[ Část 1 | Část 2 | Část 3 ]
Nedávno někdo v práci požádal o více místa pro rychle rostoucí stůl. V té době měl 3,75 miliardy řádků, prezentovaných na 143 milionech stránek a zabíral ~1,14 TB. Samozřejmě, že vždy můžeme hodit více disku ke stolu, ale chtěl jsem zjistit, jestli bychom to mohli škálovat efektivněji než současný lineární trend. Zní to jako skvělá práce pro kompresi, že? Chtěl jsem ale také vyzkoušet některá další řešení, včetně columnstore – která lidé překvapivě zdráhají vyzkoušet. Nejsem žádný Niko, ale chtěl jsem se pokusit zjistit, co by to tady pro nás mohlo udělat.
Upozorňujeme, že se v tuto chvíli nezaměřuji na vykazování pracovní zátěže nebo jiný výkon při čtení dotazů – chci pouze zjistit, jaký dopad mohu mít na úložiště (a paměť) těchto dat.
Zde je původní tabulka. Změnil jsem názvy tabulek a sloupců, abych chránil nevinné, ale vše ostatní je relativně přesné.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Jsou tam nějaké další drobnosti, které jsou širší, než by měly být a/nebo které by komprese řádků mohla vyčistit, jako jsou ty numeric(24,12) a bigint sloupce, které mohou být předčasně předimenzované, ale nehodlám se vracet k aplikačnímu týmu a zjišťovat, zda je zde malá efektivita, a v tomto cvičení vynechám kompresi řádků a zaměřím se na kompresi stránek a sloupců.
Toto je kopie dat na nečinném serveru (8 jader, 64 GB RAM) se spoustou místa na disku (hodně přes 6 TB). Nejprve tedy přidáme několik skupin souborů, jednu pro standardní klastrované úložiště sloupců a jednu pro rozdělenou verzi tabulky (kde budou všechny oddíly kromě nejnovějšího komprimovány pomocí COLUMNSTORE_ARCHIVE , protože všechna tato starší data jsou nyní "pouze pro čtení a zřídka"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
A pak nějaké soubory pro tyto skupiny souborů (jeden soubor na jádro, pěkné a jednotné velikosti na 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Na tomto konkrétním hardwaru (YMMV!) to trvalo asi 10 sekund na soubor a přineslo následující:
Abych vygeneroval oddíly, naivně jsem rozdělil data „rovnoměrně“ – nebo jsem si to alespoň myslel. Právě jsem vzal 3,75 miliardy řádků a rozdělil na něco, o čem jsem si myslel, že bude zvládnutelné:38 oddílů se 100 miliony řádků v prvních 37 oddílech a zbytek v posledním. (Pamatujte si, že toto je jen část 1! Zde existuje základní předpoklad o rovnoměrném rozložení hodnot ve zdrojové tabulce a také kolem toho, co je optimální pro populaci skupiny řádků v cílové tabulce.) Vytvoření schématu oddílu a funkce pro tento účel je následuje:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Používám RANGE LEFT protože, jak mi Cathrine Wilhelmsen nadále pomáhá připomínat, to znamená, že hraniční hodnota je součástí oddílu nalevo. Jinými slovy, hodnoty, které uvádím, jsou maximální hodnoty v každém oddílu (s daty obvykle chcete RANGE RIGHT ).
Poté jsem vytvořil dvě kopie tabulky, jednu v každé skupině souborů. První měl standardní seskupený index columnstore, jediné rozdíly byly OID sloupec není IDENTITY a vypočítaný sloupec je pouze varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Druhý byl postaven na schématu oddílů, takže bylo potřeba nejprve pojmenované PK, které pak muselo být nahrazeno seskupeným indexem columnstore (ačkoli Brent Ozar v tomto krátkém příspěvku ukazuje, že existuje nějaká neintuitivní syntaxe, která toho dosáhne v méně krocích ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Poté, abych nasadil kompresi archivu na všechny oddíly kromě posledního, spustil jsem následující:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Nyní jsem byl připraven naplnit tyto tabulky daty, změřit čas a výslednou velikost a porovnat. Upravil jsem užitečný dávkový skript od Andyho Mallona a vložil řádky do obou tabulek postupně, s velikostí dávky 10 milionů řádků. Ve skutečném skriptu je toho mnohem víc (včetně aktualizace tabulky fronty s postupem), ale v zásadě:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Poté, co jsem naplnil obě tabulky columnstore z původního (nekomprimovaného) zdroje, znovu jsem tyto oddíly přestavěl, abych vyčistil veškerý nepořádek ve skupinách řádků a slovníku. Nakonec jsem na zdrojovou tabulku použil kompresi stránky. Zde jsou časování a výsledky komprese každého typu:
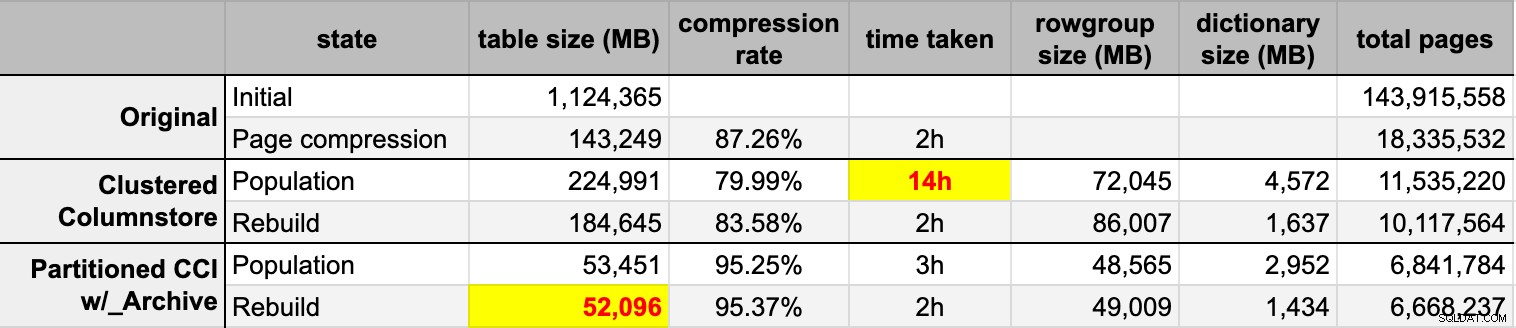
Jsem ohromen i zklamán. Jsem ohromen, protože tato data se komprimují opravdu dobře – zmenšení úložného prostoru na 5 % původního 1 TB je něco úžasného. Zklamán, protože:
- Tyto datové soubory jsem vytvořil způsobem příliš velký.
- Nerozumím tomu, co se stalo s počáteční 14hodinovou kompresí columnstore:
- Nepozoroval jsem žádný tlak na paměť ani protokol.
- Nedošlo k žádným událostem růstu souborů.
- Bohužel mě nenapadlo sledovat čekání. Ne, už to nebudu zkoušet. :-)
- Komprese stránky překonala běžnou kompresi columnstore – možná kvůli datům.
- Přestavba archivních oddílů columnstore spotřebovala spoustu času CPU a téměř nulový zisk.
V nadcházejících příspěvcích a poté, co si prohlédnu své poznámky z úžasné prezentace columnstore od Joea Obbishe na PASS Summit (na který bych odkazoval přímo, kdyby PASS věděl, jak používat uživatelské rozhraní), budu mluvit trochu o změnách, které provést konfiguraci serveru a můj skript populace, abych zjistil, zda mohu získat lepší výkon z populace columnstore.
[ Část 1 | Část 2 | Část 3 ]