O tom, proč nemám rád sp_updatestats, jsem psal již dříve. Nedávno jsem našel další důvod, proč to není můj přítel. TL;DR:Neaktualizuje statistiky indexovaných zobrazení. Nyní dokumentace netvrdí, že ano, takže zde není žádná chyba. Dokumentace MSDN jasně uvádí:
Spustí UPDATE STATISTICS pro všechny uživatelem definované a interní tabulky v aktuální databázi.Ale... kolik z vás přemýšlelo o svých indexovaných zobrazeních a přemýšlelo, zda byly aktualizovány? Přiznám se, že ne. Zapomínám na indexovaná zobrazení, což je nešťastné, protože při správném použití mohou být opravdu výkonné. Mohou být také noční můrou, kterou je třeba rozplést při odstraňování problémů, ale o jejich použití dnes nebudu polemizovat. Jen chci, abyste si byli vědomi toho, že nejsou aktualizovány pomocí sp_updatestats, a abyste viděli, jaké máte možnosti.
Nastavení
Vzhledem k tomu, že právě skončila Světová série, použijeme pro testování databázi Baseball. Můžete si jej stáhnout ze stránky SQLskills Resources. Po obnovení vytvoříme kopii tabulky dbo.Players s názvem dbo.PlayerInfo, načteme do ní několik tisíc řádků a poté vytvoříme indexovaný pohled, který připojí naši novou tabulku k tabulce PitchingPost:
USE [BaseballData];
GO
CREATE TABLE [dbo].[PlayerInfo](
[lahmanID] [int] NOT NULL,
[playerID] [varchar](10) NULL DEFAULT (NULL),
[managerID] [varchar](10) NULL DEFAULT (NULL),
[hofID] [varchar](10) NULL DEFAULT (NULL),
[birthYear] [int] NULL DEFAULT (NULL),
[birthMonth] [int] NULL DEFAULT (NULL),
[birthDay] [int] NULL DEFAULT (NULL),
[birthCountry] [varchar](50) NULL DEFAULT (NULL),
[birthState] [varchar](2) NULL DEFAULT (NULL),
[birthCity] [varchar](50) NULL DEFAULT (NULL),
[deathYear] [int] NULL DEFAULT (NULL),
[deathMonth] [int] NULL DEFAULT (NULL),
[deathDay] [int] NULL DEFAULT (NULL),
[deathCountry] [varchar](50) NULL DEFAULT (NULL),
[deathState] [varchar](2) NULL DEFAULT (NULL),
[deathCity] [varchar](50) NULL DEFAULT (NULL),
[nameFirst] [varchar](50) NULL DEFAULT (NULL),
[nameLast] [varchar](50) NULL DEFAULT (NULL),
[nameNote] [varchar](255) NULL DEFAULT (NULL),
[nameGiven] [varchar](255) NULL DEFAULT (NULL),
[nameNick] [varchar](255) NULL DEFAULT (NULL),
[weight] [int] NULL DEFAULT (NULL),
[height] [int] NULL,
[bats] [varchar](1) NULL DEFAULT (NULL),
[throws] [varchar](1) NULL DEFAULT (NULL),
[debut] [varchar](10) NULL DEFAULT (NULL),
[finalGame] [varchar](10) NULL DEFAULT (NULL),
[college] [varchar](50) NULL DEFAULT (NULL),
[lahman40ID] [varchar](9) NULL DEFAULT (NULL),
[lahman45ID] [varchar](9) NULL DEFAULT (NULL),
[retroID] [varchar](9) NULL DEFAULT (NULL),
[holtzID] [varchar](9) NULL DEFAULT (NULL),
[bbrefID] [varchar](9) NULL DEFAULT (NULL),
PRIMARY KEY CLUSTERED
([lahmanID] ASC) ON [PRIMARY]
) ON [PRIMARY];
GO
INSERT INTO [dbo].[PlayerInfo]
([lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID])
SELECT [lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID]
FROM [dbo].[Players]
WHERE [lahmanID] <= 10000;
CREATE VIEW [PlayerPostSeason]
WITH SCHEMABINDING
AS
SELECT
[p].[lahmanID],
[p].[nameFirst],
[p].[nameLast],
[p].[debut],
[p].[finalGame],
[pp].[yearID],
[pp].[round],
[pp].[teamID],
[pp].[W],
[pp].[L],
[pp].[G]
FROM [dbo].[PlayerInfo] [p]
JOIN [dbo].[PitchingPost] [pp] ON [p].[playerID] = [pp].[playerID];
CREATE UNIQUE CLUSTERED INDEX [CI_PlayerPostSeason] ON [PlayerPostSeason] ([lahmanID], [yearID], [round]);
CREATE NONCLUSTERED INDEX [NCI_PlayerPostSeason_Name] ON [PlayerPostSeason] ([nameFirst], [nameLast]); Pokud zkontrolujeme statistiky pro seskupené a neshlukované indexy, uvidíme, že existují:
DBCC SHOW_STATISTICS ('PlayerPostSeason', CI_PlayerPostSeason) WITH STAT_HEADER;
GO
DBCC SHOW_STATISTICS ('PlayerPostSeason', NCI_PlayerPostSeason_Name) WITH STAT_HEADER;
GO
 Statistiky zobrazení indexu po prvním vytvoření
Statistiky zobrazení indexu po prvním vytvoření
Nyní vložíme další řádky do PlayerInfo:
INSERT INTO [dbo].[PlayerInfo]
([lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID])
SELECT [lahmanID]
,[playerID]
,[managerID]
,[hofID]
,[birthYear]
,[birthMonth]
,[birthDay]
,[birthCountry]
,[birthState]
,[birthCity]
,[deathYear]
,[deathMonth]
,[deathDay]
,[deathCountry]
,[deathState]
,[deathCity]
,[nameFirst]
,[nameLast]
,[nameNote]
,[nameGiven]
,[nameNick]
,[weight]
,[height]
,[bats]
,[throws]
,[debut]
,[finalGame]
,[college]
,[lahman40ID]
,[lahman45ID]
,[retroID]
,[holtzID]
,[bbrefID]
FROM [dbo].[Players]
WHERE [lahmanID] > 10000; A pokud zkontrolujeme sys.dm_db_stats_properties, můžeme vidět úpravy řádku:
SELECT
[sch].[name] AS [Schema],
[so].[name] AS [ObjectName],
[so].[type] AS [ObjectType],
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated] ,
[sp].[rows] AS [RowsInTable] ,
[sp].[rows_sampled] AS [RowsSampled] ,
[sp].[modification_counter] AS [RowModifications]
FROM [sys].[objects] [so]
JOIN [sys].[stats] [ss] ON [so].[object_id] = [ss].[object_id]
JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id],
[ss].[stats_id]) sp
WHERE [so].[name] = 'PlayerPostSeason';
 Řádky upravené v indexovaném zobrazení prostřednictvím sys.dm_db_stats_properties
Řádky upravené v indexovaném zobrazení prostřednictvím sys.dm_db_stats_properties
A jen pro zajímavost, když zkontrolujeme sys.sysindexes, můžeme vidět úpravy i tam:
SELECT [so].[name], [si].[name], [si].[rowcnt], [si].[rowmodctr] FROM [sys].[sysindexes] [si] JOIN [sys].[objects] [so] ON [si].[id] = [so].[object_id] WHERE [so].[name] = 'PlayerPostSeason';
 Řádky upravené v indexovaném zobrazení prostřednictvím sys.sysindexes
Řádky upravené v indexovaném zobrazení prostřednictvím sys.sysindexes
Nyní je sys.sysindexes zastaralý, ale pokud si pamatujete z mého předchozího příspěvku, tak to sp_updatestats používá k zobrazení toho, co bylo změněno. Ale… seznam objektů pro sys.indexes je řízen dotazem na sys.objects, který, pokud si vzpomínáte, filtruje uživatelské tabulky ('U') a interní tabulky ('IT'). Nezahrnuje zobrazení ('V') v tomto filtru. Když tedy spustíme sp_updatestats a zkontrolujeme výstup (pro stručnost není součástí), není zde žádná zmínka o našem zobrazení PlayerPostSeason.
Pokud tedy máte indexovaná zobrazení a při aktualizaci statistik spoléháte na sp_updatestats, statistiky zobrazení se neaktualizují. Tipoval bych však, že většina z vás má pro své databáze povolenou možnost Auto Update Statistics. To je dobře, protože s touto možností se statistiky zobrazení aktualizují, pokud byly zrušeny. Víme, že jsme provedli více než 2000 úprav indexů na PlayerPostSeason. Pokud se dotazujeme podle selektivního křestního jména, náš plán dotazů by měl používat index NCI_PlayerPostSeason_Name, a protože statistiky jsou zastaralé, měly by být aktualizovány. Zkontrolujeme:
SELECT * FROM [PlayerPostSeason] WHERE [nameFirst] = 'Madison'; GO
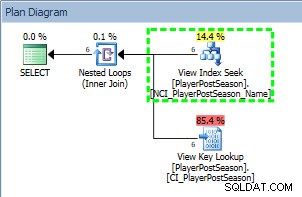 Plán dotazů z SELECT proti neshlukovanému indexu
Plán dotazů z SELECT proti neshlukovanému indexu
V plánu vidíme, že byl použit neklastrovaný index NCI_PlayerPostSeason_Name, a pokud zkontrolujeme statistiky:
 Statistiky po automatické aktualizaci
Statistiky po automatické aktualizaci
Statistiky pro neshlukovaný index byly samozřejmě aktualizovány. Ale samozřejmě nechceme při správě statistik spoléhat na automatickou aktualizaci, chceme být proaktivní. Máme dvě možnosti:
- Úkol údržby
- Vlastní skript
Úloha údržby statistik aktualizace provádí aktualizovat statistiky zobrazení. Toto není nikde v uživatelském rozhraní výslovně uvedeno, ale pokud vytvoříme plán údržby s úlohou aktualizace statistiky a spustíme ji, statistiky pro indexované zobrazení se aktualizují. Nevýhodou úlohy údržby statistik aktualizace je, že jde o přístup jako kladivo. Aktualizuje vše statistiky, bez ohledu na to, zda je to potřeba (je to skoro stejně špatné jako sp_updatestats). Dávám přednost vlastnímu skriptu, kde SQL Server aktualizuje pouze to, co bylo změněno. Pokud nechcete vytvářet svůj vlastní scénář, můžete použít scénář Ola Hallengrena. Aktualizace statistik je běžnou součástí přestavby a reorganizace indexu. Například s Oliným skriptem v úloze SQL Agent byste měli:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "PROVEĎ [dbo].[IndexOptimize] @Databases ='BaseballData', @FragmentationLow =NULL, @FragmentationMedium ='INDEX_REORGANIZE',High =BUILATION ', @FragmentationLevel1 =5, @FragmentationLevel2 =30, @UpdateStatistics ='ALL', @OnlyModifiedStatistics ='Y', @LogToTable ='Y'" –bS touto volbou, pokud byly statistiky upraveny, budou aktualizovány, a pokud zkontrolujeme uloženou proceduru [dbo].[IndexOptimize], uvidíme, kde Ola kontroluje změny:
-- Has the data in the statistics been modified since the statistics was last updated?
IF @CurrentStatisticsID IS NOT NULL AND @UpdateStatistics IS NOT NULL AND @OnlyModifiedStatistics = 'Y'
BEGIN
SET @CurrentCommand10 = ''
IF @LockTimeout IS NOT NULL SET @CurrentCommand10 = 'SET LOCK_TIMEOUT ' + CAST(@LockTimeout * 1000 AS nvarchar) + '; '
IF (@Version >= 10.504000 AND @Version < 11) OR @Version >= 11.03000
BEGIN
SET @CurrentCommand10 = @CurrentCommand10 + 'USE ' + QUOTENAME(@CurrentDatabaseName)
+ '; IF EXISTS(SELECT * FROM sys.dm_db_stats_properties (@ParamObjectID, @ParamStatisticsID)
WHERE modification_counter > 0) BEGIN SET @ParamStatisticsModified = 1 END'
END
ELSE
BEGIN
SET @CurrentCommand10 = @CurrentCommand10 + 'IF EXISTS(SELECT * FROM '
+ QUOTENAME(@CurrentDatabaseName) + '.sys.sysindexes sysindexes
WHERE sysindexes.[id] = @ParamObjectID AND sysindexes.[indid] = @ParamStatisticsID
AND sysindexes.[rowmodctr] <> 0) BEGIN SET @ParamStatisticsModified = 1 END'
END U verzí, které podporují DMF sys.dm_db_stats_properties, Ola zkontroluje všechny statistiky, které byly změněny, au verzí, které nepodporují nový DMF sys.dm_db_stats_properties, zkontroluje systémovou tabulku sys.sysindexes. Moje jediná stížnost je, že se skript chová stejně jako sp_updatestats:pokud byl upraven alespoň jeden řádek, statistika bude aktualizována.
Pokud vás nebaví psát si svůj vlastní kód pro správu statistik, pak bych doporučil držet se Oly skriptu. Ale pokud chcete své aktualizace zacílit trochu více, pak bych doporučil použít sys.dm_db_stats_properties. Tento DMF je k dispozici pouze pro SQL Server 2008R2 SP2 a vyšší a SQL Server 2012 SP1 a vyšší, takže pokud používáte nižší verzi, budete muset použít sys.indexes. Ale pro ty z vás, kteří mají přístup k sys.dm_db_stats_properties, je zde dotaz, který vám pomůže začít:
SELECT
[sch].[name] AS [Schema],
[so].[name] AS [ObjectName],
[so].[type] AS [ObjectType],
[ss].[name] AS [Statistic],
[sp].[last_updated] AS [StatsLastUpdated] ,
[sp].[rows] AS [RowsInTable] ,
[sp].[rows_sampled] AS [RowsSampled] ,
CAST(100 * [sp].[rows_sampled] / [sp].[rows] AS DECIMAL (18, 2)) AS [PercentSampled],
[sp].[modification_counter] AS [RowModifications] ,
CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18, 2)) AS [PercentChange]
FROM [sys].[objects] AS [so]
INNER JOIN [sys].[stats] AS [ss] ON [so].[object_id] = [ss].[object_id]
INNER JOIN [sys].[schemas] AS [sch] ON [so].[schema_id] = [sch].[schema_id]
OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) AS [sp]
WHERE [so].[type] IN ('U','V')
AND ((CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18,2)) >= 10.0))
ORDER BY CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18, 2)) DESC; Všimněte si, že pomocí sys.objects filtrujeme podle tabulek a pohledů; můžete to změnit tak, aby zahrnovalo systémové tabulky. Potom můžete upravit predikát tak, aby načítal pouze řádky na základě procenta upravených řádků, nebo možná kombinace procenta modifikace a počtu řádků (u tabulek s miliony nebo miliardami řádků může být toto procento nižší než u malých tabulek).
Shrnutí
Zpráva take home je zde docela jasná:Nedoporučuji používat sp_updatestats ke správě statistik. Statistiky se aktualizují, když se změní jeden nebo více řádků (což je extrémně nízká hranice pro aktualizaci statistik) a statistiky pro indexovaná zobrazení ne aktualizováno. Toto není komplexní a efektivní metoda pro správu statistik…a úloha aktualizace statistik v plánu údržby není o mnoho lepší. Aktualizuje statistiky indexovaného zobrazení, ale aktualizuje se každý statistika, bez ohledu na úpravy. Vlastní skript je opravdu správná cesta, ale pochopte, že skript Ola Hallengrena, pokud aktualizujete na základě úpravy, se také aktualizuje, když byl upraven pouze řádek (ale alespoň získá indexovaná zobrazení). Nakonec, pro nejlepší kontrolu, zkuste vytvořit svůj vlastní skript pro správu statistik. Dal jsem vám základní dotaz pro začátek. Pokud si můžete zablokovat několik hodin, abyste si procvičili psaní T-SQL a poté to otestovali, budete mít pro své databáze připravený funkční vlastní skript, než se objeví prázdniny.