Nechápejte mě špatně – miluji vlastnost Actual Rows Read, kterou jsme viděli přicházet v plánech provádění SQL Serveru na konci roku 2015. Ale v SQL Server 2016 SP1, před necelými dvěma měsíci (a vzhledem k tomu, že jsme mezitím měli Vánoce, myslím, že od té doby se moc času nepočítá), jsme získali další vzrušující doplněk – Odhadovaný počet řádků ke čtení (aha, a to je poněkud v důsledku položky Connect, kterou jsem odeslal, což dokazuje, že položky Connect Items stojí za odeslání, a zároveň způsobilo, že tento příspěvek je vhodný pro úterý T-SQL, které pořádá Brent Ozar (@brento) na téma položek Connect ).
Nechápejte mě špatně – miluji vlastnost Actual Rows Read, kterou jsme viděli přicházet v plánech provádění SQL Serveru na konci roku 2015. Ale v SQL Server 2016 SP1, před necelými dvěma měsíci (a vzhledem k tomu, že jsme mezitím měli Vánoce, myslím, že od té doby se moc času nepočítá), jsme získali další vzrušující doplněk – Odhadovaný počet řádků ke čtení (aha, a to je poněkud v důsledku položky Connect, kterou jsem odeslal, což dokazuje, že položky Connect Items stojí za odeslání, a zároveň způsobilo, že tento příspěvek je vhodný pro úterý T-SQL, které pořádá Brent Ozar (@brento) na téma položek Connect ).
Pojďme si to zrekapitulovat... když SQL Engine přistupuje k datům v tabulce, používá buď operaci Scan nebo Seek operaci. A pokud toto hledání nemá predikát hledání, který má přístup nanejvýš k jednomu řádku (protože hledá shodu na sadě sloupců – může to být jen jeden sloupec – o kterých je známo, že jsou jedinečné), pak hledání provede RangeScan a chová se stejně jako skenování, jen napříč podmnožinou řádků, které vyhověl predikátu hledání.
S řádky, které vyhověl predikátu hledání (v případě operace hledání RangeScan) nebo se všemi řádky v tabulce (v případě operace skenování), se zachází v podstatě stejným způsobem. Obojí může být předčasně ukončeno, pokud od operátora po jeho levici nejsou požadovány žádné další řádky, například pokud některý horní operátor již získal dostatek řádků nebo pokud operátor sloučení nemá žádné další řádky, se kterými by se mohl porovnávat. A oba mohou být dále filtrovány pomocí zbytkového predikátu (zobrazeného jako vlastnost „Predikát“), než se řádky vůbec obslouží operátorem Scan/Seek. Vlastnosti „Počet řádků“ a „Odhadovaný počet řádků“ by nám řekly, kolik řádků operátor očekává, že vytvoří, ale neměli jsme žádné informace o tom, jak mohou být řádky filtrovány pouze predikátem hledání. Viděli jsme TableCardinality, ale to bylo opravdu užitečné pouze pro operátory skenování, kde existovala šance, že skenování prohledá celou tabulku a najde potřebné řádky. Pro Seeks to nebylo vůbec užitečné.

Dotaz, který zde spouštím, je proti databázi WideWorldImporters a je:
SELECT COUNT(*)FROM Sales.OrdersWHERE SalespersonPersonID =7AND YEAR(Date Order) =2013AND MONTH(OrderDate) =4;
Navíc mám ve hře index:
VYTVOŘTE NENCLUSTEROVANÝ INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders (SalespersonPersonID, OrderDate);
Tento index pokrývá – dotaz nepotřebuje žádné další sloupce, aby získal odpověď – a byl navržen tak, aby bylo možné použít predikát hledání na SalespersonPersonID a rychle filtrovat data na menší rozsah. Funkce na OrderDate znamenají, že tyto dva poslední predikáty nelze použít v predikátu hledání, takže jsou místo toho zařazeny do reziduálního predikátu. Lepší dotaz by filtroval tato data pomocí OrderDate>='20130401' A OrderDate <'20130501', ale já si zde představuji scénář, který je až příliš běžný…
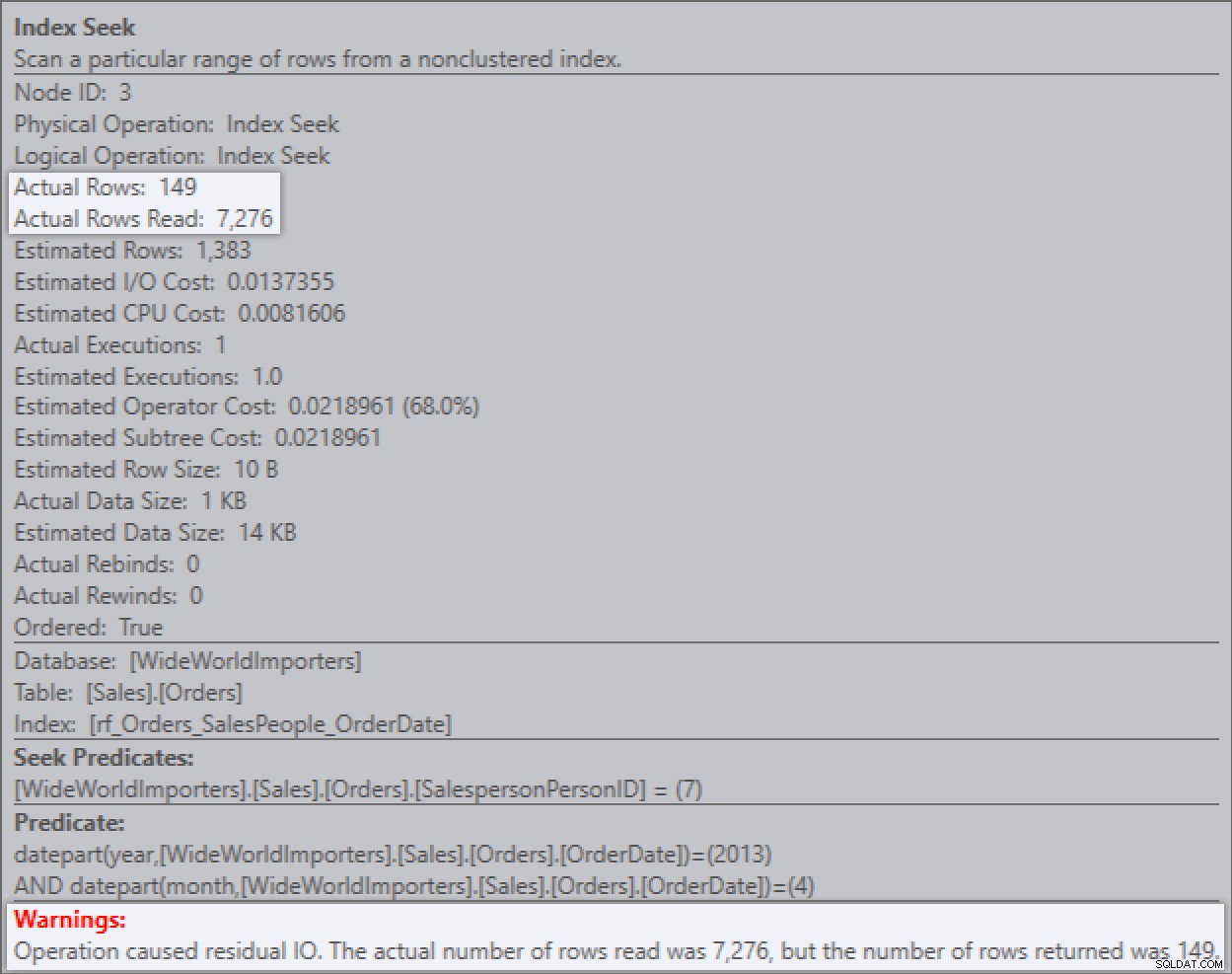
Nyní, když spustím dotaz, vidím dopad zbytkových predikátů. Plan Explorer dokonce poskytuje užitečné varování, o kterém jsem psal dříve.

Velmi jasně vidím, že RangeScan má 7 276 řádků a že zbytkový predikát to filtruje až na 149. Průzkumník plánu zobrazuje další informace o tomto v popisku:
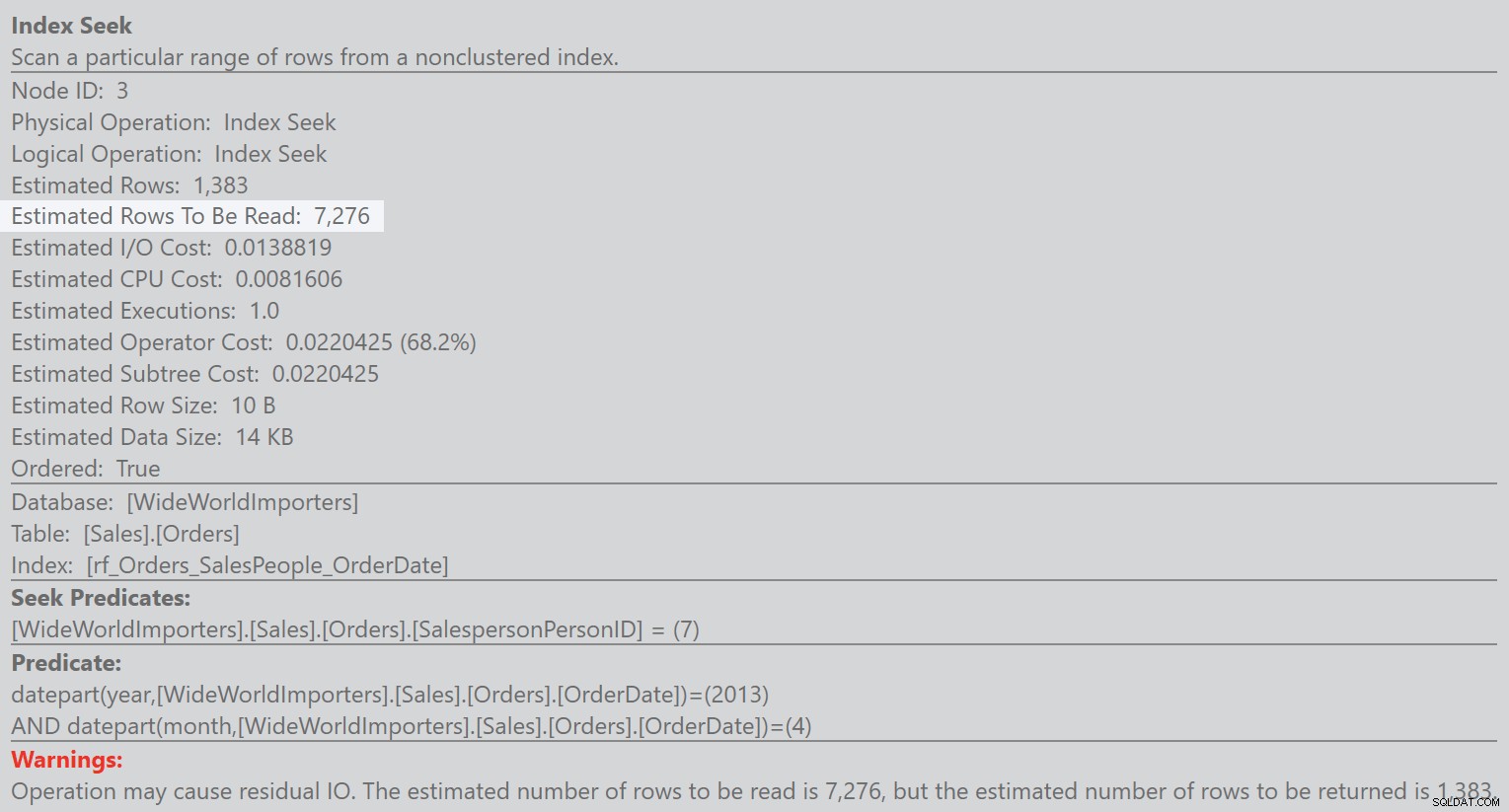
Ale bez spuštění dotazu tyto informace nevidím. prostě to tam není. Vlastnosti v odhadovaném plánu jej nemají:
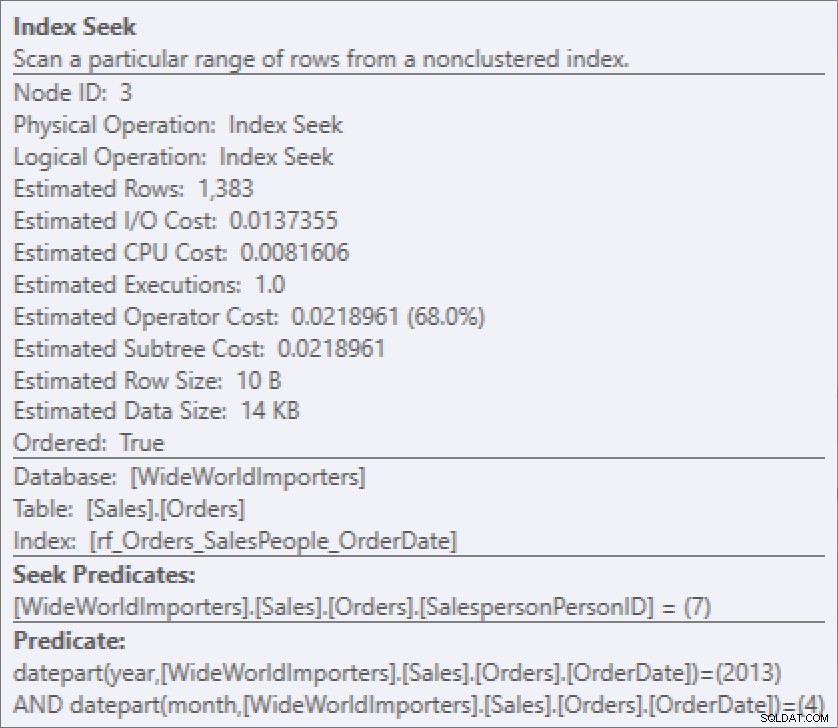
A jsem si jistý, že vám to nemusím připomínat – tyto informace nejsou ani v mezipaměti plánu. Po získání plánu z mezipaměti pomocí:
SELECT p.query_plan, t.textFROM sys.dm_exec_cached_plans cCROSS APPLY sys.dm_exec_query_plan(c.plan_handle) pCROSS APPLY sys.dm_exec_sql_text(c.plan_handle') tWHERE>YEAR%'textOtevřel jsem to a opravdu, žádné známky té hodnoty 7 276. Vypadá úplně stejně jako odhadovaný plán, který jsem právě ukázal.
Získání plánů z mezipaměti je místo, kde se odhadované hodnoty uplatní. Nejde jen o to, že bych raději ve skutečnosti nespouštěl potenciálně drahé dotazy na databáze zákazníků. Dotazovat se na mezipaměť plánu je jedna věc, ale spouštění dotazů za účelem získání skutečných údajů – to je mnohem těžší.
S nainstalovaným SQL 2016 SP1 díky této položce Connect nyní vidím vlastnost Odhadovaný počet řádků ke čtení v odhadovaných plánech a v mezipaměti plánů. Zde zobrazený popis operátora je převzat z mezipaměti a snadno vidím, že vlastnost Odhad ukazuje 7 276, stejně jako zbytkové varování:
To je něco, co bych mohl udělat na zákaznickém boxu a hledat v mezipaměti situace v problematických plánech, kde poměr odhadovaného počtu řádků ke čtení a odhadovaného počtu řádků není skvělý. Potenciálně by někdo mohl vytvořit proces, který by zkontroloval každý plán v mezipaměti, ale já jsem to neudělal.
Bystré čtení si všimne, že skutečných řádků, které vyšly z tohoto operátora, bylo 149, což bylo mnohem méně než odhadovaných 1382,56. Ale když hledám zbytkové predikáty, které musí kontrolovat příliš mnoho řádků, poměr 1 382,56 :7 276 je stále významný.
Nyní, když jsme zjistili, že tento dotaz je neúčinný, aniž bychom jej museli spouštět, způsob, jak jej opravit, je zajistit, aby byl reziduální predikát dostatečně SARGable. Tento dotaz…
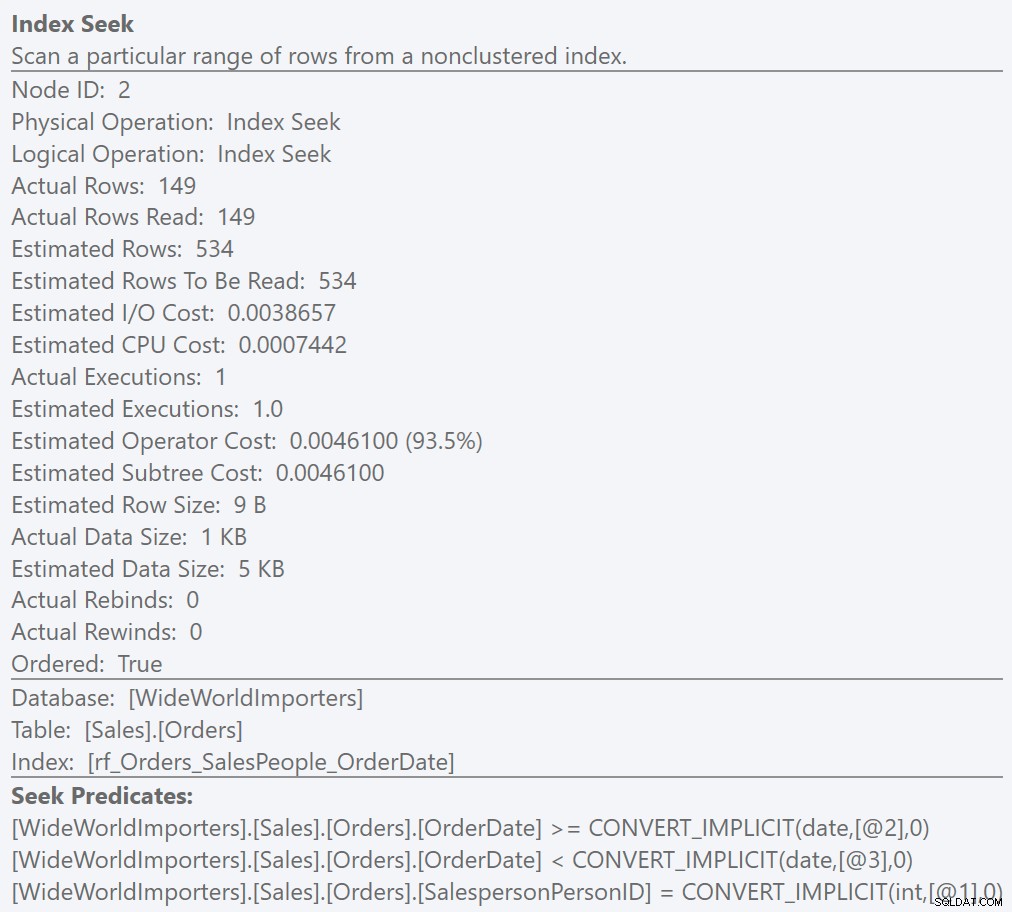
SELECT COUNT(*) FROM Sales.OrdersWHERE SalespersonPersonID =7 AND OrderDate>='20130401' AND OrderDate <'20130501';…poskytuje stejné výsledky a nemá zbytkový predikát. V této situaci je odhadovaný počet řádků ke čtení identický s odhadovaným počtem řádků a neefektivita je pryč:
Jak již bylo zmíněno dříve, tento příspěvek je součástí úterý T-SQL tohoto měsíce. Proč se tam nezamířit a podívat se, jaké další požadavky na funkce byly nedávno schváleny?