Dávno pryč jsou doby, kdy byla databáze nasazena jako jeden uzel nebo instance – výkonný, samostatný server, který měl za úkol zpracovávat všechny požadavky na databázi. Vertikální škálování byla cesta, jak jít - vyměnit server za jiný, ještě výkonnější. Během těchto dob se výkon sítě opravdu nemusel obtěžovat. Dokud přicházely žádosti, bylo vše v pořádku.
Ale v dnešní době jsou databáze stavěny jako clustery s uzly propojenými přes síť. Ne vždy se jedná o rychlou místní síť. Vzhledem k tomu, že podniky dosahují globálního měřítka, musí databázová infrastruktura také pokrývat celý svět, aby zůstala nablízku zákazníkům a snížila se latence. Přichází s dalšími výzvami, kterým musíme čelit při navrhování vysoce dostupného databázového prostředí. V tomto příspěvku na blogu se podíváme na problémy se sítí, se kterými se můžete setkat, a poskytneme několik návrhů, jak je řešit.
Dvě hlavní možnosti pro MySQL nebo MariaDB HA
Tímto konkrétním tématem jsme se poměrně obsáhle zabývali v jednom z whitepaperů, ale podívejme se na dva hlavní způsoby budování vysoké dostupnosti pro MySQL a MariaDB.
Galera Cluster
Galera Cluster je prakticky synchronní clusterová technologie pro MySQL bez sdílení. Umožňuje vytvářet sestavy s více zapisovacími jednotkami, které mohou být rozšířeny po celém světě. Galera prosperuje v prostředích s nízkou latencí, ale lze ji nakonfigurovat také pro práci s dlouhými připojeními WAN. Galera má vestavěný mechanismus kvora, který zajišťuje, že data nebudou ohrožena v případě rozdělení sítě na některé z uzlů.
Replikace MySQL
Replikace MySQL může být asynchronní nebo semisynchronní. Oba jsou navrženy pro vytváření rozsáhlých replikačních clusterů. Stejně jako v jakékoli jiné konfiguraci master-slave nebo primární-sekundární replikace může existovat pouze jeden zapisovač, master. Jiné uzly, podřízené, se používají pro účely převzetí služeb při selhání, protože obsahují kopii sady dat z maseru. Slave lze také použít pro čtení dat a odstranění části pracovní zátěže z masteru.
Obě řešení mají své limity a vlastnosti, obě trpí různými problémy. Obojí může být ovlivněno nestabilním síťovým připojením. Pojďme se podívat na tato omezení a na to, jak můžeme navrhnout prostředí, abychom minimalizovali dopad nestabilní síťové infrastruktury.
Galera Cluster – Problémy se sítí
Nejprve se podívejme na Galera Cluster. Jak jsme diskutovali, funguje nejlépe v prostředí s nízkou latencí. Jedním z hlavních problémů souvisejících s latencí v Galeře je způsob, jakým Galera zpracovává zápisy. Nebudeme zacházet do všech podrobností v tomto blogu, ale dále se budeme číst v našem tutoriálu Galera Cluster for MySQL. Sečteno a podtrženo, vzhledem k certifikačnímu procesu pro zápisy, kde se všechny uzly v clusteru musí dohodnout na tom, zda lze zápis použít nebo ne, je váš výkon zápisu pro jeden řádek přísně omezen dobou zpětného přenosu mezi zapisovači. uzel a nejvzdálenější uzel. Pokud je latence přijatelná a pokud nemáte v datech příliš mnoho aktivních míst, nastavení WAN mohou fungovat dobře. Problém začíná, když latence sítě čas od času naroste. Zápisy pak budou trvat 3 až 4krát déle než obvykle a v důsledku toho mohou být databáze přetíženy dlouhotrvajícími zápisy.
Jednou ze skvělých vlastností Galera Cluster je jeho schopnost detekovat stav clusteru a reagovat na rozdělení sítě. Pokud se některý uzel clusteru nedosáhne, bude z clusteru vyřazen a nebude moci provádět žádné zápisy. To je klíčové pro zachování integrity dat během doby, kdy je cluster rozdělen - pouze většina clusteru bude přijímat zápisy. Menšina si bude stěžovat. Aby to zvládla, Galera zavádí širokou škálu kontrol a konfigurovatelných časových limitů, aby se zabránilo falešným upozorněním na velmi přechodné problémy se sítí. Bohužel, pokud je síť nespolehlivá, Galera Cluster nebude moci správně fungovat – uzly začnou cluster opouštět, připojí se k němu později. Obzvláště problematické to bude, když budeme mít Galera Cluster napříč WAN – oddělené části clusteru mohou náhodně mizet, pokud propojovací síť nebude správně fungovat.
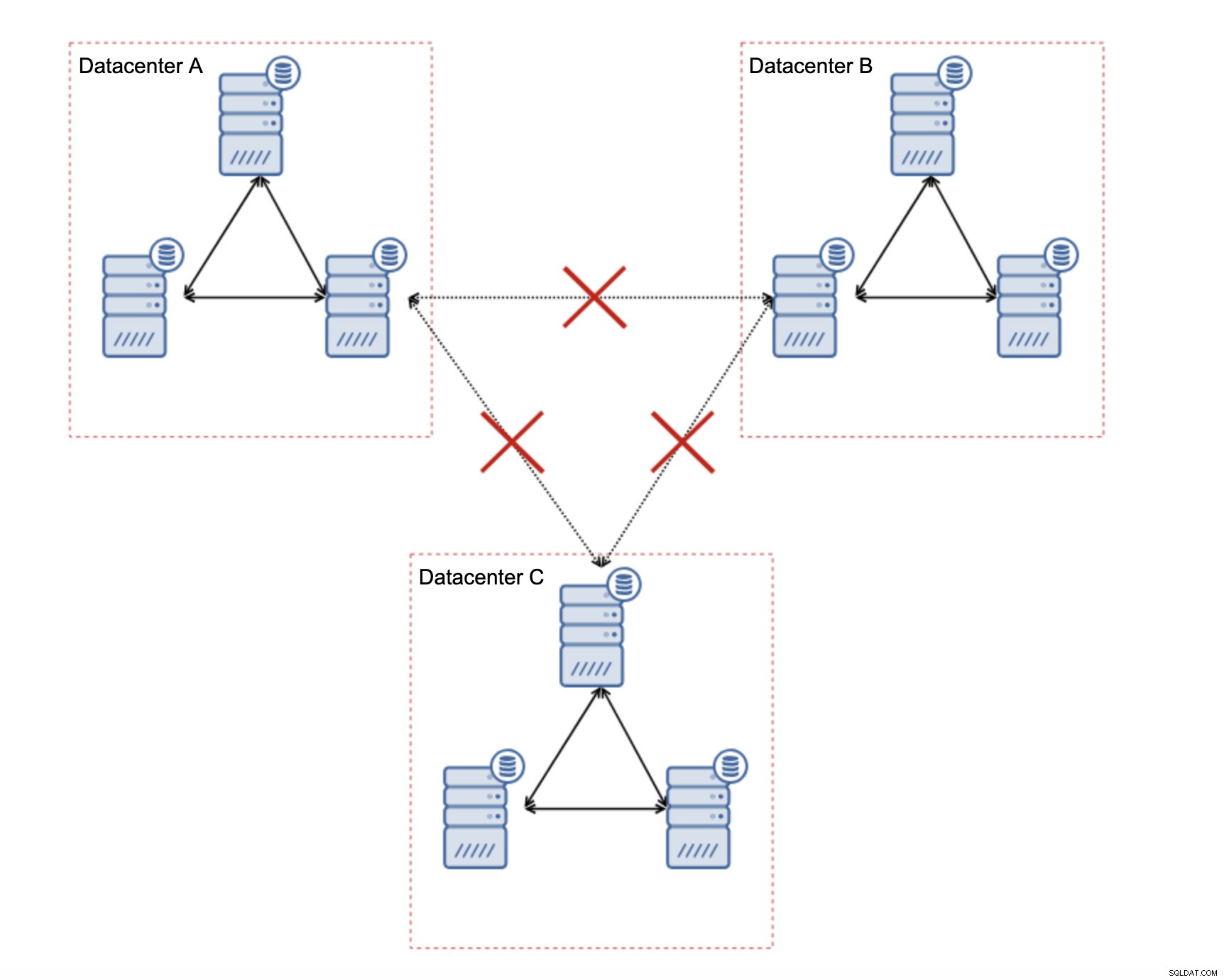
Jak navrhnout Galera Cluster pro nestabilní síť?
Za prvé, pokud máte problémy se sítí v rámci jediného datového centra, nemůžete udělat mnoho, pokud nebudete schopni tyto problémy nějak vyřešit. Nespolehlivá místní síť je pro Galera Cluster nepoužitelná, musíte přehodnotit použití jiného řešení (i když, upřímně řečeno, nespolehlivá síť bude vždy problematická). Na druhou stranu, pokud se problémy týkají pouze připojení WAN (a to je jeden z nejtypičtějších případů), může být možné nahradit připojení WAN Galera běžnou asynchronní replikací (pokud nepomohlo ladění Galera WAN).
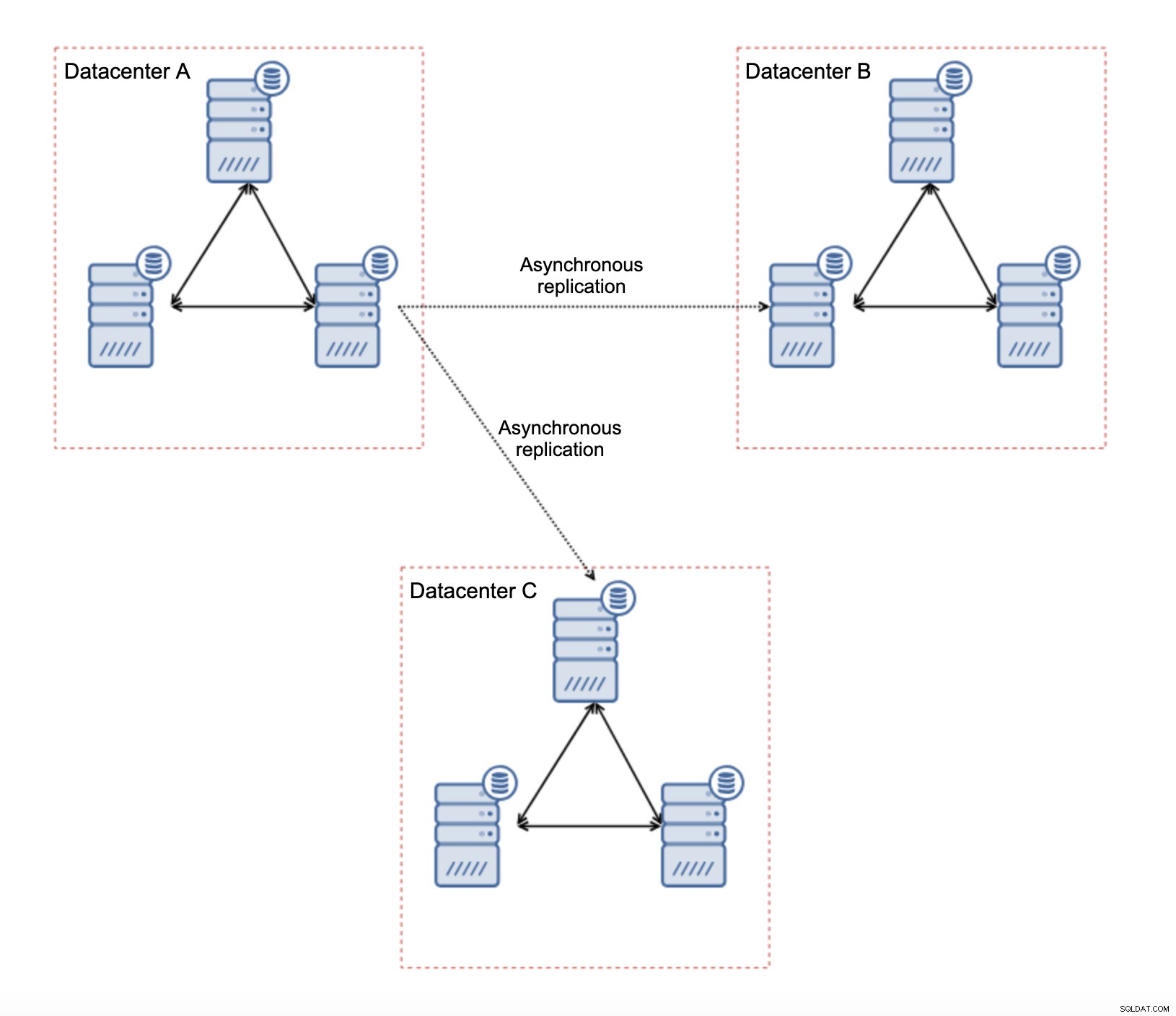
Toto nastavení má několik přirozených omezení – hlavním problémem je, že zápisy se dříve odehrávaly lokálně. Nyní budou muset všechny zápisy směřovat do „hlavního“ datového centra (v našem případě DC A). Není to tak špatné, jak to zní. Mějte prosím na paměti, že v prostředí all-Galera bude zápis zpomalen latencí mezi uzly umístěnými v různých datových centrech. Postiženy budou i místní zápisy. Bude to víceméně stejné zpomalení jako u asynchronního nastavení, ve kterém byste posílali zápisy přes WAN do „master“ datového centra.
Použití asynchronní replikace přináší všechny problémy typické pro asynchronní replikaci. Problémem se může stát zpoždění replikace – ne že by Galera byla výkonnější, jde jen o to, že Galera zpomalí provoz prostřednictvím řízení toku, zatímco replikace nemá žádný mechanismus, který by omezil provoz na hlavním serveru.
Dalším problémem je převzetí služeb při selhání:pokud by selhal „hlavní“ uzel Galera (ten, který funguje jako hlavní uzel pro podřízené v jiných datových centrech), musí být vytvořen nějaký mechanismus pro přesměrování podřízených zařízení na jiný funkční hlavní uzel. Může to být nějaký skript, je také možné zkusit něco s VIP, kde „slave“ cluster Galera podřídí virtuální IP, která je vždy přiřazena živému uzlu Galera v „master“ clusteru.
Hlavní výhodou takového nastavení je, že odstraníme propojení WAN Galera, což znamená, že náš „master“ cluster nebude zpomalován tím, že některé uzly jsou geograficky odděleny. Jak jsme zmínili, ztrácíme schopnost zapisovat ve všech datových centrech, ale latenční zápis přes WAN je stejný jako zápis lokálně do clusteru Galera, který se rozprostírá přes WAN. V důsledku toho by se měla zlepšit celková latence. Asynchronní replikace je také méně zranitelná vůči nestabilním sítím. V nejhorším případě se replikační spojení přeruší a bude znovu vytvořeno, když se sítě sblíží.
Jak navrhnout replikaci MySQL pro nestabilní síť?
V předchozí části jsme se zabývali clusterem Galera a jedním řešením bylo použití asynchronní replikace. Jak to vypadá v nastavení prosté asynchronní replikace? Podívejme se, jak může nestabilní síť způsobit největší narušení v nastavení replikace.
Za prvé, latence – jeden z hlavních bolestivých bodů pro Galera Cluster. V případě replikace je to téměř bez problému. Pokud nepoužíváte semisynchronní replikaci - v takovém případě zvýšená latence zpomalí zápisy. V asynchronní replikaci nemá latence žádný vliv na výkon zápisu. Může to však mít určitý dopad na zpoždění replikace. Není to nic tak významného, jako tomu bylo u Galery, ale můžete očekávat více špiček zpoždění a celkově méně stabilní výkon replikace, pokud síť mezi uzly trpí vysokou latencí. To je většinou způsobeno skutečností, že master může také obsluhovat několik zápisů, než může být zahájen přenos dat na slave v síti s vysokou latencí.
Nestabilita sítě může určitě ovlivnit replikační linky, ale opět to není tak kritické. MySQL slave se pokusí znovu připojit ke svým masterům a replikace bude zahájena.
Hlavním problémem replikace MySQL je ve skutečnosti něco, co Galera Cluster řeší interně – síťové dělení. O rozdělení sítě hovoříme jako o stavu, kdy jsou segmenty sítě od sebe odděleny. Replikace MySQL využívá jeden jediný zapisovací uzel – master. Bez ohledu na to, jak si své prostředí navrhnete, musíte své zápisy poslat mistrovi. Pokud master není dostupný (z jakýchkoli důvodů), aplikace nemůže dělat svou práci, pokud neběží v nějakém režimu pouze pro čtení. Proto je potřeba vybrat nového mastera co nejdříve. Zde se objevují problémy.
Za prvé, jak zjistit, který hostitel je master a který ne. Jedním z obvyklých způsobů je použití proměnné „read_only“ k rozlišení podřízených jednotek od master. Pokud má uzel povolen pouze read_only (set read_only=1), jedná se o slave (protože slave by neměly zpracovávat žádné přímé zápisy). Pokud má uzel zakázáno pouze čtení (nastaveno pouze pro čtení=0), jedná se o master. Aby to bylo bezpečnější, běžným přístupem je nastavit read_only=1 v konfiguraci MySQL – v případě restartu je bezpečnější, když se uzel objeví jako slave. Takový „jazyk“ může být srozumitelný proxy serverům, jako je ProxySQL nebo MaxScale.
Podívejme se na příklad.
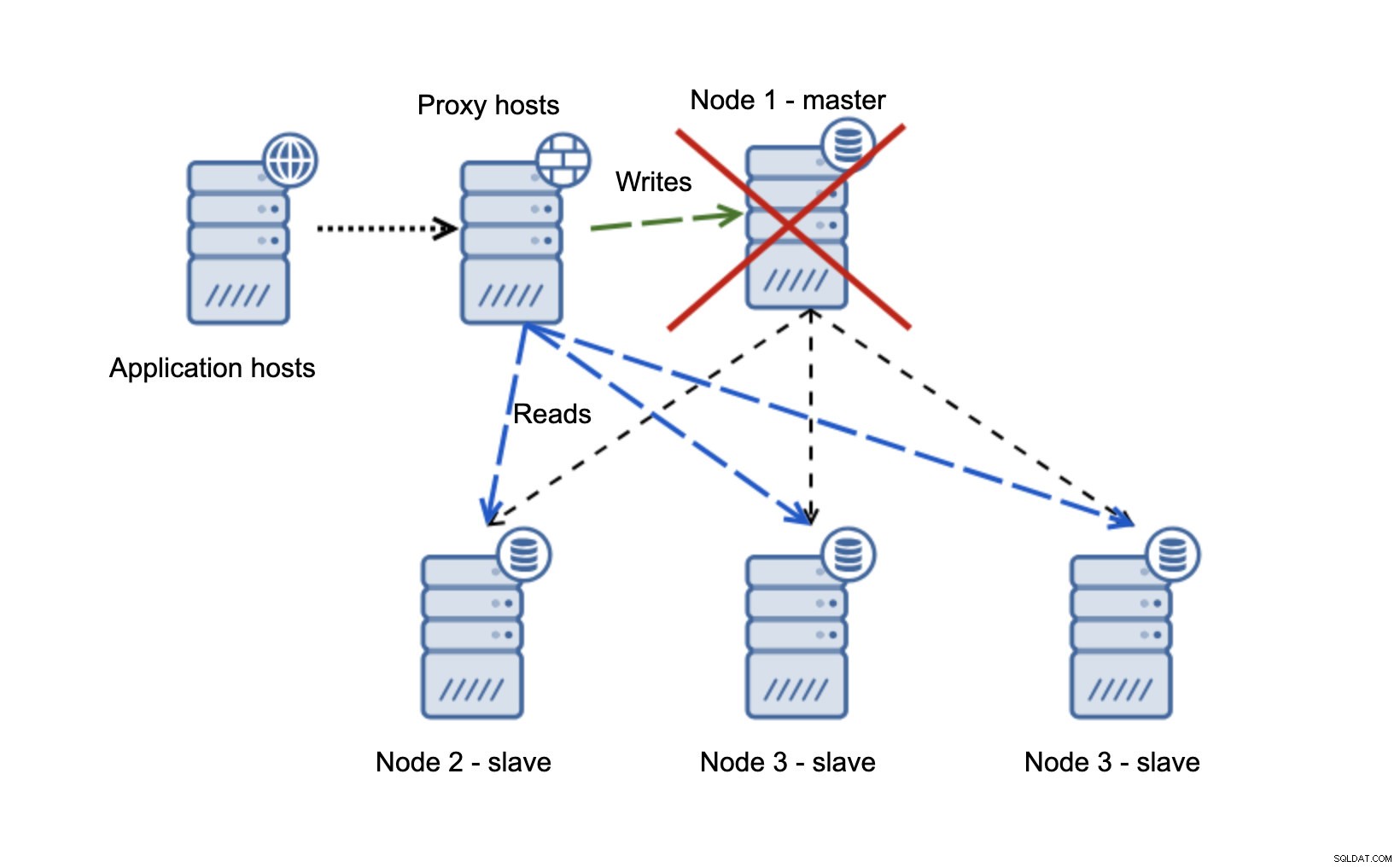
Máme hostitele aplikací, kteří se připojují k vrstvě proxy. Proxy provádějí rozdělení čtení/zápisu, posílají SELECTy na podřízené jednotky a zapisují na master. Pokud je hlavní server mimo provoz, provede se převzetí služeb při selhání, povýší se nový hlavní server, vrstva proxy to zjistí a začne odesílat zápisy do jiného uzlu.
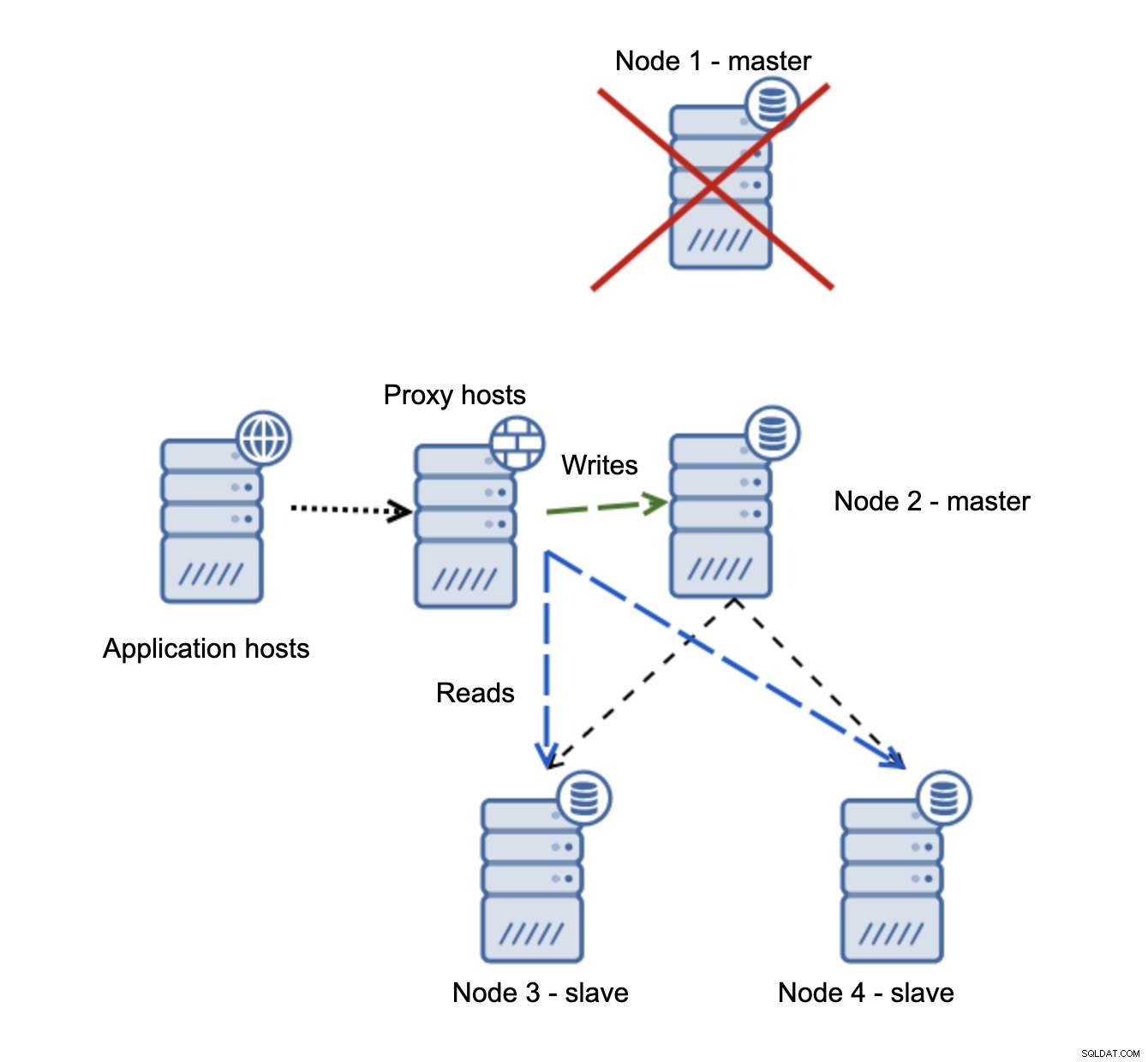
Pokud se node1 restartuje, objeví se read_only=1 a bude detekován jako slave. Není to ideální, protože se nereplikuje, ale je přijatelné. V ideálním případě by se starý mistr neměl vůbec objevit, dokud nebude přestavěn a zotročen novým mistrem.
Mnohem problematičtější situace je, pokud musíme řešit rozdělení sítě. Zvažme stejné nastavení:aplikační vrstva, proxy vrstva a databáze.
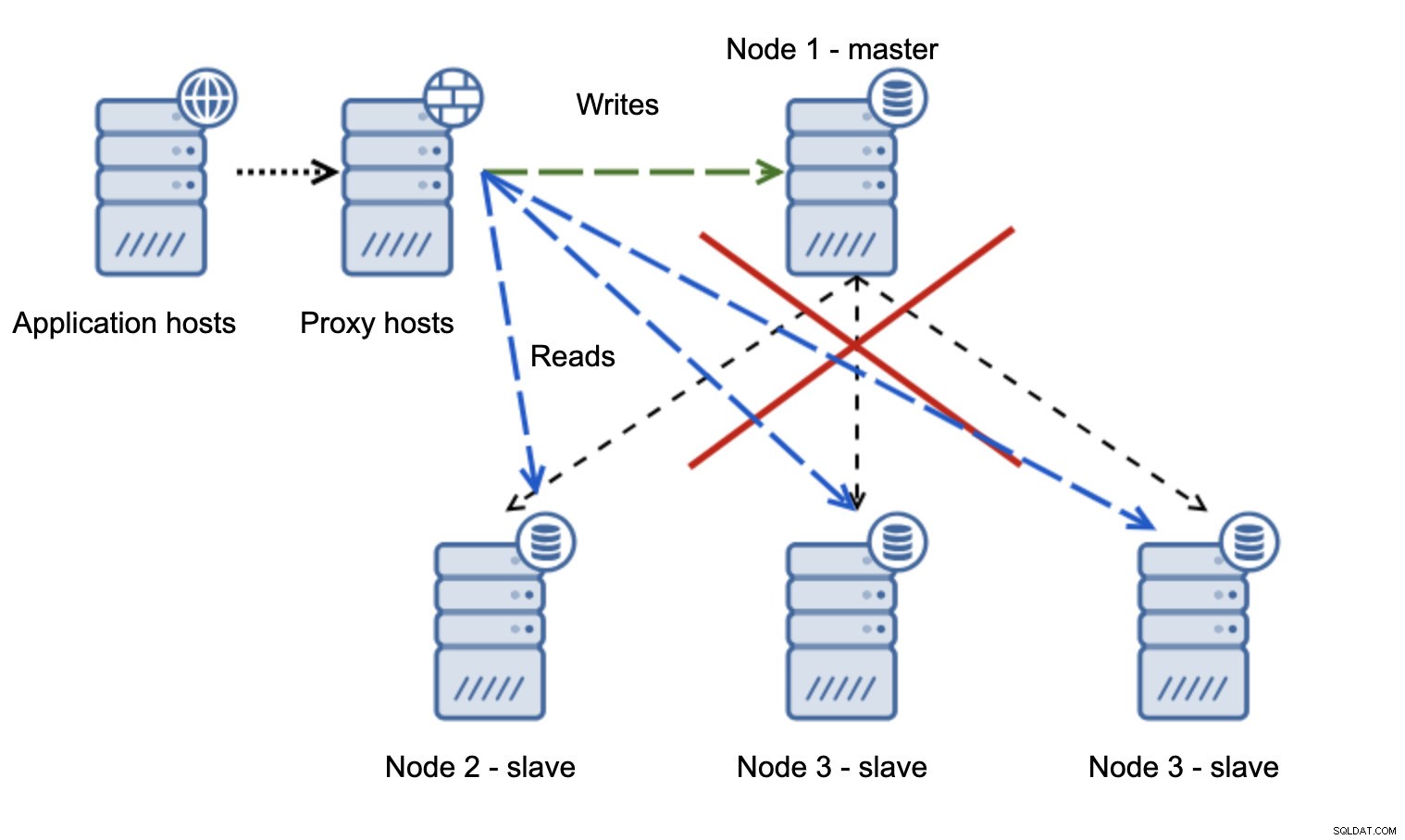
Když síť způsobí, že master není dosažitelný, aplikace není použitelná, protože se do cíle nedostanou žádné zápisy. Nový master je povýšen, zápisy jsou přesměrovány na něj. Co se stane, když problémy se sítí přestanou a starý master bude dosažitelný? Nebylo zastaveno, proto stále používá read_only=0:
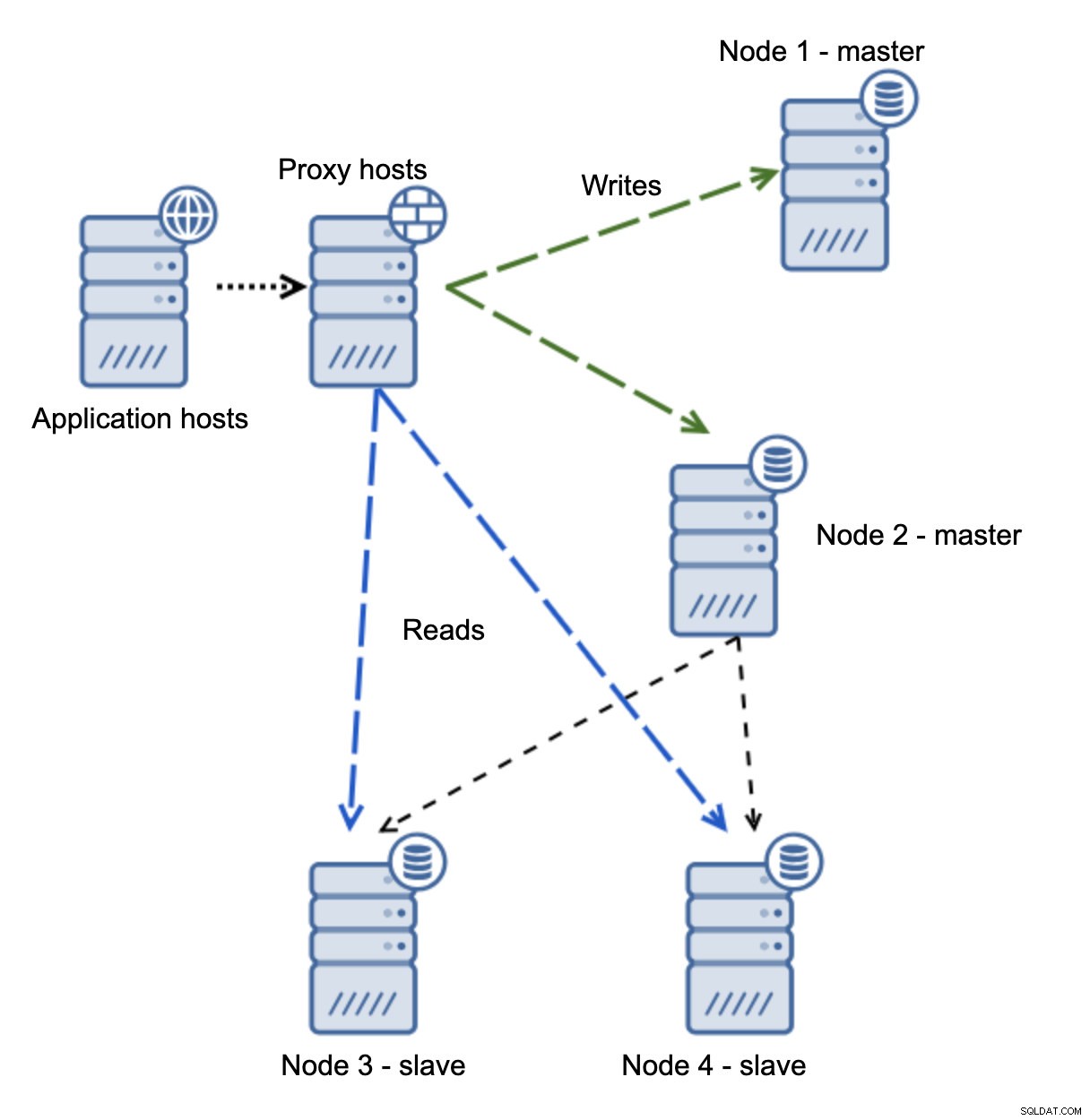
Nyní jste skončili v rozděleném mozku, když byly zápisy směrovány do dvou uzlů. Tato situace je velmi špatná, protože sloučení odlišných datových sad může chvíli trvat a je to poměrně složitý proces.
Co lze udělat, abyste se tomuto problému vyhnuli? Neexistuje žádná stříbrná kulka, ale lze podniknout určité kroky, aby se minimalizovala pravděpodobnost, že dojde k rozdělení mozku.
Za prvé, můžete být chytřejší v detekci stavu masteru. Jak to vidí otroci? Mohou se z toho replikovat? Možná se některé z podřízených jednotek stále mohou připojit k masteru, což znamená, že master je v provozu nebo alespoň umožňuje jeho zastavení, pokud by to bylo nutné. A co proxy vrstva? Vidí všechny uzly proxy hlavní server jako nedostupný? Pokud se některé stále mohou připojit, můžete zkusit využít tyto uzly k ssh do hlavního serveru a zastavit jej před převzetím služeb při selhání?
Software pro správu převzetí služeb při selhání může být také chytřejší při zjišťování stavu sítě. Možná využívá RAFT nebo nějaký jiný klastrovací protokol k vytvoření klastru s podporou kvora. Pokud software pro správu převzetí služeb při selhání dokáže detekovat rozdělený mozek, může také na základě toho provést některé akce, jako je například nastavení všech uzlů v rozděleném segmentu na pouze pro čtení, aby se zajistilo, že starý hlavní server se nebude zobrazovat jako zapisovatelný, když se sítě sblíží.
Můžete také zahrnout nástroje jako Consul nebo Etcd k uložení stavu clusteru. Proxy vrstvu lze nakonfigurovat tak, aby používala data z Consul, nikoli stav proměnné read_only. Bude pak na softwaru pro správu převzetí služeb při selhání, aby provedl nezbytné změny v aplikaci Consul, aby všechny proxy posílaly provoz do správného nového hlavního serveru.
Některé z těchto rad lze dokonce kombinovat, aby byla detekce selhání ještě spolehlivější. Celkově vzato je možné minimalizovat šance, že replikační cluster bude trpět nespolehlivými sítěmi.
Jak vidíte, bez ohledu na to, zda mluvíme o Galera nebo MySQL Replication, nestabilní sítě se mohou stát vážným problémem. Na druhou stranu, pokud prostředí navrhnete správně, můžete jej stále zprovoznit. Doufáme, že vám tento příspěvek na blogu pomůže vytvořit prostředí, která budou fungovat stabilně, i když sítě nebudou.