislý na záložním (DR) webu. Replikace z master na slave se provádí asynchronně. Hlavní web generuje binární protokoly, podřízený web replikuje události a aplikuje je později.
-
Stránky pro obnovu po havárii lze použít k jiným účelům, například k zálohování databáze, zálohování binárních protokolů a vytváření sestav, nebo těžké analytické dotazy (OLAP). Obě místa lze používat současně, s výjimkou zpoždění replikace a operací pouze pro čtení na podřízené straně.
-
Cluster DR by mohl potenciálně běžet na menších instancích v prostředí veřejného cloudu, pokud mohou držet krok s primárním clusterem. V případě potřeby můžete upgradovat instance. V určitých scénářích vám to může ušetřit nějaké náklady.
-
Pro zotavení po havárii potřebujete pouze jeden web navíc ve srovnání s nastavením replikace více webů Galera, které ke správnému fungování vyžaduje alespoň tři aktivní weby.
Nevýhody asynchronní replikace cluster-to-cluster
Toto nastavení má také své nevýhody v závislosti na tom, zda používáte obousměrnou nebo jednosměrnou replikaci:
-
Je možné, že během převzetí služeb při selhání budou chybět některá data, pokud byl slave pozadu, protože replikace je asynchronní. To by se dalo zlepšit semisynchronní a vícevláknovou replikací podřízených jednotek, i když zde bude čekat další řada problémů (režie sítě, mezera v replikaci atd.).
-
U jednosměrné replikace mohou být procedury obnovení služeb při selhání, přestože jsou procedury převzetí služeb při selhání poměrně jednoduché, složité a náchylné k lidskému chyba. Vyžaduje to určité znalosti o přepínání role master/slave zpět na primární místo. Doporučuje se uchovávat postupy zdokumentované, pravidelně nacvičovat operace převzetí služeb při selhání/obnovení selhání a používat přesné nástroje pro vytváření zpráv a monitorování.
-
Může to být docela nákladné, protože na webu pro obnovu po havárii musíte nastavit podobný počet uzlů . Není to černobílé, protože zdůvodnění nákladů obvykle vychází z požadavků vašeho podnikání. S určitým plánováním je možné maximalizovat využití databázových zdrojů na obou místech, bez ohledu na databázové role.
Zabalení
Nastavení asynchronní replikace pro vaše clustery MySQL Galera Clusters může být relativně přímočarý proces – pokud rozumíte tomu, jak správně ošetřit selhání na úrovni uzlu i clusteru. V konečném důsledku jsou operace převzetí služeb při selhání a navrácení služeb při selhání zásadní pro zajištění integrity dat.
Další tipy pro navrhování clusterů Galera s ohledem na strategie převzetí služeb při selhání a navrácení služeb při selhání naleznete v tomto příspěvku o architekturách MySQL pro zotavení po havárii. Pokud hledáte pomoc s automatizací těchto operací, vyzkoušejte ClusterControl zdarma na 30 dní a postupujte podle kroků v tomto příspěvku.
Nezapomeňte nás sledovat na Twitteru nebo LinkedIn a přihlaste se k odběru našeho newsletteru, zůstaňte informováni o nejnovějších zprávách a osvědčených postupech pro správu vašich databázových infrastruktur s otevřeným zdrojovým kódem.