Každý produkt má chyby a SQL Server není výjimkou. Použití funkcí produktu trochu neobvyklým způsobem (nebo kombinování relativně nových funkcí dohromady) je skvělý způsob, jak je najít. Chyby mohou být zajímavé a dokonce i poučné, ale možná se část radosti ztratí, když se díky zjištění spustí váš pager ve 4 hodiny ráno, možná po obzvlášť společenském večeru s přáteli…
Chyba, která je předmětem tohoto příspěvku, je ve volné přírodě pravděpodobně přiměřeně vzácná, ale nejedná se o klasický edge case. Vím alespoň o jednom konzultantovi, který se s tím ve výrobním systému setkal. Na zcela nesouvisející téma bych měl využít této příležitosti a pozdravit Grumpy Old DBA (blog).
Začnu nějakým relevantním pozadím sloučení spojení. Pokud jste si jisti, že již víte vše, co je třeba vědět o spojení sloučením, nebo se jen chcete pustit do toho, přejděte dolů do sekce s názvem "The Bug."
Merge Join
Merge join není příliš složitá věc a za správných okolností může být velmi efektivní. Vyžaduje, aby byly jeho vstupy seřazeny podle spojovacích klíčů, a nejlépe funguje v režimu one-to-many (kde jsou alespoň jeho vstupy jedinečné na spojovacích klíčích). U středně velkých spojení typu one-to-many není sériové spojení spojením vůbec špatnou volbou, za předpokladu, že požadavky na třídění vstupů lze splnit bez provedení explicitního řazení.
Vyhnutí se řazení se nejčastěji dosahuje využitím řazení poskytovaného indexem. Sloučit spojení může také využít zachované pořadí řazení z dřívějšího, nevyhnutelného řazení. Skvělá věc na slučovacím spojení je, že může zastavit zpracování vstupních řádků, jakmile některý ze vstupů vyčerpá řádky. Poslední věc:merge join se nestará o to, zda je pořadí řazení vstupů vzestupné nebo sestupné (ačkoli oba vstupy musí být stejné). Následující příklad používá standardní tabulku čísel k ilustraci většiny výše uvedených bodů:
CREATE TABLE #T1 (col1 integer CONSTRAINT PK1 PRIMARY KEY (col1 DESC)); CREATE TABLE #T2 (col1 integer CONSTRAINT PK2 PRIMARY KEY (col1 DESC)); INSERT #T1 SELECT n FROM dbo.Numbers WHERE n BETWEEN 10000 AND 19999; INSERT #T2 SELECT n FROM dbo.Numbers WHERE n BETWEEN 18000 AND 21999;
Všimněte si, že indexy vynucující primární klíče v těchto dvou tabulkách jsou definovány jako sestupné. Plán dotazů pro INSERT má řadu zajímavých funkcí:
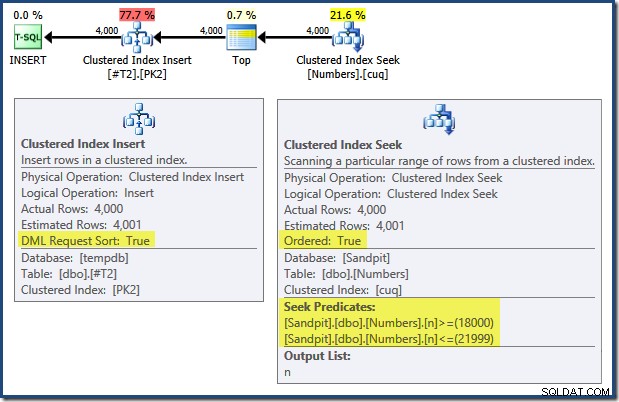
Čtení zleva doprava (jak je jedině rozumné!) má vložka seskupeného indexu nastavenou vlastnost "DML Request Sort". To znamená, že operátor vyžaduje řádky v pořadí klíčů Clustered Index. Clusterový index (v tomto případě vynucující primární klíč) je definován jako DESC , takže řádky s vyššími hodnotami musí být doručeny jako první. Seskupený index v mé tabulce čísel je ASC , takže se optimalizátor dotazů vyhýbá explicitnímu řazení tím, že nejprve hledá nejvyšší shodu v tabulce Numbers (21 999) a poté skenuje směrem k nejnižší shodě (18 000) v obráceném pořadí indexu. Zobrazení "Strom plánu" v SQL Sentry Plan Explorer jasně ukazuje zpětné (zpětné) skenování:
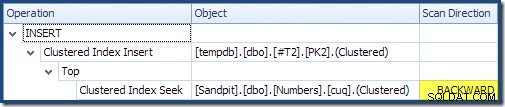
Zpětné skenování obrátí přirozené pořadí indexu. Zpětné skenování ASC indexový klíč vrací řádky v sestupném pořadí klíčů; zpětné skenování DESC indexový klíč vrací řádky ve vzestupném pořadí klíčů. "Směr skenování" sám o sobě neoznačuje vrácené pořadí klíče - musíte vědět, zda je index ASC nebo DESC učinit toto rozhodnutí.
Pomocí těchto testovacích tabulek a dat (T1 má 10 000 řádků očíslovaných od 10 000 do 19 999 včetně; T2 má 4 000 řádků očíslovaných od 18 000 do 21 999) následující dotaz spojí dvě tabulky dohromady a vrátí výsledky v sestupném pořadí obou klíčů:
SELECT
T1.col1,
T2.col1
FROM #T1 AS T1
JOIN #T2 AS T2
ON T2.col1 = T1.col1
ORDER BY
T1.col1 DESC,
T2.col1 DESC; Dotaz vrátí správných odpovídajících 2 000 řádků, jak byste očekávali. Plán po provedení je následující:
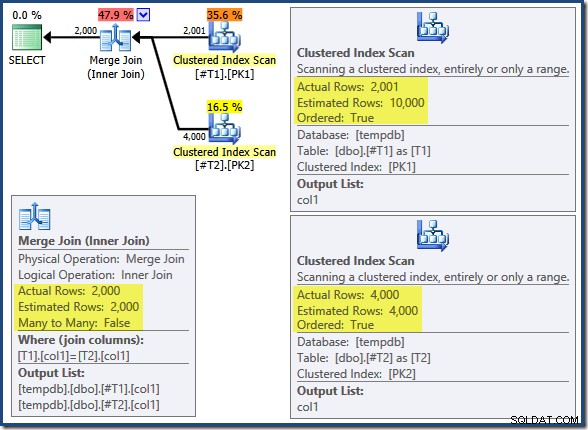
Sloučení spojení neběží v režimu many-to-many (horní vstup je jedinečný na klávesách spojení) a odhad mohutnosti 2 000 řádků je přesně správný. Clustered Index Scan tabulky T2 je seřazeno (ačkoli musíme chvíli počkat, abychom zjistili, zda je toto pořadí vpřed nebo vzad) a odhad mohutnosti 4 000 řádků je také naprosto správný. Clustered Index Scan tabulky T1 je také objednáno, ale bylo přečteno pouze 2 001 řádků, zatímco odhadem 10 000. Zobrazení stromu plánu ukazuje, že obě skenování indexu clusteru jsou seřazeny dopředu:
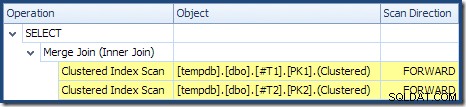
Připomeňme, že čtení DESC index FORWARD vytvoří řádky v obráceném pořadí klíče. To je přesně to, co vyžaduje ORDER BY T1.col DESC, T2.col1 DESC klauzule, takže není nutné žádné explicitní řazení. Pseudokód pro připojení jednoho k mnoha Merge Join (převzato z blogu Merge Join od Craiga Freedmana) je:

Skenování T1 v sestupném pořadí vrátí řádky začínající na 19 999 a směrem dolů k 10 000. Skenování T2 v sestupném pořadí vrátí řádky začínající na 21 999 a směrem dolů k 18 000. Všech 4 000 řádků v T2 jsou nakonec načteny, ale proces iterativního slučování se zastaví, když je z T1 načtena hodnota klíče 17 999 , protože T2 dojdou řádky. Zpracování sloučení se tedy dokončí bez úplného přečtení T1 . Čte řádky od 19 999 dolů do 17 999 včetně; celkem 2 001 řádků, jak je uvedeno ve výše uvedeném plánu provádění.
Neváhejte a spusťte test znovu pomocí ASC místo toho indexy a také změnou ORDER BY klauzule z DESC do ASC . Vytvořený prováděcí plán bude velmi podobný a nebudou potřeba žádné druhy.
Abychom shrnuli body, které budou za chvíli důležité, Merge Join vyžaduje vstupy seřazené podle spojovacího klíče, ale nezáleží na tom, zda jsou klíče seřazeny vzestupně nebo sestupně.
Chyba
Aby se chyba reprodukovala, musí být alespoň jedna z našich tabulek rozdělena na oddíly. Aby bylo možné výsledky spravovat, bude tento příklad používat pouze malý počet řádků, takže funkce rozdělení potřebuje také malé hranice:
CREATE PARTITION FUNCTION PF (integer) AS RANGE RIGHT FOR VALUES (5, 10, 15); CREATE PARTITION SCHEME PS AS PARTITION PF ALL TO ([PRIMARY]);
První tabulka obsahuje dva sloupce a je rozdělena na PRIMÁRNÍ KLÍČ:
CREATE TABLE dbo.T1
(
T1ID integer IDENTITY (1,1) NOT NULL,
SomeID integer NOT NULL,
CONSTRAINT [PK dbo.T1 T1ID]
PRIMARY KEY CLUSTERED (T1ID)
ON PS (T1ID)
);
Druhá tabulka není rozdělena. Obsahuje primární klíč a sloupec, který se připojí k první tabulce:
CREATE TABLE dbo.T2
(
T2ID integer IDENTITY (1,1) NOT NULL,
T1ID integer NOT NULL,
CONSTRAINT [PK dbo.T2 T2ID]
PRIMARY KEY CLUSTERED (T2ID)
ON [PRIMARY]
); Ukázková data
První tabulka má 14 řádků, všechny se stejnou hodnotou v SomeID sloupec. SQL Server přiřadí IDENTITY hodnoty sloupce, číslované od 1 do 14.
INSERT dbo.T1
(SomeID)
VALUES
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123), (123),
(123), (123);
Druhá tabulka je jednoduše vyplněna IDENTITY hodnoty z tabulky jedna:
INSERT dbo.T2 (T1ID) SELECT T1ID FROM dbo.T1;
Data ve dvou tabulkách vypadají takto:
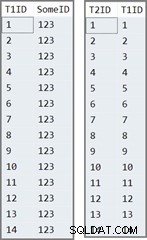
Testovací dotaz
První dotaz jednoduše spojí obě tabulky použitím jediného predikátu klauzule WHERE (který náhodou odpovídá všem řádkům v tomto značně zjednodušeném příkladu):
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123; Výsledek obsahuje všech 14 řádků podle očekávání:

Kvůli malému počtu řádků zvolí optimalizátor pro tento dotaz plán spojení vnořených smyček:
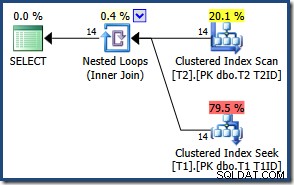
Výsledky jsou stejné (a stále správné), pokud vynutíme hash nebo sloučení spojení:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (HASH JOIN);
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
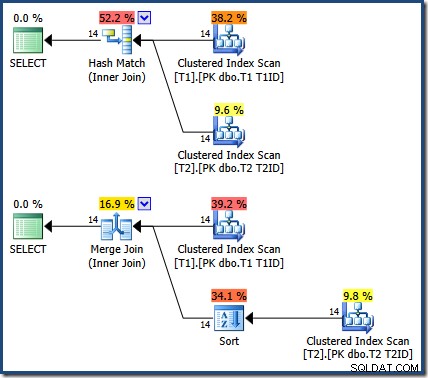
Merge Join tam je jedna k mnoha, s explicitním řazením podle T1ID vyžadováno pro tabulku T2 .
Problém sestupného indexu
Vše je v pořádku, dokud jednoho dne (z dobrých důvodů, které nás zde nemusí znepokojovat) jiný administrátor nepřidá sestupný index na SomeID sloupec tabulky 1:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC);
Náš dotaz nadále poskytuje správné výsledky, když optimalizátor zvolí vnořené smyčky nebo hash spojení, ale je to jiný příběh, když se použije spojení sloučení. Následující stále používá nápovědu k dotazu k vynucení spojení sloučení, ale to je jen důsledek nízkého počtu řádků v příkladu. Optimalizátor by přirozeně zvolil stejný plán spojení sloučení s jinými daty tabulky.
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN); Prováděcí plán je:
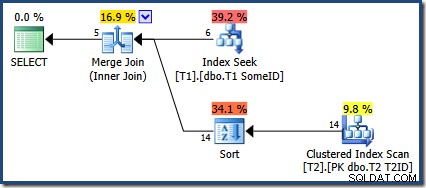
Optimalizátor se rozhodl použít nový index, ale dotaz nyní produkuje pouze pět řádků výstupu:

Co se stalo s dalšími 9 řadami? Aby bylo jasno, tento výsledek je nesprávný. Data se nezměnila, takže by mělo být vráceno všech 14 řádků (jak tomu stále je s plánem Nested Loops nebo Hash Join).
Příčina a vysvětlení
Nový neklastrovaný index na SomeID není deklarován jako jedinečný, takže seskupený indexový klíč je bezobslužně přidán do všech neklastrovaných úrovní indexu. SQL Server přidá T1ID sloupec (shlukovaný klíč) do neshlukovaného indexu, stejně jako kdybychom index vytvořili takto:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID);
Všimněte si, že chybí DESC kvalifikátor na tiše přidaném T1ID klíč. Indexové klíče jsou ASC ve výchozím stavu. To samo o sobě není problém (i když to přispívá). Druhá věc, která se našemu indexu stane automaticky, je, že je rozdělen stejným způsobem jako základní tabulka. Takže úplná specifikace indexu, pokud bychom ji měli napsat explicitně, by byla:
CREATE NONCLUSTERED INDEX [dbo.T1 SomeID] ON dbo.T1 (SomeID DESC, T1ID ASC) ON PS (T1ID);
Toto je nyní poměrně složitá struktura s klíči v nejrůznějším pořadí. Je dostatečně komplexní na to, aby se optimalizátor dotazů mýlil, když uvažoval o pořadí řazení poskytovaném indexem. Pro ilustraci zvažte následující jednoduchý dotaz:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;
Sloupec navíc nám pouze ukáže, do kterého oddílu aktuální řádek patří. Jinak je to jen jednoduchý dotaz, který vrací T1ID hodnoty ve vzestupném pořadí, WHERE SomeID = 123 . Bohužel výsledky nejsou takové, jaké specifikuje dotaz:
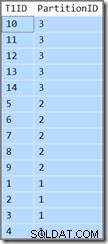
Dotaz vyžaduje T1ID hodnoty by měly být vráceny ve vzestupném pořadí, ale to není to, co získáme. Dostáváme hodnoty ve vzestupném pořadí na oddíl , ale samotné oddíly jsou vráceny v opačném pořadí! Pokud byly oddíly vráceny ve vzestupném pořadí (a T1ID hodnoty zůstaly seřazeny v rámci každého oddílu, jak je znázorněno), výsledek by byl správný.
Plán dotazů ukazuje, že optimalizátor byl zmaten hlavním DESC klíč indexu a myslel si, že pro správné výsledky potřebuje číst oddíly v opačném pořadí:
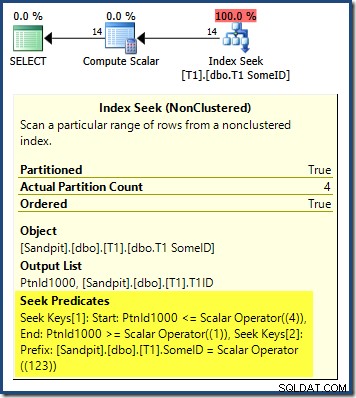
Hledání oddílu začíná na oddílu úplně vpravo (4) a pokračuje zpět k oddílu 1. Možná si myslíte, že bychom mohli problém vyřešit explicitním řazením podle čísla oddílu ASC v ORDER BY klauzule:
SELECT
T1ID,
PartitionID = $PARTITION.PF(T1ID)
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
PartitionID ASC, -- New!
T1ID ASC; Tento dotaz vrací stejné výsledky (nejedná se o tiskovou chybu nebo chybu při kopírování/vkládání):
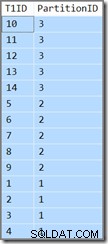
ID oddílu je stále sestupně pořadí (ne vzestupně, jak je uvedeno) a T1ID je v rámci každého oddílu seřazeno pouze vzestupně. Optimalizátor má takový zmatek, opravdu si myslí (teď se zhluboka nadechněte), že skenování rozděleného indexu předního a sestupného klíče v dopředném směru, ale s obrácenými oddíly, povede k pořadí určenému dotazem.
Neobviňuji to, abych byl upřímný, z různých úvah o řazení mě taky bolí hlava.
Jako poslední příklad zvažte:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID DESC; Výsledky jsou:

Opět T1ID pořadí řazení v rámci každého oddílu je správně sestupně, ale samotné oddíly jsou uvedeny pozpátku (jsou od 1 do 3 dolů v řádcích). Pokud by byly oddíly vráceny v opačném pořadí, výsledky by byly správně 14, 13, 12, 11, 10, 9, … 5, 4, 3, 2, 1 .
Zpět na připojení ke sloučení
Příčina nesprávných výsledků s dotazem Merge Join je nyní zřejmá:
SELECT
T2.T2ID
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.T1ID = T1.T1ID
WHERE
T1.SomeID = 123
OPTION (MERGE JOIN);
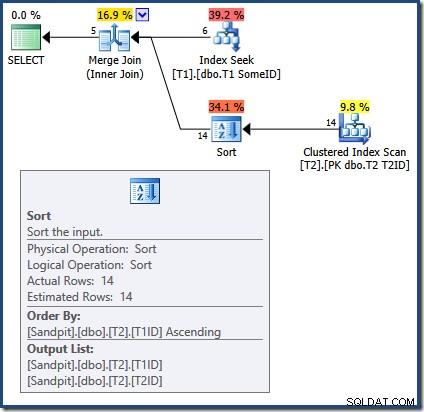
Sloučení spojení vyžaduje seřazené vstupy. Vstup z T2 je explicitně řazeno podle T1TD tak to je v pořádku. Optimalizátor nesprávně zdůvodňuje, že index na T1 může poskytnout řádky v T1ID objednat. Jak jsme viděli, není tomu tak. Index Seek vytváří stejný výstup jako dotaz, který jsme již viděli:
SELECT
T1ID
FROM dbo.T1
WHERE
SomeID = 123
ORDER BY
T1ID ASC;

Pouze prvních 5 řádků je v T1ID objednat. Další hodnota (5) rozhodně není ve vzestupném pořadí a spojení Merge Join to interpretuje jako konec proudu, spíše než aby způsobilo chybu (osobně jsem zde očekával maloobchodní tvrzení). Výsledkem je, že spojení sloučení nesprávně dokončí zpracování dříve. Připomínáme, že (neúplné) výsledky jsou:

Závěr
To je z mého pohledu velmi závažná chyba. Jednoduché hledání indexu může vrátit výsledky, které nerespektují ORDER BY doložka. Přesněji řečeno, vnitřní uvažování optimalizátoru je zcela nefunkční pro rozdělené nejedinečné neklastrované indexy se sestupným úvodním klíčem.
Ano, toto je mírně neobvyklé uspořádání. Ale jak jsme viděli, správné výsledky mohou být náhle nahrazeny nesprávnými výsledky jen proto, že někdo přidal sestupný index. Pamatujte, že přidaný index vypadal docela nevinně:žádné explicitní ASC/DESC klíčová neshoda a žádné explicitní rozdělení.
Chyba není omezena na Merge Joins. Obětí by se mohl stát jakýkoli dotaz, který zahrnuje dělenou tabulku a který závisí na pořadí řazení indexu (explicitní nebo implicitní). Tato chyba existuje ve všech verzích SQL Server od roku 2008 do roku 2014 CTP 1 včetně. Windows SQL Azure Database nepodporuje dělení, takže problém nevzniká. SQL Server 2005 používal jiný model implementace pro dělení (založený na APPLY ) a ani tímto problémem netrpí.
Pokud máte chvilku, zvažte prosím hlasování o mé položce Connect pro tuto chybu.
Rozlišení
Oprava tohoto problému je nyní k dispozici a je zdokumentována v článku znalostní báze Knowledge Base. Upozorňujeme, že oprava vyžaduje aktualizaci kódu a příznak trasování 4199 , který umožňuje řadu dalších změn procesoru dotazů. Je neobvyklé, že chyba s nesprávnými výsledky bude opravena pod číslem 4199. Požádal jsem o vysvětlení a odpověď byla:
I když tento problém zahrnuje nesprávné výsledky jako jiné opravy hotfix zahrnující procesor dotazů, tuto opravu jsme povolili pouze pod příznakem trasování 4199 pro SQL Server 2008, 2008 R2 a 2012. Tato oprava je však zapnutá výchozí bez příznaku trasování v SQL Server 2014 RTM.