Jednou z mnoha nových funkcí zavedených v SQL Server 2008 byla komprese dat. Komprese na úrovni řádků nebo stránky poskytuje příležitost k úspoře místa na disku s tím, že ke kompresi a dekomprimaci dat bude potřeba trochu více CPU. Často se tvrdí, že většina systémů je vázána na IO, nikoli na CPU, takže kompromis stojí za to. Úlovek? Abyste mohli používat kompresi dat, museli jste být na Enterprise Edition. S vydáním SQL Server 2016 SP1 se to změnilo! Pokud používáte Standard Edition SQL Server 2016 SP1 a vyšší, můžete nyní použít kompresi dat. K dispozici je také nová vestavěná funkce pro kompresi, COMPRESS (a její protějšek DECOMPRESS). Komprese dat nefunguje na datech mimo řádek, takže pokud máte v tabulce sloupec jako NVARCHAR(MAX) s hodnotami obvykle většími než 8 000 bajtů, tato data nebudou zkomprimována (díky Adamu Machanicovi za toto připomenutí) . Funkce COMPRESS tento problém řeší a komprimuje data až do velikosti 2 GB. Navíc, i když bych tvrdil, že funkce by se měla používat pouze pro velká data mimo řádky, považoval jsem srovnání přímo s kompresí řádků a stránek za užitečný experiment.
NASTAVENÍ
Pro testovací data pracuji ze skriptu, který dříve používal Aaron Bertrand, ale provedl jsem několik úprav. Vytvořil jsem samostatnou databázi pro testování, ale můžete použít tempdb nebo jinou ukázkovou databázi, a pak jsem začal s tabulkou Customers, která má tři sloupce NVARCHAR. Uvažoval jsem o vytvoření větších sloupců a jejich naplnění řetězci opakujících se písmen, ale použití čitelného textu poskytuje vzorek, který je realističtější, a poskytuje tak větší přesnost.
Poznámka: Pokud máte zájem o implementaci komprese a chcete vědět, jak to ovlivní úložiště a výkon ve vašem prostředí, VELICE DOPORUČUJI, ABYSTE JI VYTESTOVALI. Dávám vám metodologii s ukázkovými daty; implementace tohoto ve vašem prostředí by neměla vyžadovat další práci.
Níže si všimnete, že po vytvoření databáze povolujeme Query Store. Proč vytvářet samostatnou tabulku, abychom zkoušeli sledovat naše metriky výkonu, když můžeme použít pouze funkce zabudované do SQL Serveru?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Nyní nastavíme některé věci v databázi:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
S vytvořenou tabulkou přidáme některá data, ale místo 1 milionu přidáváme 5 milionů řádků. Na mém notebooku to trvá asi osm minut.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Nyní vytvoříme další tři tabulky:jednu pro kompresi řádků, jednu pro kompresi stránek a jednu pro funkci COMPRESS. Všimněte si, že pomocí funkce COMPRESS musíte vytvořit sloupce jako datové typy VARBINARY. V důsledku toho v tabulce nejsou žádné indexy bez klastrů (protože nemůžete vytvořit klíč indexu ve sloupci varbinary).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Dále zkopírujeme data z [dbo].[Customers] do dalších tří tabulek. Toto je přímý INSERT pro naše tabulky stránek a řádků a trvá asi dvě až tři minuty pro každý INSERT, ale u funkce COMPRESS je problém se škálovatelností:pokoušet se vložit 5 milionů řádků jedním tahem prostě není rozumné. Skript níže vloží řádky v dávkách po 50 000 a vloží pouze 1 milion řádků místo 5 milionů. Vím, to znamená, že tady pro srovnání nejsme doopravdy jablka na jablka, ale jsem s tím v pořádku. Vložení 1 milionu řádků trvá na mém počítači 10 minut; můžete skript vyladit a vložit 5 milionů řádků pro své vlastní testy.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Se všemi našimi tabulkami můžeme provést kontrolu velikosti. V tuto chvíli jsme neimplementovali kompresi ROW nebo PAGE, ale byla použita funkce COMPRESS:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
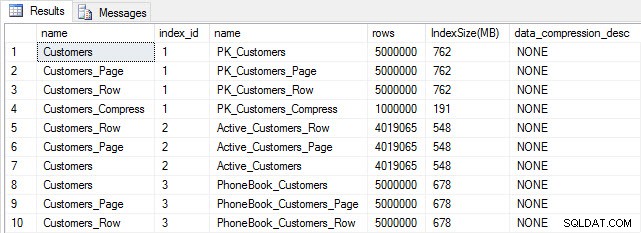 Velikost tabulky a indexu po vložení
Velikost tabulky a indexu po vložení
Podle očekávání mají všechny tabulky kromě Customers_Compress přibližně stejnou velikost. Nyní znovu sestavíme indexy ve všech tabulkách a zavedeme kompresi řádků a stránek na Customers_Row a Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Pokud zkontrolujeme velikost tabulky po kompresi, nyní můžeme vidět naše úspory místa na disku:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
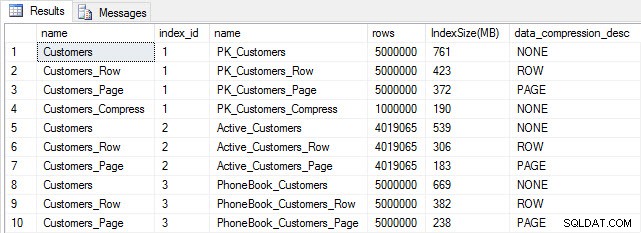
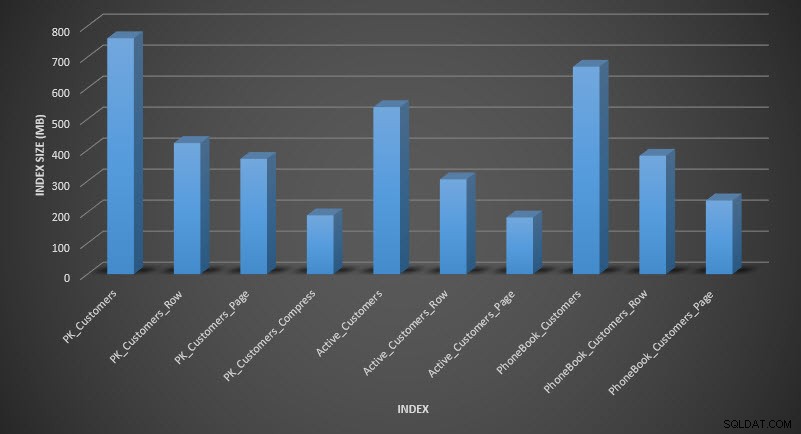 Velikost indexu po kompresi
Velikost indexu po kompresi
Podle očekávání komprese řádků a stránek výrazně snižuje velikost tabulky a jejích indexů. Nejvíce místa nám ušetřila funkce COMPRESS – seskupený index má jednu čtvrtinu velikosti původní tabulky.
KONTROLA VÝKONU DOTAZU
Než otestujeme výkon dotazu, povšimněte si, že můžeme použít Query Store a podívat se na výkon INSERT a REBUILD:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
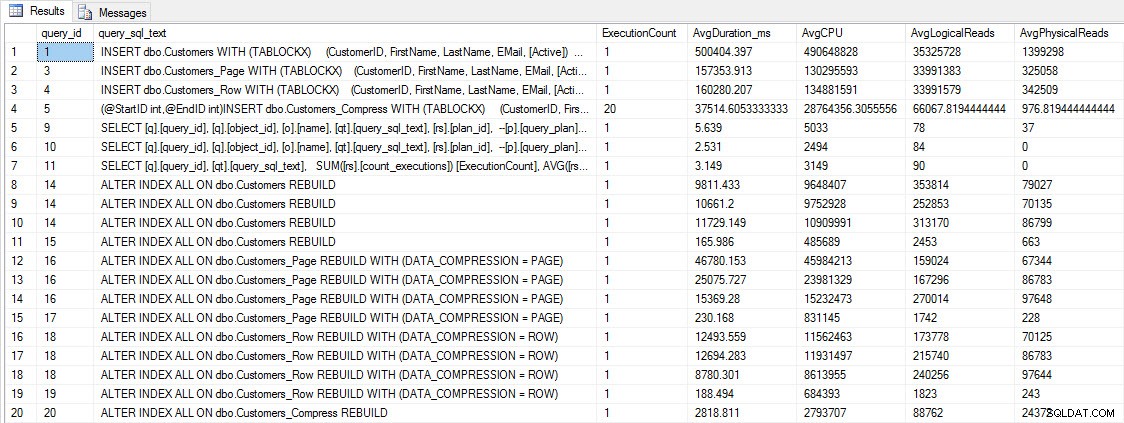 VLOŽIT a PŘESTAVIT metriky výkonu
VLOŽIT a PŘESTAVIT metriky výkonu
I když jsou tato data zajímavá, jsem zvědavější na to, jak komprese ovlivňuje mé každodenní SELECT dotazy. Mám sadu tří uložených procedur, z nichž každá má jeden dotaz SELECT, takže je použit každý index. Vytvořil jsem tyto procedury pro každou tabulku a pak jsem napsal skript pro získání hodnot pro jméno a příjmení pro použití pro testování. Zde je skript pro vytvoření procedur.
Jakmile máme uložené procedury vytvořené, můžeme spustit níže uvedený skript a zavolat je. Spusťte to a počkejte pár minut…
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Po několika minutách se podívejte, co je v Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Uvidíte, že většina uložených procedur se provedla pouze 20krát, protože dvě procedury proti [dbo].[Customers_Compress] jsou skutečně pomalý. To není překvapení; [FirstName] ani [LastName] nejsou indexovány, takže jakýkoli dotaz bude muset prohledat tabulku. Nechci, aby tyto dva dotazy zpomalily mé testování, takže upravím pracovní vytížení a zakomentuji EXEC [dbo].[usp_FindActiveCustomer_CS] a EXEC [dbo].[usp_FindAnyCustomer_CS] a pak to spustím znovu. Tentokrát to nechám běžet asi 10 minut, a když se znovu podívám na výstup Query Store, tak už mám dobrá data. Níže jsou uvedena nezpracovaná čísla a níže jsou oblíbené grafy manažerů.
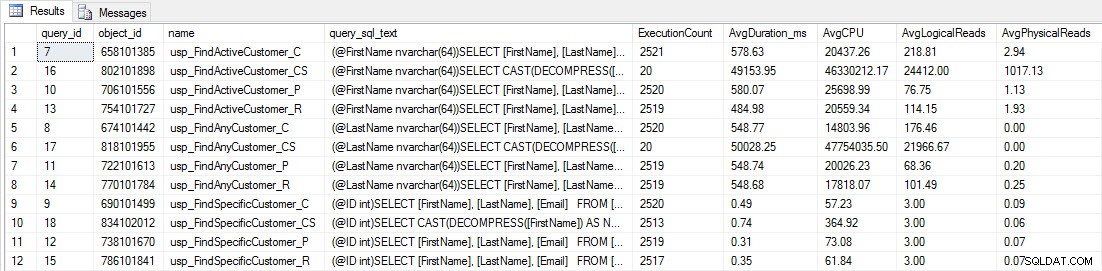 Údaje o výkonu z Query Store
Údaje o výkonu z Query Store
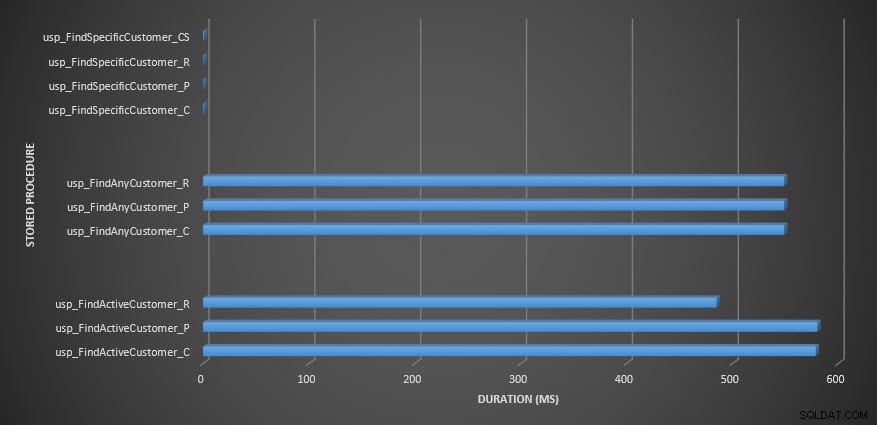 Trvání uložené procedury
Trvání uložené procedury
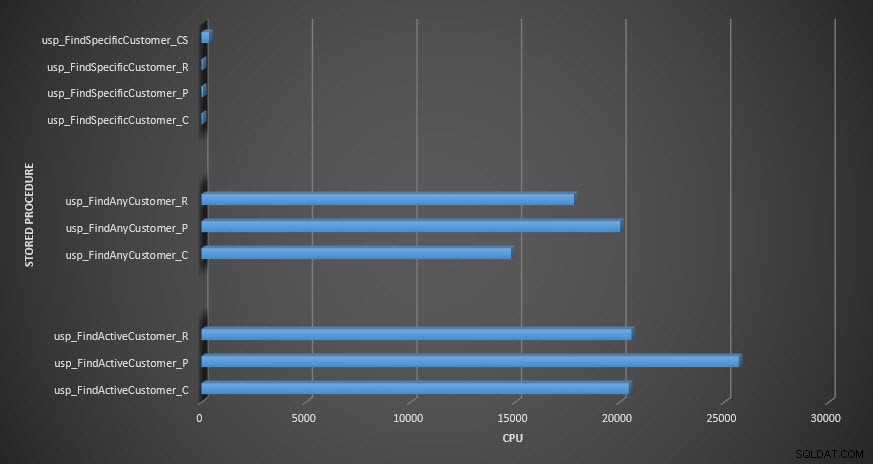 CPU s uloženou procedurou
CPU s uloženou procedurou
Připomenutí:Všechny uložené procedury končící na _C pocházejí z nekomprimované tabulky. Procedury končící na _R jsou řádková komprimovaná tabulka, ty končící _P jsou komprimované na stránce a procedury s _CS používají funkci COMPRESS (odstranil jsem výsledky pro uvedenou tabulku pro usp_FindAnyCustomer_CS a usp_FindActiveCustomer_CS, protože zkreslily graf natolik, že jsme ztratili rozdíly ve zbývajících údajích). Procedury usp_FindAnyCustomer_* a usp_FindActiveCustomer_* používaly neklastrované indexy a vracely tisíce řádků pro každé spuštění.
Očekával jsem, že doba trvání bude vyšší pro procedury usp_FindAnyCustomer_* a usp_FindActiveCustomer_* proti řádkovým a stránkovým komprimovaným tabulkám ve srovnání s nekomprimovanou tabulkou, kvůli režii dekomprimace dat. Data úložiště dotazů nepodporují moje očekávání – doba trvání těchto dvou uložených procedur je v těchto třech tabulkách zhruba stejná (nebo v jednom případě méně!). Logická IO pro dotazy byla téměř stejná napříč nekomprimovanými tabulkami a tabulkami s komprimovanými stránkami a řádky.
Pokud jde o CPU, v uložených procedurách usp_FindActiveCustomer a usp_FindAnyCustomer byla u komprimovaných tabulek vždy vyšší. Procesor byl srovnatelný pro proceduru usp_FindSpecificCustomer, což bylo vždy jednoduché vyhledávání proti klastrovanému indexu. Všimněte si vysokého CPU (ale relativně krátkého trvání) procedury usp_FindSpecificCustomer oproti tabulce [dbo].[Customer_Compress], která vyžadovala funkci DECOMPRESS pro zobrazení dat v čitelném formátu.
SOUHRN
Dodatečný CPU potřebný k načtení komprimovaných dat existuje a lze jej měřit pomocí Query Store nebo tradičních základních metod. Na základě tohoto počátečního testování je CPU srovnatelné pro jednotlivá vyhledávání, ale zvyšuje se s více daty. Chtěl jsem přinutit SQL Server, aby dekomprimoval více než jen 10 stránek – chtěl jsem alespoň 100. Provedl jsem varianty tohoto skriptu, kde byly vráceny desítky tisíc řádků a zjištění byla v souladu s tím, co vidíte zde. Očekávám, že pro zjištění významných rozdílů v trvání kvůli času na dekomprimaci dat by dotazy musely vracet stovky tisíc nebo miliony řádků. Pokud používáte systém OLTP, nechcete vracet tolik řádků, takže zde uvedené testy by vám měly poskytnout představu o tom, jak může komprese ovlivnit výkon. Pokud jste v datovém skladu, pak pravděpodobně uvidíte delší dobu trvání spolu s vyšším CPU při vracení velkých datových sad. Zatímco funkce COMPRESS poskytuje značnou úsporu místa ve srovnání s kompresí stránek a řádků, snížení výkonu, pokud jde o CPU, a nemožnost indexovat komprimované sloupce kvůli jejich datovému typu, činí tuto funkci životaschopnou pouze pro velké objemy dat, které nebudou hledali.