V tomto blogovém příspěvku budeme analyzovat 6 různých scénářů selhání v produkčních databázových systémech, od problémů s jedním serverem až po plány převzetí služeb při selhání více datových center. Provedeme vás postupy obnovy a převzetí služeb při selhání pro příslušný scénář. Doufejme, že vám to umožní dobře porozumět rizikům, kterým můžete čelit, a věcem, které je třeba vzít v úvahu při navrhování infrastruktury.
Schéma databáze je poškozena
Začněme instalací jednoho uzlu – nastavením databáze v té nejjednodušší podobě. Snadná implementace za nejnižší cenu. V tomto scénáři spouštíte více aplikací na jediném serveru, kde každé ze schémat databáze patří jiné aplikaci. Přístup k obnově jednoho schématu by závisel na několika faktorech.
- Mám nějakou zálohu?
- Mám zálohu a jak rychle ji mohu obnovit?
- Jaký typ úložiště se používá?
- Mám zálohu kompatibilní s PITR (obnovení v určitém okamžiku)?
Poškození dat lze identifikovat pomocí mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Nahraďte DATABASE názvem databáze a TABLE nahraďte názvem tabulky, kterou chcete zkontrolovat:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck zkontroluje zadanou databázi a tabulky. Pokud tabulka projde kontrolou, mysqlcheck pro tabulku zobrazí OK. V níže uvedeném příkladu vidíme, že tabulka platy vyžaduje obnovu.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKPro instalaci s jedním uzlem bez dalších serverů DR by primárním přístupem bylo obnovení dat ze zálohy. Ale to není jediná věc, kterou musíte zvážit. Mít více databázových schémat pod stejnou instancí způsobuje problém, když musíte server vypnout, abyste obnovili data. Další otázkou je, zda si můžete dovolit vrátit všechny své databáze do poslední zálohy. Ve většině případů by to nebylo možné.
Jsou zde určité výjimky. Je možné obnovit jednu tabulku nebo databázi z poslední zálohy, když není potřeba obnovení v určitém okamžiku. Takový proces je složitější. Pokud máte mysqldump, můžete z něj extrahovat svou databázi. Pokud spouštíte binární zálohy pomocí xtradbackup nebo mariabackup a máte povolenou tabulku na soubor, je to možné.
Zde je návod, jak zkontrolovat, zda máte povolenou volbu tabulky na soubor.
mysql> SET GLOBAL innodb_file_per_table=1; Pokud je povolena funkce innodb_file_per_table, můžete ukládat tabulky InnoDB do souboru .ibd tbl_name. Na rozdíl od úložiště MyISAM s jeho samostatnými soubory tbl_name .MYD a tbl_name .MYI pro indexy a data, InnoDB ukládá data a indexy společně do jediného souboru .ibd. Chcete-li zkontrolovat svůj modul úložiště, musíte spustit:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';nebo přímo z konzole:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Chcete-li obnovit tabulky z xtradbackup, musíte projít procesem exportu. Před obnovením je třeba zálohu připravit. Export se provádí ve fázi přípravy. Jakmile je vytvořena úplná záloha, spusťte standardní postup přípravy s dalším příznakem --export :
innobackupex --apply-log --export /u01/backupTím se vytvoří další exportní soubory, které použijete později ve fázi importu. Chcete-li importovat tabulku na jiný server, nejprve vytvořte novou tabulku se stejnou strukturou jako ta, která bude importována na tento server:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;zahoďte tabulkový prostor:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Poté zkopírujte soubory mytable.ibd a mytable.exp do domovské stránky databáze a importujte její tabulkový prostor:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Chcete-li to však provést lépe kontrolovaným způsobem, doporučuje se obnovit zálohu databáze v jiné instanci/serveru a zkopírovat to, co je potřeba, zpět do hlavního systému. Chcete-li tak učinit, musíte spustit instalaci instance mysql. To by mohlo být provedeno buď na stejném počítači - ale vyžaduje více úsilí při konfiguraci tak, aby obě instance mohly běžet na stejném počítači - například by to vyžadovalo různá nastavení komunikace.
Pomocí ClusterControl můžete kombinovat obnovu úloh a instalaci.
ClusterControl vás provede dostupnými zálohami on-prem nebo v cloudu, umožní vám vybrat si přesný čas pro obnovení nebo přesnou pozici protokolu a v případě potřeby nainstalovat novou instanci databáze.
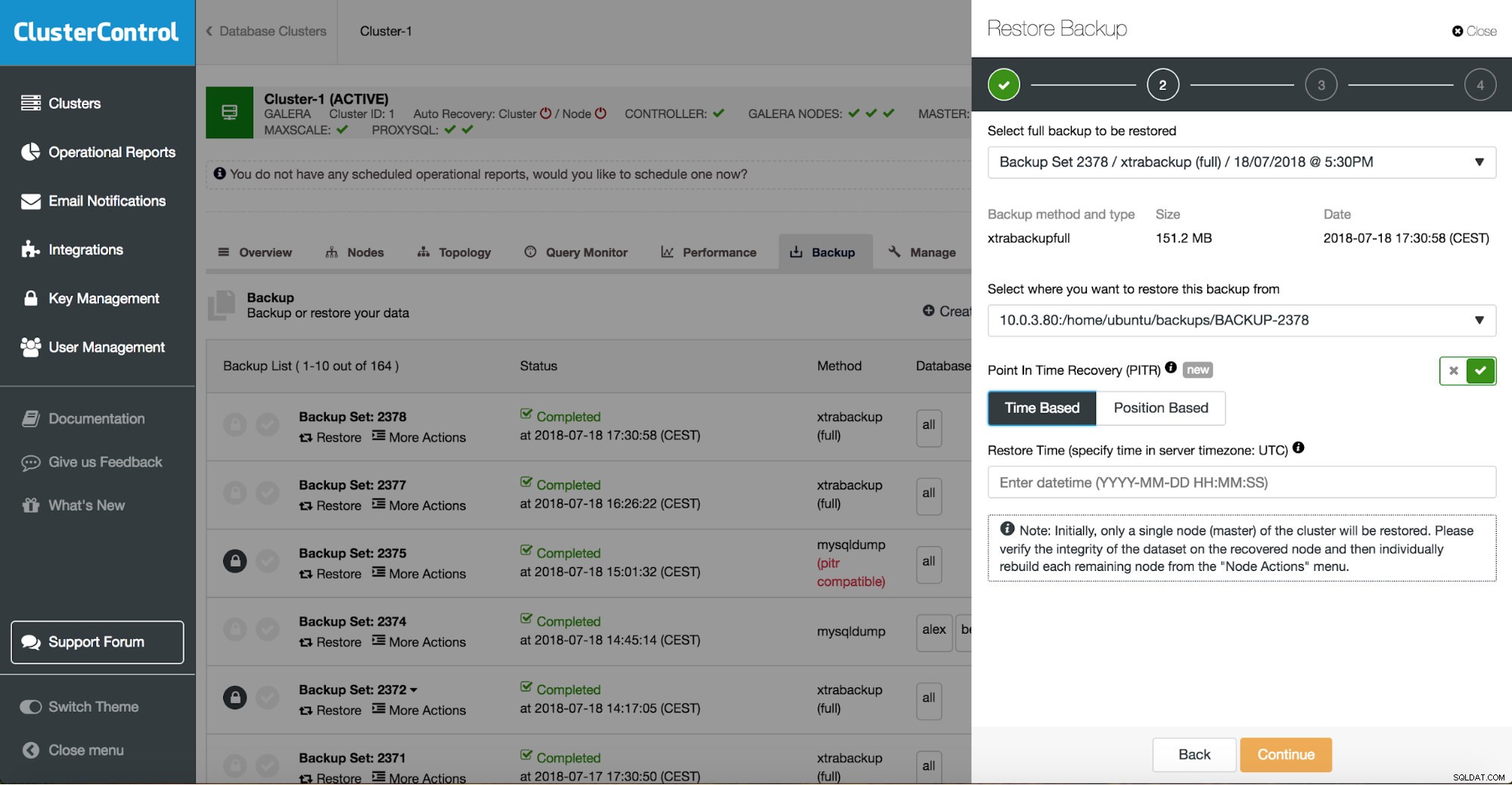 Obnovení bodu v čase ClusterControl
Obnovení bodu v čase ClusterControl 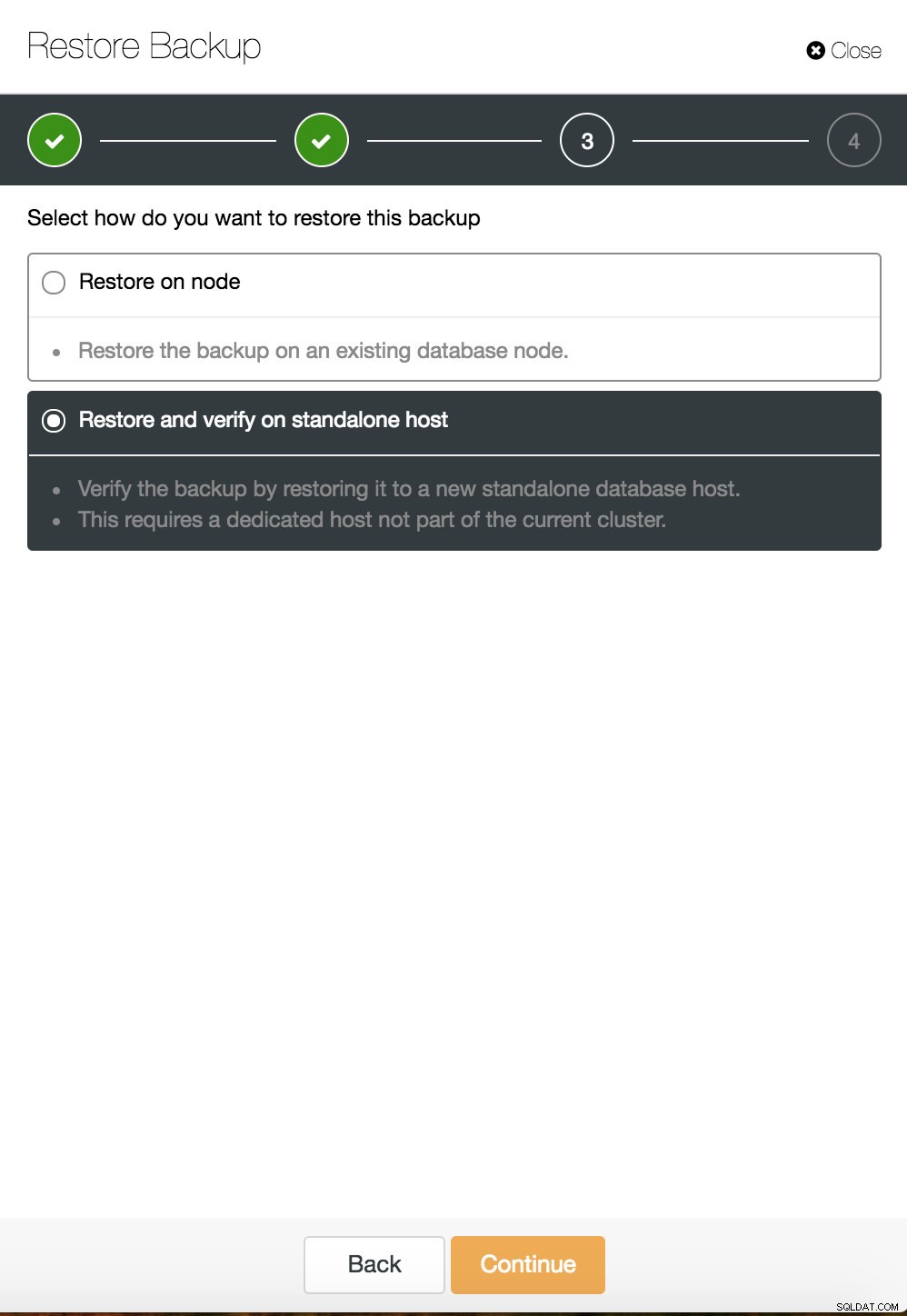 Obnovení a ověření ClusterControl na samostatném hostiteli
Obnovení a ověření ClusterControl na samostatném hostiteli 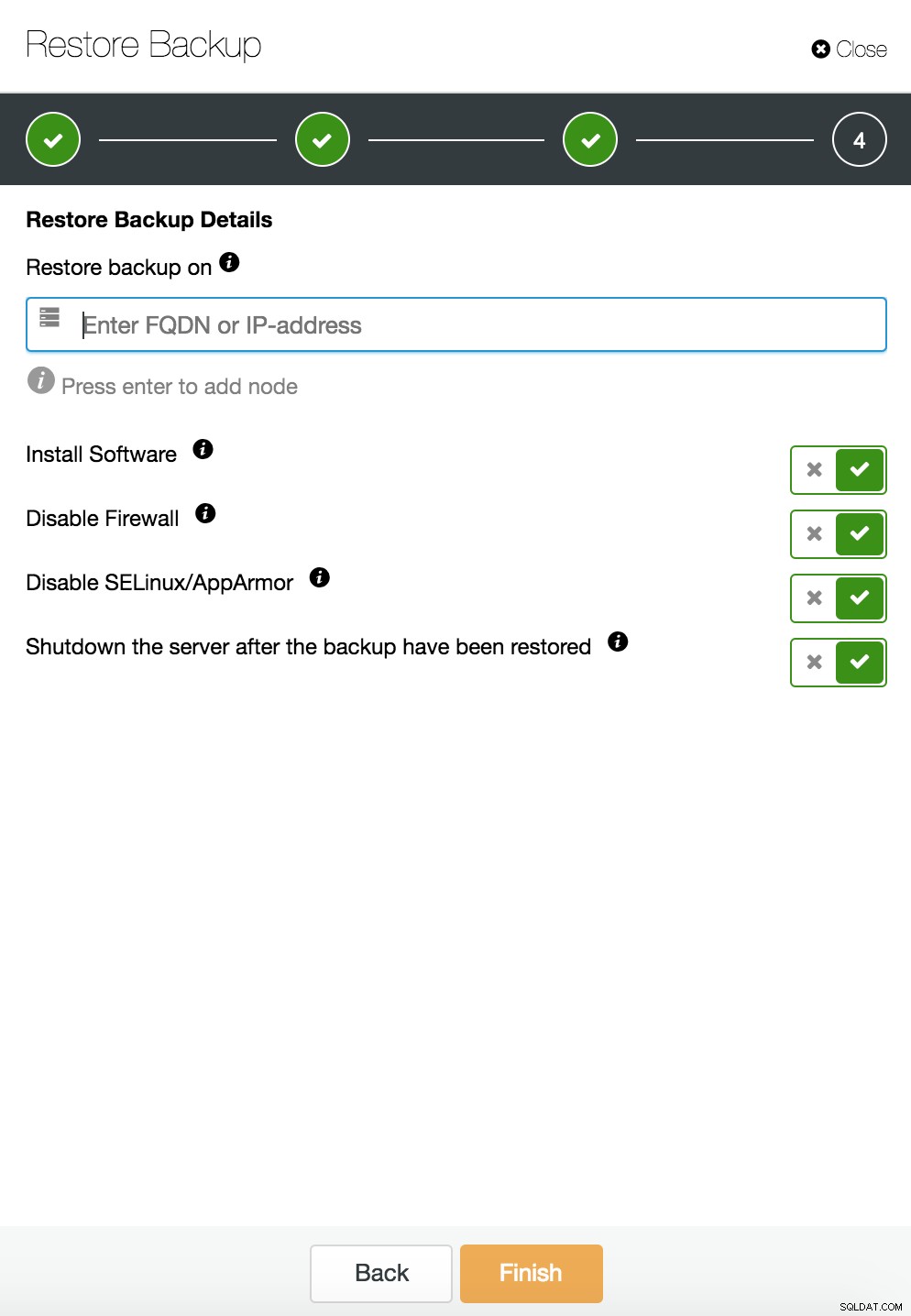 CusterControl obnovit a ověřit na samostatném hostiteli. Možnosti instalace.
CusterControl obnovit a ověřit na samostatném hostiteli. Možnosti instalace. Více informací o obnově dat naleznete na blogu MySQL Database is Corrupted... Co mám dělat?
Instance databáze je poškozena na vyhrazeném serveru
Defekty základní platformy jsou často příčinou poškození databáze. Vaše instance MySQL se při ukládání a načítání dat spoléhá na řadu věcí – diskový subsystém, řadiče, komunikační kanály, ovladače a firmware. Selhání může ovlivnit části vašich dat, binární soubory mysql nebo dokonce záložní soubory, které ukládáte v systému. Chcete-li oddělit různé aplikace, můžete je umístit na vyhrazené servery.
Různá aplikační schémata na samostatných systémech jsou dobrý nápad, pokud si je můžete dovolit. Někdo může říci, že se jedná o plýtvání zdroji, ale existuje šance, že dopad na podnikání bude menší, pokud se sníží pouze jeden z nich. Ale i tak je potřeba chránit databázi před ztrátou dat. Ukládání zálohy na stejný server není špatný nápad, pokud máte kopii někde jinde. V dnešní době je cloudové úložiště vynikající alternativou k zálohování na pásku.
ClusterControl vám umožňuje ponechat kopii zálohy v cloudu. Podporuje nahrávání ke 3 nejlepším poskytovatelům cloudu – Amazon AWS, Google Cloud a Microsoft Azure.
Až budete mít plnou zálohu obnovenou, možná ji budete chtít obnovit do určitého bodu v čase. Obnova v určitém okamžiku přenese server aktuální na novější čas, než kdy byla pořízena plná záloha. Chcete-li tak učinit, musíte mít povolené binární protokoly. Dostupné binární protokoly můžete zkontrolovat pomocí:
mysql> SHOW BINARY LOGS;A aktuální soubor protokolu s:
SHOW MASTER STATUS;Poté můžete zachytit přírůstková data předáním binárních protokolů do souboru SQL. Chybějící operace lze poté znovu provést.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outTotéž lze provést v ClusterControl.
 Cloudová záloha ClusterControl
Cloudová záloha ClusterControl 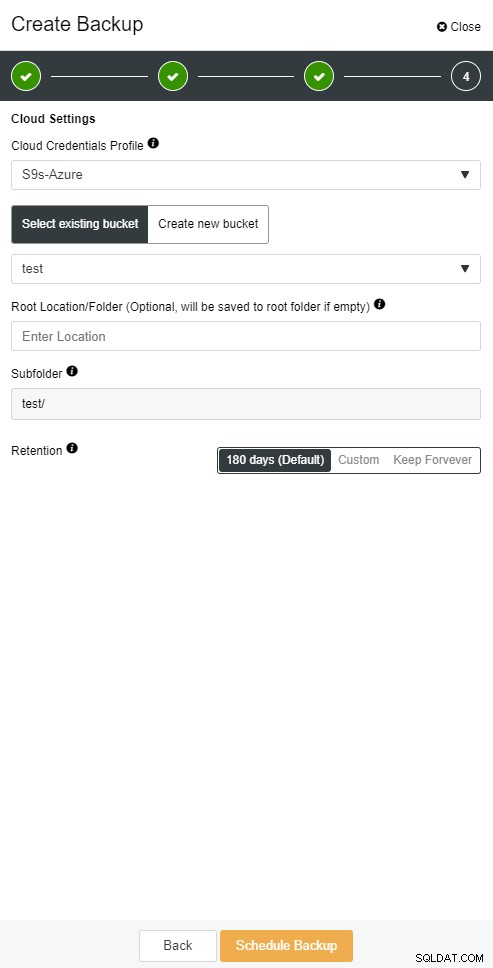 Cloudová záloha ClusterControl
Cloudová záloha ClusterControl Databázová podřízená jednotka klesá
Dobře, takže máte databázi spuštěnou na vyhrazeném serveru. Vytvořili jste propracovaný plán zálohování s kombinací plných a přírůstkových záloh, nahráli je do cloudu a uložili nejnovější zálohu na místní disky pro rychlou obnovu. Máte jiné zásady uchovávání záloh – kratší pro zálohy uložené na ovladačích místních disků a rozšířené pro zálohy v cloudu.
Vypadá to, že jste dobře připraveni na katastrofický scénář. Ale pokud jde o dobu obnovy, nemusí uspokojit vaše obchodní potřeby.
Potřebujete funkci rychlého převzetí služeb při selhání. Server, který bude spuštěn a bude používat binární protokoly z hlavního serveru, kde dochází k zápisům. Replikace Master/Slave zahajuje novou kapitolu scénáře převzetí služeb při selhání. Je to rychlý způsob, jak oživit vaši aplikaci, pokud váš master selže.
Ve scénáři převzetí služeb při selhání je však třeba vzít v úvahu jen málo věcí. Jedním z nich je nastavení zpožděné replikace slave, takže můžete reagovat na příkazy tlustého prstu, které byly spuštěny na hlavním serveru. Podřízený server může za hlavním serverem zaostávat alespoň o určitou dobu. Výchozí zpoždění je 0 sekund. Pomocí možnosti MASTER_DELAY pro CHANGE MASTER TO nastavte zpoždění na N sekund:
CHANGE MASTER TO MASTER_DELAY = N;Druhým je povolení automatického převzetí služeb při selhání. Na trhu existuje mnoho automatizovaných řešení pro překonání selhání. Automatické převzetí služeb při selhání můžete nastavit pomocí nástrojů příkazového řádku, jako je MHA, MRM, mysqlfailover nebo GUI Orchestrator a ClusterControl. Když je správně nastaven, může výrazně snížit váš výpadek.
ClusterControl podporuje automatické převzetí služeb při selhání pro replikace MySQL, PostgreSQL a MongoDB, stejně jako multimaster clusterová řešení Galera a NDB.
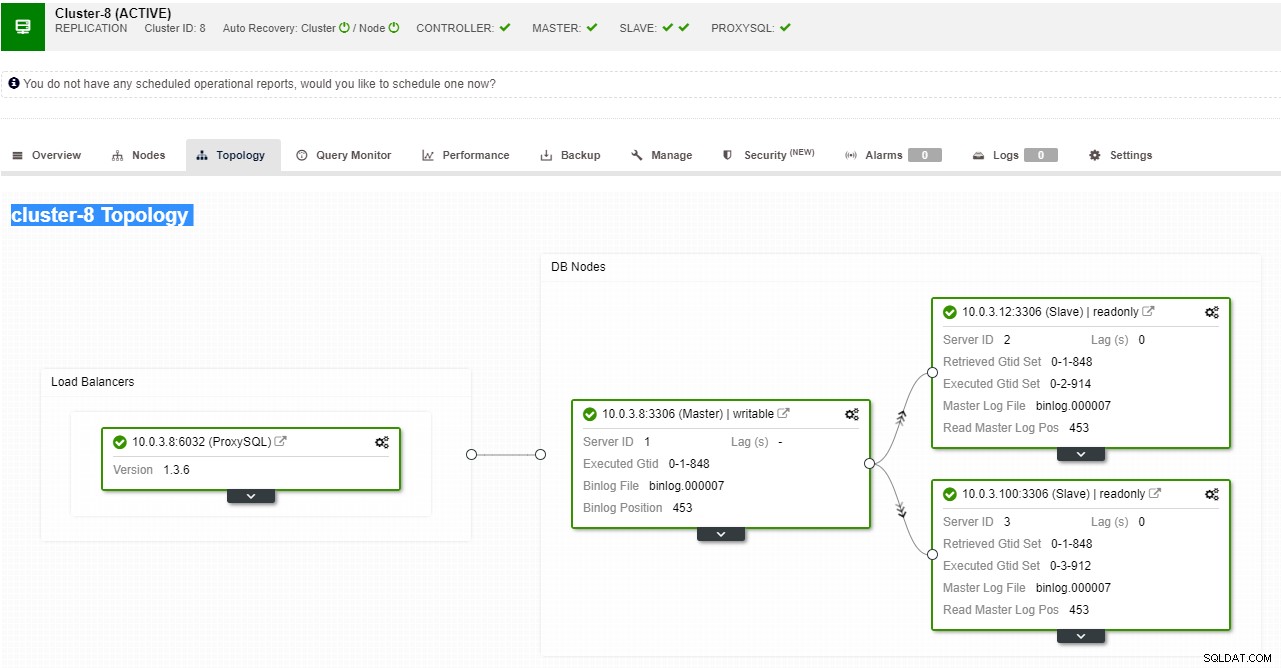 Zobrazení topologie replikace ClusterControl
Zobrazení topologie replikace ClusterControl Když dojde k selhání podřízeného uzlu a server výrazně zaostává, možná budete chtít podřízený server znovu sestavit. Proces obnovy podřízeného zařízení je podobný obnově ze zálohy.
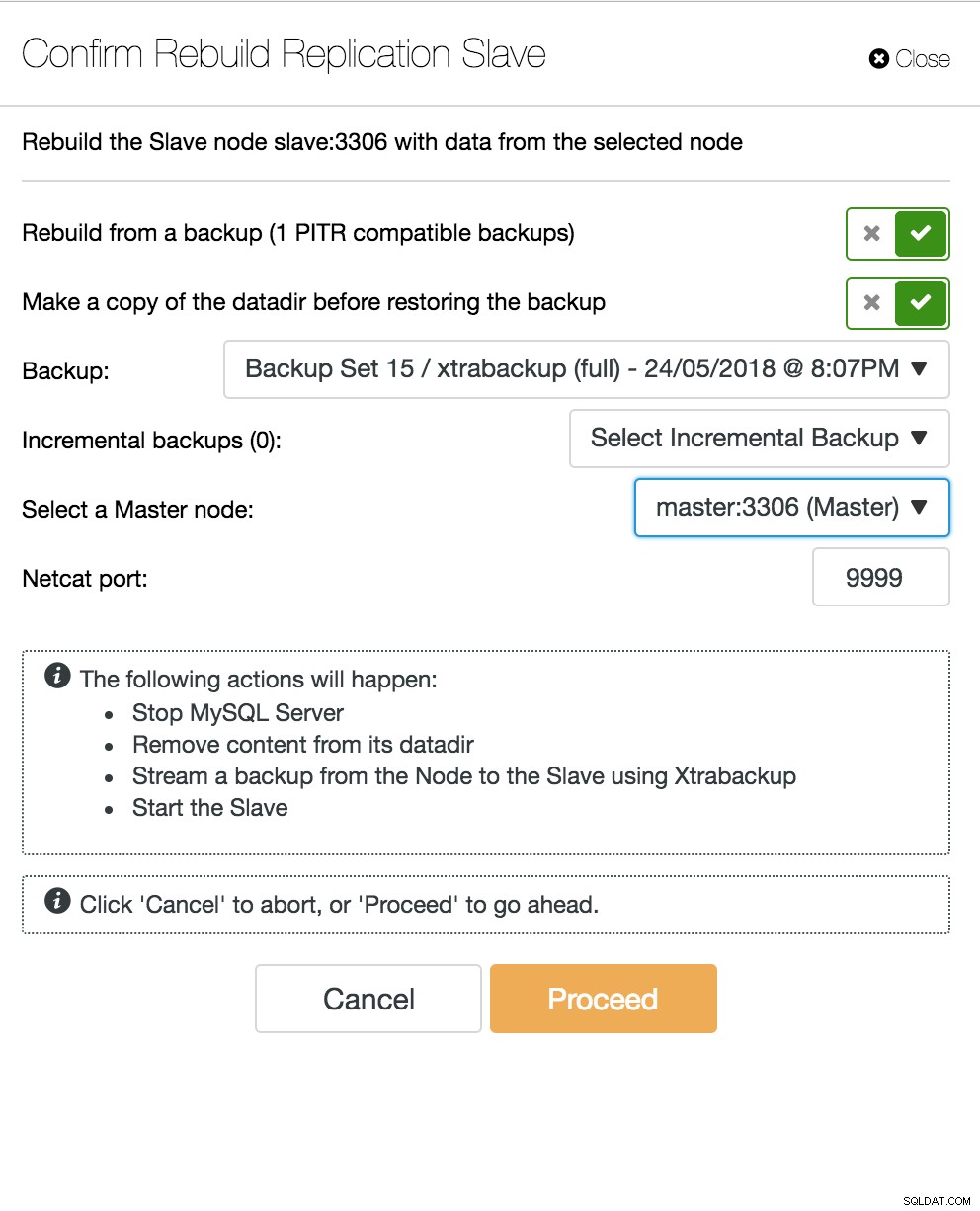 ClusterControl přebudování slave
ClusterControl přebudování slave Databázový server Multi-Master nefunguje
Nyní, když máte podřízený server fungující jako uzel DR a váš proces převzetí služeb při selhání je dobře automatizován a testován, váš život DBA se stane pohodlnějším. To je pravda, ale zbývá vyřešit ještě pár hádanek. Výpočetní výkon není zadarmo a váš obchodní tým vás může požádat, abyste lépe využívali svůj hardware, možná budete chtít používat svůj podřízený server nejen jako pasivní server, ale také pro operace zápisu.
Možná budete chtít prozkoumat řešení replikace s více hlavními servery. Galera Cluster se stal běžnou možností pro vysokou dostupnost MySQL a MariaDB. A přestože je nyní známá jako věrohodná náhrada tradičních architektur MySQL master-slave, není to náhrada typu drop-in.
Cluster Galera má sdílenou architekturu nic. Místo sdílených disků Galera používá replikaci založenou na certifikaci se skupinovou komunikací a řazením transakcí k dosažení synchronní replikace. Databázový cluster by měl být schopen přežít ztrátu uzlu, i když toho lze dosáhnout různými způsoby. V případě Galery je kritickým aspektem počet uzlů. Galera vyžaduje kvórum, aby zůstala funkční. Tříuzlový cluster může přežít pád jednoho uzlu. S více uzly ve vašem clusteru můžete přežít více selhání.
Proces obnovy je automatizovaný, takže nemusíte provádět žádné operace převzetí služeb při selhání. Osvědčeným postupem by však bylo zabít uzly a zjistit, jak rychle je můžete vrátit zpět. Chcete-li tuto operaci zefektivnit, můžete upravit velikost mezipaměti galerie. Pokud není velikost mezipaměti galerie správně naplánována, váš další spouštěcí uzel bude muset provést úplnou zálohu namísto chybějících sad zápisu v mezipaměti.
Scénář převzetí služeb při selhání je jednoduchý jako spuštění intance. Na základě dat v mezipaměti galerie bude spouštěcí uzel provádět SST (obnovení z plné zálohy) nebo IST (aplikovat chybějící sady zápisu). To je však často spojeno s lidským zásahem. Pokud chcete automatizovat celý proces převzetí služeb při selhání, můžete použít funkci automatického obnovení ClusterControl (úroveň uzlu a clusteru).
 Automatické obnovení clusteru ClusterControl
Automatické obnovení clusteru ClusterControl Odhadovaná velikost mezipaměti galerie:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Aby bylo převzetí služeb při selhání konzistentnější, měli byste v mycnf povolit gcache.recover=yes. Tato možnost po restartu oživí galera-cache. To znamená, že uzel může fungovat jako DÁRCE a obsluhovat chybějící sady zápisu (usnadňující IST namísto použití SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Uzel proxy SQL selhal
Pokud máte nastavenou virtuální IP, vše, co musíte udělat, je nasměrovat vaši aplikaci na virtuální IP adresu a vše by mělo být správné. Nestačí mít instance databáze pokrývající více datových center, stále potřebujete, aby k nim vaše aplikace přistupovaly. Předpokládejme, že jste zvýšili počet čtených replik, možná budete chtít implementovat virtuální IP adresy pro každou z těchto čtených replik také z důvodu údržby nebo dostupnosti. Může se stát těžkopádným fondem virtuálních IP adres, které budete muset spravovat. Pokud jedna z těchto čtených replik narazí na selhání, musíte znovu přiřadit virtuální IP jinému hostiteli, jinak se vaše aplikace připojí buď k hostiteli, který je mimo provoz, nebo v nejhorším případě ke zpožděnému serveru se zastaralými daty.
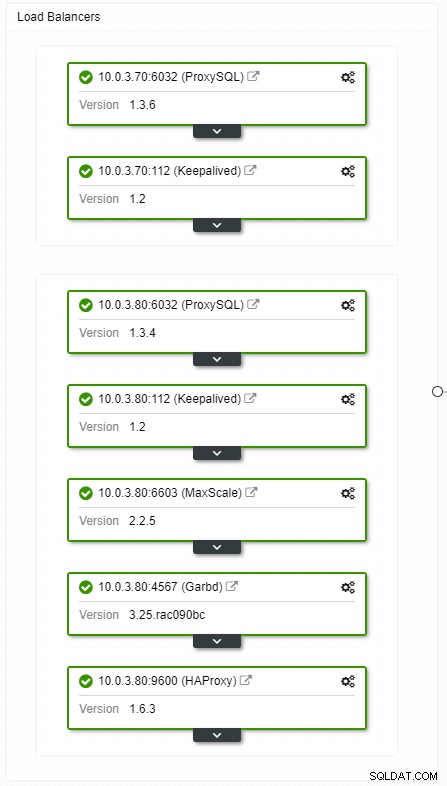 Zobrazení topologie nástroje pro vyrovnávání zatížení ClusterControl HA
Zobrazení topologie nástroje pro vyrovnávání zatížení ClusterControl HA Pády nejsou časté, ale pravděpodobnější než výpadky serverů. Pokud z jakéhokoli důvodu selže slave, něco jako ProxySQL přesměruje veškerý provoz na master s rizikem jeho přetížení. Když se slave zotaví, provoz bude přesměrován zpět na něj. Obvykle by takové prostoje neměly trvat déle než několik minut, takže celková závažnost je střední, i když pravděpodobnost je také střední.
Chcete-li, aby byly komponenty nástroje pro vyrovnávání zatížení redundantní, můžete použít keepalived.
 ClusterControl:Nasazení keepalived pro nástroj pro vyrovnávání zatížení ProxySQL
ClusterControl:Nasazení keepalived pro nástroj pro vyrovnávání zatížení ProxySQL Datové centrum selhalo
Hlavním problémem replikace je to, že neexistuje žádný většinový mechanismus pro detekci selhání datového centra a obsluhu nového hlavního serveru. Jedním z předsevzetí je použít Orchestrator/Raft. Orchestrator je supervizor topologie, který může řídit převzetí služeb při selhání. Při použití společně s Raftem bude Orchestrator informován o kvoru. Jedna z instancí Orchestrator je zvolena jako vedoucí a provádí úkoly obnovy. Spojení mezi uzlem orchestrátoru nekoreluje s potvrzováním transakční databáze a je řídké.
Orchestrator/Raft může používat další instance, které provádějí monitorování topologie. V případě síťového rozdělení neprovedou rozdělené instance Orchestrator žádnou akci. Část klastru Orchestrator, která má kvorum, zvolí nového mastera a provede potřebné změny topologie.
ClusterControl se používá pro správu, škálování a, co je nejdůležitější, pro obnovu uzlů – Orchestrator by zvládl výpadky, ale pokud by došlo k selhání podřízeného zařízení, ClusterControl zajistí, že bude obnoven. Orchestrator a ClusterControl by byly umístěny ve stejné zóně dostupnosti, oddělené od uzlů MySQL, aby bylo zajištěno, že jejich činnost nebude ovlivněna rozdělením sítě mezi zóny dostupnosti v datovém centru.