Ve Stack Overflow máme některé tabulky využívající seskupené indexy columnstore a ty fungují skvěle pro většinu naší pracovní zátěže. Nedávno jsme však narazili na situaci, kdy by „dokonalé bouře“ – několik procesů, které se všechny snažily odstranit ze stejného CCI – přemohly CPU, protože všechny šly široce paralelně a bojovaly o dokončení své operace. Zde je návod, jak to vypadalo v SolarWinds SQL Sentry:
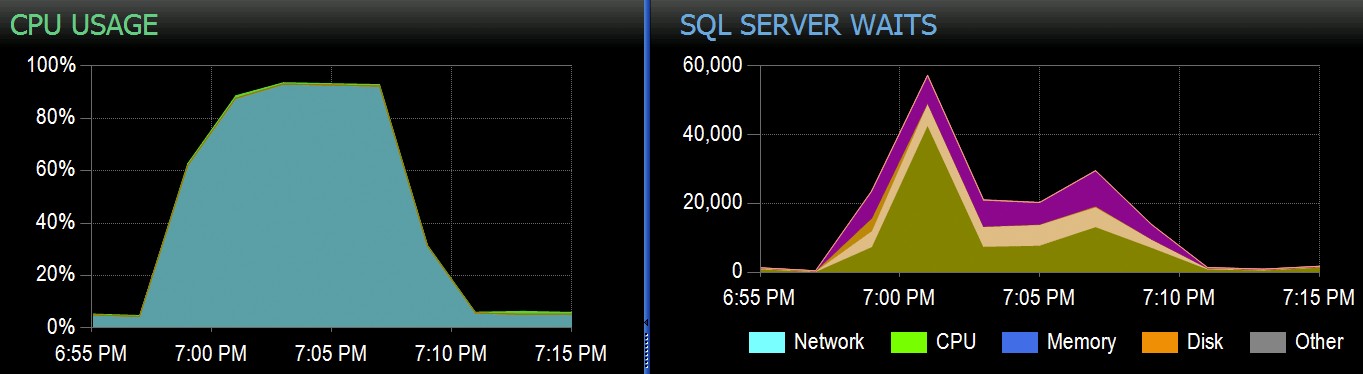
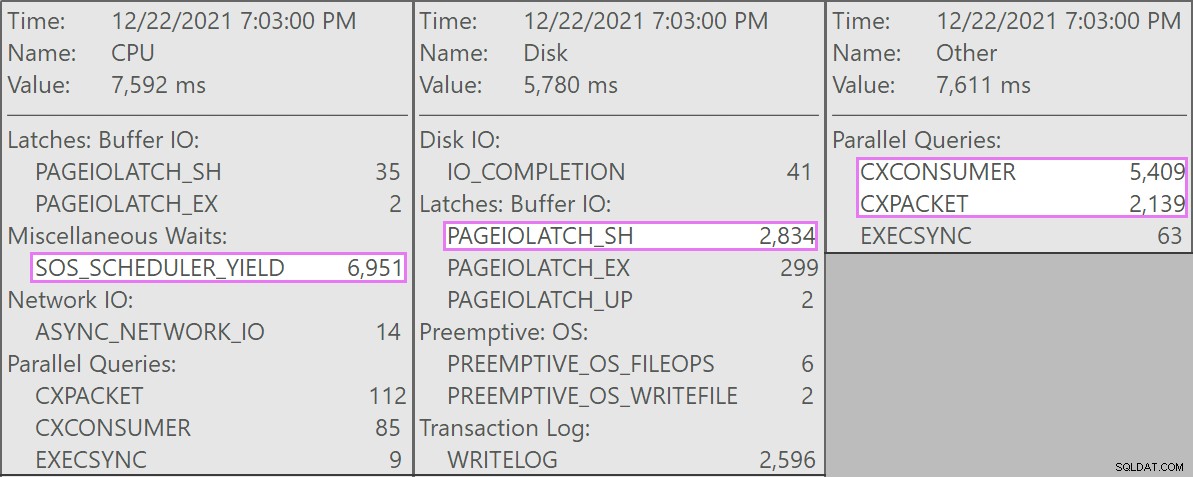
A zde jsou zajímavá čekání spojená s těmito dotazy:
Všechny soutěžní dotazy měly tento formulář:
DELETE dbo.LargeColumnstoreTable WHERE col1 =@p1 AND col2 =@p2;
Plán vypadal takto:

A varování na skenování nás upozornilo na docela extrémní zbytkové I/O:

Tabulka má 1,9 miliardy řádků, ale má pouze 32 GB (děkujeme, sloupcové úložiště!). Tyto jednořádkové mazání by však trvalo každé 10–15 sekund, přičemž většinu času stráví na SOS_SCHEDULER_YIELD .
Naštěstí, protože v tomto scénáři může být operace odstranění asynchronní, dokázali jsme problém vyřešit dvěma změnami (ačkoli zde hrubě zjednodušuji):
- Omezili jsme
MAXDOPna úrovni databáze, takže tato mazání nemohou jít tak paralelně - Vylepšili jsme serializaci procesů pocházejících z aplikace (v podstatě jsme mazání zařadili do fronty prostřednictvím jediného dispečera)
Jako DBA můžeme snadno ovládat MAXDOP , pokud to není přepsáno na úrovni dotazu (další králičí nora na další den). Nemůžeme nutně ovládat aplikaci v tomto rozsahu, zvláště pokud je distribuována nebo není naše. Jak můžeme v tomto případě serializovat zápisy, aniž bychom drasticky změnili aplikační logiku?
Mock Setup
Nebudu se pokoušet lokálně vytvořit tabulku o dvou miliardách řádků – nezáleží na přesné tabulce – ale můžeme něco aproximovat v menším měřítku a pokusit se reprodukovat stejný problém.
Předstírejme, že se jedná o SuggestedEdits tabulka (ve skutečnosti není). Ale je to jednoduchý příklad k použití, protože schéma můžeme stáhnout z Průzkumníka dat Stack Exchange. Když to použijeme jako základ, můžeme vytvořit ekvivalentní tabulku (s několika drobnými změnami, aby bylo snazší ji naplnit) a hodit na ni seskupený index columnstore:
CREATE TABLE dbo.FakeSuggestedEdits( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysDatetime(), Appr datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Komentář nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Název nvarchar (25) DEFAULT NEWID(), Tagy nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE);
Abychom jej naplnili 100 miliony řádků, můžeme křížovým spojením sys.all_objects a sys.all_columns pětkrát (v mém systému to pokaždé vytvoří 2,68 milionu řádků, ale YMMV):
-- 2680350 * 5 ~ 3 minuty INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c;GO 5>
Potom můžeme zkontrolovat mezeru:
EXEC sys.sp_spaceused @objname =N'dbo.FakeSuggestedEdits';
Je to jen 1,3 GB, ale to by mělo stačit:

Napodobování našeho smazání seskupeného úložiště sloupců
Zde je jednoduchý dotaz, který zhruba odpovídá tomu, co naše aplikace dělala s tabulkou:
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;DELETE dbo.FakeSuggestedEdits WHERE Id =@p1 AND OwnerUserId =@p2;
Plán však není úplně ideální:
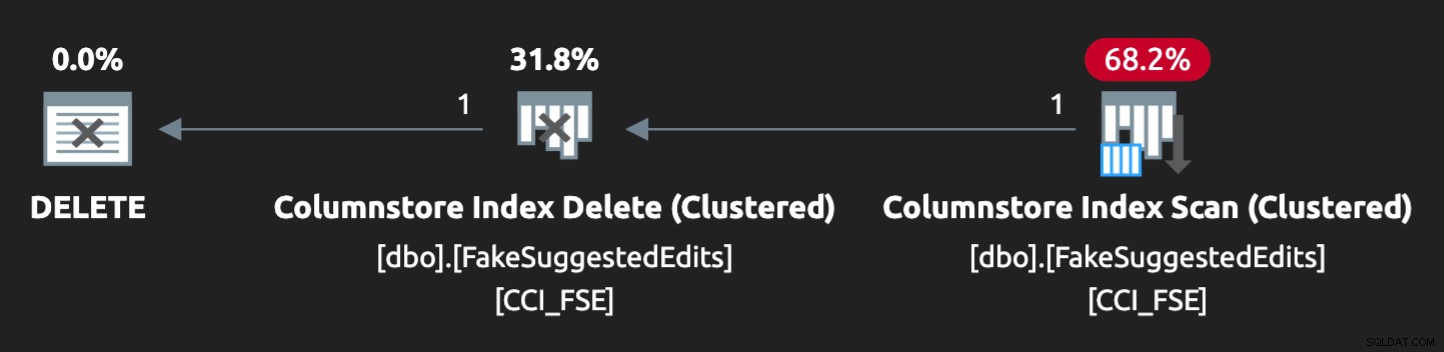
Aby to šlo paralelně a vyvolal podobný spor na mém skrovném notebooku, musel jsem optimalizátor trochu přinutit touto nápovědou:
OPTION (QUERYTRACEON 8649);
Teď to vypadá správně:

Reprodukce problému
Potom můžeme vytvořit nárůst souběžné aktivity mazání pomocí SqlStressCmd k odstranění 1 000 náhodných řádků pomocí 16 a 32 vláken:
sqlstresscmd -s docs/ColumnStore.json -t 16sqlstresscmd -s docs/ColumnStore.json -t 32
Můžeme pozorovat zátěž, kterou to klade na CPU:
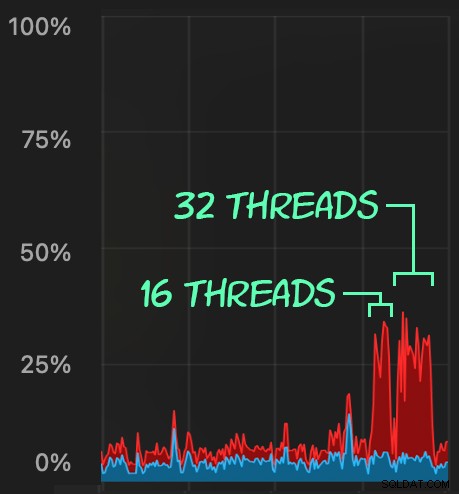
Zatížení CPU trvá v průběhu dávek přibližně 64 a 130 sekund, v tomto pořadí:
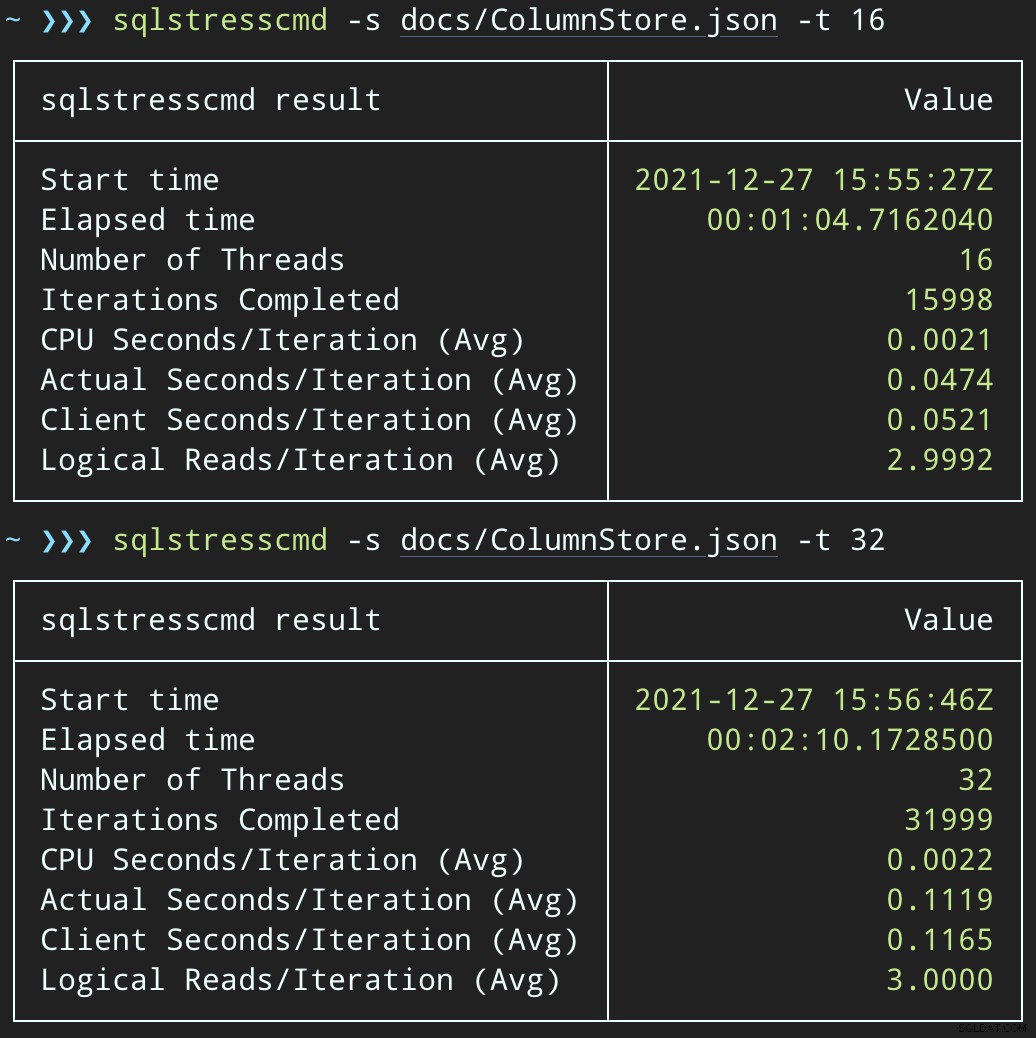
Poznámka:Výstup z SQLQueryStress je někdy v iteracích trochu mimo, ale potvrdil jsem, že práce, o kterou ho žádáte, je provedena přesně.
Možné řešení:fronta pro smazání
Zpočátku jsem přemýšlel o zavedení tabulky fronty do databáze, kterou bychom mohli použít k odstranění aktivity odstranění:
CREATE TABLE dbo.SuggestedEditDeleteQueue( QueueID int IDENTITY(1,1) PRIMÁRNÍ KLÍČ, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId); Vše, co potřebujeme, je MÍSTO spouštěče, který zachytí tato nepoctivá smazání přicházející z aplikace a umístí je do fronty pro zpracování na pozadí. Bohužel nemůžete vytvořit spouštěč na tabulce s seskupeným indexem columnstore: Msg 35358, Level 16, State 1
CREATE TRIGGER v tabulce 'dbo.FakeSuggestedEdits' se nezdařilo, protože nemůžete vytvořit spouštěč v tabulce s seskupeným indexem columnstore. Zvažte vynucení logiky spouštěče jiným způsobem, nebo pokud musíte použít spouštěč, použijte místo něj haldu nebo index B-stromu.Budeme potřebovat minimální změnu kódu aplikace, aby volala uloženou proceduru pro zpracování odstranění:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id =@Id AND OwnerUserId =@OwnerUserId;ENDToto není trvalý stav; jde jen o to, aby chování zůstalo stejné a zároveň se změnila pouze jedna věc v aplikaci. Jakmile je aplikace změněna a úspěšně volá tuto uloženou proceduru namísto odesílání ad hoc dotazů na odstranění, může se uložená procedura změnit:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId intASBEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId;ENDTestování dopadu fronty
Nyní, když změníme SqlQueryStress, aby místo toho volal uloženou proceduru:
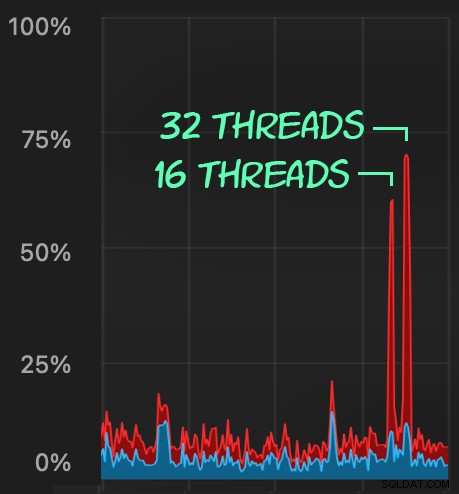
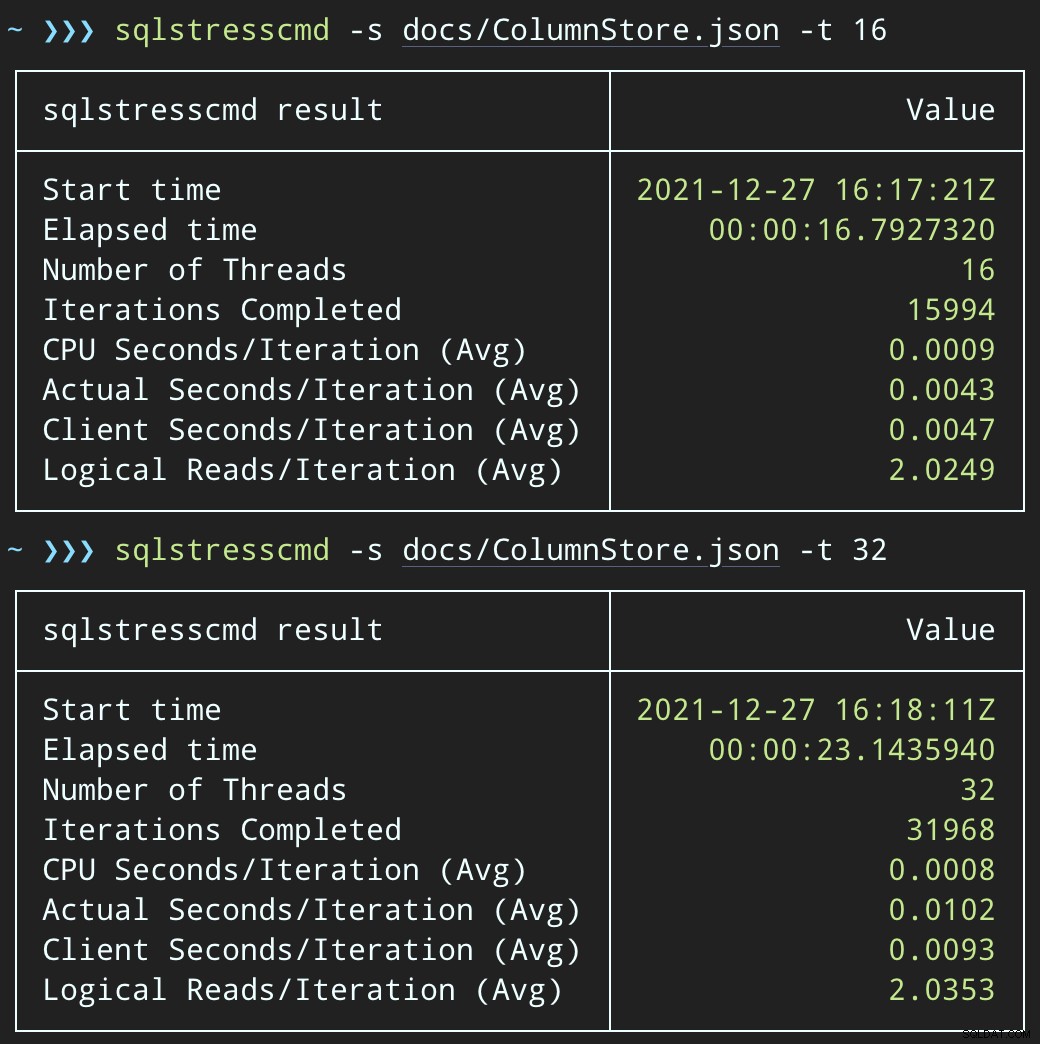
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;EXEC dbo.DeleteSuggestedEdit @Id =@p1, @OwnerUserId =@p2;A odešlete podobné dávky (umístění 16 000 nebo 32 000 řádků do fronty):
DECLARE @p1 int =ABS(CHECKSUM(NEWID())) % 10000000, @p2 int =7;EXEC dbo.@Id =@p1 A OwnerUserId =@p2;Vliv na CPU je o něco vyšší:
Úlohy však skončí mnohem rychleji – 16 a 23 sekund:
Jedná se o významné snížení bolesti, kterou budou aplikace pociťovat, když se dostanou do období vysokého souběžného běhu.
Stále však musíme provést odstranění
Stále musíme tato mazání zpracovávat na pozadí, ale nyní můžeme zavést dávkování a mít plnou kontrolu nad rychlostí a případnými prodlevami, které chceme mezi operacemi vložit. Zde je velmi základní struktura uložené procedury pro zpracování fronty (samozřejmě bez plně svěřené transakční kontroly, zpracování chyb nebo čištění tabulky fronty):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue @JobSize int =10000, @BatchSize int =100, @DelayInSeconds int =2 -- musí být mezi 1 a 59ASBEGIN SET NOCOUNT ON; DECLARE @d TABLE(Id int, OwnerUserId int); DECLARE @rc int =1, @jc int =0, @wf nvarchar(100) =N'WAITFOR DELAY ' + CHAR(39) + '00:00:' + RIGHT('0' + CONVERT(varchar(2) , @DelayInSeconds), 2) + CHAR(39); WHILE @rc> 0 AND @jc <@JobSize ZAČÁTE DELETE @d; UPDATE TOP (@BatchSize) q SET ProcessedDate =sysdatetime() VÝSTUP vložen.Id, vloženo.OwnerUserId DO @d FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST) WHERE ProcessedDate JE NULL; SET @rc =@@ROWCOUNT; IF @rc =0 BREAK; DELETE fse FROM dbo.FakeSuggestedEdits AS fse INNER JOIN @d AS d ON fse.Id =d.Id AND fse.OwnerUserId =d.OwnerUserId; SET @jc +=@rc; IF @jc> @JobSize BREAK; EXEC sys.sp_executesql @wf; END RAISERROR('Smazáno %d řádků.', 0, 1, @jc) WITH NOWAIT;ENDNyní bude mazání řádků trvat déle – průměr 10 000 řádků je 223 sekund, z toho ~ 100 je záměrné zpoždění. Ale žádný uživatel nečeká, takže koho to zajímá? Profil CPU je téměř nulový a aplikace může pokračovat v přidávání položek do fronty tak, jak vysoce souběžně chce, s téměř nulovým konfliktem s úlohou na pozadí. Při zpracování 10 000 řádků jsem do fronty přidal dalších 16 000 řádků a používala stejný procesor jako předtím – trvalo to jen o sekundu déle, než když úloha neběžela:
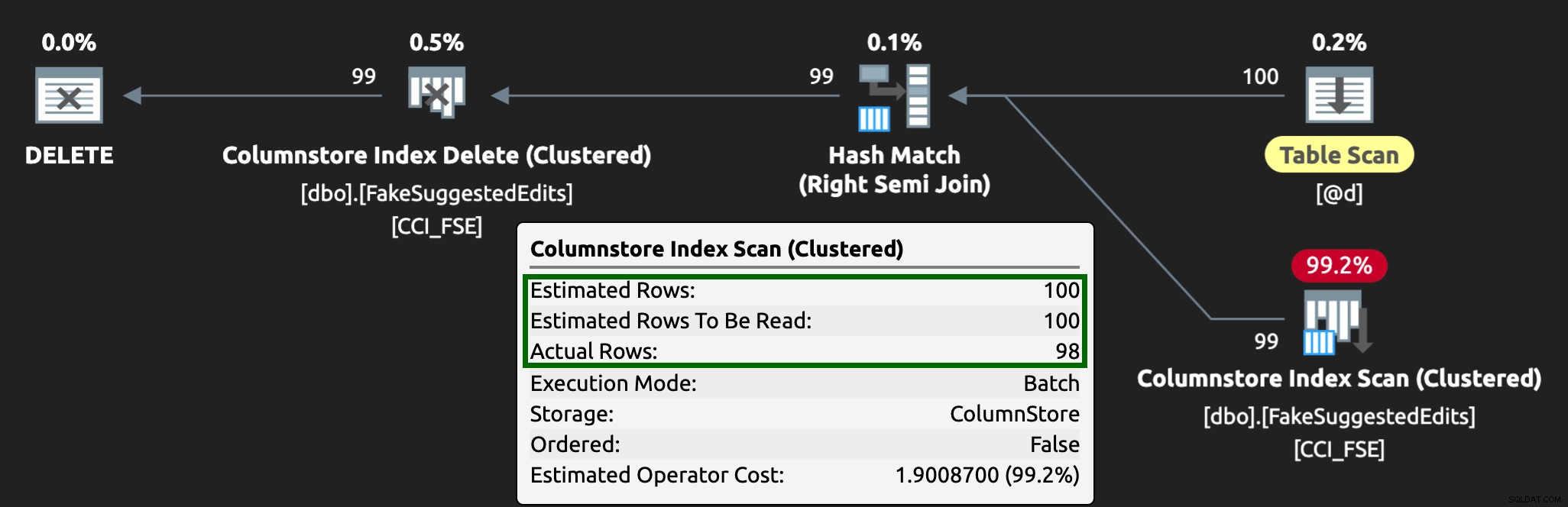
A plán nyní vypadá takto, s mnohem lépe odhadovanými / skutečnými řádky:
Vidím tento přístup s tabulkou fronty jako účinný způsob, jak se vypořádat s vysokou souběžností DML, ale vyžaduje alespoň trochu flexibility s aplikacemi odesílajícími DML – to je jeden z důvodů, proč se mi opravdu líbí, když aplikace volají uložené procedury, protože poskytněte nám mnohem větší kontrolu blíže k datům.
Další možnosti
Pokud nemáte možnost změnit dotazy na odstranění přicházející z aplikace – nebo pokud nemůžete odložit odstranění na proces na pozadí – můžete zvážit další možnosti, jak snížit dopad odstranění:
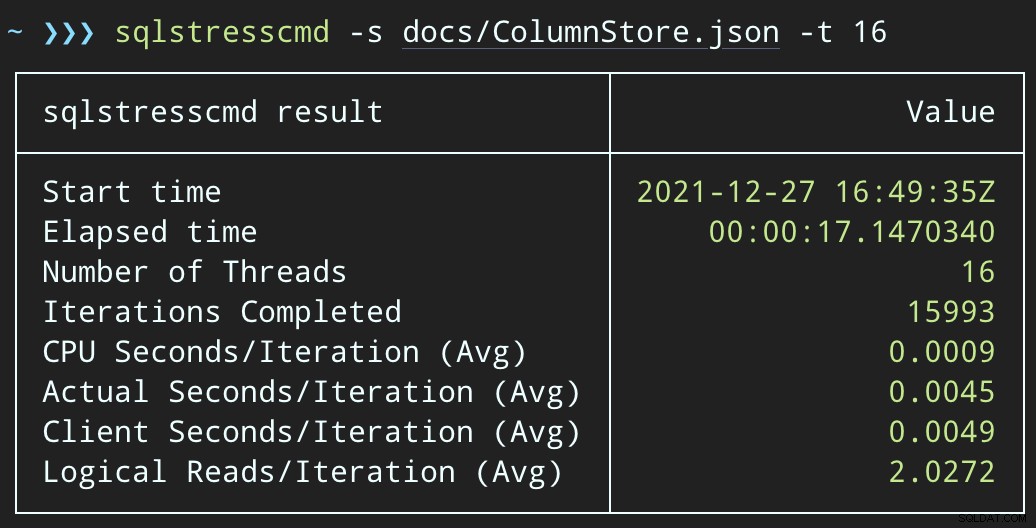
- Neshlukovaný index na predikátových sloupcích pro podporu vyhledávání bodů (můžeme to udělat izolovaně, aniž bychom měnili aplikaci)
- Pouze pomocí měkkých mazání (stále vyžaduje změny v aplikaci)
Bude zajímavé zjistit, zda tyto možnosti nabízejí podobné výhody, ale nechám si je pro budoucí příspěvek.