SQL Server nám poskytuje řadu funkcí okna, které nám pomáhají provádět výpočty napříč sadou řádků, aniž bychom museli opakovat volání databáze. Na rozdíl od standardních agregačních funkcí nebudou funkce okna seskupovat řádky do jednoho výstupního řádku, budou vracet jednu agregovanou hodnotu pro každý řádek, přičemž pro tyto řádky budou zachovány samostatné identity. Termín okno zde nesouvisí s operačním systémem Microsoft Windows, popisuje sadu řádků, které funkce zpracuje.
Jedním z nejužitečnějších typů okenních funkcí jsou Ranking Window Functions, které se používají k hodnocení konkrétních hodnot polí a jejich kategorizaci podle hodnocení každého řádku, což vede k jedné agregované hodnotě pro každý zúčastněný řádek. SQL Server podporuje čtyři funkce okna hodnocení; ROW_NUMBER(), RANK(), DENSE_RANK() a NTILE(). Všechny tyto funkce se používají k výpočtu ROWID pro poskytnuté okno řádků svým vlastním způsobem.
Čtyři funkce hodnotícího okna používají klauzuli OVER(), která definuje uživatelem specifikovanou sadu řádků v sadě výsledků dotazu. Definováním klauzule OVER() můžete také zahrnout klauzuli PARTITION BY, která určuje sadu řádků, které bude funkce okna zpracovávat, poskytnutím sloupců nebo sloupců oddělených čárkami pro definování oddílu. Kromě toho lze zahrnout klauzuli ORDER BY, která definuje kritéria řazení v rámci oddílů, kterými funkce projde řádky při zpracování.
V tomto článku probereme, jak prakticky používat čtyři funkce hodnotícího okna:ROW_NUMBER(), RANK(), DENSE_RANK() a NTILE() a rozdíl mezi nimi.
Abychom mohli sloužit našemu demu, vytvoříme novou jednoduchou tabulku a vložíme do ní několik záznamů pomocí skriptu T-SQL níže:
CREATE TABLE StudentScore
(
Student_ID INT PRIMARY KEY,
Student_Name NVARCHAR (50),
Student_Score INT
)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978)
INSERT INTO StudentScore VALUES (2,'Zaid', 770)
INSERT INTO StudentScore VALUES (3,'Mohd', 1140)
INSERT INTO StudentScore VALUES (4,'Jack', 770)
INSERT INTO StudentScore VALUES (5,'John', 1240)
INSERT INTO StudentScore VALUES (6,'Mike', 1140)
INSERT INTO StudentScore VALUES (7,'Goerge', 885)
Úspěšné vložení dat můžete zkontrolovat pomocí následujícího příkazu SELECT:
SELECT * FROM StudentScore ORDER BY Student_ScoreS použitým seřazeným výsledkem je výsledná sada následující:

ROW_NUMBER()
Funkce hodnotícího okna ROW_NUMBER() vrací jedinečné pořadové číslo pro každý řádek v oddílu zadaného okna, počínaje 1 pro první řádek v každém oddílu a bez opakování nebo přeskakování čísel ve výsledku hodnocení každého oddílu. Pokud jsou v sadě řádků duplicitní hodnoty, budou pořadová ID čísla přiřazena libovolně. Je-li zadána klauzule PARTITION BY, bude číslo řádku pořadí vynulováno pro každou logickou část. V dříve vytvořené tabulce níže uvedený dotaz ukazuje, jak použít funkci okna hodnocení ROW_NUMBER k seřazení řádků tabulky StudentScore podle skóre každého studenta:
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Z níže uvedené sady výsledků je zřejmé, že funkce okna ROW_NUMBER řadí řádky tabulky podle hodnot sloupce Student_Score pro každý řádek tím, že generuje jedinečné číslo každého řádku, které odráží jeho hodnocení Student_Score počínaje číslem 1 bez duplikátů nebo mezer a zabývající se všemi řádky jako jedním oddílem. Můžete také vidět, že duplicitní skóre jsou přiřazena k různým úrovním náhodně:
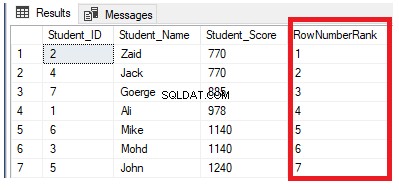
Pokud upravíme předchozí dotaz zahrnutím klauzule PARTITION BY tak, aby měla více než jeden oddíl, jak je znázorněno v dotazu T-SQL níže:
SELECT *, ROW_NUMBER() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Výsledek ukáže, že funkce okna ROW_NUMBER seřadí řádky tabulky podle hodnot sloupce Student_Score pro každý řádek, ale bude se zabývat řádky, které mají stejnou hodnotu Student_Score jako jeden oddíl. Uvidíte, že pro každý řádek bude vygenerováno jedinečné číslo odrážející jeho hodnocení Student_Score, počínaje číslem 1 bez duplikátů nebo mezer ve stejném oddílu, čímž se číslo pořadí resetuje při přechodu na jinou hodnotu Student_Score.
Například studenti se skóre 770 budou zařazeni do tohoto skóre tak, že jim bude přiděleno číslo pořadí. Když se však přesune na studenta se skóre 885, počáteční číslo hodnosti se resetuje tak, aby začínalo znovu od 1, jak je uvedeno níže:
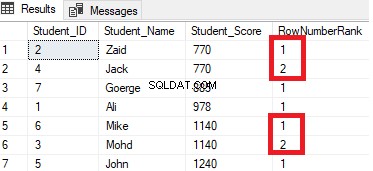
RANK()
Funkce hodnotícího okna RANK() vrací jedinečné číslo pořadí pro každý odlišný řádek v oddílu podle zadané hodnoty sloupce, počínaje 1 pro první řádek v každém oddílu, se stejným hodnocením pro duplicitní hodnoty a ponechává mezery mezi pořadími.; tato mezera se objeví v sekvenci za duplicitními hodnotami. Jinými slovy, funkce okna hodnocení RANK() se chová jako funkce ROW_NUMBER() s výjimkou řádků se stejnými hodnotami, kde se seřadí se stejným ID pořadí a vygeneruje za ním mezeru. Pokud upravíme předchozí dotaz na hodnocení tak, aby používal funkci hodnocení RANK():
SELECT *, RANK () OVER( ORDER BY Student_Score) AS RankRank
FROM StudentScoreZ výsledku uvidíte, že funkce okna RANK seřadí řádky tabulky podle hodnot sloupce Student_Score pro každý řádek, přičemž hodnota pořadí odráží jeho Student_Score počínaje číslem 1 a seřadí řádky, které mají stejné skóre Student_Score s hodnotou stejnou hodnotu pořadí. Můžete také vidět, že dva řádky, které mají Student_Score rovné 770, jsou ohodnoceny stejnou hodnotou, takže za druhým řádkem zůstává mezera, což je chybějící číslo 2. Totéž se stane s řádky, kde se Student_Score rovná 1140, které jsou seřazeny se stejnou hodnotou, přičemž za druhým řádkem zůstane mezera, což je chybějící číslo 6, jak je znázorněno níže:
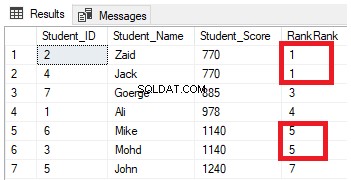
Úprava předchozího dotazu zahrnutím klauzule PARTITION BY tak, aby měla více než jeden oddíl, jak je znázorněno v dotazu T-SQL níže:
SELECT *, RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreVýsledek hodnocení nebude mít žádný význam, protože hodnocení bude provedeno podle hodnot Student_Score pro každý oddíl a data budou rozdělena podle hodnot Student_Score. A vzhledem k tomu, že každý oddíl bude mít řádky se stejnými hodnotami Student_Score, budou řádky se stejnými hodnotami Student_Score ve stejném oddílu zařazeny s hodnotou rovnou 1. Při přesunu do druhého oddílu se tedy pořadí být resetován, počínaje opět číslem 1, přičemž všechny hodnoty hodnocení se rovnají 1, jak je uvedeno níže:
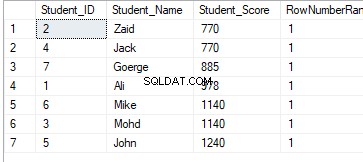
DENSE_RANK()
Funkce okna hodnocení DENSE_RANK() je podobná funkci RANK() tím, že generuje jedinečné číslo pořadí pro každý odlišný řádek v rámci oddílu podle zadané hodnoty sloupce, počínaje 1 pro první řádek v každém oddílu a řadí řádky podle stejné hodnoty se stejným hodnostním číslem, kromě toho, že nepřeskočí žádnou hodnost, takže mezi hodnostmi nejsou žádné mezery.
Pokud přepíšeme předchozí dotaz na hodnocení tak, aby používal funkci hodnocení DENSE_RANK():
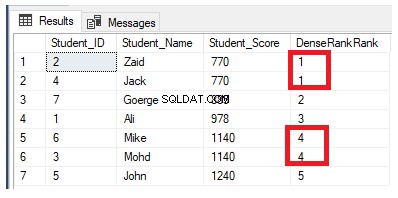
Znovu upravte předchozí dotaz přidáním klauzule PARTITION BY, aby měl více než jeden oddíl, jak je znázorněno v dotazu T-SQL níže:
SELECT *, DENSE_RANK() OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
Hodnoty pořadí nebudou mít žádný význam, kde všechny řádky budou seřazeny s hodnotou 1, kvůli přiřazení duplicitních hodnot ke stejné hodnotě pořadí a resetování počátečního ID pořadí při zpracování nového oddílu, jak je uvedeno níže:
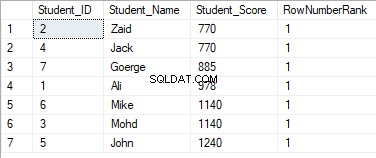
NTILE(N)
Funkce okna hodnocení NTILE(N) se používá k rozdělení řádků v sadě řádků do zadaného počtu skupin, přičemž každému řádku v sadě řádků poskytuje jedinečné číslo skupiny, počínaje číslem 1, které ukazuje skupinu, do které tento řádek patří. to, kde N je kladné číslo, které definuje počet skupin, do kterých potřebujete rozdělit sady řádků.
Jinými slovy, pokud potřebujete rozdělit konkrétní datové řádky tabulky do 3 skupin na základě hodnot konkrétních sloupců, funkce okna hodnocení NTILE(3) vám pomůže toho snadno dosáhnout.
Počet řádků v každé skupině lze vypočítat rozdělením počtu řádků do požadovaného počtu skupin. Pokud upravíme předchozí hodnotící dotaz tak, aby používal funkci okna hodnocení NTILE(4) k seřazení sedmi řádků tabulky do čtyř skupin jako dotaz T-SQL níže:
SELECT *, NTILE(4) OVER( ORDER BY Student_Score) AS NTILERank
FROM StudentScore
Počet řádků by měl být (7/4=1,75) řádků v každé skupině. Pomocí funkce NTILE() SQL Server Engine přiřadí 2 řádky prvním třem skupinám a jeden řádek poslední skupině, aby byly všechny řádky zahrnuty do skupin, jak je znázorněno v sadě výsledků níže:
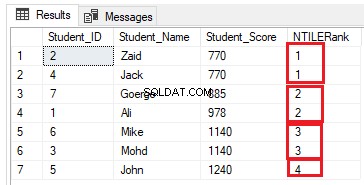
Úprava předchozího dotazu zahrnutím klauzule PARTITION BY tak, aby měla více než jeden oddíl, jak je znázorněno v dotazu T-SQL níže:
SELECT *, NTILE(4) OVER(PARTITION BY Student_Score ORDER BY Student_Score) AS RowNumberRank
FROM StudentScoreŘádky budou rozděleny do čtyř skupin na každém oddílu. Například první dva řádky se Student_Score rovným 770 budou ve stejném oddílu a budou rozděleny do skupin, které každou z nich ohodnotí jedinečným číslem, jak je znázorněno v sadě výsledků níže:
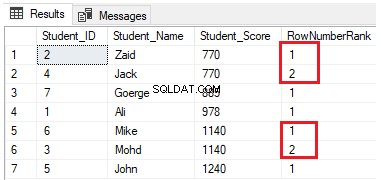
Spojení všech dohromady
Abychom měli jasnější srovnávací scénář, zkrátíme předchozí tabulku, přidáme další klasifikační kritérium, kterým je třída studentů, a nakonec vložíme nových sedm řádků pomocí skriptu T-SQL níže:
TRUNCATE TABLE StudentScore
GO
ALTER TABLE StudentScore ADD CLASS CHAR(1)
GO
INSERT INTO StudentScore VALUES (1,'Ali', 978,'A')
INSERT INTO StudentScore VALUES (2,'Zaid', 770,'B')
INSERT INTO StudentScore VALUES (3,'Mohd', 1140,'A')
INSERT INTO StudentScore VALUES (4,'Jack', 879,'B')
INSERT INTO StudentScore VALUES (5,'John', 1240,'C')
INSERT INTO StudentScore VALUES (6,'Mike', 1100,'B')
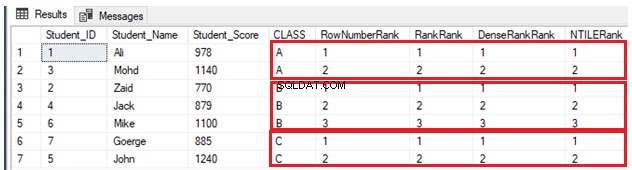
INSERT INTO StudentScore VALUES (7,'Goerge', 885,'C')Poté seřadíme sedm řádků podle skóre každého studenta a rozdělíme studenty podle jejich třídy. Jinými slovy, každý oddíl bude obsahovat jednu třídu a každá třída studentů bude hodnocena podle jejich skóre ve stejné třídě pomocí čtyř dříve popsaných funkcí okna hodnocení, jak je znázorněno ve skriptu T-SQL níže:
SELECT *, ROW_NUMBER() OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RowNumberRank,
RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS RankRank,
DENSE_RANK () OVER(PARTITION BY CLASS ORDER BY Student_Score) AS DenseRankRank,
NTILE(7) OVER(PARTITION BY CLASS ORDER BY Student_Score) AS NTILERank
FROM StudentScore
GOVzhledem k tomu, že neexistují žádné duplicitní hodnoty, čtyři funkce hodnotícího okna budou fungovat stejným způsobem a vrátí stejný výsledek, jak je znázorněno v sadě výsledků níže:
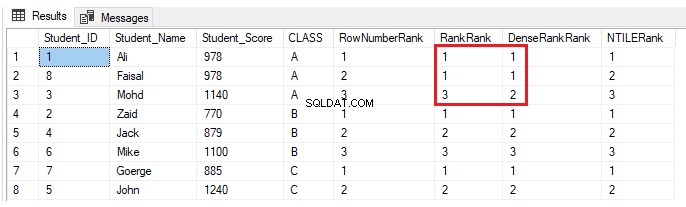
Pokud je ve třídě A zařazen další student se skóre, které již má jiný student ve stejné třídě, použijte níže uvedený příkaz INSERT:
INSERT INTO StudentScore VALUES (8,'Faisal', 978,'A')Pro funkce okna hodnocení ROW_NUMBER() a NTILE() se nic nezmění. Funkce RANK a DENSE_RANK() přiřadí studentům se stejným skóre stejnou hodnost, s mezerou v hodnostech za duplicitními hodnostmi při použití funkce RANK a žádnou mezerou v hodnostech po duplicitních hodnostech při použití DENSE_RANK( ), jak ukazuje výsledek níže:
Praktický scénář
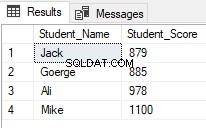
Funkce hodnocení okna jsou široce používány vývojáři SQL Server. Jeden z běžných scénářů pro použití hodnotících funkcí, když chcete načíst konkrétní řádky a přeskočit ostatní, pomocí funkce okna hodnocení ROW_NUMBER(,) v rámci CTE, jako ve skriptu T-SQL níže, který vrací studenty s hodnocením mezi 2 a 5 a přeskočte ostatní:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
WHERE RowNumberRank >= 2 and RowNumberRank <=5
ORDER BY RowNumberRank
Výsledek ukáže, že budou vráceni pouze studenti s pozicemi mezi 2 a 5:
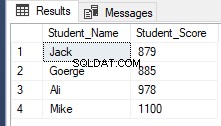
Počínaje SQL Server 2012, nový užitečný příkaz, OFFSET FETCH byl představen, který lze použít k provedení stejného předchozího úkolu načtením konkrétních záznamů a přeskočením ostatních pomocí skriptu T-SQL níže:
WITH ClassRanks AS
(
SELECT *, ROW_NUMBER() OVER( ORDER BY Student_Score) AS RowNumberRank
FROM StudentScore
)
SELECT Student_Name , Student_Score
FROM ClassRanks
ORDER BY
RowNumberRank OFFSET 1 ROWS FETCH NEXT 4 ROWS ONLY;Načítání stejného předchozího výsledku, jak je znázorněno níže:
Závěr
SQL Server nám poskytuje čtyři funkce hodnotícího okna, které nám pomáhají seřadit poskytnuté řádky podle konkrétních hodnot sloupců. Tyto funkce jsou:ROW_NUMBER(), RANK(), DENSE_RANK() a NTILE(). Všechny tyto funkce hodnocení provádějí úkol hodnocení svým vlastním způsobem a vracejí stejný výsledek, pokud v řádcích nejsou žádné duplicitní hodnoty. Pokud je v sadě řádků duplicitní hodnota, funkce RANK přiřadí stejné ID hodnocení pro všechny řádky se stejnou hodnotou, přičemž po duplikátech ponechá mezery mezi hodnoceními. Funkce DENSE_RANK také přiřadí stejné ID hodnocení pro všechny řádky se stejnou hodnotou, ale po duplikátech nezanechá žádnou mezeru mezi hodnoceními. V tomto článku projdeme různé scénáře, abychom pokryli všechny možné případy, které vám pomohou prakticky porozumět funkcím okna hodnocení.
Odkazy:
- ROW_NUMBER (Transact-SQL)
- RANK (Transact-SQL)
- DENSE_RANK (Transact-SQL)
- NTILE (Transact-SQL)
- Klauzule OFFSET FETCH (SQL Server Compact)