Není velká šance, že by vám celá myšlenka sdílené ekonomiky unikla – ať se vám to líbí nebo ne. Popularizováno společnostmi jako Airbnb, Uber, Lyft a mnoha dalšími a umožňuje lidem vydělat nějaké peníze pronájmem jejich nepoužívaných věcí. Podívejme se na datový model za takovou aplikací.
Máte volný pokoj? Zaregistrujte se na Airbnb a vydělávejte peníze navíc na jeho pronajímání. Máte auto a nějaký volný čas? Staňte se řidičem Uberu. A tak to jde – myšlenka těchto společností a mnoha dalších jim podobných je téměř stejná. Je to všechno o sdílení zdroje s (většinou) cizími lidmi, s výhodou pro obě strany. Majitel dostane peníze za svůj nevyužitý majetek, zatímco zákazník obvykle dostane dobrý obchod; to by měla být situace oboustranně výhodná.
Samozřejmě potřebujeme platformu pro spojení vlastníků se zákazníky a sledování důležitých detailů. Dnes představíme datový model, který by mohl řídit úkol. Usaďte se zpět do křesla a užijte si jízdu datovým modelem sdílené ekonomiky.
Co potřebujeme v našem datovém modelu?
Myšlenka pronajímat nemovitost, když ji nepoužíváme, se zdá být velmi moudrá. Za prvé, nemovitost se používá k zamýšlenému účelu; za druhé, pronájem bude generovat nějaký druh dodatečného příjmu. Může to být hotovost, ale také směna (např. někdo v New Yorku si na týden vymění byt s někým v Paříži).
Bezhotovostní modely jsou opravdu skvělé a obvykle závisí na vzájemném porozumění, dobré vůli a poctivosti. Tento článek se však zaměří na modely sdílené ekonomiky, které vyžadují platbu. Není to tak romantické jako bezhotovostní modely, ale platební model je docela efektivní.
Potřebujeme velmi jednoduchý způsob, jak velké množství vlastníků nemovitostí oslovit velké množství zainteresovaných zákazníků a naopak. Toto je první požadavek na náš datový model. Budeme mít uživatelské účty a alespoň dvě odlišné role – vlastníka a zákazníka.
Další věc, kterou potřebujeme, je, aby naše aplikace vypsala všechny dostupné vlastnosti. Pro Airbnb by to byly byty; pro Uber by to byla auta. Tento článek se více zaměří na pronájem bytů (datový model podobný Airbnb), ale ponechám model dostatečně obecný, aby jej bylo možné snadno převést na jakoukoli jinou požadovanou službu sdílení ekonomiky.
Pro každého vlastníka nemovitosti budeme muset definovat místo, kde působí. U bytů je to celkem zřejmé (město, kde se byt nachází). U přepravních služeb to bude záviset na aktuální poloze auta a/nebo jeho vlastníka.
U každé služby nebo zdroje budeme muset sledovat období používání a požadavky/rezervace. To nám umožní najít dostupné nemovitosti při zadání nové poptávky a vypočítat míru obsazenosti a cenu. K analýze těchto dat a vytváření dalších statistik budeme také moci používat jiné programy.
Datový model
Datový model se skládá z pěti tematických oblastí:
Země a městaUživatelé a roleSlužby a dokumentyPožadavkyPoskytované služby
Každou tematickou oblast představíme ve stejném pořadí, v jakém jsou uvedeny.
Část 1:Země a města
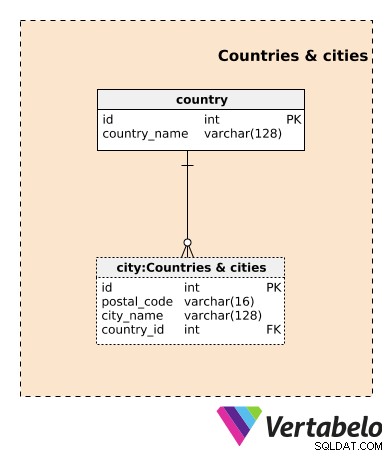
Začneme Zeměmi a městy předmětová oblast. Ačkoli nejsou specifické pro tento datový model, jsou tyto tabulky velmi důležité. Služby spojené s nemovitostmi jsou obvykle geograficky orientované. Náš model úzce souvisí s pronájmem nějakého obydlí, takže fyzická poloha je zde rozhodující. Toto umístění se samozřejmě obvykle nezmění. Existují některé velmi zvláštní případy, které by mohly vést ke změně umístění nemovitosti, ale já bych to obydlí na novém místě považoval za zcela novou nemovitost.
Pro aplikace pro auta a/nebo řidiče, jako je Uber, je také velmi důležitá aktuální poloha auta a řidiče. Na rozdíl od pronájmů bytů ve stylu Airbnb se tyto lokality mohou často měnit.
země tabulka obsahuje seznam UNIKÁTNÍCH názvů zemí, kde působíme. město tabulka obsahuje seznam všech měst, kde působíme. UNIKÁTNÍ kombinace pro tuto tabulku je kombinací postal_code , název_města a id země atributy.
Obě tyto tabulky mohou obsahovat mnoho dalších atributů, ale záměrně jsem je vynechal, protože tomuto modelu nepřidají žádnou hodnotu.
Část 2:Uživatelé a role
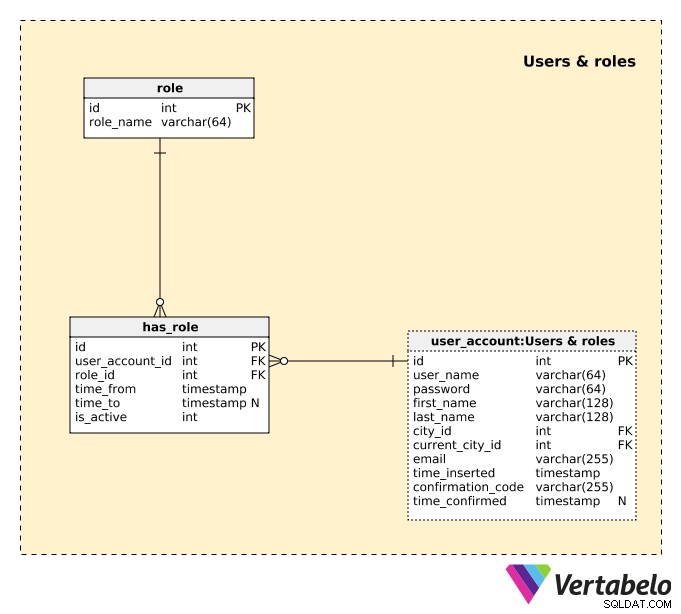
Další věc, kterou musíme udělat, je definovat uživatele a jejich chování nebo role v naší aplikaci. K tomu použijeme tři tabulky v Uživatelé a role předmětová oblast.
Seznam všech uživatelů je v user_account stůl. Pro každého uživatele uložíme následující podrobnosti:
uživatelské_jméno– UNIKÁTNÍ jméno, které si uživatel zvolil pro přístup k naší aplikaci.heslo– Hodnota hash hesla zvoleného uživatelem.first_nameapříjmení– Jméno a příjmení uživatele.id_města– Odkaz naměstokde se uživatel obvykle nachází.current_city_id– Odkaz naměstokde se uživatel aktuálně nachází.e-mail– E-mailová adresa uživatele.time_inserted– Časové razítko, kdy byl tento záznam vložen do tabulky.confirmation_code– Kód vygenerovaný během procesu registrace pro potvrzení e-mailové adresy uživatele.time_confirmed– Časové razítko, kdy byla e-mailová adresa potvrzena. Tento atribut obsahuje hodnotu NULL, dokud neprojde potvrzení.
Uživatel bude mít v aplikaci různá práva podle své role. Je také možné, že jeden uživatel může mít více než jednu aktivní roli současně, např. mohou být vlastníkem jedné nemovitosti a zákazníkem jiné nemovitosti. V takovém případě uživatel použije stejné přihlašovací údaje a bude mít možnost přepínat mezi rolemi. Každá role bude mít v aplikaci svou vlastní obrazovku.
Seznam všech možných rolí je uložen v roli slovník. Každá role je JEDNOZNAČNĚ definována svým název_role . Pro jednoduchost můžeme očekávat pouze dvě role:„vlastník nemovitosti“ a „zákazník“.
Uživateli může být stejná role přiřazena vícekrát během různých období. Jedním takovým případem by bylo, kdyby uživatel pronajímal svůj nevyužívaný byt a poté se rozhodl svůj byt nepronajmout, protože jej potřeboval. Po pár měsících se však stejný uživatel rozhodl svůj byt znovu pronajmout. V tomto případě bychom jejich roli deaktivovali a poté znovu aktivovali.
Seznam všech rolí, které byly kdy přiřazeny uživatelům, je uložen v has_role stůl. Pro každý záznam v této tabulce uložíme:
id_uživatelského_účtu– ID souvisejícíhouživatele.id_role– ID souvisejícírole.čas_od– Časové razítko, kdy byla tato role vložena do systému.time_to– Časové razítko, kdy byla tato role deaktivována. Toto bude obsahovat hodnotu NULL, dokud bude role stále aktivní.is_active– Je nastaveno na False, když je role z jakéhokoli důvodu deaktivována.
Při vkládání nového záznamu do této tabulky bychom měli zkontrolovat, zda se záznamy nepřekrývají. To nám umožňuje vyhnout se tomu, aby stejná role platila dvakrát během stejného období.
Část 3:Služby a dokumenty
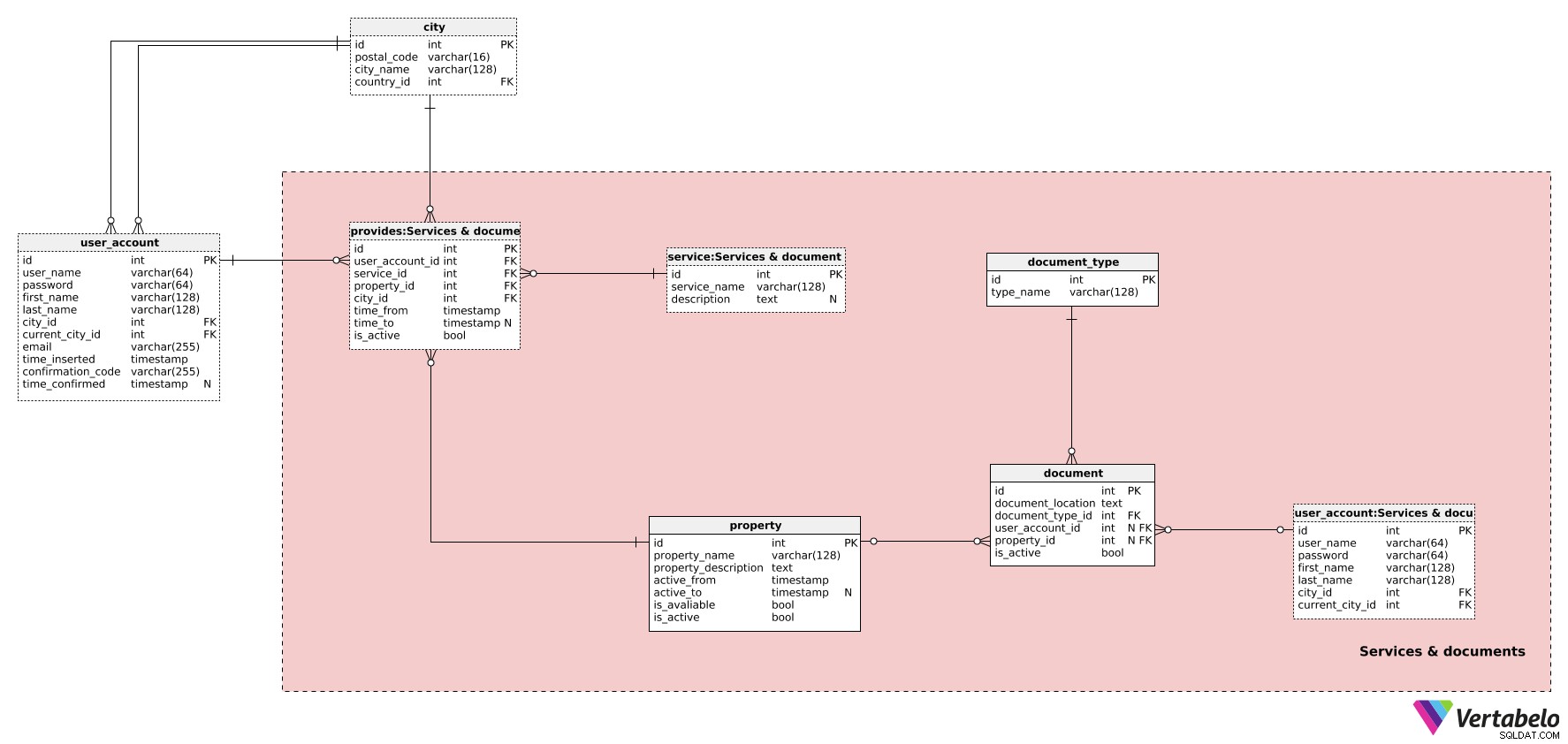
Další věc, kterou musíme definovat, jsou služby poskytované uživateli. Budeme také muset sledovat všechny související dokumenty. K tomu budeme potřebovat tabulky v Službách a dokumentech předmětová oblast.
Začněme u vlastnosti stůl. Nemovitosti jsou jakékoli předměty naší služby:obydlí, auta, kola atd. Můžeme očekávat, že uživatelé se budou o své nemovitosti starat sami. Pro každou vlastnost budeme muset definovat:
název_vlastnosti– Název obrazovky pro tuto vlastnost zvolený uživatelem. Tento název se používá při zobrazování nemovitosti potenciálním zákazníkům v aplikaci. Měl by být stručný a popisný a měl by tuto vlastnost odlišovat od ostatních vlastností.property_description– Dodatečný textový popis v nestrukturovaném formátu. Očekávat zde můžeme hromadu detailů – v podstatě vše od velikosti bytu až po to, zda zákazníci po příchodu dostanou welcome drink. Uvítací drinky v dopravních službách jsou mnohem méně pravděpodobné.active_fromaactive_to– Časové období, kdy byla tato vlastnost v našem systému aktivní.active_toatribut bude obsahovat hodnotu NULL, dokud nebude vlastnost deaktivována.is_available– Příznak označující, zda je tato vlastnost k dispozici v konkrétní čas či nikoli.is_active– Příznak označující, zda je tato vlastnost v našem systému stále aktivní. Hodnota tohoto atributu bude nastavena na False ve stejnou chvíliactive_toje nastaveno.
Nyní přejdeme ke službě slovník. Zde definujeme všechny možné typy služeb, jako je „dlouhodobý pronájem“, „krátkodobý pronájem“, „doprava“ atd. Obsahuje UNIKÁTNÍ název typu služby a další popis , v případě potřeby.
Související vlastnosti, služby a uživatele ponecháme v poskytuje stůl. Uloží období, kdy byla nemovitost k dispozici. V případě dopravy nám to řekne, kdy auto a řidič skutečně pracují pro naši společnost. V případě pronájmů bytů by nám řekl, kdy je nemovitost k dispozici. Pro každý záznam zde budeme mít:
id_uživatelského_účtu– ID uživatele poskytujícího tuto službu.id_služby– IDslužbyposkytnutý typ.id_property– Odkazuje navlastnostpoužité.čas_odatime_to– Kdy byla tato nemovitost použita k poskytování této služby.time_toatribut bude obsahovat hodnotu NULL, dokud nebude tento záznam deaktivován.is_active– Je nastaveno na False, jakmile tato vlastnost již nebude používána nebo když tento uživatel přestane tuto službu poskytovat. Toto je nastaveno ve stejném okamžiku, kdytime_toje nastaveno.
Zbývající dvě tabulky v této oblasti se týkají dokumentů. (Tabulka user_account je pouze kopií originálu, zde je použito, aby nedocházelo k překrývání vztahů.) Naše společnost bude spolupracovat s mnoha majiteli nemovitostí a nebude téměř žádná možnost si vše osobně ověřit. Jedním ze způsobů, jak zajistit kvalitu služeb, je mít vše dobře zdokumentované.
První tabulka související s dokumenty je document_type stůl. Tento jednoduchý slovník obsahuje seznam UNIKÁTNÍCH název_typu hodnoty. Zde můžeme očekávat hodnoty jako „property picture“ a „owner ID“.
Seznam všech dokumentů je uložen v dokumentu stůl. Tyto dokumenty mohou souviset s uživatelskými účty, vlastnostmi nebo obojím. Pro každý dokument uložíme:
umístění_dokumentu– Úplná cesta k tomuto dokumentu.document_type_id– Odkaz natype_document_typeslovník.id_uživatelského_účtu– Odkaz nauser_accountstůl. Tento atribut bude mít hodnotu pouze v případě, že dokument souvisí s uživatelem nebo pokud dokument souvisí s vlastností, ale uživatel tuto vlastnost také vlastní.id_property– Odkaz na související vlastnost .is_active– Označuje, zda je tento dokument stále aktivní (platný) nebo ne.
Část 4:Žádosti
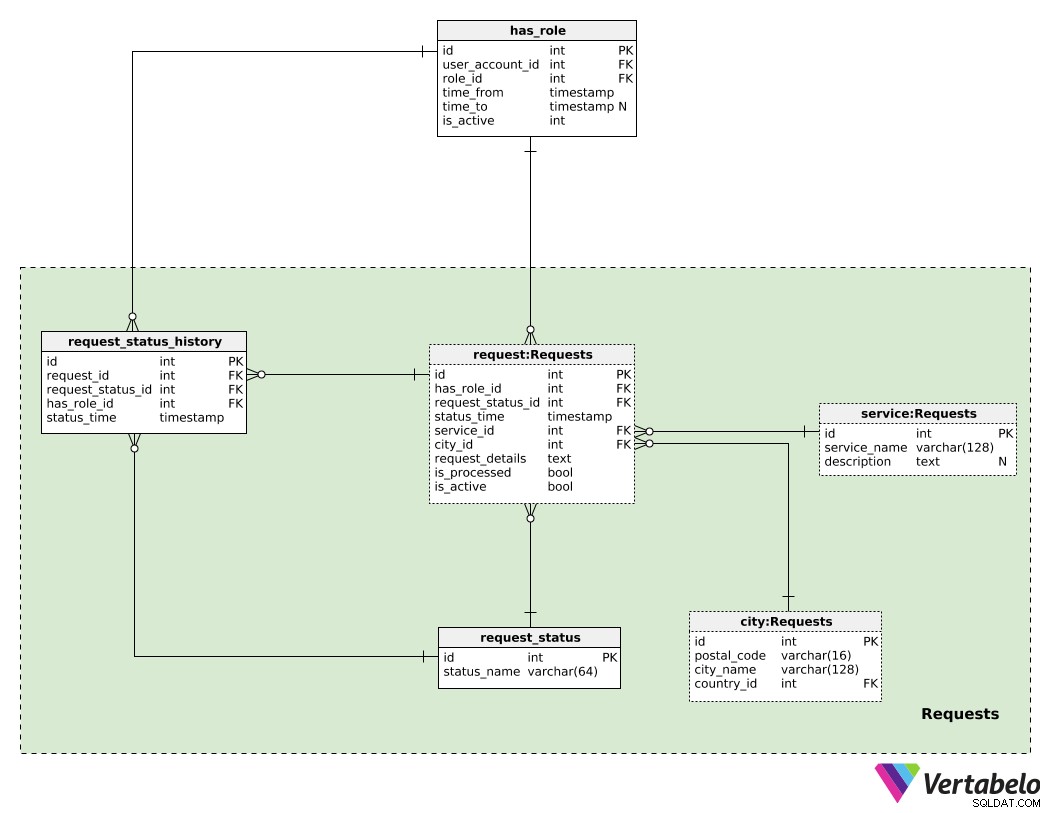
Než budeme moci poskytovat jakoukoli službu, musíme získat nějaké požadavky uživatelů. U pronájmů bytů zákazník zadá svůj požadavek na požadovanou nemovitost poté, co prohledá nabídky a najde požadované bydlení. V případě přepravních služeb zadávají požadavky zákazníci prostřednictvím mobilní aplikace (např. jsou na letišti a potřebují odvézt za 20 minut). O tom, jak zpracováváme požadavky, si povíme v další části; zatím se podívejme, jak je spravujeme.
Centrální tabulka v této oblasti je požadavek stůl. U každého požadavku uložíme:
has_role_id– Odkaz na uživatele (a jeho aktuální roli prostřednictvímhas_roletabulka), kdo podal tento požadavek.request_status_id– Odkaz na aktuální stav tohoto požadavku.stav_čas– Časové razítko, kdy byl daný stav přiřazen.id_služby– IDslužbyvyžadováno s touto žádostí.id_města– Odkaz naměstokde je tato služba vyžadována.podrobnosti_požadavku– Všechny další podrobnosti požadavku v nestrukturovaném textovém formátu.je_zpracováno– Příznak označující, zda byl tento požadavek zpracován (tj. přidělen poskytovateli služby).is_active– Tento příznak bude nastaven na hodnotu False pouze v případě, že zákazník svůj požadavek zrušil nebo pokud byl požadavek z nějakého důvodu zrušen aplikací.
Seznam všech možných stavů je uložen v request_status slovník s název_stavu jako UNIKÁTNÍ (a jedinou) hodnotu. Můžeme očekávat hodnoty jako „požadavek umístěn“, „vlastnictví vyhrazeno“, „přiděleno řidiči“, „probíhá řízení“ a „dokončeno“.
request_status_history tabulka bude ukládat historii všech stavů souvisejících s požadavky. Pro každý záznam v této tabulce uložíme ID souvisejícího požadavku (request_id ), ID stavu (request_status_id ), ID uživatelského účtu a roli, kterou měl uživatel při nastavování tohoto stavu (has_role_id ). Zaznamenáme také, kdy byl každý stav přiřazen (status_time ).
Část 5:Poskytované služby
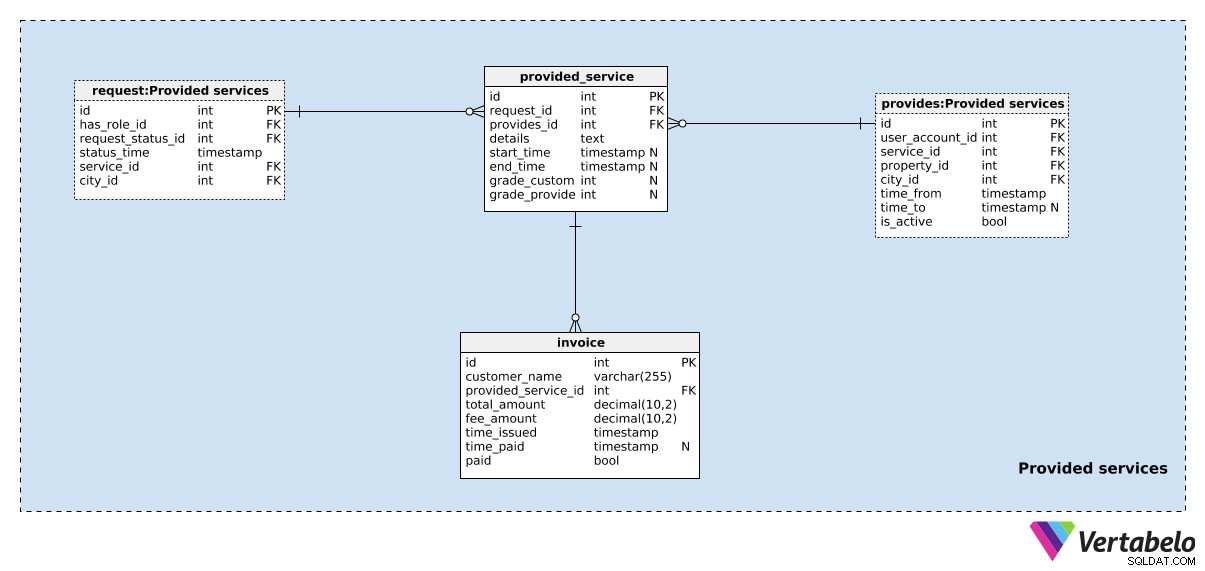
Po zadání požadavku jej musíme zpracovat. Požadavek bude buď automaticky přiřazen příslušnému poskytovateli služeb (na základě požadovaného typu služby, umístění atd.), nebo bude poskytovatelem služeb přijat ručně. Potřebujeme jen další dva stoly, abychom to zvládli.
První je poskytovaná_služba stůl. U každého záznamu uvedeme:
request_id– ID souvisejícíhopožadavku.poskytuje_id– Odkaz naposkytujetabulka, která označuje poskytovatele služeb a vlastnost zahrnutou v této akci.podrobnosti– Všechny další podrobnosti ve strukturovaném textovém formátu. Tato struktura může zahrnovat značky a hodnoty, které popisují podrobnosti požadavku. Pro jízdu by to znamenalo počáteční a koncový bod, ujetou vzdálenost atd.start_timeaend_time– Doba, po kterou byla tato služba poskytována. Obě tyto hodnoty budou nastaveny, když služba právě začala a skončila.grade_customeraposkytovatel_grade– Známky dané zákazníkem a poskytovatelem služeb pro danou službu.
Poslední tabulkou v našem modelu je faktura stůl. Budeme účtovat poplatky zákazníkům (jméno_zákazníka ) za poskytované služby (provided_service_id ). U každé faktury potřebujeme znát celková_částka , veškeré zaplacené poplatky (částka_poplatku ), kdy byla faktura vystavena (time_issued ), a kdy byla zaplacena (time_paid ) Pole zaplaceno slouží jako příznak indikující, zda byla faktura zaplacena.
Co si myslíte o našem modelu sdílení ekonomických dat?
Dnes jsme diskutovali o datovém modelu, který by mohla používat společnost jako Airbnb nebo Uber. Páteří takového obchodního modelu jsou zákazníci a poskytovatelé služeb. K tomuto modelu bych mohl přidat řadu detailů. Přesto jsem se rozhodl to neudělat, protože model by se rychle zvětšil. Myslíte, že jsem měl něco přidat? Pokud ano, řekněte mi to prosím v komentářích níže.