Když plán provádění zahrnuje skenování struktury indexu b-stromu, úložiště úložiště může mít možnost vybrat si mezi dvěma strategiemi fyzického přístupu při provádění plánu:
- Postupujte podle struktury indexového b-stromu; nebo
- vyhledejte stránky pomocí interních informací o přidělení stránek.
Tam, kde je k dispozici možnost volby, učiní modul úložiště běhové rozhodnutí o každém spuštění. Rekompilace plánu není nutné, aby změnil názor.
Strategie b-stromu začíná u kořene stromu, klesá na extrémní okraj úrovně listu (v závislosti na tom, zda je skenování vpřed nebo vzad), pak následuje odkazy na stránce na úrovni listu, dokud nedosáhnete druhého konce indexu. . Strategie alokace používá struktury Index Allocation Map (IAM) k vyhledání databázových stránek přidělených indexu. Každá stránka IAM mapuje alokace na interval 4 GB v jediném fyzickém databázovém souboru, takže skenování řetězců IAM spojených s indexem má tendenci přistupovat k indexovým stránkám ve fyzickém pořadí souborů (alespoň pokud to SQL Server dokáže).
Hlavní rozdíly mezi těmito dvěma strategiemi jsou:
- Skenování b-stromu může doručit řádky do procesoru dotazů v pořadí klíčů indexu; skenování řízené IAM nemůže;
- Skenování b-stromu nemusí být schopno vydávat velké vstupní/výstupní požadavky pro čtení dopředu, pokud logicky sousedící indexové stránky nejsou také fyzicky souvislé (např. v důsledku rozdělení stránek v indexu).
Pro index je vždy k dispozici skenování b-stromu. Podmínky často citované pro dostupnost skenování příkazů přidělení jsou:
- Plán dotazů musí umožňovat neuspořádané prohledávání indexu;
- index musí mít velikost alespoň 64 stránek; a
- buď
TABLOCKneboNOLOCKmusí být specifikována nápověda.
První podmínka jednoduše znamená, že optimalizátor dotazů musel označit skenování pomocí Ordered:False vlastnictví. Označení skenu Ordered:False znamená, že správné výsledky z prováděcího plánu nevyžadují skenování vrátí řádky v pořadí indexových klíčů (ačkoli to může udělat, pokud je to vhodné nebo jinak nutné).
Druhá podmínka (velikost) platí pouze pro SQL Server 2005 a novější. Odráží to skutečnost, že provádění skenování řízeného IAM vyžaduje určité počáteční náklady, takže je potřeba minimální počet stránek, aby se potenciální úspory splatily počáteční investici. „64 stránek“ odkazuje na hodnotu data_pages pro IN_ROW_DATA pouze alokační jednotka, jak je uvedeno v sys.allocation_units.
Skenování alokačního příkazu se samozřejmě může vyplatit pouze v případě, že jsou skutečně možná větší úvahy o předčítání do hry, ale SQL Server v současné době tento faktor nezohledňuje. Zejména nezohledňuje, jak velká část indexu je aktuálně v paměti, ani se nestará o to, jak fragmentovaný je index.
Třetí podmínkou je pravděpodobně nejméně úplný popis v seznamu. Rady ve skutečnosti nejsou vyžadovány , i když je lze použít ke splnění skutečných požadavků:Data musí být zaručena, že se nezmění během skenování, nebo (kontroverzněji) musíme naznačit, že je nám to jedno o potenciálně nepřesných výsledcích provedením kontroly na úrovni izolace nepotvrzeného čtení.
I přes tato upřesnění není seznam podmínek pro alokační skenování stále úplný. Existuje řada důležitých upozornění a výjimek, ke kterým se brzy dostaneme.
Ukázka
Následující dotaz používá ukázkovou databázi AdventureWorks:
CHECKPOINT;DBCC DROPCLEANBUFFERS;GOSELECT P.BusinessEntityID, P.PersonTypeFROM Person.Person AS P;
Všimněte si, že tabulka Osoba obsahuje 3 869 stránek. Plán po provedení (skutečný) je následující (zobrazený v Průzkumníku plánů SQL Sentry):
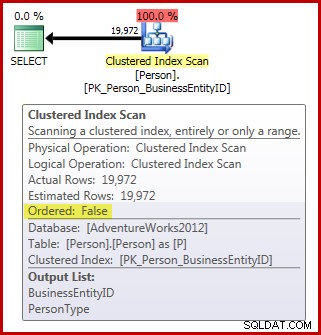
Pokud jde o požadavky na skenování alokačního pořadí, které zatím máme:
- Plán má požadovanou hodnotu
Ordered:Falsevlastnictví; a, - tabulka má více než 64 stran; ale,
- neudělali jsme nic, abychom zajistili, že se data během skenování nemohou změnit. Za předpokladu, že naše relace používá výchozí potvrzení čtení úroveň izolace, skenování se neprovádí na čtení bez potvrzení buď úroveň izolace.
V důsledku toho bychom očekávali, že toto skenování bude prováděno skenováním b-stromu spíše než řízením IAM. Výsledky dotazu naznačují, že je to pravděpodobně pravda:
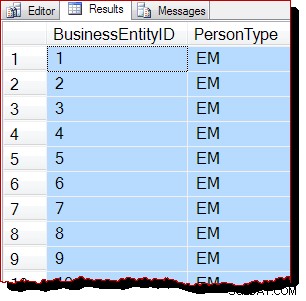
Řádky jsou vráceny v pořadí klíčů Clustered Index (podle BusinessEntityID ). Měl bych jasně uvést, že toto řazení výsledků absolutně nezaručujeme a nemělo by se na ně spoléhat. Objednané výsledky jsou zaručeny pouze odpovídajícím ORDER BY nejvyšší úrovně doložka.
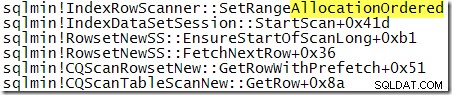
Nicméně pozorované výstupní pořadí je nepřímým důkazem, že skenování bylo tentokrát provedeno podle struktury b-stromu sdruženého indexu. Pokud je potřeba více důkazů, můžeme připojit debugger a podívat se na cestu kódu, kterou SQL Server provádí během kontroly:

Zásobník volání jasně ukazuje skenování po b-stromu.
Přidání nápovědy k uzamčení tabulky
Nyní upravíme dotaz tak, aby obsahoval nápovědu k uzamčení tabulky:
CHECKPOINT;DBCC DROPCLEANBUFFERS; SELECT P.BusinessEntityID, P.PersonTypeFROM Person.Person AS P WITH (TABLOCK);
Na výchozí úrovni izolace zamykání potvrzeného čtení zabraňuje zámek na úrovni sdílené tabulky jakýmkoli možným souběžným úpravám dat. Když jsou splněny všechny tři předpoklady pro skenování řízená IAM, očekávali bychom, že SQL Server bude používat skenování podle pořadí přidělení. Plán provádění je stejný jako předtím, takže ho nebudu opakovat, ale výsledky dotazu určitě vypadají jinak:
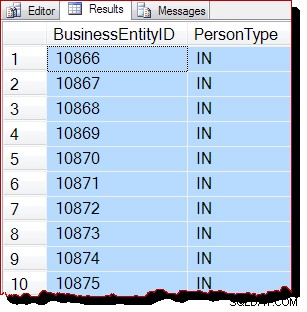
Výsledky jsou stále zřejmě seřazeny podle BusinessEntityID , ale výchozí bod (10866) je jiný. Pokud se posuneme ve výsledcích dolů, brzy narazíme na sekce, které jsou zjevně mimo klíčové pořadí:
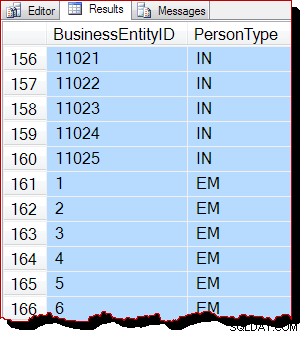
Částečné řazení je způsobeno skenováním pořadí přidělení, které zpracovává celou stránku indexu najednou. Výsledky na stránce se náhodou vrátí seřazené podle indexového klíče, ale pořadí naskenovaných stránek je nyní jiné. Znovu bych měl zdůraznit, že výsledky pro vás mohou vypadat jinak:bez nejvyšší úrovně ORDER BY není zaručeno pořadí výstupu, a to ani na stránce na původní dotaz.
Pro srovnání s výše uvedeným zásobníkem volání se jedná o trasování zásobníku získané, když SQL Server zpracovával dotaz pomocí TABLOCK nápověda:
Šlápnutím o něco dále po provedení:

Je zřejmé, že SQL Server provádí skenování podle pořadí přidělení, když je zadán zámek tabulky. Je škoda, že v plánu po spuštění není žádný údaj o tom, jaký typ skenování byl použit za běhu. Připomínáme, že typ skenování vybírá modul úložiště a může se mezi spuštěními měnit bez rekompilace plánu.
Další způsoby, jak splnit třetí podmínku
Řekl jsem již dříve, že abychom získali skenování řízené IAM, musíme zajistit, aby se data pod skenováním během jeho průběhu nezměnila, nebo musíme spustit dotaz na úrovni izolace nepotvrzeného čtení. Viděli jsme, že nápověda k uzamčení tabulky při uzamčení izolace potvrzené čtením postačuje ke splnění prvního z těchto požadavků, a je snadné ukázat, že pomocí NOLOCK/READUNCOMMITTED hint také umožňuje skenování alokačního pořadí pomocí demo dotazu.
Ve skutečnosti existuje mnoho způsobů, jak splnit třetí podmínku, včetně:
- změna indexu tak, aby umožňoval pouze zámky tabulky;
- nastavení databáze pouze pro čtení (takže je zaručeno, že se data nezmění); nebo,
- změna relace úroveň izolace na
READ UNCOMMITTED.
Existují však mnohem zajímavější varianty tohoto tématu, které znamenají, že musíme upravit tři výše uvedené podmínky…
Úrovně izolace verzování řádků
Povolte izolaci snímku potvrzeného čtení (RCSI) v databázi AdventureWorks a spusťte test pomocí TABLOCK nápověda znovu (při izolaci potvrzené čtení):
S aktivním RCSI, seřazeno podle indexu skenování se používá s TABLOCK , nikoli sken alokačního příkazu, který jsme viděli těsně předtím. Důvodem je TABLOCK nápověda určuje sdílený zámek na úrovni tabulky, ale s povoleným RCSI žádné sdílené zámky jsou převzaty. Bez zámku sdílené tabulky jsme nesplnili požadavek na zabránění souběžným úpravám dat během skenování, takže sken na objednávku nelze použít.
Dosažení skenování podle pořadí přidělení, když je povoleno RCSI, je však možné. Jedním ze způsobů je použití TABLOCKX nápověda (pro exkluzivní úroveň tabulky lock) namísto TABLOCK . Můžeme také zachovat TABLOCK nápověda a přidejte další, například READCOMMITTEDLOCK , nebo REPEATABLE READ nebo SERIALIZABLE … a tak dále. Všechny tyto funkce zabraňují možnosti souběžných úprav pomocí zámku sdílené tabulky za cenu ztráty výhod RCSI . Stále můžeme také dosáhnout skenování alokačního pořadí pomocí NOLOCK nebo READUNCOMMITTED nápověda, samozřejmě.
Situace při izolaci snímků (SI) je velmi podobná RCSI a z prostorových důvodů není podrobně prozkoumána.
TABLESAMPLE vždy* provádí sken alokačního pořadí
TABLESAMPLE klauzule je zajímavou výjimkou z mnoha věcí, o kterých jsme dosud diskutovali.
Určení TABLESAMPLE klauzule always* vede ke skenování alokačního pořadí, dokonce i pod RCSI nebo SI, a to i bez nápověd. Aby bylo jasno, sken alokačního pořadí, který je výsledkem použití TABLESAMPLE zachovává sémantiku RCSI/SI – skenování používá verze řádků a čtení neblokuje zápis (a naopak).
Druhým překvapením je TABLESAMPLE vždy* provádí skenování řízené IAM i když má tabulka méně než 64 stránek . To dává určitý smysl, protože dokumentace alespoň naznačuje, že SYSTEM metoda vzorkování používá strukturu IAM (není tedy jiná možnost, než provést sken alokačního pořadí):
SYSTEM Je metoda vzorkování závislá na implementaci specifikovaná normami ISO. V SQL Server je to jediná dostupná metoda vzorkování a je použita ve výchozím nastavení. SYSTEM používá metodu vzorkování na základě stránek, ve které je pro vzorek vybrána náhodná sada stránek z tabulky a všechny řádky na těchto stránkách jsou vráceny jako podmnožina vzorku.
* Výjimka nastane, pokud ROWS nebo PERCENT specifikaci v TABLESAMPLE klauzule znamená 100 % tabulky. Zadání dalších ROWS než metadata indikují, že jsou aktuálně v tabulce, nebude fungovat. Pomocí TABLESAMPLE SYSTEM (100 PERCENT) nebo ekvivalentní nebude vynutit skenování alokačního pořadí.
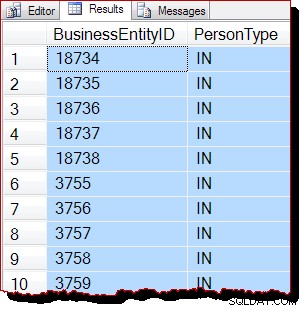
CHECKPOINT;DBCC DROPCLEANBUFFERS;GOSELECT P.BusinessEntityID, P.PersonTypeFROM Person.Person AS P TABULKY SYSTÉM (50 ŘÁDKŮ) OPAKOVATELNÝ (12345678) --WITH (TABLOCK);
Výsledky:
Efekt TOP a SET ROWCOUNT
Stručně řečeno, ani jeden z nich nemá žádný vliv na rozhodnutí použít skenování alokačního příkazu nebo ne. To se může zdát překvapivé v případech, kdy je „zřejmé“, že bude naskenováno méně než 64 stran.
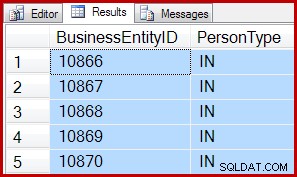
Například následující dotazy používají prohledávání řízené IAM k vrácení 5 řádků z prohledávání:
SELECT TOP (5) P.BusinessEntityID, P.PersonTypeFROM Person.Person AS P S (TABLOCK) SET ROWCOUNT 5; SELECT P.BusinessEntityID, P.PersonTypeFROM Person.Person AS P S (TABLOCK) SET ROWCOUNT 0;
Výsledky jsou pro oba stejné:
To znamená, že TOP a SET ROWCOUNT dotazy možná vynaloží režii na nastavení skenování podle pořadí přidělení, i když je naskenováno méně než 64 stránek. Složitější TOP dotazy se selektivními predikáty vloženými do skenování by mohly stále těžit z skenování podle alokačního pořadí. Pokud skenování musí zpracovat 10 000 stránek, aby našlo prvních 5 odpovídajících řádků, může být i tak výhrou skenování podle alokačního pořadí.
Zabránění všem* prověřování v alokačním pořadí v rámci celé instance
Není to něco, co byste někdy pravděpodobně udělali úmyslně, ale existuje nastavení serveru, které zabrání skenování podle pořadí přidělení pro všechny* uživatelské dotazy ve všech databázích.
Jak se to může zdát nepravděpodobné, dotyčným nastavením je možnost konfigurace serveru prahu kurzoru, která má v Books Online následující popis:
Možnost kurzorového prahu určuje počet řádků v sadě kurzorů, na kterých jsou asynchronně generovány sady kurzorových kláves. Když kurzory generují sadu klíčů pro sadu výsledků, optimalizátor dotazů odhadne počet řádků, které budou vráceny pro tuto sadu výsledků. Pokud optimalizátor dotazů odhadne, že počet vrácených řádků je větší než tato prahová hodnota, bude kurzor generován asynchronně, což uživateli umožní načítat řádky z kurzoru, zatímco kurzor pokračuje v naplňování. Jinak je kurzor generován synchronně a dotaz čeká, dokud nejsou vráceny všechny řádky.
Pokud je cursor threshold je nastavena na jakoukoli jinou hodnotu než –1 (výchozí), neproběhnou žádné kontroly pořadí alokace pro uživatelské dotazy v žádné databázi na instanci SQL Server.
Jinými slovy, pokud je povoleno asynchronní obsazení kurzoru, neprobíhá žádná prohledávání řízená IAM.
* Výjimkou je (ne100%) TABLESAMPLE dotazy. Interní dotazy generované systémem pro vytváření statistik a aktualizace statistik také nadále využívají skenování nařízená alokací.
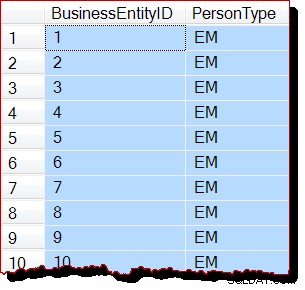
CHECKPOINT;DBCC DROPCLEANBUFFERS;GO -- VAROVÁNÍ! Zakáže prohledávání pořadí přidělení instance-wideEXECUTE sys.sp_configure @configname ='práh kurzoru', @configvalue =5000; RECONFIGURE WITH OVERRIDE;GO -- Normálně by vedlo ke skenování pořadí přiděleníSELECT P.BusinessEntityID, P.PersonTypeFROM Person.Person AS P WITH (READUNCOMMITTED);GO -- Obnovení výchozího skenování alokačního pořadíEXECUTE sys.sp_configure @configname =' prahová hodnota kurzoru', @configvalue =-1; PŘEKONFIGURUJTE S PŘEPISEM;
Výsledky (žádná kontrola alokačního pořadí):
Lze jen hádat, že asynchronní kurzorová populace z nějakého důvodu nefunguje dobře s prohledáváním pořadí přidělení. Je zcela neočekávané, že toto omezení ovlivní všechny nekurzorové uživatelské dotazy stejně tak. Možná je pro SQL Server příliš těžké zjistit, zda je dotaz spuštěn jako součást externě vydaného kurzoru API? Kdo ví.
Bylo by hezké, kdyby tento vedlejší účinek byl někde oficiálně zdokumentován, i když je těžké přesně vědět, kam by měl v Books Online jít. Zajímalo by mě, kolik produkčních systémů kvůli tomu nepoužívá skenování alokačního pořadí? Možná jich není mnoho, ale člověk nikdy neví.
Abych to uzavřel, zde je shrnutí. Skenování na základě alokace je dostupné, pokud:
- Možnost serveru
cursor thresholdje nastaveno na –1 (výchozí); a - Operátor skenování plánu dotazů má hodnotu
Ordered:Falsevlastnictví; a - celkový počet datových_stránek z
IN_ROW_DATAalokačních jednotek je minimálně 64; a - buď:
- SQL Server má přijatelnou záruku, že souběžné úpravy nejsou možné; nebo
- skenování probíhá na úrovni izolace nepotvrzeného čtení.
Bez ohledu na vše výše uvedené skenování pomocí TABLESAMPLE klauzule vždy používá skenování uspořádané podle alokace (s jedinou technickou výjimkou uvedenou v hlavním textu).