[ Část 1 | Část 2 | Část 3 ]
V části 1 jsem ukázal, jak komprese stránky i sloupcového úložiště může snížit velikost 1TB tabulky o 80 % nebo více. I když jsem byl ohromen, že jsem mohl zmenšit tabulku z 1 TB na 50 GB, nebyl jsem příliš spokojen s množstvím času, který to trvalo (od 2 do 14 hodin). S některými tipy laskavě vypůjčenými od lidí, jako je Joe Obbish, Lonny Niederstadt, Niko Neugebauer a další, se v tomto příspěvku pokusím provést některé změny ve svém původním pokusu o lepší výkon při zatížení. Protože běžný index columnstore nebyl komprimován lépe než komprese stránky na této sadě dat a trvalo to o 13 hodin déle, než jsem se tam dostal, zaměřím se pouze na pokročilejší řešení pomocí COLUMNSTORE_ARCHIVE komprese.
Některé z problémů, které podle mého názoru ovlivnily výkon, zahrnují následující:
- Špatné volby rozvržení souboru – Vložil jsem 8 souborů do jedné skupiny souborů, s paralelismem, ale bez (nebo neoptimálním) rozdělením, rozprašováním I/O přes více souborů s bezohledným opuštěním. K vyřešení tohoto problému:
- rozdělte tabulku na 8 oddílů (jeden na jádro)
- umístit datový soubor každého oddílu do vlastní skupiny souborů
- použijte 8 samostatných procesů k přiřazení ke každému oddílu
- použijte kompresi archivu na všech oddílech kromě "aktivního"
- příliš mnoho malých dávek a neoptimální populace skupin řádků – zpracováním 10 milionů řádků najednou jsem naplnil devět skupin řádků pěknými 1 048 576 řádky a zbývajících 562 816 řádků by skončilo v další menší skupině řádků. A jakékoli nerovnoměrné rozdělení, které zanechalo zbytek <102 400 řádků, by vložilo vložky do méně efektivní struktury delta obchodu. Chcete-li řádky rozmístit rovnoměrněji a vyhnout se delta store, budu:
- zpracovat co nejvíce dat v přesných násobcích 1 048 576 řádků
- rozložte je na 8 oddílů co nejrovnoměrněji
- použijte velikost dávky blížící se 10x -> 100 milionů řádků
- skládání plánovače – i když jsem to nezkontroloval, je možné, že část zpomalení byla způsobena tím, že jeden plánovač zabíral příliš mnoho práce a jiný plánovač neměl dost, kvůli zacyklení plánovače. Nyní, když budu záměrně načítat data 8 procesy maxdop 1 místo jednoho procesu maxdop 8, aby byly všechny plánovače stejně vytížené, budu:
- použijte uloženou proceduru, která se snaží rovnoměrně vyvážit napříč plánovači (viz strany 189–191 v SQLCAT's Guide to:Relational Engine, kde najdete inspiraci za tímto nápadem)
- povolte globální příznak trasování 2467 a 2469, jak je v dokumentaci varováno
- úloha komprese pozadí columnstore – bylo marnotratné nechat to běžet během zalidňování, protože jsem stejně plánoval na konci přestavbu. Tentokrát budu:
- zakázat tuto úlohu pomocí globálního příznaku trasování 634
Zrušil jsem původní funkci oddílu a schéma a vytvořil jsem nový založený na rovnoměrnější distribuci dat. Chci, aby 8 oddílů odpovídalo počtu jader a počtu datových souborů, abych maximalizoval „paralelismus chudáka“, který plánuji použít.
Nejprve musíme vytvořit novou sadu skupin souborů, z nichž každá má svůj vlastní soubor:
ALTER DATABASE OKopírovat ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OKopírovat ADD FILE (název =N'CCI_Part_1', velikost =250000, název souboru ='K:\Data\o_cci_p_1.mdf') DO FILEGROUP FG_CCI_Part1; -- ... 6 dalších ... ALTER DATABASE OKopírovat ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OKopírujte PŘIDAT SOUBOR (název =N'CCI_Part_8', velikost =250000, název souboru ='K:\Data\o_cci_p_8.mdf') DO FILEGROUP FG_CCI_Part8;
Dále jsem se podíval na počet řádků v tabulce:3 754 965 954. Chcete-li je distribuovat přesně rovnoměrně napříč 8 oddíly, to by bylo 469 370 744,25 řádků na oddíl. Aby to dobře fungovalo, přizpůsobíme hranice oddílu dalšímu násobek 1 048 576 řádků. Toto je 1,048,576 x 448 = 469,762,048 – což by byl počet řádků, pro které střílíme v prvních 7 oddílech, takže v posledním oddíle zůstane 466 631 618 řádků. Chcete-li zobrazit skutečné OID hodnoty, které by sloužily jako hranice pro optimální počet řádků v každém oddílu, provedl jsem tento dotaz proti původní tabulce (protože spuštění trvalo 25 minut, rychle jsem se naučil tyto výsledky vypsat do samostatné tabulky):
;WITH x AS ( SELECT OID, rn =ROW_NUMBER() OVER (ORDER BY OID) FROM dbo.tblOriginal WITH (NOLOCK))SELECT OID, PartitionID =1+(rn/((1048576*448)+1) ) DO dbo.stage OD x WHERE rn % (1048576*112) =0;
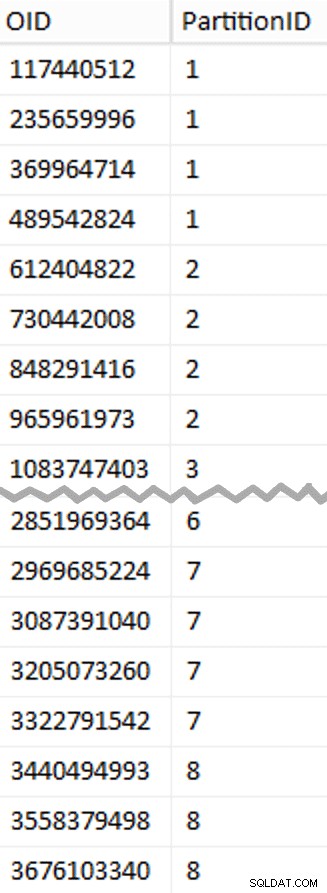 Zde můžete rozbalit více, než byste čekali. CTE odvede veškerou těžkou práci, protože musí naskenovat celou 1,14TB tabulku a přiřadit číslo řádku každému řádku . Chci vrátit pouze každý
Zde můžete rozbalit více, než byste čekali. CTE odvede veškerou těžkou práci, protože musí naskenovat celou 1,14TB tabulku a přiřadit číslo řádku každému řádku . Chci vrátit pouze každý (1048576*112)th Řádek, protože toto jsou moje hraniční řádky dávky, takže WHERE doložka ano. Pamatujte, že chci rozdělit práci do dávek blízkých 100 milionům řádků najednou, ale také nechci zpracovat 469 milionů řádků najednou. Takže kromě rozdělení dat do 8 oddílů chci každý z těchto oddílů rozdělit do čtyř dávek po 117 440 512 (1,048,576*112) řádky. Každá sousední sada čtyř dávek patří do jednoho oddílu, takže PartitionID I derivace jen přidá jedničku k výsledku aktuálního čísla řádku integer děleno (1,048,576*448) , který zajišťuje, že hranice je vždy v sadě "vlevo". K výsledku pak přidáme jeden, protože jinak bychom mluvili o kolekci oddílů na bázi 0, a to nikdo nechce.
Dobře, to bylo hodně slov. Vpravo je obrázek zobrazující (zkrácený) obsah stage tabulka (kliknutím zobrazíte úplný výsledek se zvýrazněním hodnot hranic oddílu).
Z této pracovní tabulky pak můžeme odvodit další dotaz, který nám ukáže minimální a maximální hodnoty pro každou dávku uvnitř každého oddílu, stejně jako extra dávku, která se nezapočítává (řádky v původní tabulce s OID větší než nejvyšší hraniční hodnota):
;WITH x AS ( SELECT OID, PartitionID FROM dbo.stage),y AS ( SELECT PartitionID, MinID =COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1, MaxID =OID FROM x UNION ALL SELECT ID oddílu =8, MinID =MAX(OID)+1, MaxID =4000000000 -- snadnější než zapamatovat si skutečné maximum FROM x)SELECT ID oddílu, ID dávky =ŘÁDEK_ČÍSLO() PŘES (ODDÍL PODLE ID oddílu ŘADIT PODLE MINID), MinID, MaxID, RowsInRange =CONVERT(int, NULL)INTO dbo.BatchQueueFROM y; -- Nenechme to jako hromadu:VYTVOŘTE UNIKÁTNÍ CLUSTEROVANÝ INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID);
Tyto hodnoty vypadají takto:
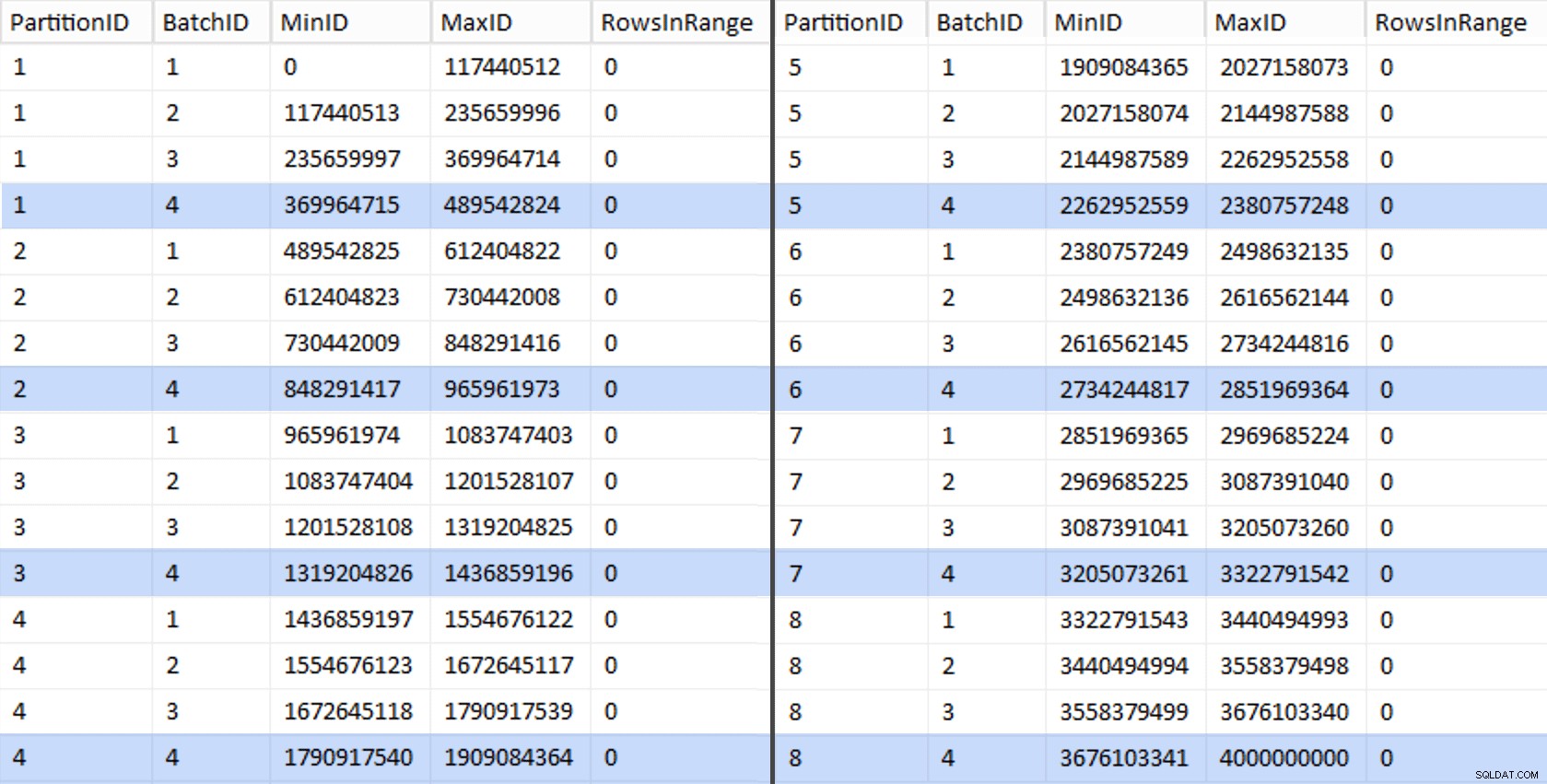
Abychom otestovali naši práci, můžeme odtud odvodit sadu dotazů, které aktualizují BatchQueue se skutečnými počty řádků z tabulky.
DECLARE @sql nvarchar(max) =N''; SELECT @sql +='UPDATE dbo.BatchQueue SET RowsInRange =( SELECT COUNT(*) FROM dbo.tblOriginal WITH (NOLOCK) WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM (MaxID) WHERE) + =' + RTRIM(MinID) + ' AND MaxID =' + RTRIM(MaxID) + ';'FROM dbo.BatchQueue; EXEC sys.sp_executesql @sql;
V mém systému to trvalo asi 6 minut. Poté můžete spustit následující dotaz, abyste ukázali, že každá dávka kromě té úplně poslední je schopna plně naplnit skupiny řádků a neponechat žádný zbytek pro potenciální využití úložiště delta:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Nyní tabulka vypadá takto:
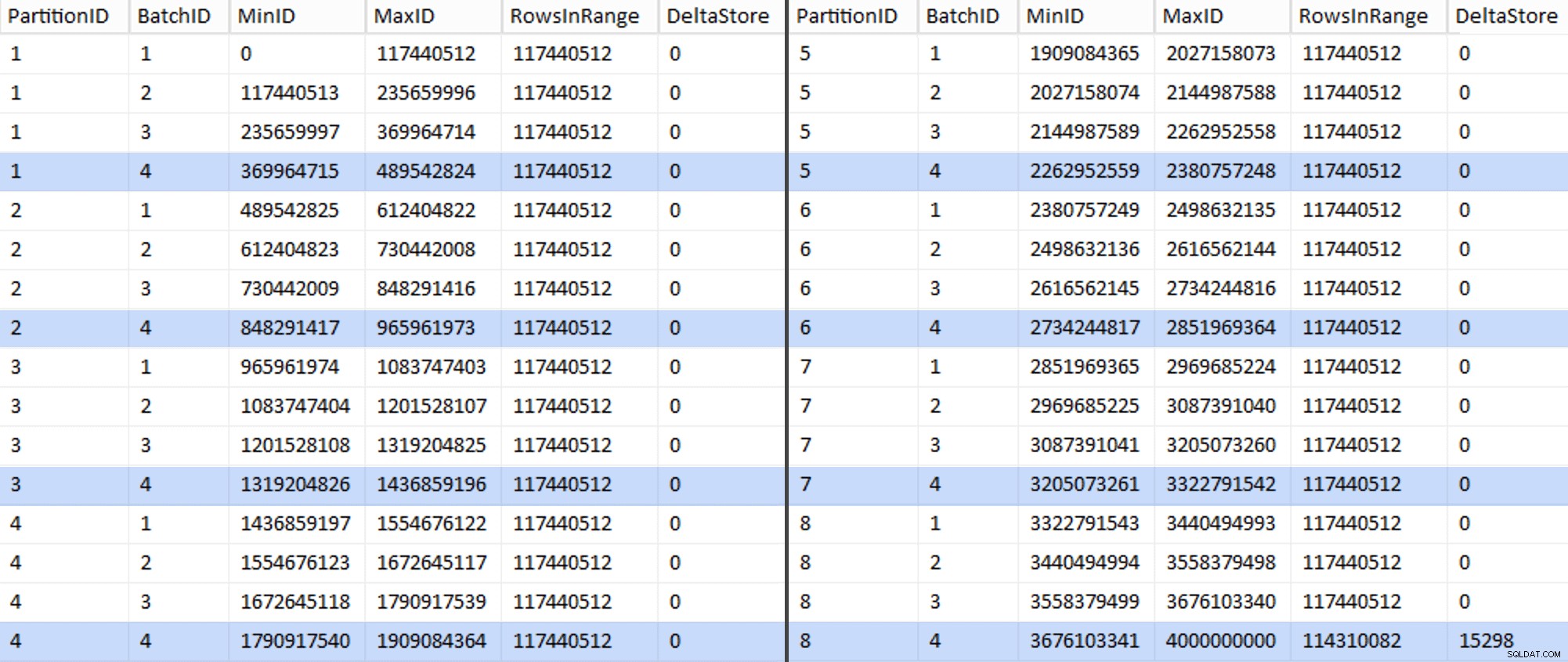
Jistě, každá dávka má vypočítaných 117 440 512 milionů řádků, kromě posledního, který bude, alespoň v ideálním případě, obsahovat náš jediný nekomprimovaný delta obchod. Pravděpodobně tomu také můžeme zabránit tím, že pro tento oddíl jen mírně změníme velikost dávky tak, aby byly všechny čtyři dávky spuštěny se stejnou velikostí, nebo změnou počtu dávek tak, aby vyhovovaly nějakému jinému násobku 102 400 nebo 1 048 576. Protože by to vyžadovalo získání nového OID hodnoty ze základní tabulky, což přidává dalších 25 minut plus k našemu úsilí o migraci, nechám tento jeden nedokonalý oddíl sklouznout – zejména proto, že z něj stejně nevyužíváme plnou archivní kompresi.
BatchQueue tabulka začíná vykazovat známky užitečnosti pro zpracování našich dávek za účelem migrace dat do naší nové, rozdělené, seskupené tabulky columnstore. Které potřebujeme vytvořit, když teď známe hranice. Existuje pouze 7 hranic, takže byste to určitě mohli udělat ručně, ale rád nechám dynamické SQL dělat mou práci za mě:
DECLARE @sql nvarchar(max) =N''; SELECT @sql =N'CREATE PARTITION FUNCTION PF_OID([bigint])AS RANGE LEFT FOR VALUES ( ' + STRING_AGG(MaxID, ', ') + ');' FROM dbo.BatchQueue WHERE ID oddílu <8 AND BatchID =4; PRINT @sql;-- EXEC sys.sp_executesql @sql;
Výsledky:
VYTVOŘIT FUNKCI ODDĚLENÍ PF_OID([bigint])JAKO ZBÝVAJÍCÍ ROZSAH PRO HODNOTY ( 489542824, 965961973, 1436859196, 1909084364, 23807572149, prez 93543);Jakmile to bude vytvořeno, můžeme vytvořit naše schéma oddílů a přiřadit každý následující oddíl k jeho vyhrazenému souboru:
VYTVOŘTE SCHÉMA ODDĚLENÍ PS_OID JAKO ODDĚLENÍ PF_OID TO (CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8);Nyní můžeme vytvořit tabulku a připravit ji na migraci:
CREATE TABLE dbo.tblPartitionedCCI( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar 128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL , NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 datum NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NUNU , NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- potřeba vytvořit omezení PK pro schéma oddílů... OMEZENÍ PK_CCI_Part PRIMÁRNÍ KLÍČ CLUSTERED (OID) ON PS_OID(OID)); -- ... pouze jej okamžitě zahodit...ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part;GO -- ... takže jej můžeme nahradit CCI:CREATE CLUSTERED CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID );GO -- nyní znovu sestavte s požadovanou kompresí:ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION =ALL WITH ( DATA_COMPRESSION =COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION =COLUMNSTORE ON PARTITIONS (8));V části 3 dále nakonfiguruji
BatchQueuetabulky, vytvořte proceduru pro procesy, které posunou data do nové struktury, a analyzujte výsledky.[ Část 1 | Část 2 | Část 3 ]