Databáze musí fungovat optimálně, ale to není tak snadný úkol. Databáze INFORMAČNÍ SCHÉMA může být vaší tajnou zbraní ve válce o optimalizaci databáze.
Jsme zvyklí vytvářet databáze pomocí grafického rozhraní nebo řady SQL příkazů. To je úplně v pořádku, ale je také dobré trochu porozumět tomu, co se děje na pozadí. To je důležité pro vytváření, údržbu a optimalizaci databáze a je to také dobrý způsob, jak sledovat změny, ke kterým dochází „v zákulisí“.
V tomto článku se podíváme na několik SQL dotazů, které vám mohou pomoci nahlédnout do fungování databáze MySQL.
Databáze INFORMATION_SCHEMA
INFORMATION_SCHEMA jsme již probrali databáze v tomto článku. Pokud jste to ještě nečetli, rozhodně vám doporučuji, abyste to udělali, než budete pokračovat.
Pokud si potřebujete zopakovat INFORMATION_SCHEMA databáze – nebo pokud se rozhodnete nečíst první článek – zde jsou některá základní fakta, která byste měli vědět:
INFORMATION_SCHEMAdatabáze je součástí standardu ANSI. Budeme pracovat s MySQL, ale další RDBMS mají své varianty. Můžete najít verze pro H2 Database, HSQLDB, MariaDB, Microsoft SQL Server a PostgreSQL.- Toto je databáze, která sleduje všechny ostatní databáze na serveru; najdeme zde popisy všech objektů.
- Jako každá jiná databáze,
INFORMATION_SCHEMAdatabáze obsahuje řadu souvisejících tabulek a informací o různých objektech. - Tuto databázi můžete dotazovat pomocí SQL a výsledky použít k:
- Sledování stavu a výkonu databáze a
- Automaticky generovat kód na základě výsledků dotazu.
Nyní přejdeme k dotazování na databázi INFORMATION_SCHEMA. Začneme tím, že se podíváme na datový model, který budeme používat.
Datový model
Model, který použijeme v tomto článku, je uveden níže.
Toto je zjednodušený model, který nám umožňuje ukládat informace o třídách, instruktorech, studentech a další související podrobnosti. Pojďme si stručně projít tabulky.
Seznam lektorů uložíme v lecturer stůl. Pro každého lektora zaznamenáme first_name a last_name .
class tabulka uvádí všechny třídy, které na naší škole máme. Pro každý záznam v této tabulce uložíme class_name , ID lektora, plánované start_date a end_date a všechny další class_details . Pro jednoduchost budu předpokládat, že máme pouze jednoho lektora na třídu.
Kurzy jsou obvykle organizovány jako série přednášek. Obvykle vyžadují jednu nebo více zkoušek. Seznamy souvisejících přednášek a zkoušek uložíme do lecture a exam tabulky. Oba budou mít ID související třídy a očekávaný start_time a end_time .
Nyní potřebujeme studenty do našich tříd. Seznam všech studentů je uložen v student stůl. Opět budeme ukládat pouze first_name a last_name každého studenta.
Poslední věc, kterou musíme udělat, je sledovat aktivity studentů. Uchováme seznam všech tříd, do kterých se student zapsal, záznamy o docházce studenta a výsledky jejich zkoušek. Každá ze zbývajících tří tabulek – on_class , on_lecture a on_exam – bude mít odkaz na studenta a odkaz na příslušnou tabulku. Pouze on_exam tabulka bude mít další hodnotu:grade.
Ano, tento model je velmi jednoduchý. Mohli bychom přidat mnoho dalších podrobností o studentech, lektorech a třídách. Při aktualizaci nebo mazání záznamů bychom mohli ukládat historické hodnoty. Přesto bude tento model pro účely tohoto článku stačit.
Vytvoření databáze
Jsme připraveni vytvořit databázi na našem lokálním serveru a prozkoumat, co se v ní děje. Model vyexportujeme (ve Vertabelo) pomocí „Generate SQL script " knoflík.
Poté vytvoříme databázi na instanci serveru MySQL. Svou databázi jsem nazval „classes_and_students “.
Další věc, kterou musíme udělat, je spustit dříve vygenerovaný skript SQL.
Nyní máme databázi se všemi jejími objekty (tabulky, primární a cizí klíče, alternativní klíče).
Velikost databáze
Po spuštění skriptu se zobrazí data o „classes and students ” databáze je uložena v INFORMATION_SCHEMA databáze. Tato data jsou v mnoha různých tabulkách. Nebudu je zde znovu všechny vypisovat; to jsme udělali v předchozím článku.
Podívejme se, jak můžeme v této databázi použít standardní SQL. Začnu jedním velmi důležitým dotazem:
SET @table_schema = "classes_and_students";
SELECT
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) AS "DB Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)"
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema;
Dotazujeme se pouze na INFORMATION_SCHEMA.TABLES stůl zde. Tato tabulka by nám měla poskytnout více než dost podrobností o všech tabulkách na serveru. Upozorňujeme, že jsem odfiltroval pouze tabulky z "classes_and_students " pomocí SET proměnnou v prvním řádku a později pomocí této hodnoty v dotazu. Většina tabulek obsahuje sloupce TABLE_NAME a TABLE_SCHEMA , které označují tabulku a schéma/databázi, do které tato data patří.
Tento dotaz vrátí aktuální velikost naší databáze a volné místo vyhrazené pro naši databázi. Zde je skutečný výsledek:

Podle očekávání je velikost naší prázdné databáze menší než 1 MB a rezervované volné místo je mnohem větší.
Velikosti a vlastnosti tabulek
Další zajímavou věcí by bylo podívat se na velikosti tabulek v naší databázi. K tomu použijeme následující dotaz:
SET @table_schema = "classes_and_students";
SELECT
INFORMATION_SCHEMA.TABLES.TABLE_NAME,
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_LENGTH + INFORMATION_SCHEMA.TABLES.INDEX_LENGTH ) / 1024 / 1024, 2) "Table Size (in MB)",
ROUND(SUM( INFORMATION_SCHEMA.TABLES.DATA_FREE )/ 1024 / 1024, 2) AS "Free Space (in MB)",
MAX( INFORMATION_SCHEMA.TABLES.TABLE_ROWS) AS table_rows_number,
MAX( INFORMATION_SCHEMA.TABLES.AUTO_INCREMENT) AS auto_increment_value
FROM INFORMATION_SCHEMA.TABLES
WHERE INFORMATION_SCHEMA.TABLES.TABLE_SCHEMA = @table_schema
GROUP BY INFORMATION_SCHEMA.TABLES.TABLE_NAME
ORDER BY 2 DESC;
Dotaz je téměř totožný s předchozím, s jedinou výjimkou:výsledek je seskupen na úrovni tabulky.
Zde je obrázek výsledku vráceného tímto dotazem:
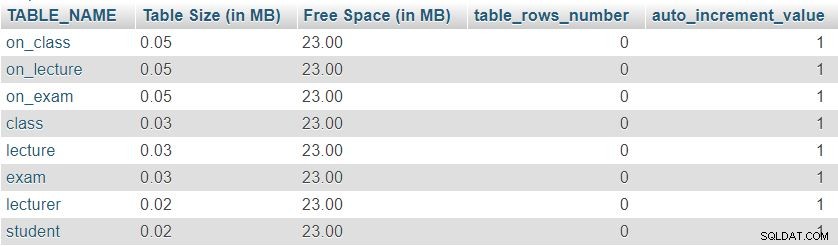
Nejprve si můžeme všimnout, že všech osm stolů má minimální „Velikost tabulky“ vyhrazeno pro definici tabulky, která zahrnuje sloupce, primární klíč a index. „Volné místo“ je rovnoměrně rozdělen mezi všechny tabulky.
Můžeme také vidět počet řádků aktuálně v každé tabulce a aktuální hodnotu auto_increment vlastnost pro každou tabulku. Protože jsou všechny tabulky zcela prázdné, nemáme žádná data a auto_increment je nastaveno na 1 (hodnota, která bude přiřazena dalšímu vloženému řádku).
Primární klíče
Každá tabulka by měla mít definovanou hodnotu primárního klíče, takže je moudré zkontrolovat, zda to platí pro naši databázi. Jedním ze způsobů, jak toho dosáhnout, je spojit seznam všech tabulek se seznamem omezení. To by nám mělo poskytnout informace, které potřebujeme.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
COUNT(*) AS PRI_number
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN (
SELECT
INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA,
INFORMATION_SCHEMA.COLUMNS.TABLE_NAME
FROM INFORMATION_SCHEMA.COLUMNS
WHERE INFORMATION_SCHEMA.COLUMNS.TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.COLUMNS.COLUMN_KEY = 'PRI'
) col
ON tab.TABLE_SCHEMA = col.TABLE_SCHEMA
AND tab.TABLE_NAME = col.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema
GROUP BY
tab.TABLE_NAME;
Použili jsme také INFORMATION_SCHEMA.COLUMNS tabulky v tomto dotazu. Zatímco první část dotazu jednoduše vrátí všechny tabulky v databázi, druhá část (po LEFT JOIN ) bude počítat počet PRI v těchto tabulkách. Použili jsme LEFT JOIN protože chceme zjistit, zda tabulka má 0 PRI ve COLUMNS tabulka.
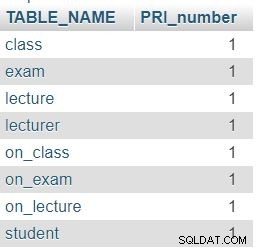
Podle očekávání obsahuje každá tabulka v naší databázi přesně jeden sloupec primárního klíče (PRI).
„Ostrovy“?
„Ostrovy“ jsou tabulky, které jsou zcela odděleny od zbytku modelu. Stávají se, když tabulka neobsahuje žádné cizí klíče a není odkazována v žádné jiné tabulce. To by se opravdu nemělo stávat, pokud k tomu není opravdu dobrý důvod, např. když tabulky obsahují parametry nebo ukládají výsledky či sestavy uvnitř modelu.
SET @table_schema = "classes_and_students";
SELECT
tab.TABLE_NAME,
(CASE WHEN f1.number_referenced IS NULL THEN 0 ELSE f1.number_referenced END) AS number_referenced,
(CASE WHEN f2.number_referencing IS NULL THEN 0 ELSE f2.number_referencing END) AS number_referencing
FROM INFORMATION_SCHEMA.TABLES tab
LEFT JOIN
-- # table was used as a reference
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME,
COUNT(*) AS number_referenced
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME
) f1
ON tab.TABLE_SCHEMA = f1.REFERENCED_TABLE_SCHEMA
AND tab.TABLE_NAME = f1.REFERENCED_TABLE_NAME
LEFT JOIN
-- # of references in the table
(
SELECT
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME,
COUNT(*) AS number_referencing
FROM INFORMATION_SCHEMA.KEY_COLUMN_USAGE
WHERE INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_SCHEMA = @table_schema
AND INFORMATION_SCHEMA.KEY_COLUMN_USAGE.REFERENCED_TABLE_NAME IS NOT NULL
GROUP BY
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_SCHEMA,
INFORMATION_SCHEMA.KEY_COLUMN_USAGE.TABLE_NAME
) f2
ON tab.TABLE_SCHEMA = f2.TABLE_SCHEMA
AND tab.TABLE_NAME = f2.TABLE_NAME
WHERE tab.TABLE_SCHEMA = @table_schema;
Jaká je myšlenka za tímto dotazem? No, používáme INFORMATION_SCHEMA.KEY_COLUMN_USAGE tabulka, chcete-li otestovat, zda je některý sloupec v tabulce odkazem na jinou tabulku nebo zda je některý sloupec použit jako odkaz v jakékoli jiné tabulce. První část dotazu vybere všechny tabulky. Po prvním LEFT JOIN spočítáme, kolikrát byl kterýkoli sloupec z této tabulky použit jako reference. Po druhém LEFT JOIN spočítáme, kolikrát kterýkoli sloupec z této tabulky odkazoval na jinou tabulku.
Vrácený výsledek je:
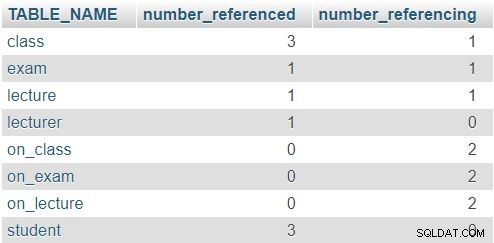
V řádku pro class tabulky, čísla 3 a 1 znamenají, že na tuto tabulku bylo odkazováno třikrát (v lecture , exam a on_class tabulky) a že obsahuje jeden atribut odkazující na jinou tabulku (lecturer_id ). Ostatní tabulky mají podobný vzorec, i když skutečná čísla se samozřejmě budou lišit. Zde platí pravidlo, že žádný řádek by neměl mít v obou sloupcích 0.
Přidávání řádků
Zatím vše probíhalo podle očekávání. Úspěšně jsme importovali náš datový model z Vertabelo na místní MySQL Server. Všechny tabulky obsahují klíče, přesně tak, jak je chceme, a všechny tabulky spolu souvisí – v našem modelu nejsou žádné „ostrovy“.
Nyní vložíme několik řádků do našich tabulek a použijeme dříve demonstrované dotazy ke sledování změn v naší databázi.
Po přidání 1 000 řádků do tabulky lektora znovu spustíme dotaz z „Table Sizes and Properties sekce “. Vrátí následující výsledek:
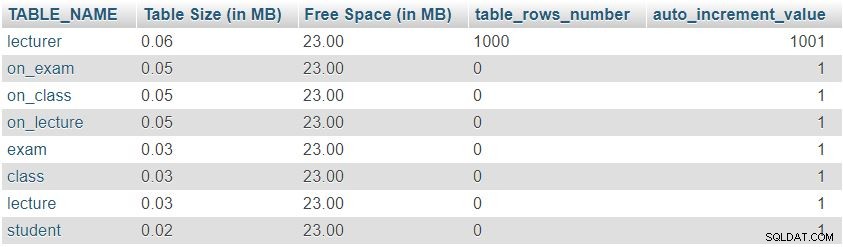
Můžeme si snadno všimnout, že počet řádků a hodnoty auto_increment se změnily podle očekávání, ale nedošlo k žádné významné změně ve velikosti tabulky.
Toto byl jen testovací příklad; v situacích reálného života bychom zaznamenali výrazné změny. Počet řádků se výrazně změní v tabulkách vyplněných uživateli nebo automatizovanými procesy (tj. tabulkách, které nejsou slovníky). Kontrola velikosti a hodnot v takových tabulkách je velmi dobrý způsob, jak rychle najít a opravit nežádoucí chování.
Chcete sdílet?
Práce s databázemi je neustálou snahou o optimální výkon. Abyste byli v tomto úsilí úspěšnější, měli byste použít jakýkoli dostupný nástroj. Dnes jsme viděli několik dotazů, které jsou užitečné v našem boji za lepší výkon. Našli jste ještě něco užitečného? Hráli jste s INFORMATION_SCHEMA databáze dříve? Podělte se o své zkušenosti v komentářích níže.