Replikace Galera je relativně nová ve srovnání s replikací MySQL, která je nativně podporována od MySQL v3.23. Přestože replikace MySQL je navržena pro jednosměrnou replikaci master-slave, lze ji nakonfigurovat jako aktivní master-master setup s obousměrnou replikací. I když je jeho nastavení snadné a některé případy použití mohou z tohoto „hacku“ těžit, existuje řada upozornění. Na druhou stranu je cluster Galera odlišným typem technologie, kterou je třeba se naučit a spravovat. Stojí to za to?
V tomto příspěvku na blogu porovnáme replikaci master-master s clusterem Galera.
Koncepty replikace
Než se vrhneme na srovnání, vysvětlíme si základní koncepty těchto dvou replikačních mechanismů.
Obecně platí, že jakákoli úprava databáze MySQL generuje událost v binárním formátu. Tato událost je přenášena do ostatních uzlů v závislosti na zvolené metodě replikace – replikace MySQL (nativní) nebo replikace Galera (opravená pomocí wsrep API).
Replikace MySQL
Následující diagramy ilustrují datový tok úspěšné transakce z jednoho uzlu do druhého při použití replikace MySQL:
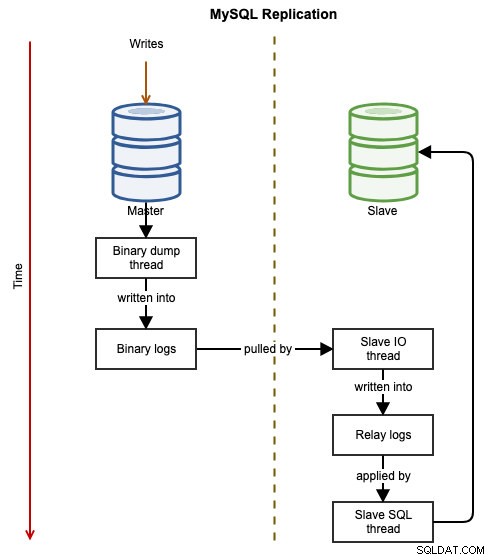
Binární událost je zapsána do binárního protokolu hlavního serveru. Slave (otroci) prostřednictvím slave_IO_thread vytáhne binární události z hlavního binárního protokolu a replikuje je do svého reléového protokolu. vlákno_slave_SQL poté asynchronně použije událost z protokolu přenosu. Vzhledem k asynchronní povaze replikace není zaručeno, že podřízený server bude mít data, když hlavní server provede změnu.
V ideálním případě bude replikace MySQL mít podřízený server konfigurovaný jako server pouze pro čtení nastavením read_only=ON nebo super_read_only=ON. Jedná se o preventivní opatření k ochraně podřízeného zařízení před náhodnými zápisy, které mohou vést k nekonzistenci dat nebo selhání během hlavního převzetí služeb při selhání (např. chybné transakce). V nastavení replikace aktivní-aktivní master-master však musí být na druhém masteru zakázáno pouze čtení, aby bylo možné současně zpracovávat zápisy. Primární hlavní server musí být nakonfigurován tak, aby se replikoval ze sekundárního hlavního serveru pomocí příkazu CHANGE MASTER, aby se umožnila cyklická replikace.
Replikace Galera
Následující diagramy ilustrují tok replikace dat úspěšné transakce z jednoho uzlu do druhého pro Galera Cluster:
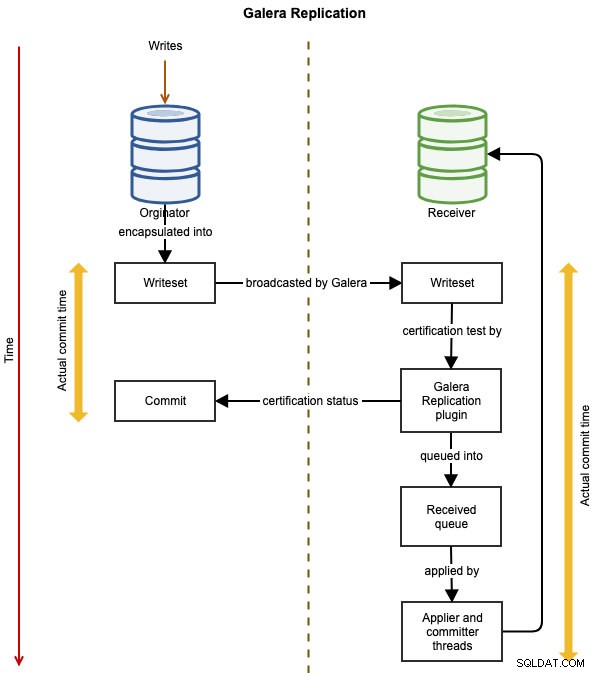
Událost je zapouzdřena do zapisovací sady a vysílána z uzlu původce do ostatních uzlů v clusteru pomocí replikace Galera. Sada zápisů prochází certifikací na každém uzlu Galera a pokud projde, aplikační vlákna použijí sadu zápisů asynchronně. To znamená, že podřízený server se nakonec stane konzistentním, po dohodě všech zúčastněných uzlů v globálním celkovém uspořádání. Je logicky synchronní, ale vlastní zápis a odevzdání do tabulkového prostoru probíhá nezávisle, a tedy asynchronně na každém uzlu se zárukou, že se změna rozšíří na všechny uzly.
Zabránění kolizi primárního klíče
Aby bylo možné nasadit replikaci MySQL v nastavení master-master, je třeba upravit hodnotu automatického přírůstku, aby nedošlo ke kolizi primárního klíče pro INSERT mezi dvěma nebo více replikujícími se mastery. To umožňuje, aby se hodnota primárního klíče na masterech vzájemně prokládala a bránila tomu, aby bylo stejné číslo automatického zvýšení použito dvakrát na jednom z uzlu. Toto chování je nutné nakonfigurovat ručně v závislosti na počtu hlavních serverů v nastavení replikace. Hodnota auto_increment_increment se rovná počtu replikujících se předloh a auto_increment_offset musí být mezi nimi jedinečné. Například v odpovídajícím souboru my.cnf by měly existovat následující řádky:
Mistr1:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=1Master2:
log-slave-updates
auto_increment_increment=2
auto_increment_offset=2Podobně Galera Cluster používá stejný trik, aby se vyhnul kolizím primárního klíče tím, že automaticky řídí hodnotu automatického přírůstku a offset pomocí wsrep_auto_increment_control variabilní. Pokud je nastaveno na 1 (výchozí), automaticky se upraví auto_increment_increment a auto_increment_offset proměnné podle velikosti shluku a při změně velikosti shluku. Tím se vyhnete konfliktům replikace kvůli auto_increment. V prostředí master-slave lze tuto proměnnou nastavit na OFF.
Důsledkem této konfigurace je, že hodnota automatického přírůstku nebude v sekvenčním pořadí, jak ukazuje následující tabulka tříuzlového clusteru Galera:
| Uzel | auto_increment_increment | auto_increment_offset | Automatické zvýšení hodnoty |
|---|---|---|---|
| Uzel 1 | 3 | 1 | 1, 4, 7, 10, 13, 16... |
| Uzel 2 | 3 | 2 | 2, 5, 8, 11, 14, 17... |
| Uzel 3 | 3 | 3 | 3, 6, 9, 12, 15, 18... |
Pokud aplikace provádí operace vkládání na následujících uzlech v následujícím pořadí:
- Uzel1, Uzel3, Uzel2, Uzel3, Uzel3, Uzel1, Uzel3 ..
Hodnota primárního klíče, která bude uložena v tabulce, pak bude:
- 1, 6, 8, 9, 12, 13, 15...
Jednoduše řečeno, při použití replikace master-master (replikace MySQL nebo Galera) musí být vaše aplikace schopna tolerovat hodnoty nesekvenčních automatických přírůstků ve své datové sadě.
Pro uživatele ClusterControl vezměte na vědomí, že podporuje nasazení replikace MySQL master-master s limitem dvou master na replikační klastr, pouze pro aktivní-pasivní nastavení. Proto ClusterControl záměrně nekonfiguruje mastery pomocí auto_increment_increment a auto_increment_offset proměnné.
Konzistence dat
Galera Cluster přichází s mechanismem řízení toku, kde každý uzel v clusteru musí držet krok při replikaci, jinak budou muset všechny ostatní uzly zpomalit, aby umožnily nejpomalejšímu uzlu dohnat. To v zásadě minimalizuje pravděpodobnost zpoždění slave, i když k němu stále může dojít, ale ne tak významné jako při replikaci MySQL. Ve výchozím nastavení Galera povoluje, aby uzly byly pozadu alespoň o 16 transakcí prostřednictvím proměnné gcs.fc_limit . Pokud chcete provádět kritická čtení (SELECT, který musí vracet nejaktuálnější informace), pravděpodobně budete chtít použít proměnnou relace wsrep_sync_wait .
Galera Cluster na druhé straně přichází s ochranou proti nekonzistenci dat, kdy uzel bude vyřazen z clusteru, pokud z jakýchkoli důvodů nedokáže použít jakoukoli sadu zápisů. Když se například uzel Galera nepodaří použít sadu zápisu kvůli vnitřní chybě základního úložiště (MySQL/MariaDB), uzel se sám vytáhne z clusteru s následující chybou:
150305 16:13:14 [ERROR] WSREP: Failed to apply trx 1 4 times
150305 16:13:14 [ERROR] WSREP: Node consistency compromized, aborting..Chcete-li opravit konzistenci dat, musí být problematický uzel znovu synchronizován, než se bude moci připojit ke clusteru. To lze provést ručně nebo vymazáním datového adresáře pro spuštění přenosu stavu snímku (úplná synchronizace od dárce).
Replikace MySQL master-master nevynucuje ochranu konzistence dat a slave se může rozcházet, např. replikovat podmnožinu dat nebo zaostávat, což činí slave nekonzistentní s masterem. Je navržen tak, aby replikoval data v jednom toku – od hlavního až po podřízené. Kontroly konzistence dat je třeba provádět ručně nebo pomocí externích nástrojů, jako je Percona Toolkit pt-table-checksum nebo mysql-replication-check.
Řešení konfliktů
Obecně platí, že replikace master-master (nebo multi-master nebo obousměrná) replikace umožňuje více než jednomu členu v klastru zpracovávat zápisy. Při replikaci MySQL v případě konfliktu replikace vlákno SQL podřízeného zařízení jednoduše zastaví aplikaci dalšího dotazu, dokud nebude konflikt vyřešen, buď ručním přeskočením události replikace, opravou problematických řádků nebo opětovnou synchronizací podřízeného serveru. Jednoduše řečeno, pro replikaci MySQL neexistuje žádná podpora automatického řešení konfliktů.
Galera Cluster poskytuje lepší alternativu opakovaným pokusem o problematickou transakci během replikace. Pomocí wsrep_retry_autocommit proměnnou, lze dát Galeře pokyn, aby automaticky opakovala neúspěšnou transakci kvůli konfliktům v celém clusteru, než vrátí chybu klientovi. Pokud je nastaveno na 0, nebudou provedeny žádné pokusy o opakování, zatímco hodnota 1 (výchozí) nebo více udává počet pokusů o opakování. To může být užitečné pro pomoc aplikacím používajícím automatické potvrzení, aby se zabránilo uváznutí.
Konsensus uzlu a převzetí služeb při selhání
Galera používá Group Communication System (GCS) ke kontrole shody uzlů a dostupnosti mezi členy clusteru. Pokud uzel není v pořádku, bude automaticky vyřazen z clusteru po gmcast.peer_timeout hodnota, výchozí hodnota je 3 sekundy. Zdravý uzel Galera ve stavu „Synced“ je považován za spolehlivý uzel pro čtení a zápis, zatímco ostatní nikoli. Tento design výrazně zjednodušuje procedury kontroly stavu z vyšších vrstev (vyvažovač zátěže nebo aplikace).
V replikaci MySQL se master nestará o své slave(y), zatímco slave má konsensus pouze se svým jediným masterem prostřednictvím vlákna slave_IO_thread procesu při replikaci binárních událostí z binárního protokolu hlavního serveru. Pokud dojde k výpadku hlavního serveru, replikace se přeruší a každý slave_net_timeout bude proveden pokus o opětovné navázání spojení (výchozí nastavení je 60 sekund). Z hlediska aplikace nebo nástroje pro vyrovnávání zatížení musí postupy kontroly stavu pro replikační podřízenou jednotku zahrnovat alespoň kontrolu následujícího stavu:
- Seconds_Behind_Master
- Slave_IO_Running
- Slave_SQL_Running
- proměnná pouze pro čtení
- proměnná super_read_only (MySQL 5.7.8 a novější)
Z hlediska převzetí služeb při selhání jsou obecně uzly master-master replikace a uzly Galera rovnocenné. Obsahují stejnou datovou sadu (ačkoli můžete replikovat podmnožinu dat v replikaci MySQL, ale to je pro master-master neobvyklé) a sdílejí stejnou roli jako master, schopné zpracovávat čtení a zápis současně. V důsledku této rovnováhy tedy z pohledu databáze ve skutečnosti nedochází k žádnému převzetí služeb při selhání. Pouze ze strany aplikace, která by vyžadovala převzetí služeb při selhání pro přeskočení nefunkčních uzlů. Mějte na paměti, že protože replikace MySQL je asynchronní, je možné, že ne všechny změny provedené na hlavním serveru se přenesou do druhého hlavního serveru.
Zřizování uzlů
Proces synchronizace uzlu s clusterem před zahájením replikace se nazývá zajišťování. V replikaci MySQL je zřízení nového uzlu manuální proces. Před nastavením replikačního spojení je třeba vzít zálohu hlavního uzlu a obnovit ji do nového uzlu. Pro existující uzel replikace, pokud byly binární protokoly hlavního serveru otočeny (na základě expire_logs_days , výchozí hodnota 0 znamená žádné automatické odstranění), možná budete muset znovu zřídit uzel pomocí tohoto postupu. Existují také externí nástroje, jako je Percona Toolkit pt-table-sync a ClusterControl, které vám s tím pomohou. ClusterControl podporuje opětovnou synchronizaci slave pomocí pouhých dvou kliknutí. Máte možnosti opětovné synchronizace vytvořením zálohy z aktivní hlavní nebo existující zálohy.
V Galeře existují dva způsoby, jak toho dosáhnout – inkrementální přenos stavu (IST) nebo přenos stavu snímku (SST). Proces IST je preferovanou metodou, kdy se z mezipaměti dárce přenášejí pouze chybějící transakce. Proces SST je podobný převzetí úplné zálohy od dárce, obvykle je poměrně náročný na zdroje. Galera automaticky určí, který proces synchronizace se má spustit, na základě stavu připojení. Ve většině případů, pokud se uzel nepodaří připojit ke clusteru, jednoduše vymažte datadir MySQL problematického uzlu a spusťte službu MySQL. Proces zajišťování Galera je mnohem jednodušší, je velmi užitečný při škálování vašeho clusteru nebo opětovném zavádění problematického uzlu zpět do clusteru.
Volně spojené vs. těsně spojené
Replikace MySQL funguje velmi dobře i přes pomalejší připojení a připojení, která nejsou spojitá. Může být také použit na různém hardwaru, prostředí a operačních systémech. Podporuje to většina úložišť, včetně MyISAM, Aria, MEMORY a ARCHIVE. Toto volně propojené nastavení umožňuje replikaci MySQL master-master dobře fungovat ve smíšeném prostředí s menšími omezeními.
Uzly Galera jsou těsně propojeny, kde je výkon replikace stejně rychlý jako nejpomalejší uzel. Galera používá mechanismus řízení toku k řízení toku replikace mezi členy a eliminaci jakéhokoli zpoždění slave. Replikace může být rychlá nebo pomalá na každém uzlu a Galera ji upravuje automaticky. Proto se doporučuje používat jednotné hardwarové specifikace pro všechny uzly Galera, zejména s ohledem na CPU, RAM, diskový subsystém, síťovou kartu a latenci sítě mezi uzly v clusteru.
Závěry
Stručně řečeno, Galera Cluster je lepší ve srovnání s replikací MySQL master-master díky podpoře synchronní replikace se silnou konzistencí a pokročilejším funkcím, jako je automatická kontrola členství, automatické zřizování uzlů a vícevláknové podřízené jednotky. V konečném důsledku to závisí na tom, jak aplikace spolupracuje s databázovým serverem. Některé starší aplikace vytvořené pro samostatný databázový server nemusí správně fungovat v klastrovaném nastavení.
Abychom zjednodušili naše výše uvedené body, následující důvody ospravedlňují, kdy použít replikaci MySQL master-master:
- Věci, které Galera nepodporuje:
- Replikace pro tabulky jiné než InnoDB/XtraDB, jako je MyISAM, Aria, MEMORY nebo ARCHIVE.
- Transakce XA.
- Replikace založená na příkazech mezi mastery (např. když je šířka pásma velmi drahá).
- Spoléhání se na explicitní zamykání, jako je příkaz LOCK TABLES.
- Protokol obecných dotazů a protokol pomalých dotazů musí být nasměrovány do tabulky, nikoli do souboru.
- Volně propojené nastavení, kde se hardwarové specifikace, verze softwaru a rychlost připojení výrazně liší na každém masteru.
- Pokud již máte replikační řetězec MySQL a chcete přidat další aktivní/záložní hlavní server pro redundanci, abyste urychlili převzetí služeb při selhání a dobu obnovy v případě, že jeden z hlavních serverů není dostupný.
- Pokud vaši aplikaci nelze upravit tak, aby obcházela omezení Galera Cluster a mít nástroj pro vyrovnávání zatížení s podporou MySQL, jako je ProxySQL nebo MaxScale, není možné.
Důvody, proč zvolit Galera Cluster před replikací MySQL master-master:
- Schopnost bezpečně zapisovat do více masterů.
- Konzistence dat je automaticky spravována (a zaručena) napříč databázemi.
- Snadné zavedení a synchronizace nových uzlů databáze.
- Automaticky zjištěna selhání nebo nekonzistence.
- Obecně pokročilejší a robustnější funkce s vysokou dostupností.