Python je v dnešní době velmi populární. Vzhledem k tomu, že Python je univerzální programovací jazyk, lze jej také použít k provádění procesu extrahování, transformace, načtení (ETL). K dispozici jsou různé moduly ETL, ale dnes zůstaneme u kombinace Pythonu a MySQL. Python použijeme k vyvolání uložených procedur a přípravě a provádění příkazů SQL.
Použijeme dva podobné, ale odlišné přístupy. Nejprve vyvoláme uložené procedury, které provedou celou práci, a poté budeme analyzovat, jak bychom mohli provést stejný proces bez uložených procedur pomocí kódu MySQL v Pythonu.
připraveni? Než se do toho pustíme, podívejme se na datový model – neboli datové modely, protože v tomto článku jsou dva.
Datové modely
Budeme potřebovat dva datové modely, jeden pro ukládání našich provozních dat a druhý pro ukládání dat z přehledů.
První model je zobrazen na obrázku výše. Tento model se používá k ukládání provozních (živých) dat pro podnikání založené na předplatném. Další informace o tomto modelu naleznete v našem předchozím článku Vytvoření DWH, Část první:Předplacený obchodní datový model.
Oddělení provozních a reportovacích dat je obvykle velmi moudré rozhodnutí. Abychom dosáhli tohoto oddělení, budeme muset vytvořit datový sklad (DWH). Už jsme to udělali; model můžete vidět na obrázku výše. Tento model je také podrobně popsán v příspěvku Vytvoření DWH, Část 2:Předplacený obchodní datový model.
Nakonec potřebujeme extrahovat data z živé databáze, transformovat je a načíst do našeho DWH. Již jsme to provedli pomocí uložených procedur SQL. Popis toho, čeho chceme dosáhnout, spolu s některými příklady kódu naleznete v části Vytvoření datového skladu, část 3:Předplacený obchodní datový model.
Pokud potřebujete další informace týkající se DWH, doporučujeme přečíst si tyto články:
- Hvězdné schéma
- Schéma sněhových vloček
- Hvězdné schéma vs. schéma sněhové vločky.
Naším dnešním úkolem je nahradit uložené procedury SQL kódem Python. Jsme připraveni udělat nějaké kouzlo Pythonu. Začněme používáním pouze uložených procedur v Pythonu.
Metoda 1:ETL pomocí uložených procedur
Než začneme popisovat proces, je důležité zmínit, že na našem serveru máme dvě databáze.
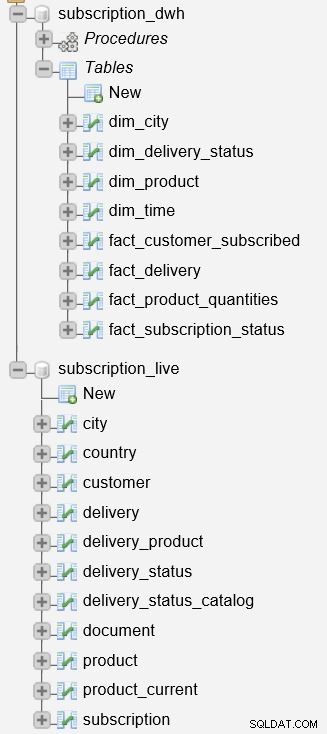
subscription_live databáze se používá k ukládání transakčních/živých dat, zatímco subscription_dwh je naše databáze hlášení (DWH).
Již jsme popsali uložené procedury používané k aktualizaci tabulek dimenzí a faktů. Budou číst data z subscription_live databázi, zkombinujte ji s daty v subscription_dwh databáze a vložte nová data do subscription_dwh databáze. Tyto dva postupy jsou:
p_update_dimensions– Aktualizuje tabulky dimenzídim_timeadim_city.p_update_facts– Aktualizuje dvě tabulky faktů,fact_customer_subscribedafact_subscription_status.
Pokud chcete vidět úplný kód pro tyto postupy, přečtěte si článek Vytvoření datového skladu, část 3:Předplacený obchodní datový model.
Nyní jsme připraveni napsat jednoduchý skript Python, který se připojí k serveru a provede proces ETL. Nejprve se podívejme na celý skript (etl_procedures.py ). Poté vysvětlíme nejdůležitější části.
# import MySQL connectorimport mysql.connector# connect to serverconnection =mysql.connector.connect(user='', password=' ', host='127.0.0.1')print('Připojeno k databáze.')cursor =connection.cursor()# Aktualizuji rozměrycursor.callproc('subscription_dwh.p_update_dimensions')print('Tabulky dimenzí aktualizovány.')# II aktualizace factscursor.callproc('subscription_dwh.p_update_facts')print('Fact tabulky aktualizovány.')# commit &close connectioncursor.close()connection.commit()connection.close()print('Odpojeno od databáze.')
etl_procedures.py
Import modulů a připojení k databázi
Python používá moduly k ukládání definic a příkazů. Můžete použít existující modul nebo napsat svůj vlastní. Používání stávajících modulů vám zjednoduší život, protože používáte předem napsaný kód, ale psaní vlastního modulu je také velmi užitečné. Když ukončíte interpret Python a znovu jej spustíte, ztratíte funkce a proměnné, které jste dříve definovali. Samozřejmě nechcete zadávat stejný kód znovu a znovu. Abyste tomu zabránili, můžete své definice uložit do modulu a importovat je do Pythonu.
Zpět na etl_procedures.py . V našem programu začínáme importem MySQL Connector:
# import MySQL konektorimport mysql.connector
Konektor MySQL pro Python se používá jako standardizovaný ovladač, který se připojuje k serveru/databázi MySQL. Budete si jej muset stáhnout a nainstalovat, pokud jste tak dosud neučinili. Kromě připojení k databázi nabízí řadu metod a vlastností pro práci s databází. Některé z nich použijeme, ale kompletní dokumentaci si můžete prohlédnout zde.
Dále se budeme muset připojit k naší databázi:
# connect to serverconnection =mysql.connector.connect(user='', heslo=' ', host='127.0.0.1')print('Připojeno k databázi.')kurzor =připojení .cursor()
První řádek se připojí k serveru (v tomto případě se připojuji k místnímu počítači) pomocí vašich přihlašovacích údajů (nahraďte
connection =mysql.connector.connect(user='', heslo=' ', host='127.0.0.1', databáze=' ')
Záměrně jsem se připojil pouze k serveru a ne ke konkrétní databázi, protože budu používat dvě databáze umístěné na stejném serveru.
Další příkaz – print – je zde pouze upozornění, že jsme byli úspěšně připojeni. I když to nemá žádný programátorský význam, lze jej použít k odladění kódu, pokud se ve skriptu něco pokazí.
Poslední řádek v této části je:
kurzor =connection.cursor()
Kurzory představují strukturu obslužné rutiny používanou k práci s daty. Využijeme je pro získávání dat z databáze (SELECT), ale také pro úpravy dat (INSERT, UPDATE, DELETE). Před použitím kurzoru jej musíme vytvořit. A to je to, co tato řada dělá.
Postupy volání
Předchozí část byla obecná a mohla být použita pro jiné úlohy související s databází. Následující část kódu je specificky pro ETL:volání našich uložených procedur pomocí cursor.callproc příkaz. Vypadá to takto:
# 1. update dimensionscursor.callproc('subscription_dwh.p_update_dimensions')print('Tabulky dimenzí aktualizovány.')# 2. update factscursor.callproc('subscription_dwh.p_update_facts')print('Tabulky faktů aktualizovány.') Postupy volání jsou do značné míry samozřejmé. Po každém volání byl přidán příkaz k tisku. Opět nám to dává oznámení, že vše proběhlo v pořádku.
Potvrdit a zavřít
Poslední část skriptu potvrdí změny databáze a zavře všechny použité objekty:
# commit &close connectioncursor.close()connection.commit()connection.close()print('Odpojeno od databáze.') Postupy volání jsou do značné míry samozřejmé. Po každém volání byl přidán příkaz k tisku. Opět nám to dává oznámení, že vše proběhlo v pořádku.
Závazek je zde zásadní; bez něj nedojde k žádným změnám v databázi, i když jste zavolali proceduru nebo provedli SQL příkaz.
Spuštění skriptu
Poslední věc, kterou musíme udělat, je spustit náš skript. K tomu použijeme následující příkazy v prostředí Python:
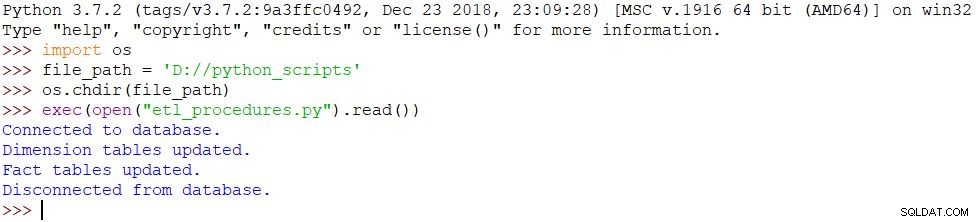
import osfile_path ='D://python_scripts'os.chdir(cesta_souboru)exec(open("etl_procedures.py").read())
Skript se provede a podle toho se provedou všechny změny v databázi. Výsledek je vidět na obrázku níže.
Metoda 2:ETL pomocí Pythonu a MySQL
Výše uvedený přístup se příliš neliší od přístupu volání uložených procedur přímo v MySQL. Jediný rozdíl je v tom, že teď máme scénář, který za nás udělá celou práci.
Mohli bychom použít jiný přístup:vše umístit do skriptu Python. Zahrneme příkazy Pythonu, ale také připravíme SQL dotazy a spustíme je v databázi. Zdrojová databáze (živá) a cílová databáze (DWH) jsou stejné jako v příkladu s uloženými procedurami.
Než se do toho ponoříme, podívejme se na celý skript (etl_queries.py ):
from datetime import date# import MySQL connectorimport mysql.connector# connect to serverconnection =mysql.connector.connect(user='', password='', host='127.0.0.1')print ('Připojeno k databázi.')# 1. aktualizace dimenzí# 1.1 aktualizace dim_time# datum - včeravčera =date.fromordinal(date.dnes().toordinal()-1)yesterday_str ='"' + str(včera) + ' "'# test, zda je datum již v tabulcecursor =connection.cursor()query =( "SELECT COUNT(*) " "FROM subscribe_dwh.dim_time " "WHERE time_date =" + včerejšek_str)cursor.execute(query)result =kurzor .fetchall()yesterday_subscription_count =int(výsledek[0][0])if včera_předplatné_count ==0:včera_rok ='YEAR("' + str(včera) + '")' včera_měsíc ='MONTH("' + str(včera) ) + '")' včera_týden ='WEEK("' + str(včera) + '")' včera_týden ='WEEKDAY("' + str(včera) + '")' query =( "INSERT INTO subscribe_dwh.`dim_time `(`time_date`, `time_year`, `time_month`, `time_week` kurzor .execute(query)# 1.2 update dim_cityquery =( "VLOŽTE DO předplatného_dwh.`dim_city`(`název_města`, `postal_code`, `country_name`, `ts`) " "VYBERTE city_live.city_name, city_live.postal_code, country_live.country , Now() " "OD předplatného_live.city city_live " "VNITŘNÍ PŘIPOJENÍ k předplatnému_live.country country_live ON city_live.country_id =country_live.id " "LEVÉ PŘIPOJENÍ k předplatnému_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name_city A PSČ_město_wh. postal_code AND country_live.country_name =city_dwh.country_name " "KDE city_dwh.id JE NULL")cursor.execute(query)print('Tabulky dimenzí aktualizovány.')# 2. aktualizovat fakta# 2.1 aktualizovat zákazníci přihlášeni# odstranit stará data pro same datequery =( "VYMAZAT předplatné_dwh.`fact_customer_subscribed`.* " "Z předplatného_dwh.`fa ct_customer_subscribed` " "VNITŘNÍ PŘIPOJENÍ předplatného_dwh.`dim_time` ZAPNUTO subscribe_dwh.`fact_customer_subscribed`.`dim_time_id` =subscribe_dwh.`dim_time`.`id` " "KDE subscribe_dwh.`dim_time`.`včera_ nebo_datum.` ="včera_ nebo) execute(query)# insert new dataquery =( "INSERT INTO subscribe_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) ") city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active =1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active =0 THEN 1 ELSE 0 END) AS total_inactive CASE WHEN customer_live.active =1 AND DATE(customer_live.time_updated) =@time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active =0 AND DATE(customer_live.time_updated) =@time_date THEN 1 ) AS daily_canceled, MIN(NOW()) AS ts " "OD předplatného_live.`customer` customer_live " "INNER JOIN subscri ption_live.`city` city_live ON customer_live.city_id =city_live.id " "VNITŘNÍ PŘIPOJENÍ předplatné_live.`country` country_live ON city_live.country_id =country_live.id " "VNITŘNÍ PŘIPOJENÍ předplatné_dwh.dim_city city_dwh ON city_live.wh.city =city_livedwh.city .postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "INNER JOIN subscribe_dwh.dim_time time_dwh ON time_dwh.time_date =" + včera_str + " " "GROUP BY city_dwh.id, time_dwh.execuid") )# 2.2 aktualizace statusů předplatného# smazat stará data pro stejný datequery =( "VYMAZAT subscribe_dwh.`fact_subscription_status`.* " "Z předplatného_dwh.`fact_subscription_status` " "VNITŘNÍ PŘIPOJENÍ předplatného_dwh.`dim_time` ON subscribe_dwh``fact_subscription_status`. dim_time_id` =subscribe_dwh.`dim_time`.`id` " "KDE subscribe_dwh.`dim_time`.`time_date` =" + včera_str)cursor.execute(query)# insert new dataquery =( "INSERT INTO subscribe_dwh.`fact _subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_dwh.id AS dim subscribe_live.active =1 POTOM 1 JINÝ 0 KONEC) JAKO total_active, SUM(PŘÍPAD, KDYŽ předplatné_live.active =0 POTOM 1 JINAK 0 KONEC) JAKO total_inactive, SUM(PŘÍPAD, KDYŽ předplatné_live.aktivní =1 A DATUM(subscription_live.time_updated) =@ time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscribe_live.active =0 AND DATE(subscription_live.time_updated) =@time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscribe_live .`customer` customer_live " "INNER JOIN subscribe_live.`subscription` subscribe_live ON subscribe_live.customer_id =customer_live.id " "INNER JOIN subscribe_live.`city` city_live ON customer_live.city_id =city_live.id " "INNER JOIN subscribe_live." country_live ON city_live.country_id =country_live.id " "VNITŘNÍ PŘIPOJTE SE k odběru_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name " "VNITŘNÍ PŘIPOJENÍ SE k odběru_dwh.dim_GROUP včera čas_str. BY city_dwh.id, time_dwh.id")cursor.execute(query)print('Tabulky faktů aktualizovány.')# potvrdit a zavřít připojenícursor.close()connection.commit()connection.close()print('Odpojeno od databáze .')
etl_queries.py
Import modulů a připojení k databázi
Ještě jednou budeme muset importovat MySQL pomocí následujícího kódu:
import mysql.connector
Importujeme také modul datetime, jak je znázorněno níže. Potřebujeme to pro operace související s datem v Pythonu:
od data importu datetime
Postup připojení k databázi je stejný jako v předchozím příkladu.
Aktualizace dim_time dimenze
Chcete-li aktualizovat dim_time tabulky, budeme muset zkontrolovat, zda je hodnota (za včerejšek) již v tabulce. K tomu budeme muset použít datové funkce Pythonu (místo SQL):
# datum - včeravčera =date.fromordinal(date.today().toordinal()-1)yesterday_str ='"' + str(včera) + '"'
První řádek kódu vrátí včerejší datum v proměnné datum, zatímco druhý řádek uloží tuto hodnotu jako řetězec. Budeme to potřebovat jako řetězec, protože ho při sestavování SQL dotazu zřetězíme s jiným řetězcem.
Dále budeme muset otestovat, zda je toto datum již v dim_time stůl. Po deklaraci kurzoru připravíme SQL dotaz. K provedení dotazu použijeme cursor.execute příkaz:
# test, jestli je datum již v tabulcecursor =connection.cursor()query =( "SELECT COUNT(*) " "FROM subscribe_dwh.dim_time " "WHERE time_date =" + včera_str)cursor.execute(query)'" '
Výsledek dotazu uložíme do výsledku variabilní. Výsledek bude mít buď 0 nebo 1 řádek, takže můžeme otestovat první sloupec prvního řádku. Bude obsahovat 0 nebo 1. (Nezapomeňte, že stejné datum můžeme mít v tabulce dimenzí pouze jednou.)
Pokud datum ještě není v tabulce, připravíme řetězce, které budou součástí SQL dotazu:
výsledek =kurzor.fetchall()yesterday_subscription_count =int(výsledek[0][0])if včerejší_počet_předplatného ==0:včera_rok ='YEAR("' + str(včera) + '")' včera_měsíc ='MONTH( "' + str(včera) + '")' včera_týden ='WEEK("' + str(včera) + '")' včera_týden ='WEEKDAY("' + str(včera) + '")' Nakonec vytvoříme dotaz a provedeme jej. Tím se aktualizuje dim_time tabulky po jejím potvrzení. Všimněte si prosím, že jsem použil úplnou cestu k tabulce, včetně názvu databáze (subscription_dwh ).
query =( "INSERT INTO subscribe_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + včera_str + ", " + včera_rok + ", " + včera_měsíc + ", " + včera_týden + ", " + včerejší_týden + ", Nyní())") kurzor.execute(dotaz) Aktualizujte dimenzi dim_city
Aktualizace dim_city stůl je ještě jednodušší, protože před vložením nemusíme nic testovat. Tento test ve skutečnosti zahrneme do dotazu SQL.
# 1.2 update dim_cityquery =( "INSERT INTO subscribe_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now () " "OD předplatného_live.city city_live " "VNITŘNÍ PŘIPOJENÍ k předplatnému_live.country country_live ON city_live.country_id =country_live.id " "LEVÉ PŘIPOJENÍ k předplatnému_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_postcode AND_postcode AND_postal_code AND_postal. country_live.country_name =city_dwh.country_name " "KDE city_dwh.id JE NULL")cursor.execute(dotaz)
Zde připravíme provedení SQL dotazu. Všimněte si, že jsem opět použil úplné cesty k tabulkám, včetně názvů obou databází (subscription_live a subscription_dwh ).
Aktualizace tabulek faktů
Poslední věc, kterou musíme udělat, je aktualizovat naše tabulky faktů. Proces je téměř stejný jako aktualizace tabulek dimenzí:připravujeme dotazy a provádíme je. Tyto dotazy jsou mnohem složitější, ale jsou stejné jako ty, které se používají v uložených procedurách.
Oproti uloženým procedurám jsme přidali jedno vylepšení:odstranění existujících dat pro stejné datum v tabulce faktů. To nám umožní spustit skript vícekrát pro stejné datum. Na konci budeme muset transakci potvrdit a zavřít všechny objekty a připojení.
Spuštění skriptu
V této části máme menší změnu, která volá jiný skript:
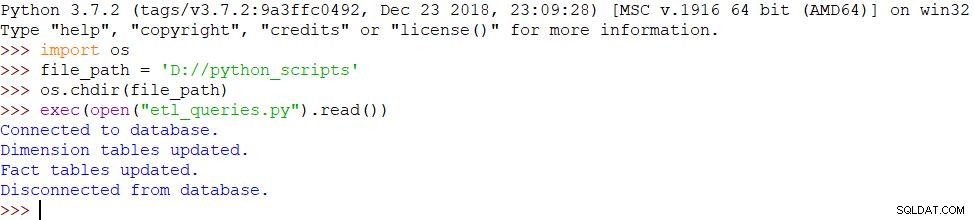
- import os- file_path ='D://python_scripts'- os.chdir(cesta_souboru)- exec(open("etl_queries.py").read())
Protože jsme použili stejné zprávy a skript byl úspěšně dokončen, výsledek je stejný:
Jak byste použili Python v ETL?
Dnes jsme viděli jeden příklad provádění procesu ETL pomocí skriptu Python. Jsou i jiné způsoby, jak toho dosáhnout, např. řada open-source řešení, která využívají Python knihovny pro práci s databázemi a provádění ETL procesu. V příštím článku si s jedním z nich pohrajeme. Mezitím se neváhejte podělit o své zkušenosti s Pythonem a ETL.