SQLAlchemy vám pomůže pracovat s databázemi v Pythonu. V tomto příspěvku vám řekneme vše, co potřebujete vědět, abyste mohli začít s tímto modulem.
V předchozím článku jsme mluvili o tom, jak používat Python v procesu ETL. Zaměřili jsme se na to, abychom práci provedli prováděním uložených procedur a SQL dotazů. V tomto a dalším článku použijeme jiný přístup. Místo psaní kódu SQL použijeme sadu nástrojů SQLAlchemy. Tento článek můžete také použít samostatně jako rychlý úvod k instalaci a používání SQLAlchemy.
připraveni? Začněme.
Co je SQLAlchemy?
Python je dobře známý pro svůj počet a rozmanitost modulů. Tyto moduly výrazně zkracují naši dobu kódování, protože implementují rutiny potřebné k dosažení konkrétního úkolu. K dispozici je řada modulů, které pracují s daty, včetně SQLAlchemy.
K popisu SQLAlchemy použiji citát z SQLAlchemy.org:
SQLAlchemy je sada nástrojů Python SQL a Object Relational Mapper, která poskytuje vývojářům aplikací plný výkon a flexibilitu SQL.
Poskytuje celou sadu dobře známé perzistence na podnikové úrovni vzory, navržené pro efektivní a vysoce výkonný přístup k databázi, přizpůsobené do jednoduchého jazyka domény Pythonic.
Nejdůležitější částí je zde trochu o ORM (object-relational mapper), který nám pomáhá zacházet s databázovými objekty spíše jako s objekty Pythonu než se seznamy.
Než budeme pokračovat s SQLAlchemy, zastavme se a promluvme si o ORM.
Výhody a nevýhody používání ORM
Ve srovnání s nezpracovaným SQL mají ORM své klady a zápory – a většina z nich platí i pro SQLAlchemy.
Dobré věci:
- Přenositelnost kódu. ORM se stará o syntaktické rozdíly mezi databázemi.
- Pouze jeden jazyk je potřeba pro práci s vaší databází. I když, abych byl upřímný, toto by nemělo být hlavní motivací k použití ORM.
- ORM zjednodušují váš kód , např. starají se o vztahy a zacházejí s nimi jako s předměty, což je skvělé, pokud jste zvyklí na OOP.
- Uvnitř programu můžete manipulovat se svými daty .
Bohužel vše má svou cenu. Nepříliš dobré věci o ORM:
- V některých případech může být ORM pomalé .
- Psaní složitých dotazů může být ještě komplikovanější nebo může mít za následek pomalé dotazy. To ale není případ použití SQLAlchemy.
- Pokud dobře znáte své DBMS, pak je ztráta času učit se psát stejné věci v ORM.
Nyní, když jsme toto téma zpracovali, vraťme se k SQLAlchemy.
Než začneme...
…připomeňme si cíl tohoto článku. Pokud vás zajímá pouze instalace SQLAlchemy a potřebujete rychlý návod, jak provádět jednoduché příkazy, udělá to tento článek. Příkazy uvedené v tomto článku však budou použity v dalším článku k provedení procesu ETL a nahrazení kódu SQL (uložené procedury) a Pythonu, které jsme představili v předchozích článcích.
Dobře, začněme hned na začátku:instalací SQLAlchemy.
Instalace SQLAlchemy
1. Zkontrolujte, zda je modul již nainstalován
Chcete-li použít modul Python, musíte jej nainstalovat (to znamená, pokud nebyl nainstalován dříve). Jedním ze způsobů, jak zkontrolovat, které moduly byly nainstalovány, je použití tohoto příkazu v prostředí Python:
help('modules')
Chcete-li zkontrolovat, zda je nainstalován konkrétní modul, jednoduše jej zkuste importovat. Použijte tyto příkazy:
import sqlalchemy sqlalchemy.__version__
Pokud je SQLAlchemy již nainstalován, první řádek se úspěšně spustí. import je standardní příkaz Pythonu používaný k importu modulů. Pokud modul není nainstalován, Python vyhodí chybu – vlastně seznam chyb červeným textem – kterou nemůžete přehlédnout :)
Druhý příkaz vrátí aktuální verzi SQLAlchemy. Vrácený výsledek je zobrazen níže:

Budeme také potřebovat další modul, a to je PyMySQL . Toto je lehká klientská knihovna MySQL v čistém Pythonu. Tento modul podporuje vše, co potřebujeme pro práci s databází MySQL, od spouštění jednoduchých dotazů až po složitější databázové akce. Můžeme zkontrolovat, zda existuje pomocí help('modules') , jak bylo popsáno dříve, nebo pomocí následujících dvou příkazů:
import pymysql pymysql.__version__
Samozřejmě se jedná o stejné příkazy, které jsme použili k testování, zda byla nainstalována SQLAlchemy.
Co když SQLAlchemy nebo PyMySQL ještě nejsou nainstalovány?
Import dříve nainstalovaných modulů není těžký. Co když ale potřebné moduly ještě nejsou nainstalovány?
Některé moduly mají instalační balíček, ale většinou k jejich instalaci použijete příkaz pip. PIP je nástroj Pythonu používaný k instalaci a odinstalaci modulů. Nejjednodušší způsob instalace modulu (v OS Windows) je:
- Použijte Příkazový řádek -> Spustit -> cmd .
- Umístění v adresáři Python cd C:\...\Python\Python37\Scripts .
- Spusťte příkaz pip
install(v našem případě spustímepip install pyMySQLapip install sqlAlchemy.
PIP lze také použít k odinstalaci stávajícího modulu. K tomu byste měli použít pip uninstall .
2. Připojování k databázi
I když je instalace všeho potřebného k použití SQLAlchemy nezbytná, není to příliš zajímavé. Ani to není ve skutečnosti součástí toho, co nás zajímá. Ani jsme se nepřipojili k databázím, které chceme používat. Teď to vyřešíme:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Pomocí výše uvedeného skriptu navážeme připojení k databázi umístěné na našem místním serveru subscription_live databáze.
(Poznámka: Nahraďte
Pojďme si projít skript, příkaz po příkazu.
import sqlalchemy from sqlalchemy.engine import create_engine
Tyto dva řádky importují náš modul a create_engine funkce.
Dále navážeme připojení k databázi umístěné na našem serveru.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Funkce create_engine vytvoří engine a pomocí .connect() , připojí se k databázi. create_engine funkce používá tyto parametry:
dialect+driver://username:password@host:port/database
V našem případě je dialekt mysql , ovladač je pymysql (dříve nainstalované) a zbývající proměnné jsou specifické pro server a databáze, ke kterým se chceme připojit.
(Poznámka: Pokud se připojujete místně, použijte localhost místo vaší „místní“ IP adresy 127.0.0.1 a příslušný port :3306 .)

Výsledek příkazu print(engine_live.table_names()) je znázorněno na obrázku výše. Podle očekávání jsme získali seznam všech tabulek z naší operační/živé databáze.
3. Spouštění příkazů SQL pomocí SQLAlchemy
V této části analyzujeme nejdůležitější příkazy SQL, prozkoumáme strukturu tabulky a provedeme všechny čtyři příkazy DML:SELECT, INSERT, UPDATE a DELETE.
Výroky použité v tomto skriptu probereme samostatně. Vezměte prosím na vědomí, že jsme již prošli připojovací částí tohoto skriptu a již jsme uvedli názvy tabulek. V tomto řádku jsou drobné změny:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Právě jsme importovali vše, co budeme používat z SQLAlchemy.
Tabulky a struktura
Skript spustíme zadáním následujícího příkazu v prostředí Python:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Výsledkem je spuštěný skript. Nyní pojďme analyzovat zbytek skriptu.
SQLAlchemy importuje informace související s tabulkami, strukturou a vztahy. Pro práci s těmito informacemi by mohlo být užitečné zkontrolovat seznam tabulek (a jejich sloupců) v databázi:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Tím se jednoduše vrátí seznam všech tabulek z připojené databáze.
Poznámka: table_names() metoda vrací seznam názvů tabulek pro daný engine. Můžete vytisknout celý seznam nebo jej procházet pomocí smyčky (jako byste to mohli udělat s jakýmkoli jiným seznamem).
Dále vrátíme seznam všech atributů z vybrané tabulky. Příslušná část skriptu a výsledek jsou uvedeny níže:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
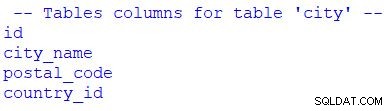
Můžete vidět, že jsem použil for procházet sadu výsledků. Mohli bychom nahradit table_city.c s table_city.columns .
Poznámka: Proces načítání popisu databáze a vytváření metadat v SQLAlchemy se nazývá reflexe.
Poznámka: MetaData jsou objekt, který uchovává informace o objektech v databázi, takže tabulky v databázi jsou také propojeny s tímto objektem. Obecně platí, že tento objekt ukládá informace o tom, jak vypadá schéma databáze. Budete jej používat jako jediný kontaktní bod, když budete chtít provést změny nebo získat fakta o schématu DB.
Poznámka: Atributy autoload = True a autoload_with = engine_live by měly být použity k zajištění toho, že atributy tabulky budou nahrány (pokud již nebyly).
VYBRAT
Myslím, že nemusím vysvětlovat, jak důležitý je příkaz SELECT :) Takže řekněme, že k psaní příkazů SELECT můžete použít SQLAlchemy. Pokud jste zvyklí na syntaxi MySQL, bude nějakou dobu trvat, než se přizpůsobíte; stejně je vše docela logické. Abych to co nejjednodušeji řekl, řekl bych, že příkaz SELECT je rozřezaný a některé části jsou vynechány, ale vše je stále ve stejném pořadí.
Zkusme nyní několik příkazů SELECT.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
První je jednoduchý příkaz SELECT vrací všechny hodnoty z dané tabulky. Syntaxe tohoto příkazu je velmi jednoduchá:název tabulky jsem umístil do select() . Všimněte si prosím, že:
- Připraveno prohlášení -
stmt = select([table_city]. - Vytiskl prohlášení pomocí
print(stmt), což nám dává dobrou představu o právě provedeném příkazu. To lze také použít pro ladění. - Výsledek byl vytištěn pomocí
print(connection_live.execute(stmt).fetchall()). - Projděte si výsledek a vytiskněte každý jednotlivý záznam.
Poznámka: Protože jsme do SQLAlchemy načetli také omezení primárního a cizího klíče, příkaz SELECT bere jako argumenty seznam objektů tabulky a automaticky vytváří vztahy tam, kde je to potřeba.
Výsledek je znázorněn na obrázku níže:

Python načte všechny atributy z tabulky a uloží je do objektu. Jak je znázorněno, můžeme tento objekt použít k provádění dalších operací. Konečným výsledkem našeho vyjádření je seznam všech měst z city tabulka.
Nyní jsme připraveni na složitější dotaz. Právě jsem přidal klauzuli ORDER BY .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Poznámka: asc() metoda provádí vzestupné řazení proti nadřazenému objektu pomocí definovaných sloupců jako parametrů.
Vrácený seznam je stejný, ale nyní je seřazen vzestupně podle hodnoty id. Je důležité poznamenat, že jsme jednoduše přidali .order_by( na předchozí dotaz SELECT. .order_by(...) metoda nám umožňuje změnit pořadí vrácené sady výsledků stejným způsobem, jaký bychom použili v dotazu SQL. Parametry by se proto měly řídit logikou SQL, používat názvy sloupců nebo pořadí sloupců a ASC nebo DESC.
Dále přidáme WHERE na náš příkaz SELECT.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Poznámka: .where() metoda se používá k testování podmínky, kterou jsme použili jako argument. Můžeme také použít .filter() metoda, která je lepší pro filtrování složitějších podmínek.
Ještě jednou .where část je jednoduše zřetězena s naším příkazem SELECT. Všimněte si, že jsme podmínku umístili do závorek. Jakákoli podmínka je v závorkách testována stejným způsobem, jako by byla testována v části WHERE příkazu SELECT. Podmínka rovnosti je testována pomocí ==namísto =.
Poslední věc, kterou zkusíme pomocí SELECT, je spojení dvou tabulek. Nejprve se podívejme na kód a jeho výsledek.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Výše uvedené prohlášení má dvě důležité části:
select([table_city.columns.city_name, table_country.columns.country_name])definuje, které sloupce budou vráceny v našem výsledku..select_from(table_city.join(table_country))definuje podmínku spojení/tabulku. Všimněte si, že jsme nemuseli zapisovat celou podmínku spojení, včetně klíčů. Je to proto, že SQLAlchemy „ví“, jak jsou tyto dvě tabulky spojeny, protože primární klíče a pravidla cizích klíčů jsou importována na pozadí.
VLOŽIT / AKTUALIZOVAT / VYMAZAT
Toto jsou tři zbývající příkazy DML, které pokryjeme v tomto článku. Zatímco jejich struktura může být velmi složitá, tyto příkazy jsou obvykle mnohem jednodušší. Použitý kód je uveden níže.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Stejný vzor se používá pro všechny tři příkazy:příprava příkazu, jeho tisk a provedení a tisk výsledku po každém příkazu, abychom viděli, co se v databázi vlastně stalo. Ještě jednou si všimněte, že části příkazu byly považovány za objekty (.values(), .where()).

Tyto znalosti využijeme v nadcházejícím článku k vytvoření celého ETL skriptu pomocí SQLAlchemy.
Další krok:SQLAlchemy v procesu ETL
Dnes jsme analyzovali, jak nastavit SQLAlchemy a jak provádět jednoduché příkazy DML. V příštím článku použijeme tyto znalosti k napsání kompletního procesu ETL pomocí SQLAlchemy.
Kompletní skript použitý v tomto článku si můžete stáhnout zde.