
Nedávno jsem byl pokárán za to, že jsem v některých případech uvedl, že neklastrovaný index bude pro konkrétní dotaz fungovat lépe než seskupený index. Tato osoba uvedla, že seskupený index je vždy nejlepší, protože vždy pokrývá z definice, a že jakýkoli neshlukovaný index s některými nebo všemi stejnými klíčovými sloupci byl vždy nadbytečný.
S radostí souhlasím s tím, že seskupený index je vždy pokrývající (a abychom se vyhnuli nejasnostem, budeme se držet diskových tabulek s tradičními indexy B-stromu).
 Nesouhlasím však s tím, že seskupený index je vždy rychlejší než index bez klastrů. Také nesouhlasím s tím, že je vždy nadbytečné vytvářet neshlukovaný index nebo jedinečné omezení sestávající ze stejných (nebo některých stejných) sloupců v klíči shlukování.
Nesouhlasím však s tím, že seskupený index je vždy rychlejší než index bez klastrů. Také nesouhlasím s tím, že je vždy nadbytečné vytvářet neshlukovaný index nebo jedinečné omezení sestávající ze stejných (nebo některých stejných) sloupců v klíči shlukování.
Vezměme si tento příklad, Warehouse.StockItemTransactions , od WideWorldImporters. Clusterový index je implementován prostřednictvím primárního klíče pouze na StockItemTransactionID sloupec (docela typické, když máte nějaké náhradní ID generované IDENTITOU nebo SEKVENCÍ).
Je docela běžnou věcí vyžadovat sčítání celé tabulky (ačkoli v mnoha případech existují lepší způsoby). To může být pro příležitostnou kontrolu nebo jako součást procedury stránkování. Většina lidí to udělá takto:
SELECT COUNT(*) FROM Warehouse.StockItemTransactions;
S aktuálním schématem to bude používat index bez klastrů:
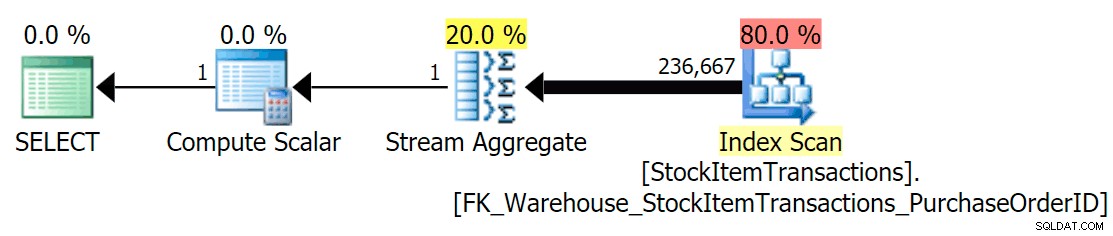
Víme, že neklastrovaný index neobsahuje všechny sloupce v seskupeném indexu. Operace počítání se pouze musí ujistit, že jsou zahrnuty všechny řádky, aniž by se staralo o to, které sloupce jsou přítomny, takže SQL Server obvykle vybere index s nejmenším počtem stránek (v tomto případě má zvolený index ~414 stránek).
Nyní spusťte dotaz znovu, tentokrát jej porovnáme s naznačeným dotazem, který vynutí použití seskupeného indexu.
SELECT COUNT(*) FROM Warehouse.StockItemTransactions; SELECT COUNT(*) /* with hint */ FROM Warehouse.StockItemTransactions WITH (INDEX(1));
Získáme téměř identický tvar plánu, ale můžeme vidět obrovský rozdíl ve čteních (414 pro zvolený index vs. 1 982 pro seskupený index):
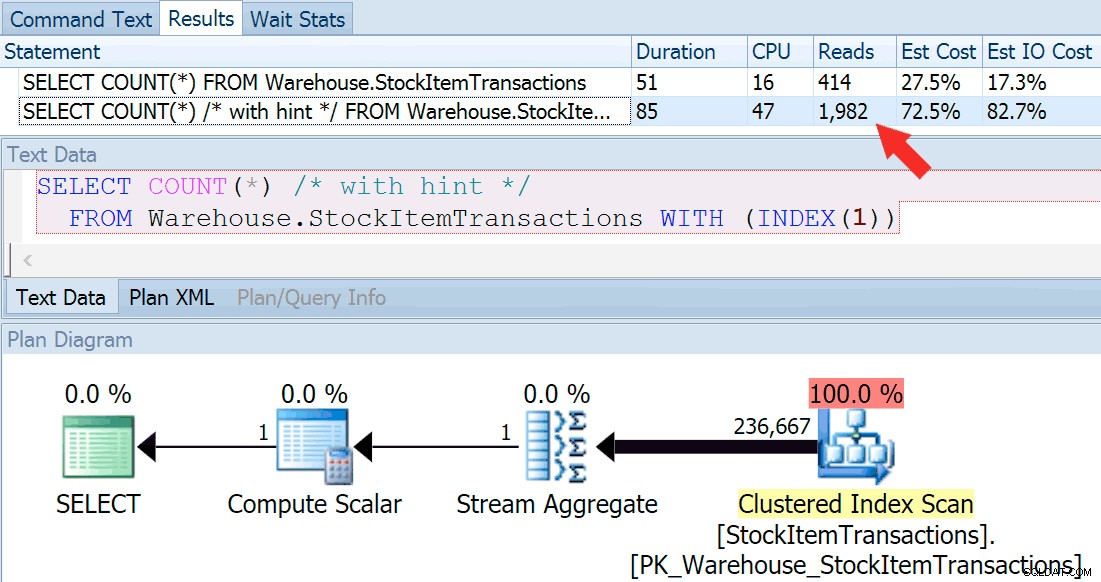
Trvání je o něco vyšší u seskupeného indexu, ale rozdíl je zanedbatelný, když máme co do činění s malým množstvím dat uložených v mezipaměti na rychlém disku. Tento rozdíl by byl mnohem výraznější s větším množstvím dat, na pomalém disku nebo na systému s tlakem paměti.
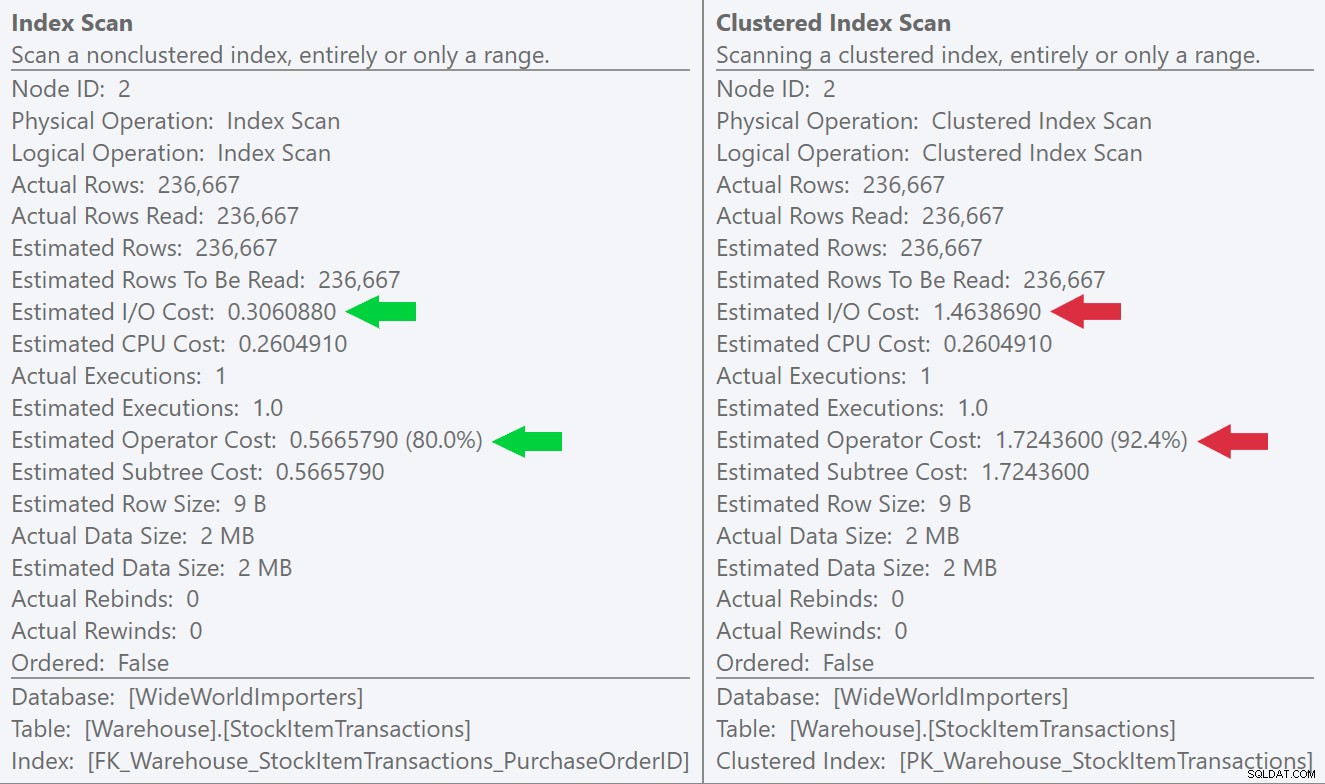
Pokud se podíváme na popisky pro operace skenování, můžeme vidět, že zatímco počet řádků a odhadované náklady na CPU jsou identické, velký rozdíl pochází z odhadovaných I/O nákladů (protože SQL Server ví, že v seskupený index než index bez seskupení):
Tento rozdíl můžeme vidět ještě jasněji, pokud vytvoříme nový, jedinečný index pouze ve sloupci ID (což se stane „nadbytečným“ se seskupeným indexem, že?):
CREATE UNIQUE INDEX NewUniqueNCIIndex ON Warehouse.StockItemTransactions(StockItemTransactionID);
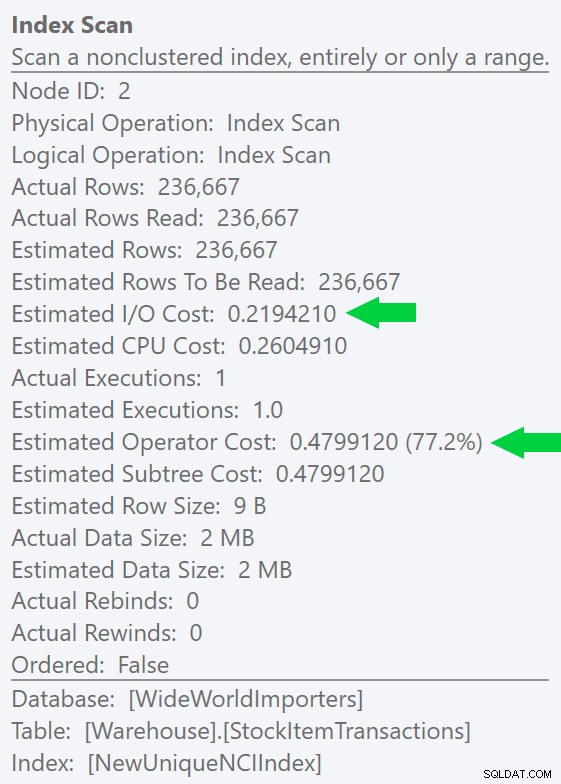 Spuštění podobného dotazu s explicitní nápovědou indexu vytvoří stejný tvar plánu, ale ještě nižší odhadovaný I/O náklady (a ještě kratší doby trvání) – viz obrázek vpravo. A pokud spustíte původní dotaz bez nápovědy, uvidíte, že SQL Server nyní také volí tento index.
Spuštění podobného dotazu s explicitní nápovědou indexu vytvoří stejný tvar plánu, ale ještě nižší odhadovaný I/O náklady (a ještě kratší doby trvání) – viz obrázek vpravo. A pokud spustíte původní dotaz bez nápovědy, uvidíte, že SQL Server nyní také volí tento index.
Může se to zdát samozřejmé, ale mnoho lidí by věřilo, že klastrovaný index je zde nejlepší volbou. SQL Server bude téměř vždy silně upřednostňovat jakoukoli metodu, která poskytne nejlevnější způsob, jak provést všechny I/O, a v případě úplného skenování to bude „nejhubenější“ index. To se také může stát u obou typů vyhledávání (jednotlivé a rozsahové skenování), alespoň když index pokrývá.
Nyní, jako vždy, to není v žádném případě to znamená, že byste měli jít a vytvořit další indexy na všech vašich tabulkách, abyste uspokojili početní dotazy. Nejen, že je to neefektivní způsob kontroly velikosti tabulky (opět viz tento článek), ale index, který by měl být podporován, by musel znamenat, že tento dotaz spouštíte častěji, než aktualizujete data. Pamatujte, že každý index vyžaduje místo na disku, místo v paměti a všechny zápisy do tabulky se také musí dotýkat každého indexu (filtrované indexy stranou).
Shrnutí
Mohl bych přijít s mnoha dalšími příklady, které ukazují, kdy může být neshlukovaný index užitečný a stojí za náklady na údržbu, i když duplikujete klíčové sloupce seskupeného indexu. Neklastrované indexy lze vytvořit se stejnými klíčovými sloupci, ale v jiném pořadí klíčů, nebo s různými ASC/DESC na samotných sloupcích, aby bylo možné lépe podporovat alternativní pořadí prezentace. Můžete také mít indexy bez klastrů, které obsahují pouze malou podmnožinu řádků pomocí filtru. A konečně, pokud dokážete uspokojit své nejběžnější dotazy pomocí tenčích, neseskupených indexů, je to také lepší pro spotřebu paměti.
Ale ve skutečnosti, mým cílem této série je pouze ukázat protipříklad, který ilustruje pošetilost dělat paušální prohlášení, jako je toto. Nechám vám vysvětlení od Paula Whitea, který v odpovědi DBA.SE vysvětluje, proč takový neseskupený index může ve skutečnosti fungovat mnohem lépe než seskupený index. To platí i v případě, že oba používají oba typy hledání:
- Rozdíl mezi hledáním seskupeného indexu a hledáním indexu bez seskupení