PŘÍPAD SQL? Kousek dortu!
Opravdu?
Ne, dokud nenarazíte na 3 nepříjemné problémy, které mohou způsobit chyby běhu a pomalý výkon.
Pokud se snažíte naskenovat podnadpisy, abyste viděli, jaké jsou problémy, nemohu vás obviňovat. Čtenáři, včetně mě, jsou netrpěliví.
Věřím, že základy SQL CASE již znáte, takže vás nebudu nudit dlouhými úvody. Pojďme hlouběji porozumět tomu, co se děje pod kapotou.
1. SQL CASE se ne vždy vyhodnocuje postupně
Výrazy v příkazu Microsoft SQL CASE se většinou vyhodnocují postupně nebo zleva doprava. Při použití s agregačními funkcemi je to však jiný příběh. Uveďme příklad:
-- aggregate function evaluated first and generated an error
DECLARE @value INT = 0;
SELECT CASE WHEN @value = 0 THEN 1 ELSE MAX(1/@value) END;
Výše uvedený kód vypadá normálně. Když se vás zeptám, co je výsledkem těchto prohlášení, pravděpodobně řeknete 1. Vizuální kontrola nám říká, že protože @hodnota je nastavena na 0. Když je @hodnota 0, výsledek je 1.
Ale v tomto případě tomu tak není. Podívejte se na skutečný výsledek z SQL Server Management Studio:
Msg 8134, Level 16, State 1, Line 4
Divide by zero error encountered.
Ale proč?
Když podmíněné výrazy používají agregační funkce jako MAX() v případě SQL CASE, vyhodnotí se jako první. Tedy MAX(1/@value) způsobí dělení nulovou chybou, protože @value je nula.
Tato situace je obtížnější, když je skrytá. Vysvětlím to později.
2. Jednoduchý výraz CASE CASE se vyhodnocuje vícekrát
Tak co?
Dobrá otázka. Pravdou je, že pokud používáte literály nebo jednoduché výrazy, nejsou vůbec žádné problémy. Pokud ale jako podmíněný výraz použijete poddotazy, čeká vás velké překvapení.
Než vyzkoušíte příklad níže, možná budete chtít obnovit kopii databáze odtud. Použijeme jej pro zbytek příkladů.
Nyní zvažte tento velmi jednoduchý dotaz:
SELECT TOP 1 manufacturerID FROM SportsCars
Je to velmi jednoduché, že? Vrátí 1 řádek s 1 sloupcem dat. STATISTICS IO odhaluje minimální logická čtení.
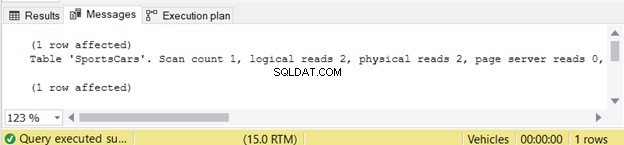
Rychlá poznámka :Pro nezasvěcené vyšší logické čtení zpomaluje dotaz. Přečtěte si další podrobnosti.
Prováděcí plán také odhaluje jednoduchý proces:
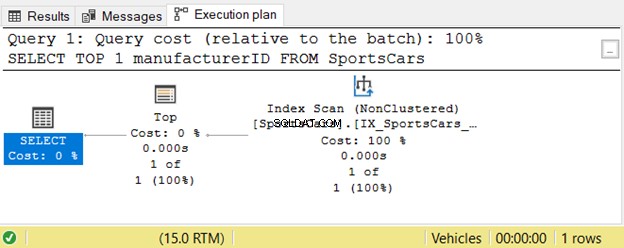
Nyní tento dotaz vložíme do výrazu CASE jako poddotaz:
-- Using a subquery in a SQL CASE
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE (SELECT TOP 1 manufacturerID FROM SportsCars)
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Analýza
Držte nám palce, protože tohle čtyřikrát odfoukne logické čtení.
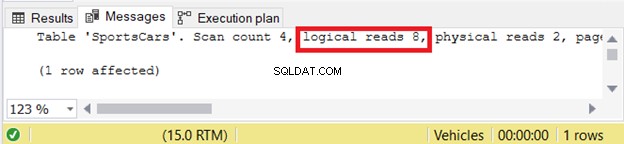
Překvapení! Ve srovnání s obrázkem 1 s pouhými 2 logickými čteními je to 4krát více. Dotaz je tedy 4x pomalejší. Jak se to mohlo stát? Poddotaz jsme viděli pouze jednou.
Ale to není konec příběhu. Podívejte se na Prováděcí plán:
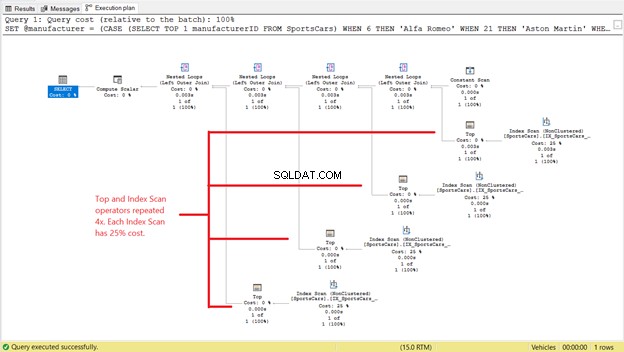
Na obrázku 4 vidíme 4 instance operátorů Top a Index Scan. Pokud každý Top a Index Scan spotřebuje 2 logická čtení, vysvětluje to, proč se logické čtení stalo 8 na obrázku 3. A protože každý Top a Index Scan má 25% náklady , také nám říká, že jsou stejné.
Tím to ale nekončí. Vlastnosti operátoru Compute Scalar odhalují, jak se s celým příkazem zachází.
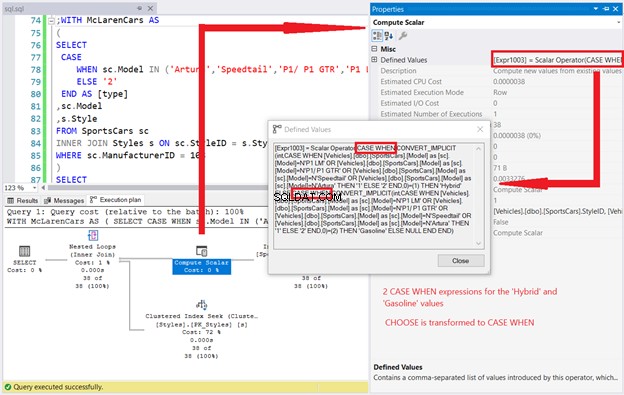
Vidíme 4 výrazy CASE WHEN pocházející z definovaných hodnot operátorem Compute Scalar. Vypadá to, že z našeho jednoduchého výrazu CASE se stal hledaný výraz typu CASE:
DECLARE @manufacturer NVARCHAR(50)
SET @manufacturer = (CASE
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 6 THEN 'Alfa Romeo'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 21 THEN 'Aston Martin'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 64 THEN 'Ferrari'
WHEN (SELECT TOP 1 manufacturerID FROM SportsCars) = 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Pojďme si to zrekapitulovat. Pro každý operátor Top a Index Scan existovala 2 logická čtení. Toto vynásobené 4 dává 8 logických čtení. Také jsme viděli 4 výrazy CASE WHEN v operátoru Compute Scalar.
Nakonec byl poddotaz v jednoduchém výrazu CASE vyhodnocen 4x. Tím se váš dotaz zpozdí.
Jak se vyhnout vícenásobnému hodnocení dílčího dotazu pomocí jednoduchého výrazu CASE
Abychom se vyhnuli takovým problémům s výkonem, jako je více příkazů CASE v SQL, musíme dotaz přepsat.
Nejprve vložte výsledek poddotazu do proměnné. Potom tuto proměnnou použijte v podmínce jednoduchého výrazu CASE serveru SQL Server, jako je tento:
DECLARE @manufacturer NVARCHAR(50)
DECLARE @ManufacturerID INT -- create a new variable
-- store the result of the subquery in a variable
SET @ManufacturerID = (SELECT TOP 1 manufacturerID FROM SportsCars)
-- use the new variable in the simple CASE expression
SET @manufacturer = (CASE @ManufacturerID
WHEN 6 THEN 'Alfa Romeo'
WHEN 21 THEN 'Aston Martin'
WHEN 64 THEN 'Ferrari'
WHEN 108 THEN 'McLaren'
ELSE 'Others'
END)
SELECT @manufacturer;
Je to dobrá oprava? Podívejme se na logická čtení ve STATISTICS IO:

Vidíme nižší logické čtení z upraveného dotazu. Vyjmutí poddotazu a přiřazení výsledku k proměnné je mnohem lepší. Co říkáte na Prováděcí plán? Viz níže.
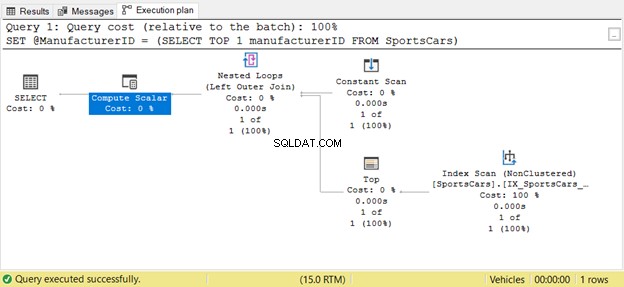
Operátor Top a Index Scan se objevil pouze jednou, nikoli 4krát. Skvělé!
Také s sebou :Nepoužívejte poddotaz jako podmínku ve výrazu CASE. Pokud potřebujete načíst hodnotu, vložte nejprve výsledek poddotazu do proměnné. Potom tuto proměnnou použijte ve výrazu CASE.
3. Tyto 3 vestavěné funkce se tajně transformují na SQL CASE
Existuje tajemství a příkaz SQL Server CASE s ním má něco společného. Pokud nevíte, jak se tyto 3 funkce chovají, nebudete vědět, že se dopouštíte chyby, které jsme se snažili vyhnout v bodech #1 a #2 dříve. Tady jsou:
- IIF
- COALESCE
- VYBRAT
Pojďme je jeden po druhém prozkoumat.
IIF
Použil jsem Immediate IF nebo IIF ve Visual Basic a Visual Basic for Applications. To je také ekvivalentní ternárnímu operátoru C#:
Tato funkce s podmínkou vrátí 1 ze 2 argumentů na základě výsledku podmínky. A tato funkce je dostupná i v T-SQL. Příkaz CASE v klauzuli WHERE lze použít v rámci příkazu SELECT
Ale je to jen cukrový kabátek delšího výrazu CASE. jak to víme? Podívejme se na příklad.
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'McLaren Senna', 'Yes', 'No');Výsledek tohoto dotazu je ‚Ne.‘ Nicméně prohlédněte si plán provádění spolu s vlastnostmi Compute Scalar.
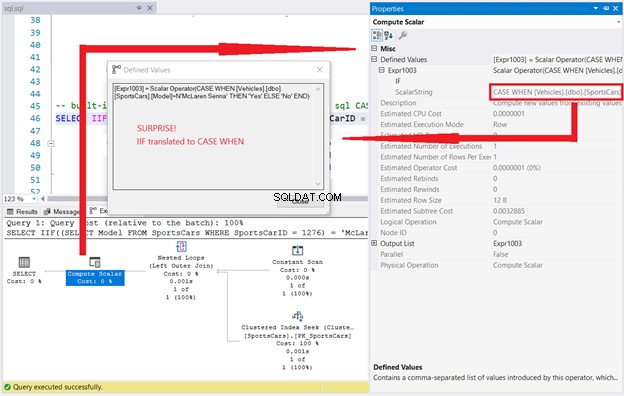
Protože IIF je CASE WHEN, co si myslíte, že se stane, když něco takového spustíte?
DECLARE @averageCost MONEY = 1000000.00;
DECLARE @noOfPayments TINYINT = 0; -- intentional to force the error
SELECT IIF((SELECT Model FROM SportsCars WHERE SportsCarID = 1276) = 'SF90 Spider', 83333.33,MIN(@averageCost / @noOfPayments));
To bude mít za následek chybu Dělení nulou, pokud je @noOfPayments 0. Totéž se stalo v bodě 1 dříve.
Možná se divíte, co tuto chybu způsobuje, protože výsledek výše uvedeného dotazu bude PRAVDA a měl by vrátit 83333.33. Zkontrolujte znovu bod #1.
Pokud tedy při používání IIF narazíte na chybu, jako je tato, je na vině SQL CASE.
COALESCE
COALESCE je také zkratka výrazu SQL CASE. Vyhodnotí seznam hodnot a vrátí první nenulovou hodnotu. V předchozím článku o COALESCE jsem uvedl příklad, který vyhodnocuje poddotaz dvakrát. Ale použil jsem jinou metodu k odhalení CASE SQL v plánu provádění. Zde je další příklad, který bude používat stejné techniky.
SELECT
COALESCE(m.Manufacturer + ' ','') + sc.Model AS Car
FROM SportsCars sc
LEFT JOIN Manufacturers m ON sc.ManufacturerID = m.ManufacturerID
Podívejme se na plán provádění a výpočet skalárně definovaných hodnot.
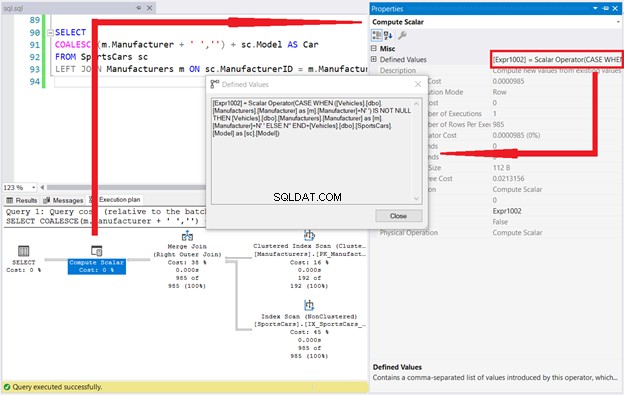
SQL CASE je v pořádku. Klíčové slovo COALESCE není nikde v okně Definované hodnoty. To dokazuje tajemství této funkce.
Ale to není vše. Kolikrát jste viděli [Vehicles].[dbo].[Styles].[Style] v okně Definované hodnoty? DVAKRÁT! To je v souladu s oficiální dokumentací společnosti Microsoft. Představte si, že jeden z argumentů v COALESCE je poddotaz. Potom zdvojnásobte logické čtení a získejte také pomalejší provádění.
VYBRAT
Nakonec VYBERTE. Jedná se o obdobu funkce MS Access CHOOSE. Vrátí 1 hodnotu ze seznamu hodnot na základě pozice indexu. Funguje také jako index do pole.
Podívejme se, zda dokážeme transformaci převést na CASE SQL s příkladem. Podívejte se na kód níže:
;WITH McLarenCars AS
(
SELECT
CASE
WHEN sc.Model IN ('Artura','Speedtail','P1/ P1 GTR','P1 LM') THEN '1'
ELSE '2'
END AS [type]
,sc.Model
,s.Style
FROM SportsCars sc
INNER JOIN Styles s ON sc.StyleID = s.StyleID
WHERE sc.ManufacturerID = 108
)
SELECT
Model
,Style
,CHOOSE([Type],'Hybrid','Gasoline') AS [type]
FROM McLarenCars
Zde je náš příklad CHOOSE. Nyní se podívejme na plán provádění a vypočítat skalárně definované hodnoty:
Vidíte klíčové slovo CHOOSE v okně Defined Values na obrázku 10? Co takhle CASE WHEN?
Stejně jako předchozí příklady je i tato funkce CHOOSE pouhou cukrovinkou k delšímu výrazu CASE. A protože dotaz má 2 položky pro CHOOSE, klíčová slova CASE WHEN se objevila dvakrát. Viz okno Defined Values uzavřené v červeném rámečku.
Máme zde však několik CASE WHEN v SQL. Je to kvůli výrazu CASE ve vnitřním dotazu CTE. Pokud se podíváte pozorně, tato část vnitřního dotazu se objeví také dvakrát.
Takové věci
Teď, když jsou tajemství venku, co jsme se dozvěděli?
- CASE SQL se při použití agregačních funkcí chová odlišně. Buďte opatrní při předávání argumentů agregačním funkcím jako MIN, MAX nebo COUNT.
- Jednoduchý výraz CASE se vyhodnotí několikrát. Všimněte si toho a vyhněte se předávání dílčího dotazu. Ačkoli je syntakticky správný, bude fungovat špatně.
- IIF, CHOOSE a COALESCE mají špinavá tajemství. Pamatujte na to před předáním hodnot těmto funkcím. Transformuje se do SQL CASE. V závislosti na hodnotách způsobíte buď chybu, nebo penalizaci výkonu.
Doufám, že tento odlišný pohled na SQL CASE byl pro vás užitečný. Pokud ano, může se líbit i vašim vývojářským přátelům. Sdílejte to prosím na svých oblíbených platformách sociálních médií. A dejte nám vědět, co si o tom myslíte v sekci Komentáře.