V tomto článku budeme diskutovat o typických chybách, se kterými se mohou nováčci setkat při navrhování kódu T-SQL. Kromě toho se podíváme na osvědčené postupy a několik užitečných tipů, které vám mohou pomoci při práci se serverem SQL Server, a také na řešení pro zlepšení výkonu.
Obsah:
1. Typy dat
2. *
3. Přezdívka
4. Pořadí sloupců
5. NOT IN vs NULL
6. Formát data
7. Filtr data
8. Сkalkulace
9. Převést implicitní
10. LIKE &Suppressed index
11. Unicode vs ANSI
12. KOMPLETOVAT
13. BINARY COLLATE
14. Styl kódu
15. [var]char
16. Délka dat
17. ISNULL vs COALESCE
18. Matematika
19. UNION vs UNION ALL
20. Znovu si přečtěte
21. Dílčí dotaz
22. PŘÍPAD KDY
23. Skalární funkce
24. ZOBRAZENÍ
25. KURZORY
26. STRING_CONCAT
27. SQL Injection
Typy dat
Hlavním problémem, kterému při práci se serverem SQL čelíme, je nesprávná volba datových typů.
Předpokládejme, že máme dvě identické tabulky:
DECLARE @Employees1 TABLE (ZaměstnanecID VELKÝ PRIMÁRNÍ KLÍČ , IsMuž VARCHAR(3) , Datum narození VARCHAR(20))INSERT INTO @Employees1VALUES (123, 'ANO', '2012-DETACLARE-01.01.Zaměstnanec)ID INT PRIMÁRNÍ KLÍČ , IsMale BIT , Datum narození DATE) INSERT INTO @Employees2VALUES (123, 1, '2012-09-01')
Proveďme dotaz, abychom zjistili, jaký je rozdíl:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FROM @Employees2 WHERE BirthDate =@BirthDate
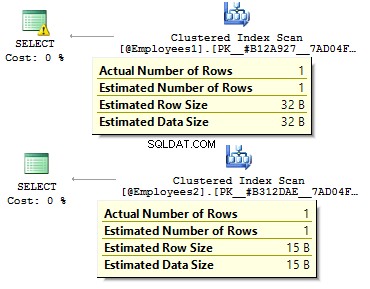
V prvním případě jsou datové typy více redundantní, než by mohly být. Proč bychom měli ukládat bitovou hodnotu jako ANO/NE řádek? Proč bychom měli ukládat datum jako řádek? Proč bychom měli používat BIGINT pro zaměstnance v tabulce, nikoli INT ?
Vede to k následujícím nevýhodám:
- Tabulky mohou zabírat mnoho místa na disku;
- Potřebujeme přečíst více stránek a vložit více dat do BufferPool pro zpracování dat.
- Špatný výkon.
*
Setkal jsem se se situací, kdy vývojáři získávají všechna data z tabulky a poté na straně klienta používají DataReader pro výběr pouze požadovaných polí. Nedoporučuji používat tento přístup:
POUŽÍVEJTE ČAS Statistiky AdventureWorks2014GOSET STATISTICS, IO ONSELECT *FROM Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , LastNameFROM Person.PersonSET STATISTICS TIME, IO OFF
Významný rozdíl bude v době provádění dotazu. Kromě toho může krycí index snížit počet logických čtení.
Tabulka 'Osoba'. Počet skenování 1, logická čtení 3819, fyzická čtení 3, ... Doby provádění SQL serveru:Čas CPU =31 ms, uplynulý čas =1235 ms. Tabulka 'Osoba'. Počet skenování 1, logické čtení 109, fyzické čtení 1, ... Časy spuštění serveru SQL Server:Čas CPU =0 ms, uplynulý čas =227 ms.
Alias
Vytvoříme tabulku:
POUŽÍVEJTE AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') IS NOT NULL DROP TABLE Sales.UserCurrencyGCREATE TABLE Sales.UserCurrency (Kód měny NCHAR(3) PRIMÁRNÍ KLÍČ)'INSERT INTORRency Sales.UserCurdu
Předpokládejme, že máme dotaz, který vrací počet identických řádků v obou tabulkách:
SELECT COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN ( SELECT CurrencyCode FROM Sales.UserCurrency )
Vše bude fungovat podle očekávání, dokud někdo nepřejmenuje sloupec v Sales.UserCurrency tabulka:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Kód', 'COLUMN'
Dále provedeme dotaz a uvidíme, že dostaneme všechny řádky v Sales.Currency tabulky místo 1 řádku. Při vytváření prováděcího plánu ve fázi vazby SQL Server zkontroluje sloupce Sales.UserCurrency, nenalezne Kód měny tam a rozhodne, že tento sloupec patří do Sales.Currency stůl. Poté optimalizátor vypustí CurrencyCode =CurrencyCode podmínka.
Proto doporučuji používat aliasy:
SELECT COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN ( SELECT u.CurrencyCode FROM Sales.UserCurrency u )
Pořadí sloupců
Předpokládejme, že máme tabulku:
IF OBJECT_ID('dbo.DatePeriod') NENÍ NULL DROP TABLE dbo.DatePeriodGOCREATE TABLE dbo.DatePeriod ( StartDate DATE , EndDate DATE)
Data tam vkládáme vždy na základě informace o pořadí sloupců.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Předpokládejme, že někdo změní pořadí sloupců:
CREATE TABLE dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Data budou vložena v jiném pořadí. V tomto případě je vhodné explicitně specifikovat sloupce v příkazu INSERT:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Zde je další příklad:
SELECT TOP(1) *FROM dbo.DatePeriodORDER BY 2 DESC
Ve kterém sloupci budeme objednávat data? To bude záviset na pořadí sloupců v tabulce. V případě, že někdo změní pořadí, dostaneme špatné výsledky.
NOT IN vs. NULL
Pojďme si promluvit o NOT IN prohlášení.
Například musíte napsat pár dotazů:vrátit záznamy z první tabulky, které neexistují ve druhé tabulce a viz verš. Obvykle mladší vývojáři používají IN a NENÍ V :
DECLARE @t1 TABLE (t1 INT, UNIQUE CLUSTERED(t1))INSERT INTO @t1 VALUES (1), (2)DECLARE @t2 TABLE (t2 INT, UNIQUE CLUSTERED(t2))INSERT INTO @t2 VALUES (1 )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
První dotaz vrátil 2, druhý 1. Dále do druhé tabulky přidáme další hodnotu – NULL :
INSERT INTO @t2 VALUES (1), (NULL)
Při provádění dotazu s NOT IN , nezískáme žádné výsledky. Proč IN funguje a NE IN ne? Důvodem je, že SQL Server používá TRUE , NEPRAVDA a NEZNÁMÝ logiku při porovnávání dat.
Při provádění dotazu SQL Server interpretuje podmínku IN následujícím způsobem:
a IN (1, NULL) ==a=1 NEBO a=NULL
NENÍ V :
a NOT IN (1, NULL) ==a<>1 AND a<>NULL
Při porovnávání jakékoli hodnoty s NULL, SQL Server vrátí NEZNÁMÝ. Buď 1=NULL nebo NULL=NULL – oba mají za následek NEZNÁMÝ. Pokud máme ve výrazu AND, obě strany vrátí NEZNÁMÝ.
Upozorňuji, že tento případ není ojedinělý. Například označíte sloupec jako NOT NULL. Po chvíli se jiný vývojář rozhodne povolit hodnoty NULL pro ten sloupec. To může vést k situaci, kdy po vložení jakékoli hodnoty NULL do tabulky přestane sestava klienta fungovat.
V tomto případě bych doporučil vyloučit hodnoty NULL:
SELECT *FROM @t1WHERE t1 NOT IN ( SELECT t2 FROM @t2 WHERE t2 NOT NULL )
Kromě toho je možné použít EXCEPT :
SELECT * FROM @t1EXCEPTSELECT * FROM @t2
Případně můžete použít NOT EXISTS :
SELECT *FROM @t1WHERE NOT EXISTS( SELECT 1 FROM @t2 WHERE t1 =t2 )
Která možnost je výhodnější? Druhá možnost s NEEXISTUJE se zdá být nejproduktivnější, protože generuje optimálnější predikátový zásobník operátor pro přístup k datům z druhé tabulky.
Ve skutečnosti mohou hodnoty NULL vrátit neočekávaný výsledek.
Zvažte to na tomto konkrétním příkladu:
POUŽÍVEJTE AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color ='Grey'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color <> 'Grey'
Jak vidíte, nedosáhli jste očekávaného výsledku z důvodu, že hodnoty NULL mají samostatné operátory porovnání:
SELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Zde je další příklad s CHECK omezení:
IF OBJECT_ID('tempdb.dbo.#temp') NENÍ NULL DROP TABLE #tempGOCREATE TABLE #temp ( Barva VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Barva V ('Černá', 'Bílá')) ))
Vytvoříme tabulku s oprávněním vkládat pouze bílou a černou barvu:
INSERT INTO #temp VALUES ('Black') (ovlivněný 1 řádek)
Vše funguje podle očekávání.
INSERT INTO #temp VALUES ('Červená')Příkaz INSERT byl v konfliktu s podmínkou CHECK...Příkaz byl ukončen.
Nyní přidáme NULL:
INSERT INTO #temp VALUES (NULL) (ovlivněn 1 řádek)
Proč omezení CHECK prošlo hodnotou NULL? Důvodem je, že NOT FALSE je dost podmínkou k pořízení záznamu. Řešením je explicitně definovat sloupec jako NOT NULL nebo použijte v omezení hodnotu NULL.
Formát data
Velmi často můžete mít potíže s datovými typy.
Například potřebujete získat aktuální datum. K tomu můžete použít funkci GETDATE:
SELECT GETDATE()
Poté stačí zkopírovat vrácený výsledek v požadovaném dotazu a smazat čas:
SELECT *FROM sys.objectsWHERE create_date <'2016-11-14'
Je to správně?
Datum je určeno řetězcovou konstantou:
SET LANGUAGE EnglishSET DATEFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Všechny hodnoty mají jednohodnotovou interpretaci:
----------- ----------- ----------- -----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Nezpůsobí žádné problémy, dokud nebude dotaz s touto obchodní logikou proveden na jiném serveru, kde se nastavení mohou lišit:
SET DATEFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec -2016'SELECT @d1, @d2, @d3, @d4
Tyto možnosti však mohou vést k nesprávné interpretaci data:
----------- ----------- ----------- -----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Kromě toho může tento kód vést k viditelné i skryté chybě.
Zvažte následující příklad. Potřebujeme vložit data do testovací tabulky. Na testovacím serveru vše funguje perfektně:
DECLARE @t TABLE (a DATETIME)INSERT INTO @t VALUES ('05/13/2016')
Na straně klienta však bude mít tento dotaz problémy, protože nastavení našeho serveru se liší:
DECLARE @t TABLE (a DATETIME)SET DATEFORMAT DMYINSERT INTO @t VALUES ('05/13/2016') Zpráva 242, úroveň 16, stav 3, řádek 28Konverze datového typu varchar na datový typ datetime vedla k hodnotě mimo rozsah.
Jaký formát bychom tedy měli použít k deklaraci datových konstant? Chcete-li odpovědět na tuto otázku, spusťte tento dotaz:
SET DATEFORMAT YMDSET LANGUAGE EnglishDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='121601 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112' VYBERTE @d1, @d2, @d3, @d4
Interpretace konstant se může lišit v závislosti na nainstalovaném jazyce:
----------- ----------- ----------- -----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ----------- ----------- ------------ -----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Proto je lepší použít poslední dvě možnosti. Také bych rád dodal, že explicitně specifikovat datum není dobrý nápad:
NASTAVIT JAZYK FrenchDECLARE @d DATETIME ='12-jan-2016'Msg 241, Level 16, State 1, Line 29 Échec de la conversion de la date et/ou de l'heure à partir d'une chaîne de caractères.
Pokud tedy chcete, aby byly konstanty s daty interpretovány správně, musíte je zadat v následujícím formátu RRRRMMDD.
Kromě toho bych vás rád upozornil na chování některých datových typů:
SET LANGUAGE EnglishSET DATEFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-01 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
Na rozdíl od DATETIME, DATE typ je správně interpretován s různými nastaveními na serveru:
---------- ----------2016-01-12 2016-01-12---------- ------- ---2016-01-12 2016-12-01
Filtr data
Abychom se posunuli dále, zvážíme, jak efektivně filtrovat data. Začněme od nich DATETIME/DATE:
POUŽÍVEJTE AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Nyní se pokusíme zjistit, kolik řádků dotaz vrátí za určený den:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime ='20140716'
Dotaz vrátí 0. Při sestavování prováděcího plánu se SQL server pokouší přetypovat řetězcovou konstantu do datového typu sloupce, který potřebujeme odfiltrovat:
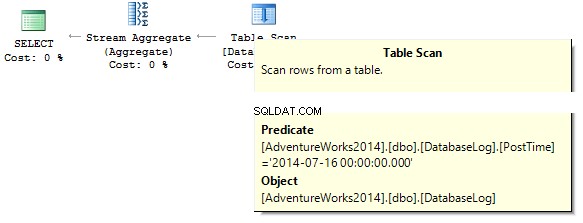
Vytvořte index:
VYTVOŘTE NEZAHRNUTÝ INDEX IX_PostTime NA dbo.DatabaseLog (PostTime)
Existují správné a nesprávné možnosti výstupu dat. Například musíte odstranit sloupec času:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='16'20140
Nebo musíme zadat rozsah:
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime BETWEEN '20140716' AND '20140716 23:59:59.997'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE27 PostTime>'01'07 PostTime>
S ohledem na optimalizaci mohu říci, že tyto dva dotazy jsou nejsprávnější. Jde o to, že všechny konverze a výpočty indexových sloupců, které jsou odfiltrovány, mohou drasticky snížit výkon a prodloužit dobu logických čtení:
Tabulka 'DatabaseLog'. Počet skenů 1, logické čtení 7, ...Tabulka 'DatabaseLog'. Počet skenů 1, logické čtení 2, ...
Čas odeslání pole nebylo dříve zahrnuto do indexu a při použití tohoto správného přístupu při filtrování jsme neviděli žádnou efektivitu. Další věc je, když potřebujeme vydat data za měsíc:
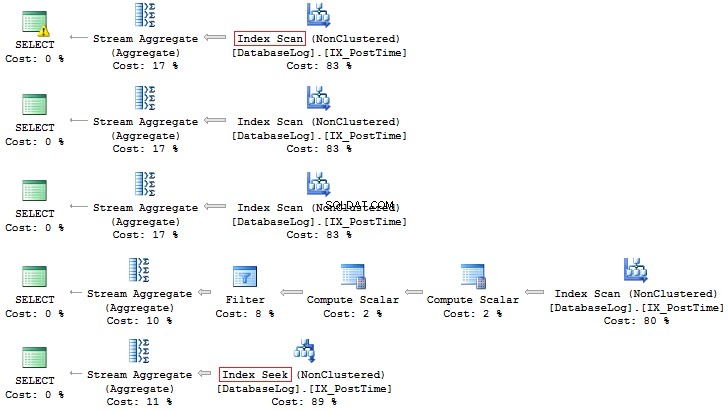
SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =2014 (MONTH AND DATE PART) PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='201407FBIROMBaseLoLo PostTime>='20140701' A PostTime <'20140801'
Opět platí, že druhá možnost je vhodnější:
Kromě toho můžete vždy vytvořit index na základě vypočítaného pole:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ONthLastDay PŘIDAT MĚSÍCPosledníDen JAKO POSTSIS PERSONAL GOTHREAD.
Ve srovnání s předchozím dotazem může být rozdíl v logických čteních významný (pokud se jedná o velké tabulky):
SET STATISTICS IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' AND PostTime <'20140801'SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE Month'FTISTICS17DIA'SET =Log. Počet skenů 1, logické čtení 7, ...Tabulka 'DatabaseLog'. Počet skenů 1, logické čtení 3, ...
Výpočet
Jak již bylo diskutováno, jakékoli výpočty ve sloupcích indexu snižují výkon a zvyšují dobu čtení logiky:
POUŽÍVEJTE AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000 SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROM'Person.EntableWHERE000 Počet skenů 1, logické čtení 67, ...Tabulka 'Osoba'. Počet skenů 0, logické čtení 3, ...
Pokud se podíváme na prováděcí plány, pak v prvním z nich SQL Server spustí IndexScan :
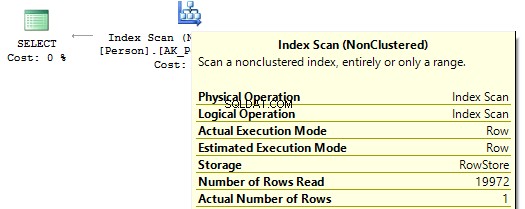
Když pak ve sloupcích indexu nejsou žádné výpočty, uvidíme IndexSeek :

Převést implicitní
Pojďme se podívat na tyto dva dotazy, které filtrují podle stejné hodnoty:
POUŽÍVEJTE AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Prováděcí plány poskytují následující informace:
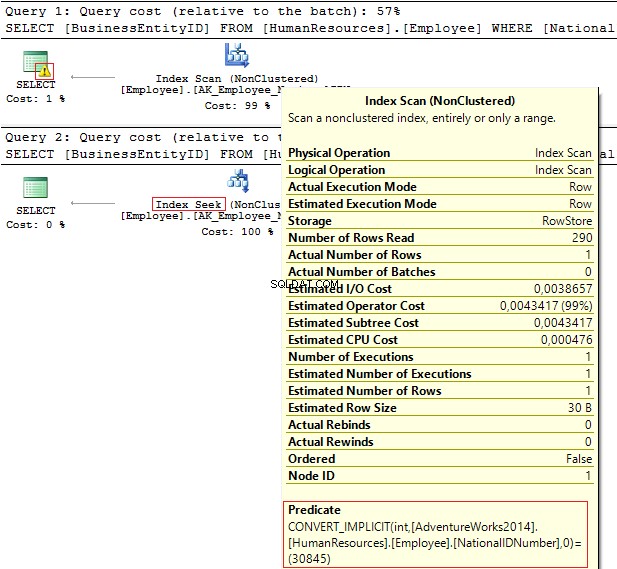
- Upozornění a IndexScan na prvním plánu
- IndexSeek – na druhém.
Tabulka 'Zaměstnanec'. Počet skenů 1, logické čtení 4, ...Tabulka 'Zaměstnanec'. Počet skenů 0, logické čtení 2, ...
NationalIDNumber sloupec má NVARCHAR(15) datový typ. Konstanta, kterou používáme k filtrování dat, je nastavena jako INT což nás vede k implicitní konverzi datových typů. Na druhou stranu může snížit výkon. Můžete to sledovat, když někdo upraví datový typ ve sloupci, ale dotazy se nezmění.
Je důležité pochopit, že implicitní převod datového typu může vést k chybám za běhu. Například předtím, než bylo pole PSČ číselné, se ukázalo, že poštovní směrovací číslo může obsahovat písmena. Datový typ byl tedy aktualizován. Pokud však vložíme abecední PSČ, starý dotaz již nebude fungovat:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Conversion se nezdařilo při převodu hodnoty nvarchar 'K4B 1S2' na datový typ int.
Dalším příkladem je situace, kdy potřebujete použít EntityFramework na projektu, který ve výchozím nastavení interpretuje všechna řádková pole jako Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Proto jsou generovány nesprávné dotazy:

Chcete-li tento problém vyřešit, ujistěte se, že se datové typy shodují.
Líbí se mi a index potlačení
Mít krycí index ve skutečnosti neznamená, že jej budete efektivně používat.
Pojďme si to ověřit na tomto konkrétním příkladu. Předpokládejme, že potřebujeme vypsat všechny řádky, které začínají…
POUŽÍVEJTE AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'SELECT AddressLine1FROM Person.[Address]WHERE LEFT(AddressLine1, 3) ='100'ROM Person AddressLi. Adresa]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Získáme následující logická čtení a plány provádění:
Tabulka 'Adresa'. Počet skenů 1, logické čtení 216, ...Tabulka 'Adresa'. Počet skenů 1, logické čtení 216, ...Tabulka 'Adresa'. Počet skenů 1, logické čtení 216, ...Tabulka 'Adresa'. Počet skenů 1, logické čtení 4, ...
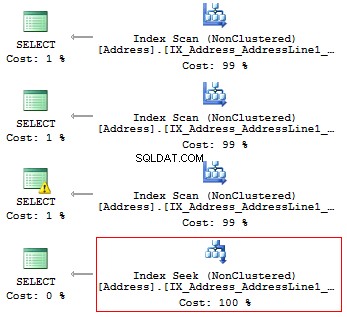
Pokud tedy existuje index, neměl by obsahovat žádné výpočty ani převod typů, funkcí atd.
Co ale uděláte, když potřebujete najít výskyt podřetězce v řetězci?
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
K této otázce se vrátíme později.
Unicode vs ANSI
Je důležité si uvědomit, že existují UNICODE a ANSI struny. Typ UNICODE zahrnuje NVARCHAR/NCHAR (2 bajty na jeden symbol). Chcete-li uložit ANSI řetězce, je možné použít VARCHAR/CHAR (1 bajt na 1 symbol). Existuje také TEXT/NTEXT , ale nedoporučuji je používat, protože mohou snížit výkon.
Pokud v dotazu zadáte konstantu Unicode, pak je nutné před ní uvést symbol N. Chcete-li to zkontrolovat, proveďte následující dotaz:
SELECT '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Pokud N nepředchází konstantu, SQL Server se pokusí najít vhodný symbol v kódování ANSI. Pokud se nepodaří najít, zobrazí se otazník.
COLLATE
Velmi často se při pohovoru na pozici Middle/Senior DB Developer tazatel často ptá na následující otázku:Vrátí tento dotaz data?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'SELECT @a, @bWHERE @a =@b
Záleží. Za prvé, symbol N nepředchází řetězcovou konstantu, proto bude interpretován jako ANSI. Za druhé, hodně záleží na aktuální hodnotě COLLATE, což je sada pravidel, při výběru a porovnávání řetězcových dat.
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER S ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CI_ASGOUSE testGODECLARE @ЁЁa NCHAR(1)' AR @1'b ) ='Ф'SELECT @a, @bWHERE @a =@b Tento příkaz COLLATE vrátí otazníky, protože jejich symboly jsou stejné:
---- ----? ?
Pokud změníme příkaz COLLATE za jiný příkaz:
Test ALTER DATABASE COLLATE Cyrillic_General_100_CI_AS
V tomto případě dotaz nevrátí nic, protože znaky azbuky budou interpretovány správně.
Pokud tedy řetězcová konstanta zabírá UNICODE, pak je nutné nastavit N před řetězcovou konstantu. Přesto bych nedoporučoval jej nastavovat všude z důvodů, které jsme probrali výše.
Další otázka, kterou je třeba v rozhovoru položit, se týká porovnávání řádků.
Zvažte následující příklad:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a =@b, 'TRUE', 'FALSE')
Jsou tyto řádky stejné? Abychom to mohli zkontrolovat, musíme výslovně zadat COLLATE:
DECLARE @a VARCHAR(10) ='TEXT' , @b VARCHAR(10) ='text'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Vzhledem k tomu, že při porovnávání a výběru řádků se rozlišují malá a velká písmena (CS) a nerozlišují velká a malá písmena (CI) COLLATE, nemůžeme s jistotou říci, zda jsou stejné. Kromě toho existují různé COLLATE jak na testovacím serveru, tak na straně klienta.
Existuje případ, kdy COLLATEs cílové báze a tempdb neshodují se.
Vytvořte databázi pomocí COLLATE:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER S ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE albánština_100_CS_ASGOUSE testGOCREATE CHARBLE VALUEINT'c ')GOIF OBJECT_ID('tempdb.dbo.#t1') NENÍ NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') NENÍ NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') IS NOT NULL DROP TABLE #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 VALUES ('a')CREATE TABLE #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FROM tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FROM t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'kolatace') FROM # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'kolatace') FROM #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'kolatace') FROM @t Při vytváření tabulky zdědí COLLATE z databáze. Jediný rozdíl pro první dočasnou tabulku, pro kterou určujeme strukturu explicitně bez COLLATE, je ten, že dědí COLLATE z tempdb databáze.
------ -------------------------tempdb Cyrillic_General_CI_AStest Albanian_100_CS_ASt Albanian_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Albanian_100_CS_AS#t3 Albanian_CS_AS#t3 Albanian_100_CS_AS
Popíšu případ, kdy COLLATEs neodpovídají na konkrétním příkladu s #t1.
Data například nejsou správně odfiltrována, protože COLLATE nemusí brát v úvahu případ:
SELECT *FROM #t1WHERE c ='A'
Případně můžeme mít konflikt při spojování tabulek s různými COLLATE:
VYBERTE *Z #t1JOIN t ON [#t1].c =t.c
Zdá se, že na testovacím serveru vše funguje perfektně, zatímco na klientském serveru se zobrazí chyba:
Zpráva 468, úroveň 16, stav 9, řádek 93Nelze vyřešit konflikt řazení mezi "Albanian_100_CS_AS" a "Cyrillic_General_CI_AS" v operaci rovná se.
Abychom to obešli, musíme všude nastavit hacky:
SELECT *FROM #t1JOIN t ON [#t1].c =t.c COLLATE database_default
BINARY COLLATE
Nyní zjistíme, jak COLLATE využít ve svůj prospěch.
Zvažte příklad s výskytem podřetězce v řetězci:
SELECT AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
Tento dotaz je možné optimalizovat a zkrátit dobu jeho provedení.
Nejprve musíme vygenerovat velkou tabulku:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER S ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE test =TERLE MODIFY test ='ZEMBY NODIFY ='ZEMBY SISI DATABASE test MODIFY FILE (NAME =N'test_log', SIZE =64 MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL , unicod NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( HODNOTY (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) t(N) ), E2(N ) AS (VYBRAT 1 Z E1 a, E1 b), E4(N) AS (VYBRAT 1 Z E2 a, E2 b), E8(N) AS (VYBRAT 1 Z E4 a, E4 b)VLOŽIT DO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FROM E8) t Vytvořte počítané sloupce s binárními COLLATES a indexy:
ALTER TABLE t PŘIDAT ansi_bin JAKO VRCHNÍ (ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t PŘIDAT unicod_bin JAKO VRCHNÍ (unicod) COLLATE Latin1_General_100_BIN2CREATE NEZAHRNUTÝ REJSTŘÍK ON NT INDTENCED INDEX ansiod NO INDTENCEDtnic u ansi_bin)VYTVOŘIT NEZAHRNUTÝ INDEX unicod_bin ON t (unicod_bin)
Proveďte proces filtrace:
SET STATISTICS TIME, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TIME, IO OFF
Jak vidíte, tento dotaz vrací následující výsledek:
Doby spuštění serveru SQL Server:Čas CPU =350 ms, uplynulý čas =354 ms. Doby spuštění serveru SQL:Čas CPU =335 ms, uplynulý čas =355 ms. Doby spuštění serveru SQL:Čas CPU =16 ms, uplynulý čas =18 ms. Doby spuštění serveru SQL:Čas CPU =17 ms, uplynulý čas =18 ms.
Jde o to, že filtr založený na binárním srovnání zabere méně času. Pokud tedy potřebujete často a rychle filtrovat výskyt řetězců, pak je možné ukládat data s COLLATE končící na BIN. Je však třeba poznamenat, že všechny binární COLLATE rozlišují velká a malá písmena.
Styl kódu
Styl kódování je přísně individuální. Přesto by tento kód měl být jednoduše udržován jinými vývojáři a měl by odpovídat určitým pravidlům.
Vytvořte samostatnou databázi a tabulku uvnitř:
USE [master]GOIF DB_ID('test') IS NOT NULL BEGIN ALTER DATABASE test SET SINGLE_USER S ROLLBACK IMMEDIATE DROP DATABASE testENDGOCREATE DATABASE test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABLE dbo.Employ dbo.Employ PRIeMAEmploy
Poté napište dotaz:
vyberte číslo zaměstnance ze zaměstnance
Nyní změňte COLLATE na jakékoli rozlišení:
ALTER DATABASE test COLLATE Latin1_General_CS_AI
Potom zkuste provést dotaz znovu:
Zpráva 208, úroveň 16, stav 1, řádek 19 Neplatný název objektu 'employee'.
Optimalizátor používá pravidla pro aktuální COLLATE v kroku vazby, když kontroluje tabulky, sloupce a další objekty a také porovnává každý objekt syntaktického stromu se skutečným objektem systémového katalogu.
Pokud chcete generovat dotazy ručně, musíte v názvech objektů vždy používat správná velká a malá písmena.
Co se týče proměnných, COLLATE se dědí z hlavní databáze. Abyste s nimi mohli také pracovat, musíte tedy používat správná velká a malá písmena:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid
V tomto případě se nezobrazí chyba:
-----------------------Cyrillic_General_CI_AS-----------1
Přesto se může na jiném serveru objevit případová chyba:
--------------------------Latin1_General_CS_ASMsg 137, Úroveň 15, Stav 2, Řádek 4Musí deklarovat skalární proměnnou "@empid". [var]char
Jak víte, jsou pevné (CHAR , NCHAR ) a proměnná (VARCHAR , NVARCHAR ) datové typy:
DECLARE @a CHAR(20) ='text' , @b VARCHAR(20) ='text'SELECT LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'VYBRAT [a =b] =IIF(@a =@b, 'PRAVDA', 'NEPRAVDA') , [b =a] =IIF(@b =@a, 'TRUE', 'FALSE') , [a LIKE b] =IIF(@a LIKE @b, 'TRUE', 'FALSE') , [b LIKE a] =IIF(@ b LIKE @a, 'TRUE', 'FALSE')
Pokud má řádek pevnou délku, řekněme 20 symbolů, ale zapsali jste pouze 4 symboly, pak SQL Server ve výchozím nastavení přidá 16 mezer vpravo:
--- --- ---- ---- ---------------------- ----------- -----------4 4 20 4 "text " "text"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
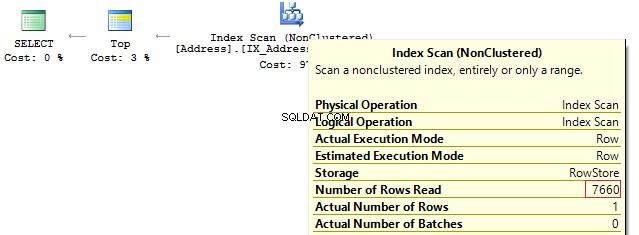
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
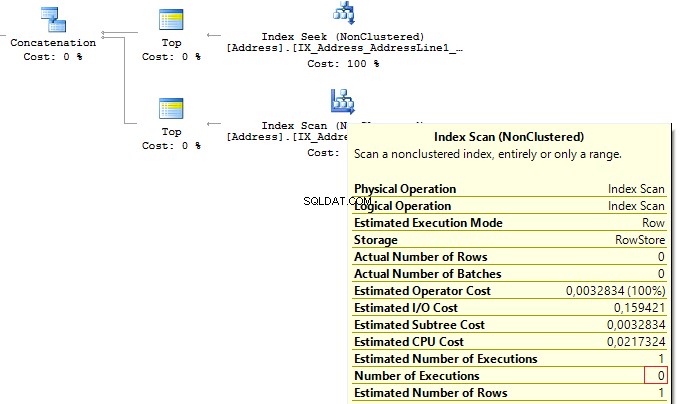
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
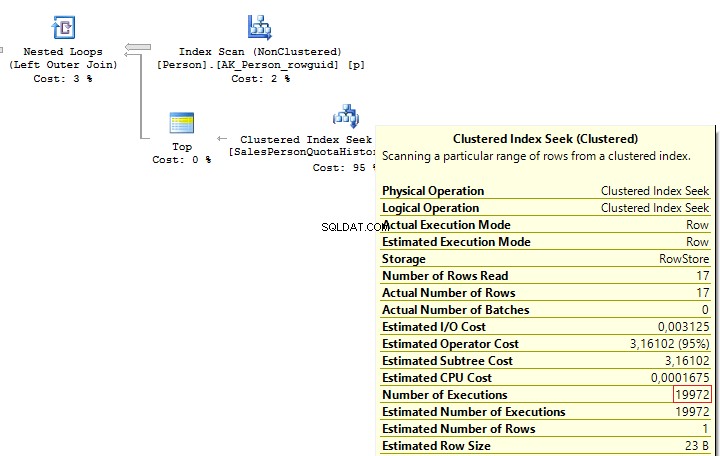
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
We get the following result:
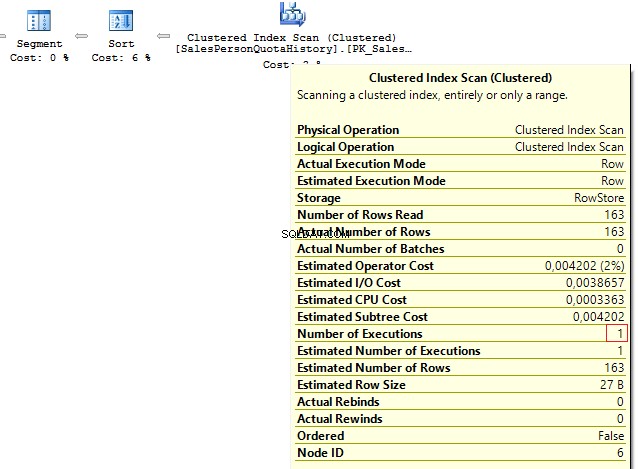
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
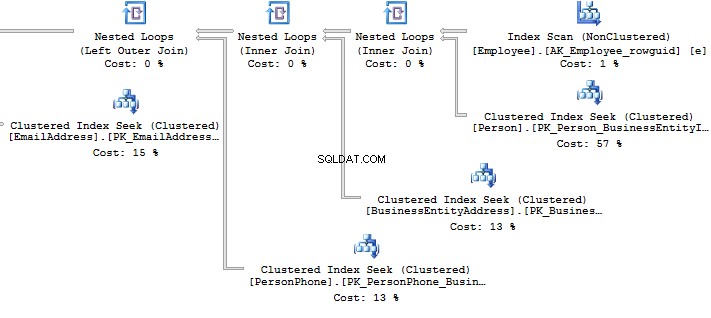
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
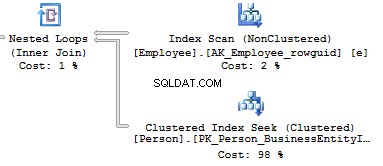
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
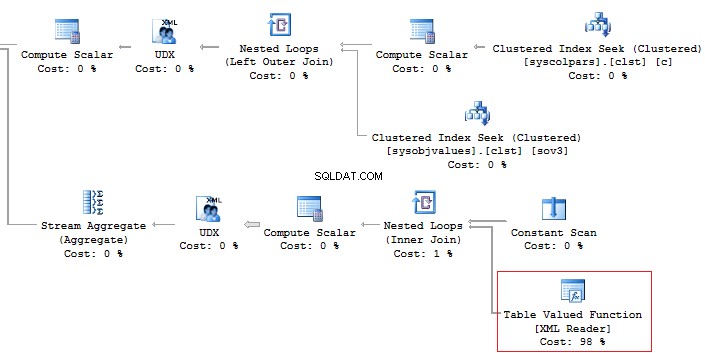
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
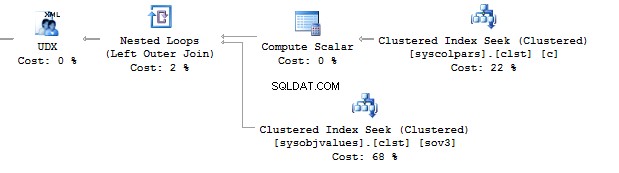
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.