Zavedení uživatelsky přívětivého vyhledávání může být složité, ale také velmi efektivně. jak to mám vědět? Není to tak dávno, co jsem potřeboval implementovat vyhledávač do mobilní aplikace. Aplikace byla postavena na frameworku Ionic a připojovala by se k backendu CakePHP 2. Cílem bylo zobrazit výsledky, když uživatel píše. Bylo pro to několik možností, ale ne všechny splňovaly požadavky mého projektu.
Abychom ilustrovali, co tento druh úkolu zahrnuje, představme si hledání skladeb a jejich možných vztahů (jako jsou umělci, alba atd.).
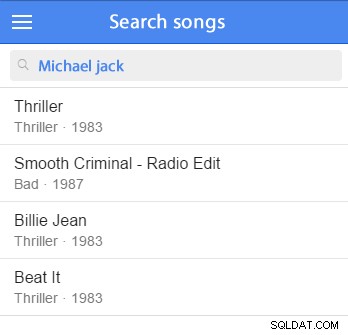
Záznamy by musely být seřazeny podle relevance, což by záviselo na tom, zda hledané slovo odpovídalo polím ze samotného záznamu nebo z jiných sloupců v souvisejících tabulkách. Vyhledávání by také mělo implementovat alespoň nějaké základní odvození slov. (Stemming se používá k získání tvaru kořene slova. "Stemmer", "stemmer", "stemming" a "stemmed" mají všechny stejný kořen:"stem".)
Zde prezentovaný přístup byl testován s několika stovkami tisíc záznamů a byl schopen získat užitečné výsledky, když uživatel psal.
Výsledky fulltextového vyhledávání
Existuje několik způsobů, jak můžeme tento druh vyhledávání implementovat. Náš projekt měl určitá omezení ve vztahu k času a zdrojům serveru, takže jsme museli řešení zachovat co nejjednodušší. Nakonec se objevilo několik uchazečů:
Elasticsearch
Elasticsearch poskytuje fulltextové vyhledávání ve službě orientované na dokumenty. Je navržen tak, aby řídil obrovské množství zátěže distribuovaným způsobem:dokáže seřadit výsledky podle relevance, provádět agregace a pracovat s odvozením slov a synonyma. Tento nástroj je určen pro vyhledávání v reálném čase. Z jejich webových stránek:
Elasticsearch staví na platformě Apache Lucene distribuované funkce, které poskytují nejvýkonnější dostupné možnosti fulltextového vyhledávání. Výkonné, pro vývojáře přívětivé rozhraní API pro dotazy podporuje vícejazyčné vyhledávání, geolokaci, kontextové návrhy, co jste mysleli, automatické doplňování a úryvky výsledků.
Elasticsearch může fungovat jako REST služba, která odpovídá na http požadavky a lze ji velmi rychle nastavit. Spuštění motoru jako služby však vyžaduje, abyste měli některá přístupová oprávnění k serveru. A pokud váš poskytovatel hostingu nepodporuje Elasticsearch hned po vybalení, budete si muset nainstalovat nějaké balíčky.
Pointa je, že tento produkt je skvělou volbou, pokud chcete spolehlivé řešení vyhledávání. (Poznámka:Možná budete potřebovat VPS nebo dedikovaný server, protože hardwarové požadavky jsou dost náročné.)
Sfinga
Stejně jako Elasticsearch, Sphinx také poskytuje velmi solidní fulltextový vyhledávací produkt:Craigslist s ním obsluhuje více než 300 000 000 dotazů denně. Sphinx neposkytuje nativní RESTful rozhraní. Je implementován v C, s menší hardwarovou stopou než Elasticsearch (který je implementován v Javě a může běžet na jakémkoli OS s jvm). Pro správný běh Sphinx budete také potřebovat root přístup k serveru s vyhrazenou RAM/CPU.
Fulltextové vyhledávání MySQL
Historicky bylo fulltextové vyhledávání podporováno v motorech MyISAM. Po verzi 5.6 MySQL také podporovalo fulltextové vyhledávání v úložištích InnoDB. To byla skvělá zpráva, protože umožňuje vývojářům těžit z referenční integrity InnoDB, schopnosti provádět transakce a zámků na úrovni řádků.
V zásadě existují dva přístupy k fulltextovému vyhledávání v MySQL:přirozený jazyk a booleovský režim. (Třetí možnost rozšiřuje vyhledávání v přirozeném jazyce o druhý rozšiřující dotaz.)
Hlavní rozdíl mezi přirozeným a booleovským režimem je v tom, že booleovský režim umožňuje určité operátory jako součást vyhledávání. Například lze použít booleovské operátory, pokud má slovo větší význam než ostatní v dotazu nebo pokud by mělo být ve výsledcích přítomno konkrétní slovo atd. Za zmínku stojí, že v obou případech lze výsledky seřadit podle relevance vypočítané podle MySQL během vyhledávání.
Rozhodování
Pro náš problém se nejlépe hodilo použití fulltextového vyhledávání InnoDb v booleovském režimu. Proč?
- Na implementaci funkce vyhledávání jsme měli málo času.
- V tuto chvíli jsme neměli žádná velká data, která bychom museli schovat, ani velké zatížení, které by vyžadovalo něco jako Elasticsearch nebo Sphinx.
- Použili jsme sdílený hosting, který nepodporuje Elasticsearch ani Sphinx a hardware byl v této fázi značně omezený.
- I když jsme v naší vyhledávací funkci chtěli, aby slova vycházela ze slov, nebyla to překážka:mohli jsme to implementovat (v rámci omezení) pomocí jednoduchého kódování PHP a denormalizace dat
- Celotextové vyhledávání v booleovském režimu může vyhledávat slova se zástupnými znaky (pro odvození slova) a třídit výsledky na základě relevance.
Fulltextové vyhledávání v booleovském režimu
Jak již bylo zmíněno, hledání v přirozeném jazyce je nejjednodušší přístup:stačí vyhledat frázi nebo slovo ve sloupcích, kde máte nastavený fulltextový index, a dostanete výsledky seřazené podle relevance.
V modelu Normalized Vertabelo
Podívejme se, jak by fungovalo jednoduché vyhledávání. Nejprve vytvoříme ukázkovou tabulku:
-- Vytvořil Vertabelo (https://vertabelo.com)-- Datum poslední úpravy:2016-04-25 15:01:22.153-- tables-- Tabulka:artistCREATE TABLE artisti ( id int(11) NOT NULL AUTO_INCREMENT, název varchar(255) NOT NULL, bio text NOT NULL, CONSTRAINT artist_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX artist_idx_1 ON artist (name);-- Konec souboru.
V režimu přirozeného jazyka
Můžete vložit nějaká ukázková data a začít testovat. (Bylo by dobré jej přidat do vaší ukázkové datové sady.) Například zkusíme vyhledat Michaela Jacksona:
VYBERTE *Z umělců, KDE SE SHODUJÍ (jméno interpreta) PROTI („Michael Jackson“ V REŽIMU PŘIROZENÉHO JAZYKA)
Tento dotaz najde záznamy, které odpovídají hledaným výrazům, a seřadí odpovídající záznamy podle relevance; čím lepší je shoda, tím je relevantnější a tím výše se výsledek zobrazí v seznamu.
V booleovském režimu
Stejné vyhledávání můžeme provést v booleovském režimu. Pokud na náš dotaz nepoužijeme žádné operátory, jediný rozdíl bude v tom, že výsledky nejsou seřazeno podle relevance:
VYBERTE *Z umělců, KDE SE SHODUJÍ (název interpreta) PROTI ('Michael Jackson' V BOOLEANSKÉM REŽIMU) Operátor zástupných znaků v booleovském režimu
Protože chceme hledat kmenová a částečná slova, budeme potřebovat zástupný operátor (*). Tento operátor lze použít při vyhledávání v booleovském režimu, a proto jsme zvolili tento režim.
Pojďme tedy uvolnit sílu booleovského vyhledávání a zkuste vyhledat část jména umělce. Operátor zástupných znaků použijeme k nalezení jakéhokoli interpreta, jehož jméno začíná na ‚Mich‘:
VYBERTE *Z umělců, KDE SE SHODUJÍ (jméno) PROTI ('Mich*' V BOOLEANSKÉM REŽIMU) Řazení podle relevance v booleovském režimu
Nyní se podívejme na vypočítanou relevanci pro vyhledávání. To nám pomůže porozumět třídění, které budeme později provádět s Cake:
SELECT *, MATCH (name) PROTI ('mich*' IN BOOLEAN MODE) AS rankFROM artistWHERE MATCH (name) PROTI ('mich*' IN BOOLEAN MODE)POŘADÍ PODLE hodnosti DESC Tento dotaz načítá shody vyhledávání a hodnotu relevance, kterou MySQL vypočítává pro každý záznam. Optimalizátor enginu zjistí, že vybíráme relevanci, takže se nebude obtěžovat přepočítáním pořadí.
Předcházení slov ve fulltextovém vyhledávání
Když do vyhledávání začleníme prameny slov, vyhledávání se stane uživatelsky přívětivější. I když výsledkem není slovo samo o sobě, algoritmy se snaží vygenerovat stejný kořen pro odvozená slova. Například kmen „argu“ není anglické slovo, ale lze jej použít jako kmen pro „argument“, „argued“, „argues“, „arguing“, „Argus“ a další slova.
Odvození zlepšuje výsledky, protože uživatel může zadat slovo, které nemá přesnou shodu, ale jeho „kmen“ ano. Ačkoli by mohla být alternativa PHP stemmer nebo Snowball's Python stemmer (pokud máte root SSH přístup k vašemu serveru), použijeme třídu PorterStemmer.php.
Tato třída implementuje algoritmus navržený Martinem Porterem pro kmenová slova v angličtině. Jak uvádí autor na svých webových stránkách, je zdarma k použití pro jakýkoli účel. Stačí umístit soubor do vašeho adresáře Vendors v CakePHP, zahrnout knihovnu do vašeho modelu a zavolat statickou metodu, která založí slovo:
//zahrnout knihovnu (měla by se jmenovat PorterStemmer.php) do složky Prodejců v CakePHPApp::import('Vendor', 'PorterStemmer'); //stopka slova (slova je třeba jedno po druhém odvozovat)echo PorterStemmer::Stem(‘odvození‘); //výstup bude ‘stopka’ Naším cílem je zrychlit a zefektivnit vyhledávání a umět výsledky třídit podle relevance celého textu. Abychom toho dosáhli, budeme muset použít odvození slov dvěma způsoby:
- Slova zadaná uživatelem
- Data související se skladbou (která uložíme do sloupců a seřadíme podle výsledků podle relevance)
První typ odvození slov lze provést takto:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /odstranit nežádoucí znaky$words =explode(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($slova jako $slovo) { $stemmedSearch .=PorterStemmer::Stem($ slovo) . "* ";//za každé slovo přidáme zástupný znak $unstemmedSearch =$word . "* ";//prohledávání sloupce interpreta, který není zakrytý}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //jinak si mySql bude stěžovat, protože nemůžete použít samotný zástupný znak $stemmedSearch =""; $unstemmedSearch ="";} Vytvořili jsme dva řetězce:jeden pro vyhledávání jména interpreta (bez odvození od názvu) a jeden pro hledání v ostatních sloupcích s odvozenými informacemi. To nám později pomůže postavit naše „proti“ část fulltextového dotazu. Nyní se podívejme, jak můžeme stopovat a třídit data skladby.
Denormalizace dat skladby
Naše kritéria řazení budou založena na tom, že se nejprve shoduje s interpretem skladby (bez odvození). Dále bude následovat název skladby, album a související kategorie. Stemming bude použit u všech sekundárních vyhledávacích kritérií.
Abych to ilustroval, předpokládejme, že hledám „nirvana“ a existuje píseň s názvem „Nirvana Games“ od „XYZ“ a další píseň s názvem „Polly“ od umělce „Nirvana“. Ve výsledcích by měla být jako první uvedena „Polly“, protože shoda se jménem interpreta je důležitější než shoda s názvem skladby (na základě mých kritérií).
Za tímto účelem jsem do songs tabulka, jedna pro každé z požadovaných kritérií vyhledávání/třídění:
ALTER TABLE `songs` PŘIDAT `denorm_artist` VARCHAR(255) NOT NULL AFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL AFTER`denorm_artist`, ADD NOT `denorm_artist`, ADD NOT `denorm_artist` 5VARCHAR denorm_trackname`,ADD `denorm_categories` VARCHAR(500) NOT NULL AFTER`denorm_album`, PŘIDAT FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album` nebo m`DD`cateries_TEXT(m`DD`cateries_TEXT);
Náš kompletní databázový model by vypadal takto:
Kdykoli uložíte skladbu pomocí add/edit v CakePHP, stačí uložit jméno interpreta do sloupce denorm_artist aniž by to zastavil. Dále do denorm_trackname přidejte odvozený název stopy pole (podobně jako jsme to udělali ve hledaném textu) a uložte název odvozeného alba do denorm_album sloupec. Nakonec uložte sadu odvozených kategorií pro skladbu do denorm_categories pole, zřetězení slov a přidání jedné mezery mezi každý odvozený název kategorie.
Fulltextové vyhledávání a třídění podle relevance v CakePHP
Pokračujeme v příkladu hledání „Nirvana“ a podívejme se, čeho může dotaz podobný tomuto dosáhnout:
SELECT trackname, MATCH(denorm_artist) PROTI ('Nirvana*' V BOOLEAN MODE) jako rank1, MATCH(denorm_trackname) PROTI ('Nirvana*' IN BOOLEAN MODE) jako rank2, MATCH(denorm_album) PROTI ('Nirvana* V BOOLEANSKÉM REŽIMU) jako rank3, MATCH(denorm_categories) PROTI ('Nirvana*' V BOOLEAN MODE) jako rank4 Z písní WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' IN BOOLEAN MODE) NEBO MATCH(denorm_trackname)PROTI* ' V BOOLEANSKÉM REŽIMU) NEBO SHODA (denorm_album) PROTI ('Nirvana*' V BOOLEANSKÉM REŽIMU) NEBO SHODA (denorm_categories) PROTI ('Nirvana*' V BOOLEANSKÉM REŽIMU) POŘADÍ PODLE hodnost1 DESC, hodnost2 DESC, hodnost43 DESC, před> Dostali bychom následující výstup:
| název stopy | rank1 | rank2 | rank3 | rank4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| nirvana hry | 0 | 0,0906190574169159 | 0 | 0 |
Chcete-li to provést v CakePHP, najít metoda musí být volána pomocí kombinace parametrů „pole“, „podmínky“ a „objednávka“. Pokračujeme v předchozím příkladu kódu PHP:
//v rámci souboru modelu Song.php $fields =array( "Song.trackname", "MATCH(Song.denorm_artist) PROTI ({$unstemmedSearch} V BOOLEAN MODE) jako `rank1`", "MATCH(Song. denorm_trackname) PROTI ({$stemmedSearch} V BOOLEANSKÉM REŽIMU) jako `rank2`", "MATCH(Song.denorm_album) PROTI ({$stemmedSearch} V BOOLEAN MODE) jako `rank3`", "MATCH(Song.denorm_categories) PROTI ( {$stemmedSearch} V BOOLEANSKÉM REŽIMU) jako `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( "NEBO" => pole( "MATCH(Song.denorm_artist) PROTI ({$unstemmedSearch} V BOOLEANSKÉM REŽIMU)", "MATCH(Song.denorm_trackname) PROTI ({$stemmedSearch} V BOOLEANSKÉM REŽIMU)", "MATCH(Song. denorm_album) PROTI ({$stemmedSearch} V BOOLEANSKÉM REŽIMU)", "MATCH(Song.denorm_categories) PROTI ({$stemmedSearch} V BOOLEANSKÉM REŽIMU)" ) );$results =$this->find (‚all‘,array(‘conditions‘=>$conditions,‘fields‘=>$fields,‘order‘=>$order); $results bude pole skladeb seřazených podle kritérií, která jsme definovali dříve.
Toto řešení lze použít ke generování vyhledávání, která jsou pro uživatele smysluplná – aniž by to od vývojářů vyžadovalo příliš mnoho času nebo zbytečně komplikovalo kód.
Vyhledávání CakePHP je ještě lepší
Stojí za zmínku, že „okořenění“ denormalizovaných sloupců větším množstvím dat může vést k lepším výsledkům.
„Kořením“ mám na mysli, že byste do denormalizovaných sloupců mohli zahrnout více údajů z dalších sloupců, které považujete za užitečné, s cílem učinit výsledky relevantnějšími, například pokud byste věděli, že země umělce může figurovat ve vyhledávacích dotazech, mohli přidat zemi spolu se jménem umělce do denorm_artist sloupec. Tím by se zlepšila kvalita výsledků vyhledávání.
Z mé zkušenosti (v závislosti na skutečných datech, která používáte, a sloupcích, které denormalizujete) bývají nejvyšší výsledky opravdu přesné. To je skvělé pro mobilní aplikace, protože procházení dlouhého seznamu může být pro uživatele frustrující.
A konečně, pokud potřebujete získat více dat z tabulek, ke kterým se skladba vztahuje, vždy se můžete připojit a získat interpreta, kategorie, alba, komentáře k písni atd. Pokud používáte filtr chování CakePHP, který je obsažen doporučujeme přidat plugin EagerLoader, aby se spojení provádělo efektivně.
Pokud máte svůj vlastní přístup k implementaci fulltextového vyhledávání, podělte se o něj v komentářích níže. Všichni se můžeme učit ze zkušeností ostatních.