Nedávno jsem se podílel na vývoji funkcionality, která vyžadovala rychlý a častý přenos velkých objemů dat na disk. Tato data se navíc měla čas od času číst z disku. Bylo mi tedy souzeno zjistit místo, způsob a prostředky pro uložení těchto dat. V tomto článku stručně zhodnotím úkol a také prozkoumám a porovnám řešení pro dokončení tohoto úkolu.
Kontext úkolu :Pracuji v týmu, který vyvíjí nástroje pro vývoj relativních databází (SQL Server, MySQL, Oracle). Řada nástrojů zahrnuje jak samostatné nástroje, tak doplňky pro MS SSMS.
Úkol :Obnovení dokumentů, které byly otevřeny v okamžiku uzavření IDE při příštím spuštění IDE.
Případ použití :Rychlé ukončení IDE před odchodem z kanceláře bez přemýšlení o tom, které dokumenty byly uloženy a které ne. Při dalším spuštění IDE potřebujeme získat stejné prostředí, jaké bylo v okamžiku uzavření a pokračovat v práci. Veškeré výsledky práce musí být uloženy v okamžiku nepořádného uzavření, např. během selhání programu nebo operačního systému nebo během vypnutí.
Analýza úkolů :Podobná funkce je k dispozici ve webových prohlížečích. Prohlížeče však ukládají pouze adresy URL, které se skládají z přibližně 100 symbolů. V našem případě potřebujeme uložit celý obsah dokumentu. Proto potřebujeme místo pro ukládání a ukládání uživatelských dokumentů. Navíc někdy uživatelé pracují s SQL jiným způsobem než s jinými jazyky. Například, když napíšu třídu C# delší než 1000 řádků, bude to stěží přijatelné. Zatímco ve vesmíru SQL, spolu s 10-20-řádkovými dotazy, existují monstrózní databázové výpisy. Takové výpisy lze jen stěží upravovat, což znamená, že uživatelé by raději uchovali své úpravy v bezpečí.
Požadavky na úložiště:
- Mělo by se jednat o jednoduché vestavěné řešení.
- Měl by mít vysokou rychlost zápisu.
- Měl by mít možnost víceprocesového přístupu. Tento požadavek není kritický, protože můžeme zajistit přístup pomocí synchronizačních objektů, ale přesto by bylo hezké mít tuto možnost.
Kandidáti
První kandidát je poněkud neohrabaný, to znamená uložit vše do složky, někde v AppData.
Druhý kandidát je zřejmý – SQLite, standard vestavěných databází. Velmi solidní a oblíbený kandidát.
Třetím kandidátem je databáze LiteDB. Je to první výsledek pro dotaz „vestavěná databáze pro .net“ v Google.
První pohled
Souborový systém. Soubory jsou soubory, vyžadují údržbu a správné pojmenování. Kromě obsahu souboru budeme muset uložit malou sadu vlastností (původní cestu na disku, připojovací řetězec, verzi IDE, ve které byl otevřen). To znamená, že budeme muset buď vytvořit dva soubory pro jeden dokument, nebo vymyslet formát, který odděluje vlastnosti od obsahu.
SQLite je klasická relační databáze. Databáze je reprezentována jedním souborem na disku. Tento soubor je svázán s databázovým schématem, načež s ním musíme interagovat pomocí prostředků SQL. Budeme moci vytvořit 2 tabulky, jednu pro vlastnosti a druhou pro obsah – v případě, že budeme potřebovat vlastnosti nebo obsah používat samostatně.
LiteDB je nerelační databáze. Podobně jako u SQLite je databáze reprezentována jedním souborem. Je to celé napsané v С#. Vyznačuje se úchvatnou jednoduchostí použití:do knihovny potřebujeme pouze dát objekt, zatímco serializace bude provedena jejími vlastními prostředky.
Test výkonu
Před poskytnutím kódu bych rád vysvětlil obecnou koncepci a poskytl výsledky srovnání.
Obecná koncepce je porovnávání rychlosti zápisu velkého množství malých souborů do databáze, průměrného množství průměrných souborů a malého množství velkých souborů. Případy s průměrnými soubory se většinou blíží skutečným případům, zatímco případy s malými a velkými soubory jsou hraniční případy, které je třeba také vzít v úvahu.
Zapisoval jsem obsah do souboru pomocí FileStream se standardní velikostí vyrovnávací paměti.
V SQLite byla jedna nuance, kterou bych rád zmínil. Nepodařilo se nám umístit veškerý obsah dokumentu (jak jsem uvedl výše, může být opravdu velký) do jedné databáze. Jde o to, že pro účely optimalizace ukládáme text dokumentu řádek po řádku. To znamená, že abychom mohli vložit text do jedné buňky, musíme všechny dokumenty umístit do jednoho řádku, čímž by se zdvojnásobilo množství použité operační paměti. Druhá stránka problému by se odhalila při čtení dat z databáze. Proto byla v SQLite samostatná tabulka, kde byla data ukládána řádek po řádku a data byla propojena pomocí cizího klíče s tabulkou obsahující pouze vlastnosti souboru. Kromě toho se mi podařilo zrychlit databázi pomocí dávkového vkládání dat (několik tisíc řádků najednou) ve vypnutém režimu synchronizace bez logování a v rámci jedné transakce.
LiteDB obdržel objekt, který má mezi vlastnostmi Seznam a knihovna jej sama uložila na disk.
Při vývoji testovací aplikace jsem pochopil, že preferuji LiteDB. Jde o to, že testovací kód pro SQLite zabere více než 120 řádků, zatímco kód, který řeší stejný problém v LiteDb, zabere pouze 20 řádků.
Generování testovacích dat
FileStrings.cs
vnitřní třída FileStrings { private static readonly Náhodný náhodný =new Random(); public List Strings { get; soubor; } =new List(); public int SomeInfo { get; soubor; } public FileStrings() { } public FileStrings(int id, int minLines, desetinný řádekIncrement) { SomeInfo =id; int řádky =minŘádky + (int)(id * přírůstek řádku); for (int i =0; i <řádky; i++) { Strings.Add(GetString()); } } private string GetString() { int length =250; StringBuilder builder =new StringBuilder(length); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (desítkové)NUM_FILES)) .ToList();
před>
SQLite
private static void SaveToDb(Seznam souborů) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Zdroj dat=data\database.db;FailIfMissing=False;"; připojení.Otevřít(); příkaz var =connection.CreateCommand(); command.CommandText =@"CREATE TABLE files( id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings( id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_number_file_line strings; PRAGMA synchronous =OFF;PRAGMA journal_mode =OFF"; command.ExecuteNonQuery(); var insertFilecommand =connection.CreateCommand(); insertFilecommand.CommandText ="INSERT INTO files(název_souboru) VALUES(?); SELECT last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =connection.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strings(řetězec, file_id, line_number) VALUES(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (položka var v souborech) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =název_souboru; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0; foreach (var line in item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(položka seznamu) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("files"); data.EnsureIndex(f => f.SomeInfo); data.Insert(položka); } }
Následující tabulka ukazuje průměrné výsledky pro několik spuštění testovacího kódu. Během úprav byla statistická odchylka zcela nepostřehnutelná.
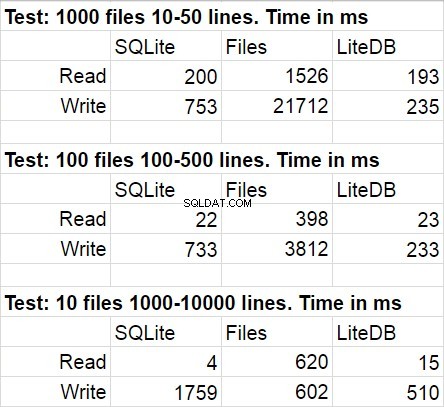
Nepřekvapilo mě, že v tomto srovnání zvítězil LiteDB. Byl jsem však šokován výhrou LiteDB nad soubory. Po krátkém prostudování repozitáře knihovny jsem zjistil velmi pečlivě implementovaný paginální zápis na disk, ale jsem si jistý, že je to jen jeden z mnoha výkonových triků, které se tam používají. Ještě jedna věc, na kterou bych rád upozornil, je rychlý pokles rychlosti přístupu k systému souborů, když je množství souborů ve složce opravdu velké.
Pro vývoj naší funkce jsme si vybrali LiteDB a téměř jsme této volby nelitovali. Jde o to, že knihovna je napsána v nativním jazyce pro všechny C#, a pokud by něco nebylo zcela jasné, vždy jsme se mohli odkázat na zdrojový kód.
Nevýhody
Kromě výše zmíněných kladů LiteDB ve srovnání s jeho konkurenty jsme si během vývoje začali všímat i záporů. Většinu těchto nevýhod lze vysvětlit ‚mládež‘ knihovny. Poté, co jsme knihovnu začali používat mírně za hranicemi „standardního“ scénáře, objevili jsme několik problémů (#419, #420, #483, #496). Autor knihovny odpovídal na dotazy poměrně rychle a většina problémů byla rychle vyřešena. Nyní zbývá pouze jeden úkol (neplést s jeho stavem Uzavřeno). To je otázka konkurenčního přístupu. Zdá se, že někde hluboko v knihovně se skrývá velmi ošklivá rasová kondice. Tuto chybu jsme překonali zcela originálním způsobem (mám v úmyslu na toto téma napsat samostatný článek).
Rád bych také zmínil absenci přehledného editoru a prohlížeče. Existuje LiteDBShell, ale je pouze pro skutečné fanoušky konzole.
Shrnutí
Nad LiteDB jsme vybudovali velkou a důležitou funkcionalitu a nyní pracujeme na další velké funkci, kde budeme používat i tuto knihovnu. Pro ty, kteří hledají průběžnou databázi, doporučuji věnovat pozornost LiteDB a způsobu, jakým se osvědčí v kontextu vašeho úkolu, protože, jak víte, kdyby něco fungovalo pro jeden úkol, nemuselo by to nutně pracovat na jiném úkolu.