Tento článek je čtvrtý ze série o prahových hodnotách optimalizace. Série pokrývá seskupování a agregaci dat, vysvětluje různé algoritmy, které může SQL Server používat, a model kalkulace, který mu pomáhá při výběru mezi algoritmy. V tomto článku se zaměřím na úvahy o paralelismu. Zabývám se různými strategiemi paralelismu, které může SQL Server používat, prahovými hodnotami pro výběr mezi sériovým a paralelním plánem a logikou kalkulace, kterou SQL Server používá pomocí konceptu zvaného stupeň paralelismu pro kalkulaci (DOP pro kalkulaci nákladů).
Ve svých příkladech budu nadále používat tabulku dbo.Orders ve vzorové databázi PerformanceV3. Před spuštěním příkladů v tomto článku spusťte následující kód, abyste odstranili několik nepotřebných indexů:
PUSTIT INDEX, POKUD EXISTUJE idx_nc_sid_od_cid NA dbo.Orders;PUSTIT INDEX, POKUD EXISTUJE idx_unc_od_oid_i_cid_eid NA dbo.Orders;
Jediné dva indexy, které by v této tabulce měly zůstat, jsou idx_cl_od (seskupený s datem objednávky jako klíčem) a PK_Orders (nesdružený s orderid jako klíčem).
Paralelní strategie
Kromě toho, že si musí SQL Server vybrat mezi různými strategiemi seskupování a agregace (předobjednaný Stream Aggregate, Sort + Stream Aggregate, Hash Aggregate), musí si také vybrat, zda půjde se sériovým nebo paralelním plánem. Ve skutečnosti si může vybrat mezi několika různými strategiemi paralelismu. SQL Server používá nákladovou logiku, která vede k prahovým hodnotám optimalizace, které za různých podmínek upřednostňují jednu strategii před ostatními. Již jsme podrobně probrali logiku kalkulace, kterou SQL Server používá v sériových plánech v předchozích dílech série. V této části představím řadu strategií paralelismu, které může SQL Server použít pro zpracování seskupování a agregace. Zpočátku se nebudu zabývat podrobnostmi logiky kalkulace, spíše popíšu dostupné možnosti. Později v článku vysvětlím, jak kalkulační vzorce fungují, a důležitý faktor v těchto vzorcích nazývaný DOP pro kalkulaci.
Jak se později dozvíte, SQL Server ve svých kalkulačních vzorcích pro paralelní plány bere v úvahu počet logických CPU ve stroji. V mých příkladech, pokud neřeknu jinak, předpokládám, že cílový systém má 8 logických CPU. Pokud si chcete vyzkoušet příklady, které poskytnu, abyste získali stejné plány a hodnoty nákladů jako já, musíte kód spustit také na počítači s 8 logickými CPU. Pokud váš stroj náhodou má jiný počet CPU, můžete emulovat stroj s 8 CPU – pro účely kalkulace – takto:
DBCC OPTIMIZER_WHATIF(CPU, 8);
I když tento nástroj není oficiálně zdokumentován a podporován, je docela vhodný pro účely výzkumu a učení.
Tabulka Objednávky v naší vzorové databázi má 1 000 000 řádků s ID objednávek v rozsahu 1 až 1 000 000. Abych demonstroval tři různé strategie paralelismu pro seskupování a agregaci, vyfiltruji objednávky, jejichž ID objednávky je větší nebo rovno 300 001 (700 000 shod), a seskupím data třemi různými způsoby (podle zákazníka [20 000 skupin před filtrováním], podle empid [500 skupin] a podle shipperid [5 skupin]) a vypočítat počet objednávek na skupinu.
Pomocí následujícího kódu vytvořte indexy pro podporu seskupených dotazů:
VYTVOŘIT INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);VYTVOŘIT INDEX idx_oid_i_sid ON dbo.Orders(orderid) INCLUDE(shipperid);VYTVOŘIT INDEX idx_oid_i_idOrd Idbo. před>Následující dotazy implementují výše uvedené filtrování a seskupování:
-- Dotaz 1:Serial SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Dotaz 2:Paralelní, nikoli lokální/globální SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid; -- Dotaz 3:Lokální paralelní globální paralelní SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Dotaz 4:Lokální paralelní globální sériové SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid;Všimněte si, že Dotaz 1 a Dotaz 2 jsou stejné (oba seskupené podle custid), pouze první vynutí sériový plán a druhý získá paralelní plán na stroji s 8 CPU. Tyto dva příklady používám k porovnání sériové a paralelní strategie pro stejný dotaz.
Obrázek 1 ukazuje odhadované plány pro všechny čtyři dotazy:
Obrázek 1:Strategie paralelního
Prozatím si nedělejte starosti s hodnotami nákladů zobrazenými na obrázku a zmínkou o termínu DOP pro kalkulaci. k těm se dostanu později. Nejprve se zaměřte na pochopení strategií a rozdílů mezi nimi.
Strategie použitá v sériovém plánu pro Query 1 by vám měla být známá z předchozích dílů série. Plán filtruje relevantní objednávky pomocí vyhledávání v indexu pokrytí, který jste vytvořili dříve. Poté, s odhadovaným počtem řádků, které mají být seskupeny a agregovány, optimalizátor upřednostní strategii Hash Aggregate před strategií Sort + Stream Aggregate.
Plán pro Query 2 používá jednoduchou strategii paralelismu, která využívá pouze jednoho agregačního operátora. Paralelní operátor hledání indexu distribuuje pakety řádků do různých vláken způsobem cyklicky. Každý paket řádků může obsahovat více různých ID zákazníků. Aby jediný agregační operátor mohl vypočítat správné konečné počty skupin, musí všechny řádky, které patří do stejné skupiny, zpracovat stejné vlákno. Z tohoto důvodu se k opětovnému rozdělení toků podle seskupovací sady (custid) používá operátor výměny Parallelism (Repartition Streams). A konečně, operátor výměny Parallelism (Gather Streams) se používá ke shromažďování toků z více vláken do jednoho toku řádků výsledků.
Plány pro Dotaz 3 a Dotaz 4 využívají složitější strategii paralelismu. Plány začínají podobně jako plán pro Dotaz 2, kde paralelní operátor hledání indexu distribuuje pakety řádků do různých vláken. Poté se agregační práce provádí ve dvou krocích:jeden agregační operátor lokálně seskupuje a agreguje řádky aktuálního vlákna (všimněte si člena výsledku partialagg1004) a druhý agregační operátor globálně seskupuje a agreguje výsledky místních agregátů (všimněte si globalagg1005 výsledkový člen). Každý ze dvou agregovaných kroků – místní a globální – může používat kterýkoli z agregačních algoritmů, které jsem popsal dříve v sérii. Oba plány pro Query 3 a Query 4 začínají s místním hash Aggregate a pokračují s globálním Sort + Stream Aggregate. Rozdíl mezi těmito dvěma je v tom, že první z nich používá paralelismus v obou krocích (proto se mezi nimi používá výměna Repartition Streams a výměna Gather Streams po globálním agregátu), a ten pozdější zpracovává lokální agregát v paralelní zóně a globální agregovat v sériové zóně (proto se mezi těmito dvěma používá výměna Gather Streams).
Při průzkumu optimalizace dotazů obecně a konkrétně paralelismu je dobré znát nástroje, které vám umožňují ovládat různé aspekty optimalizace, abyste viděli jejich účinky. Již víte, jak vynutit sériový plán (pomocí nápovědy MAXDOP 1) a jak emulovat prostředí, které má pro účely kalkulace určitý počet logických CPU (DBCC OPTIMIZER_WHATIF, s volbou CPU). Dalším užitečným nástrojem je nápověda k dotazu ENABLE_PARALLEL_PLAN_PREFERENCE (zavedená v SQL Server 2016 SP1 CU2), která maximalizuje paralelismus. Chci tím říct, že pokud je pro dotaz podporován paralelní plán, bude upřednostňován paralelismus ve všech částech plánu, které lze paralelně zpracovávat, jako by byl zdarma. Všimněte si například na obrázku 1, že plán pro Query 4 standardně zpracovává lokální agregát v sériové zóně a globální agregát v paralelní zóně. Zde je stejný dotaz, jen tentokrát s použitou nápovědou k dotazu ENABLE_PARALLEL_PLAN_PREFERENCE (nazýváme ho Dotaz 5):
SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plán pro dotaz 5 je znázorněn na obrázku 2:
Obrázek 2:Maximalizace paralelismu
Všimněte si, že tentokrát jsou místní i globální agregáty zpracovávány v paralelních zónách.
Výběr sériového / paralelního plánu
Připomeňme, že během optimalizace dotazů SQL Server vytvoří více kandidátských plánů a vybere ten s nejnižšími náklady z těch, které vytvořil. Výraz náklady je trochu nesprávné pojmenování, protože kandidátský plán s nejnižšími náklady má být podle odhadů plán s nejnižší dobou běhu, nikoli plán s nejnižším celkovým množstvím použitých zdrojů. Například mezi sériovým kandidátským plánem a paralelním plánem vytvořeným pro stejný dotaz bude paralelní plán pravděpodobně využívat více zdrojů, protože potřebuje používat výměnné operátory, které synchronizují vlákna (distribuovat, přerozdělovat a shromažďovat proudy). Aby však paralelní plán potřeboval na dokončení běhu méně času než sériový plán, musí úspory dosažené prováděním práce s více vlákny převážit práci navíc, kterou vykonávají operátoři výměny. A to se musí odrážet v kalkulačních vzorcích, které SQL Server používá, když je zapojen paralelismus. Není to jednoduchý úkol, který se dělá přesně!
Kromě toho, že náklady na paralelní plán musí být nižší než náklady sériového plánu, aby byly preferovány, musí být náklady na alternativu sériového plánu vyšší nebo rovné prahové hodnotě pro paralelismus . Toto je možnost konfigurace serveru nastavená ve výchozím nastavení na 5, která zabraňuje tomu, aby byly dotazy s poměrně nízkou cenou zpracovány paralelně. Myšlenka je taková, že systém s velkým počtem malých dotazů by celkově více těžil z používání sériových plánů, namísto plýtvání spoustou zdrojů na synchronizaci vláken. Stále můžete mít několik dotazů se sériovými plány spouštěnými současně a efektivně využívat víceprocesorové prostředky stroje. Ve skutečnosti mnoho odborníků na SQL Server rádo zvyšuje prahovou hodnotu nákladů pro paralelismus z výchozích 5 na vyšší hodnotu. Systém provozující poměrně malý počet velkých dotazů současně by mnohem více těžil z používání paralelních plánů.
Abychom to zrekapitulovali, aby SQL Server upřednostnil paralelní plán před sériovou alternativou, náklady sériového plánu musí být alespoň prahová hodnota nákladů pro paralelismus a náklady paralelního plánu musí být nižší než náklady sériového plánu (což znamená potenciálně nižší doba běhu).
Než se dostanu k podrobnostem o skutečných kalkulačních vzorcích, ilustruji na příkladech různé scénáře, kde se volí mezi sériovými a paralelními plány. Pokud si chcete vyzkoušet příklady, ujistěte se, že váš systém předpokládá 8 logických CPU, aby získal podobné náklady na dotazy jako já.
Zvažte následující dotazy (budeme je nazývat Dotaz 6 a Dotaz 7):
-- Dotaz 6:Serial SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; -- Dotaz 7:Vynucené paralelní SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empidOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plány pro tyto dotazy jsou znázorněny na obrázku 3.
Obrázek 3:Sériová cena
Zde jsou náklady [nuceného] paralelního plánu nižší než náklady sériového plánu; náklady na sériový plán jsou však nižší než výchozí prahová hodnota pro paralelismus 5, proto SQL Server jako výchozí zvolil sériový plán.
Zvažte následující dotazy (budeme je nazývat Dotaz 8 a Dotaz 9):
-- Dotaz 8:Paralelní SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Dotaz 9:Vynucené sériové SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empidOPTION(MAXDOP 1);Plány pro tyto dotazy jsou znázorněny na obrázku 4.
Obrázek 4:Sériová cena>=prahová hodnota nákladů pro paralelismus, paralelní náklady
Zde jsou náklady [vynuceného] sériového plánu vyšší nebo rovné prahu nákladů pro paralelismus a náklady paralelního plánu jsou nižší než náklady sériového plánu, proto SQL Server jako výchozí zvolil paralelní plán.
Zvažte následující dotazy (budeme je nazývat Dotaz 10 a Dotaz 11):
-- Dotaz 10:Serial SELECT *FROM dbo.OrdersWHERE orderid>=100000; -- Dotaz 11:Vynucený paralelní SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plány pro tyto dotazy jsou znázorněny na obrázku 5.
Obrázek 5:Sériová cena>=prahová hodnota nákladů pro paralelismus, paralelní náklady>=sériové náklady
Zde jsou náklady sériového plánu větší nebo rovné prahu nákladů pro paralelismus; nicméně náklady na sériový plán jsou nižší než [vynucené] náklady na paralelní plán, proto SQL Server zvolil sériový plán jako výchozí.
Je ještě jedna věc, kterou potřebujete vědět o pokusu o maximalizaci paralelismu s nápovědou ENABLE_PARALLEL_PLAN_PREFERENCE. Aby SQL Server vůbec mohl používat paralelní plán, musí existovat nějaký aktivátor paralelismu, jako je zbytkový predikát, řazení, agregace a tak dále. Plán, který používá pouze skenování indexu nebo hledání indexu bez zbytkového predikátu a bez jakéhokoli dalšího aktivátoru paralelismu, bude zpracován se sériovým plánem. Jako příklad zvažte následující dotazy (budeme je nazývat Dotaz 12 a Dotaz 13):
-- Dotaz 12 SELECT *FROM dbo.OrdersOPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE')); -- Dotaz 13 SELECT *FROM dbo.OrdersWHERE orderid>=100000OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));Plány pro tyto dotazy jsou znázorněny na obrázku 6.
Obrázek 6:Aktivátor paralelismu
Query 12 dostane sériový plán navzdory nápovědě, protože neexistuje žádný aktivátor paralelismu. Dotaz 13 má paralelní plán, protože je v něm obsažen zbytkový predikát.
Výpočet a testování DOP pro kalkulaci
Microsoft musel zkalibrovat kalkulační vzorce ve snaze dosáhnout nižších nákladů paralelního plánu, než náklady sériového plánu odrážet kratší dobu běhu a naopak. Jedním z potenciálních nápadů bylo vzít náklady na CPU sériového operátora a jednoduše je vydělit počtem logických CPU ve stroji, aby se vytvořily náklady na CPU paralelního operátora. Logický počet CPU ve stroji je hlavním faktorem určujícím stupeň paralelismu dotazu, zkráceně DOP (počet vláken, která lze použít v paralelní zóně v plánu). Zjednodušené uvažování je, že pokud operátor potřebuje k dokončení T časových jednotek při použití jednoho vlákna a stupeň paralelismu dotazu je D, při použití D vláken by to operátorovi zabralo čas T/D. V praxi věci nejsou tak jednoduché. Obvykle například běží více dotazů současně a ne pouze jeden, v takovém případě jediný dotaz nezíská všechny prostředky CPU počítače. Microsoft tedy přišel s myšlenkou stupně paralelismu pro kalkulaci nákladů (zkráceně DOP pro kalkulaci nákladů). Tato míra je obvykle nižší než počet logických CPU ve stroji a je to faktor, kterým se dělí náklady na CPU sériového operátora, aby se vypočítaly náklady na CPU paralelního operátora.
Normálně se DOP pro kalkulaci počítá jako počet logických CPU dělený 2 pomocí celočíselného dělení. Existují však výjimky. Když je počet CPU 2 nebo 3, DOP pro kalkulaci je nastaveno na 2. U 4 nebo více CPU je DOP pro kalkulaci nastaveno na #CPUs / 2, opět pomocí celočíselného dělení. To je až do určitého maxima, které závisí na velikosti paměti dostupné pro stroj. U stroje s pamětí až 4 096 MB je maximální DOP pro kalkulaci 8; s více než 4 096 MB je maximální DOP pro kalkulaci 32.
Chcete-li otestovat tuto logiku, již víte, jak emulovat požadovaný počet logických CPU pomocí DBCC OPTIMIZER_WHATIF s volbou CPU, jako je tento:
DBCC OPTIMIZER_WHATIF(CPU, 8);Pomocí stejného příkazu s možností MemoryMBs můžete emulovat požadované množství paměti v MB, například takto:
DBCC OPTIMIZER_WHATIF(MemoryMBs, 16384);Ke kontrole stávajícího stavu emulovaných možností použijte následující kód:
DBCC TRACEON(3604); DBCC OPTIMIZER_WHATIF(Stav); DBCC TRACEOFF(3604);K resetování všech možností použijte následující kód:
DBCC OPTIMIZER_WHATIF(ResetAll);Zde je dotaz T-SQL, který můžete použít k výpočtu DOP pro kalkulaci na základě vstupního počtu logických CPU a množství paměti:
DECLARE @NumCPUs JAKO INT =8, @MemoryMBs JAKO INT =16384; VYBERTE PŘÍPAD, KDYŽ @NumCPUs =1 THEN 1 WHEN @NumCPUs <=3 THEN 2 KDYŽ @NumCPUs>=4 THEN (VYBERTE MIN(n) Z ( VALUES(@NumCPUs / 2), (MaxDOP4C ) ) JAKO D2(n)) KONEC JAKO DOP4CFROM ( VALUES( CASE WHEN @MemoryMBs <=4096 THEN 8 ELSE 32 END ) ) AS D1(MaxDOP4C);Se zadanými vstupními hodnotami tento dotaz vrátí 4.
Tabulka 1 uvádí podrobnosti o DOP pro kalkulaci, kterou získáte na základě logického počtu CPU a množství paměti ve vašem počítači.
| #CPU | DOP pro kalkulaci při MemoryMBs <=4096 | DOP pro kalkulaci, když MemoryMBs> 4096 |
|---|---|---|
| 1 | 1 | 1 |
| 2–5 | 2 | 2 |
| 6-7 | 3 | 3 |
| 8–9 | 4 | 4 |
| 10-11 | 5 | 5 |
| 12-13 | 6 | 6 |
| 14–15 | 7 | 7 |
| 16–17 | 8 | 8 |
| 18–19 | 8 | 9 |
| 20–21 | 8 | 10 |
| 22-23 | 8 | 11 |
| 24–25 | 8 | 12 |
| 26–27 | 8 | 13 |
| 28–29 | 8 | 14 |
| 30–31 | 8 | 15 |
| 32-33 | 8 | 16 |
| 34-35 | 8 | 17 |
| 36–37 | 8 | 18 |
| 38–39 | 8 | 19 |
| 40-41 | 8 | 20 |
| 42-43 | 8 | 21 |
| 44-45 | 8 | 22 |
| 46–47 | 8 | 23 |
| 48–49 | 8 | 24 |
| 50-51 | 8 | 25 |
| 52-53 | 8 | 26 |
| 54-55 | 8 | 27 |
| 56-57 | 8 | 28 |
| 58–59 | 8 | 29 |
| 60-61 | 8 | 30 |
| 62-63 | 8 | 31 |
| >=64 | 8 | 32 |
Tabulka 1:DOP pro kalkulaci
Jako příklad se vraťme k výše uvedenému dotazu 1 a dotazu 2:
-- Dotaz 1:Vynucené sériové SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custidOPTION(MAXDOP 1); -- Dotaz 2:Přirozeně paralelní SELECT custid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY custid;
Plány pro tyto dotazy jsou znázorněny na obrázku 7.
 Obrázek 7:DOP pro kalkulace
Obrázek 7:DOP pro kalkulace
Dotaz 1 vynutí sériový plán, zatímco dotaz 2 získá paralelní plán v mém prostředí (emuluje 8 logických CPU a 16 384 MB paměti). To znamená, že DOP pro kalkulaci v mém prostředí je 4. Jak bylo zmíněno, cena CPU paralelního operátora se vypočítá jako cena CPU sériového operátora dělená DOP pro kalkulaci. Můžete vidět, že tomu tak skutečně je v našem paralelním plánu s operátory Index Seek a Hash Aggregate, které fungují paralelně.
Pokud jde o náklady operátorů burz, ty jsou tvořeny počátečními náklady a určitými konstantními náklady na řádek, které můžete snadno zpětně analyzovat.
Všimněte si, že v jednoduché strategii paralelního seskupování a agregace, která je zde použitá, jsou odhady mohutnosti v sériovém a paralelním plánu stejné. Je to proto, že je zaměstnán pouze jeden agregovaný operátor. Později uvidíte, že při použití místní/globální strategie se věci liší.
Následující dotazy pomáhají ilustrovat vliv počtu logických CPU a počtu zapojených řádků na cenu dotazu (10 dotazů s přírůstky po 100 000 řádků):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=900001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=800001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=700001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=600001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=500001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=400001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=200001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=100001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=000001GROUP BY empid;
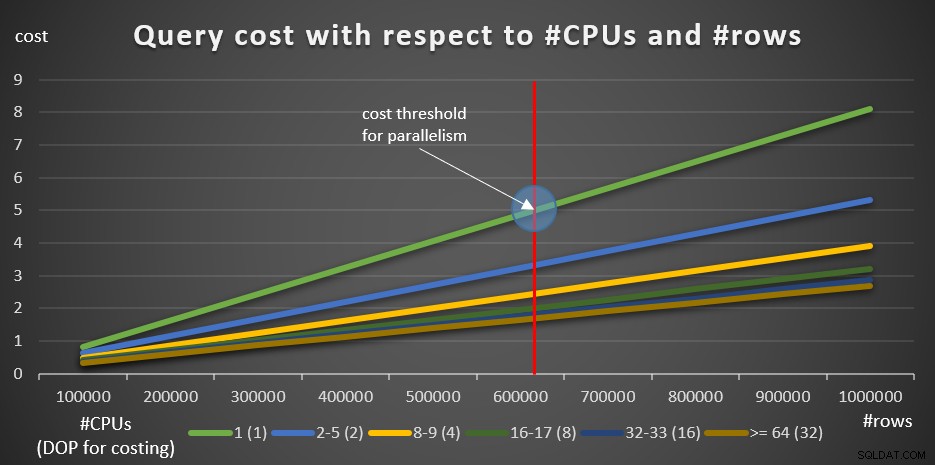
Obrázek 8 ukazuje výsledky.
Obrázek 8:Cena dotazu s ohledem na #CPUs a #rows
Zelená čára představuje náklady na různé dotazy (s různým počtem řádků) pomocí sériového plánu. Další řádky představují náklady na paralelní plány s různým počtem logických CPU a jejich příslušné DOP pro kalkulaci. Červená čára představuje bod, kde je cena sériového dotazu 5 – výchozí prahová hodnota ceny pro nastavení paralelismu. Nalevo od tohoto bodu (méně řádků k seskupení a agregaci) obvykle optimalizátor neuvažuje o paralelním plánu. Abyste mohli zkoumat náklady na paralelní plány pod prahem nákladů pro paralelismus, můžete udělat jednu ze dvou věcí. Jednou z možností je použít nápovědu k dotazu ENABLE_PARALLEL_PLAN_PREFERENCE, ale pro připomenutí, tato možnost maximalizuje paralelismus, nikoli pouze vynucení. Pokud to není požadovaný efekt, můžete jednoduše deaktivovat prahovou hodnotu nákladů pro paralelismus, například takto:
EXEC sp_configure 'zobrazit pokročilé možnosti', 1; PŘENASTAVIT; EXEC sp_configure 'prah nákladů pro paralelismus', 0; EXEC sp_configure 'zobrazit pokročilé možnosti', 0; RECONFIGURE;
Je zřejmé, že to není chytrý tah ve výrobním systému, ale dokonale užitečné pro výzkumné účely. To je to, co jsem udělal, abych vytvořil informace pro graf na obrázku 8.
Počínaje 100 000 řádky a přidáním 100 000 přírůstků se zdá, že všechny grafy naznačují, že prahová hodnota nákladů pro paralelismus nebyla faktorem, vždy by byl preferován paralelní plán. To je skutečně případ našich dotazů a počtu zahrnutých řádků. Zkuste však menší počet řádků, počínaje 10 000 a zvyšovat po 10 000 pomocí následujících pěti dotazů (opět ponechte prozatím zakázaný práh ceny pro paralelismus):
SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=990001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=980001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=970001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=960001GROUP BY empid; SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=950001GROUP BY empid;
Obrázek 9 ukazuje náklady na dotaz se sériovým i paralelním plánem (emulující 4 CPU, DOP pro kalkulaci 2).
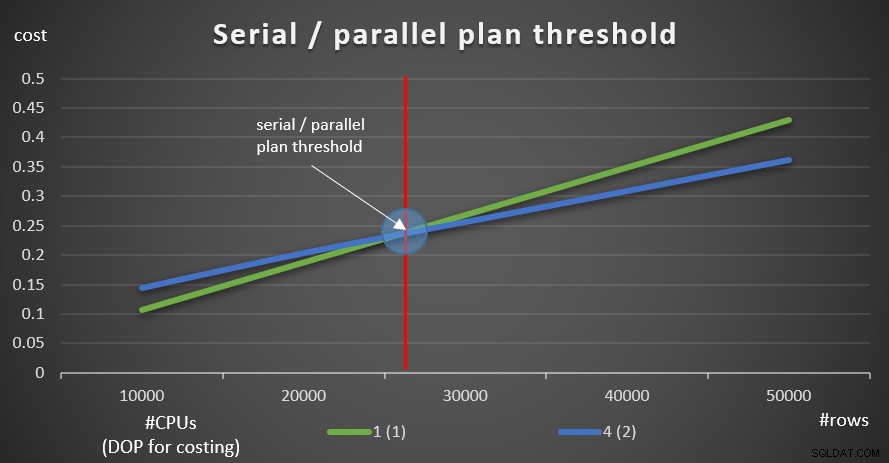 Obrázek 9:Sériové / prahová hodnota paralelního plánu
Obrázek 9:Sériové / prahová hodnota paralelního plánu
Jak vidíte, existuje prahová hodnota optimalizace, do které je preferován sériový plán a nad nímž je preferován paralelní plán. Jak již bylo zmíněno, v normálním systému, kde buď udržujete prahovou hodnotu ceny pro nastavení paralelismu na výchozí hodnotě 5 nebo vyšší, je efektivní prahová hodnota stejně vyšší než v tomto grafu.
Již dříve jsem zmínil, že když SQL Server zvolí jednoduchou strategii paralelismu seskupování a agregace, odhady mohutnosti sériových a paralelních plánů jsou stejné. Otázkou je, jak SQL Server zpracuje odhady mohutnosti pro strategii lokálního/globálního paralelismu.
Abych to zjistil, použiji Dotaz 3 a Dotaz 4 z našich dřívějších příkladů:
-- Dotaz 3:Lokální paralelní globální paralelní SELECT empid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY empid; -- Dotaz 4:Lokální paralelní globální sériové SELECT shipperid, COUNT(*) AS numordersFROM dbo.OrdersWHERE orderid>=300001GROUP BY shipperid;
V systému s 8 logickými CPU a efektivním DOP pro nákladovou hodnotu 4 jsem dostal plány zobrazené na obrázku 10.
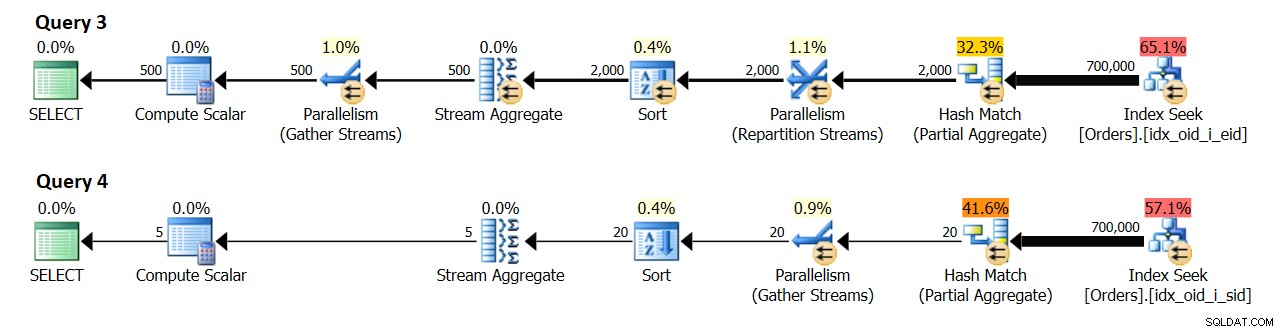 Obrázek 10:Odhad mohutnosti
Obrázek 10:Odhad mohutnosti
Dotaz 3 seskupuje objednávky podle empid. Nakonec se očekává 500 různých skupin zaměstnanců.
Dotaz 4 seskupuje objednávky podle odesílatele. Nakonec se očekává 5 různých skupin odesílatelů.
Je zvláštní, že se zdá, že odhad mohutnosti pro počet skupin vytvořených místním agregátem je { počet různých skupin očekávaných každým vláknem } * { DOP pro kalkulaci }. V praxi si uvědomíte, že toto číslo bude obvykle dvakrát tolik, protože to, co se počítá, je DOP pro provádění (aka, jen DOP), které je založeno především na počtu logických CPU. Emulovat tuto část pro účely výzkumu je trochu složitější, protože příkaz DBCC OPTIMIZER_WHATIF s volbou CPU ovlivňuje výpočet DOP pro kalkulaci, ale DOP pro provádění nebude větší než skutečný počet logických CPU, které vaše instance SQL Server vidí. Toto číslo je v podstatě založeno na počtu plánovačů, se kterými SQL Server začíná. můžete řídit počet plánovačů, se kterými se SQL Server spouští pomocí spouštěcího parametru -P{ #schedulers }, ale to je o něco agresivnější výzkumný nástroj ve srovnání s možností relace.
V každém případě, bez emulace jakýchkoli prostředků, má můj testovací stroj 4 logické CPU, což má za následek DOP pro cenu 2 a DOP pro provádění 4. V mém prostředí místní agregát v plánu pro Dotaz 3 ukazuje odhad 1 000 skupin výsledků (500 x 2) a ve skutečnosti 2 000 (500 x 4). Podobně místní agregát v plánu pro Dotaz 4 ukazuje odhad 10 skupin výsledků (5 x 2) a skutečných 20 (5 x 4).
Až budete s experimentováním hotovi, spusťte následující kód pro vyčištění:
-- Nastaví práh nákladů pro paralelismus na výchozí EXEC sp_configure 'zobrazit pokročilé možnosti', 1; PŘENASTAVIT; EXEC sp_configure 'prah nákladů pro paralelismus', 5; EXEC sp_configure 'zobrazit pokročilé možnosti', 0; RECONFIGURE;GO -- Resetovat možnosti OPTIMIZER_WHATIF DBCC OPTIMIZER_WHATIF(ResetAll); -- Pusťte indexy DROP INDEX idx_oid_i_sid ON dbo.Orders;DROP INDEX idx_oid_i_eid ON dbo.Orders;DROP INDEX idx_oid_i_cid ON dbo.Orders;
Závěr
V tomto článku jsem popsal řadu strategií paralelismu, které SQL Server používá ke zpracování seskupování a agregace. Důležitým konceptem, který je třeba pochopit při optimalizaci dotazů s paralelními plány, je stupeň paralelismu (DOP) pro kalkulaci nákladů. Ukázal jsem řadu prahových hodnot optimalizace, včetně prahu mezi sériovým a paralelním plánem a prahu nastavení nákladů pro paralelismus. Většina konceptů, které jsem zde popsal, není jedinečná pro seskupování a agregaci, ale je stejně použitelná pro úvahy o paralelním plánu na SQL Server obecně. Příští měsíc budu v sérii pokračovat diskusí o optimalizaci s přepisováním dotazů.