Toto je závěrečná část pětidílné série, která se hluboce ponoří do způsobu, jakým se začnou realizovat paralelní plány v režimu řádků SQL Server. Část 1 inicializovala kontext provádění nula pro nadřazenou úlohu a část 2 vytvořila strom skenování dotazů. Část 3 zahájila skenování dotazů a provedla určitou ranou fázi zpracování a zahájily první další paralelní úlohy ve větvi C. Část 4 popisovala synchronizaci výměny a spuštění paralelních plánových větví C &D.
Zahájení paralelních úloh větve B
Připomenutí poboček v tomto paralelním plánu (pro zvětšení klikněte):
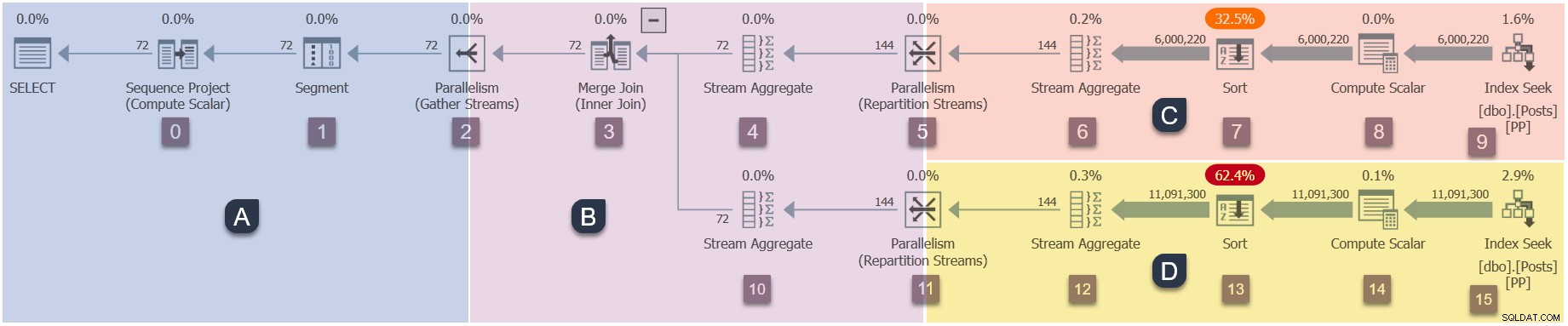
Toto je čtvrtá fáze v pořadí provádění:
- Větev A (nadřazený úkol).
- Větev C (další paralelní úlohy).
- Větev D (další paralelní úkoly).
- Větev B (další paralelní úkoly).
Jediné vlákno, které je momentálně aktivní (není pozastaveno na CXPACKET ) je nadřazený úkol , který je na spotřebitelské straně výměny přerozdělovacích toků v uzlu 11 ve větvi B:
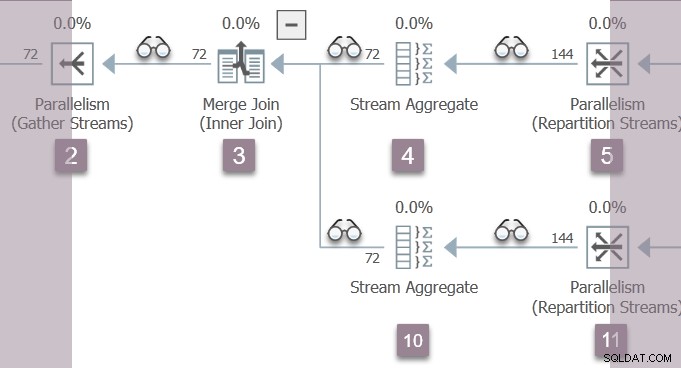
Nadřazený úkol se nyní vrací z vnořených ranných fází volání, nastavení uplynulých a CPU časů v profilerech, jak to jde. První a poslední aktivní čas není aktualizovány během rané fáze zpracování. Pamatujte, že tato čísla se zaznamenávají proti nulovému kontextu provádění – paralelní úlohy větve B zatím neexistují.
Rodičovský úkol vzestupuje strom od uzlu 11, přes agregaci proudů v uzlu 10 a slučovací spojení v uzlu 3, zpět k výměně shromažďovacích proudů v uzlu 2.
Zpracování rané fáze je nyní dokončeno .
S původním EarlyPhases volání v uzlu 2 shromáždit proudy výměna konečně Po dokončení se nadřazený úkol vrátí k otevření této ústředny (můžete si na tento hovor vzpomenout hned na začátku této série). Otevřená metoda v uzlu 2 nyní volá CQScanExchangeNew::StartAllProducers k vytvoření paralelních úloh pro větev B.
Rodičovský úkol nyní čeká na CXPACKET u spotřebitele straně uzlu 2 shromažďují proudy výměna. Toto čekání bude pokračovat, dokud nově vytvořené úkoly větve B nedokončí své vnořené Open zavolá a vrátí se k dokončení otevření produkční strany výměny sběrných proudů.
Otevřeny paralelní úlohy větve B
Dvě nové paralelní úlohy ve větvi B začínají u producenta straně uzlu 2 shromažďují proudy výměna. Podle obvyklého modelu iterativního provádění v režimu řádků volají:
CQScanXProducerNew::Open(otevřená strana producenta uzlu 2).CQScanProfileNew::Open(profil pro uzel 3).CQScanMergeJoinNew::Open(node 3 merge join).CQScanProfileNew::Open(profil pro uzel 4).CQScanStreamAggregateNew::Open(agregace proudu uzlu 4).CQScanProfileNew::Open(profil pro uzel 5).CQScanExchangeNew::Open(výměna přerozdělovacích proudů).
Paralelní úlohy sledují vnější (horní) vstup do slučovacího spojení, stejně jako zpracování v rané fázi.
Dokončení výměny
Když úkoly větve B dorazí ke spotřebiteli strana přerozdělovacích proudů si vyměňuje v uzlu 5, každý úkol:
- Registruje se pomocí výměnného portu (
CXPort). - Vytvoří potrubí (
CXPipe), které spojují tuto úlohu s jednou nebo více úlohami na straně výrobce (v závislosti na typu výměny). Aktuální výměna je přerozdělovací toky, takže každá spotřebitelská úloha má dvě roury (na DOP 2). Každý spotřebitel může obdržet řádky od kteréhokoli ze dvou výrobců. - Přidá
CXPipeMergesloučit řádky z více kanálů (protože se jedná o výměnu zachovávající pořadí). - Vytváří řádkové pakety (matoucím názvem
CXPacket) používá se pro řízení průtoku a pro vyrovnávání řad přes výměnné potrubí. Ty jsou alokovány z dříve přidělené paměti dotazů.
Jakmile obě paralelní úlohy na straně spotřebitele dokončí tuto práci, výměna uzlu 5 je připravena jít. Dva spotřebitelé (ve větvi B) a dva výrobci (ve větvi C) všichni otevřeli port výměny, takže uzel 5 CXPACKET čeká na konec .
Kontrolní bod
Jak se věci mají:
- Nadřazený úkol v větvi A čeká na
CXPACKETna spotřebitelské straně uzlu 2 shromažďuje výměnu toků. Toto čekání bude pokračovat, dokud se oba producenti uzlu 2 nevrátí a neotevře burzu. - Dva paralelní úkoly v větvi B jsou spustitelné . Právě otevřeli spotřebitelskou stranu výměny přerozdělovacích toků v uzlu 5.
- Dva paralelní úlohy v větvi C byly právě uvolněny z jejich
CXPACKETpočkejte a jsou nyní spustitelné . Dva agregáty proudu v uzlu 6 (jeden na paralelní úlohu) mohou začít agregovat řádky ze dvou řazení v uzlu 7. Připomeňme, že hledání indexu v uzlu 9 bylo uzavřeno před nějakým časem, když řazení dokončilo svou vstupní fázi. - Dva paralelní úkoly v větvi D čekají na
CXPACKETna straně producenta výměny přerozdělovacích toků v uzlu 11. Čekají, až bude spotřebitelská strana uzlu 11 otevřena dvěma paralelními úlohami ve větvi B. Vyhledávání indexu se uzavřelo a řazení jsou připraveny k přechodu na jejich výstupní fáze.
Více aktivních větví
Je to poprvé, co jsme měli aktivních více poboček (B a C) současně, což může být náročné na diskusi. Naštěstí je návrh demo dotazu takový, že agregace proudu ve větvi C vytvoří pouze několik řádků. Malý počet úzkých výstupních řádků se snadno vejde do bufferů řádkového paketu v uzlu si vymění 5 přerozdělovacích proudů. Úlohy větve C proto mohou pokračovat ve své práci (a případně se ukončit), aniž by čekaly, až spotřebitelská strana uzlu 5 přerozdělení toků načte nějaké řádky.
Pohodlně to znamená, že můžeme nechat dvě paralelní úlohy větve C běžet na pozadí, aniž bychom se o ně museli starat. Musíme se pouze zabývat tím, co dělají dvě paralelní úlohy větve B.
Otevření větve B dokončeno
Připomenutí větve B:
Dva paralelní pracovníci ve větvi B se vrátí ze svého Open volání v uzlu 5 repartition streams výměna. Tím se vrátí přes agregaci proudu v uzlu 4 do slučovacího spojení v uzlu 3.
Protože jsme vzestupně strom v Open metoda, profilery nad uzlem 5 a uzlem 4 zaznamenávají poslední aktivní čas a také sčítání uplynulých časů a časů CPU (na úlohu). U nadřazeného úkolu nyní neprovádíme rané fáze, takže čísla zaznamenaná pro kontext provádění nula nejsou ovlivněna.
Při slučovacím spojení začnou dvě paralelní úlohy větve B sestupně vnitřní (nižší) vstup, který je vede přes agregaci proudů v uzlu 10 (a několik profilovačů) na spotřebitelskou stranu výměny přerozdělovacích toků v uzlu 11.
Větev D obnovuje provádění
K opakování událostí větve C v uzlu 5 nyní dochází v uzlu 11 přerozdělovacích toků. Spotřebitelská strana výměny uzlu 11 je dokončena a otevřena. Dva producenti ve větvi D ukončí svůj CXPACKET čeká a stává se spustitelným znovu. Úlohy větve D necháme běžet na pozadí a jejich výsledky umístíme do výměnných vyrovnávacích pamětí.
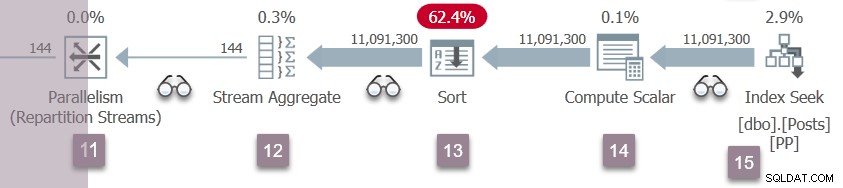
Nyní existuje šest paralelních úloh (po dvou ve větvích B, C a D) spolupracující sdílení času na dvou plánovačích přiřazených k dalším paralelním úlohám v tomto dotazu.
Otevření větve A dokončeno
Dvě paralelní úlohy ve větvi B se vrátí z Open volání na výměně proudů přerozdělení v uzlu 11, za agregací toků v uzlu 10, přes slučovací spojení v uzlu 3 a zpět na stranu producenta shromážděných proudů v uzlu 2. Profiler naposledy aktivní a akumulované uplynulé časy a časy CPU se aktualizují, jak stoupáme stromem ve vnořených Open metody.
U výrobce Na straně výměny sběrných datových proudů se obě paralelní úlohy větve B synchronizují otevřením výměnného portu a počkejte na CXPACKET aby se spotřebitelská strana otevřela.
Rodičovský úkol Čekání na spotřebitelské straně sběrných datových proudů je nyní vydáno z jeho CXPACKET počkat, což mu umožní dokončit otevření výměnného portu na straně spotřebitele. To zase uvolní producenty z jejich (stručného) CXPACKET Počkejte. Shromažďovací streamy uzlu 2 nyní otevřeli všichni vlastníci.
Dokončení kontroly dotazů
Rodičovský úkol nyní stoupá strom skenování dotazů z výměny sběrných proudů a vrací se z Open hovory na ústředně, segment a sekvenční projekt operátory ve větvi A.
Tím je otevření dokončeno strom skenování dotazů, který byl před chvílí spuštěn voláním CQueryScan::StartupQuery . Všechny větve paralelního plánu se nyní začaly provádět.
Vracející se řádky
Plán provádění je připraven začít vracet řádky jako odpověď na GetRow volání v kořenovém adresáři stromu skenování dotazů, zahájené voláním CQueryScan::GetRow . Nebudu zabíhat do úplných podrobností, protože to je přísně nad rámec článku o tom, jak spouštějí paralelní plány .
Přesto je krátká sekvence:
- Nadřazená úloha volá
GetRowna sekvenčním projektu, který voláGetRowv segmentu, který voláGetRowna spotřebitele strana výměny shromažďovacích proudů. - Pokud na burze ještě nejsou k dispozici žádné řádky, nadřazený úkol čeká na
CXCONSUMER. - Mezitím nezávisle běžící paralelní úlohy větve B rekurzivně volaly
GetRowpočínaje výrobcem strana výměny shromažďovacích proudů. - Řádky dodávají větvi B spotřebitelské strany výměn přerozdělovacích toků v uzlech 5 a 12.
- Větve C a D stále zpracovávají řádky ze svých druhů prostřednictvím příslušných agregátů toků. Úkoly větve B možná budou muset čekat na
CXCONSUMERv přerozdělovacích proudech uzlů 5 a 12, aby byl k dispozici úplný paket řádků. - Řádky vycházející z vnořeného prvku
GetRowvolání ve větvi B jsou sestavována do řádkových paketů u producenta strana výměny shromažďovacích proudů. CXCONSUMERnadřazeného úkolu čekání na spotřebitelské straně sběrných proudů končí, když je paket dostupný.- Řádek po druhém je pak zpracován prostřednictvím nadřazených operátorů ve větvi A a nakonec ke klientovi.
- Nakonec řádky dojdou a vnořené
Closevlny volání po stromě, napříč ústřednami a paralelní provádění končí.
Souhrn a závěrečné poznámky
Nejprve shrnutí posloupnosti provádění tohoto konkrétního plánu paralelního provádění:
- Rodičovský úkol otevře větev A . Počáteční fáze zpracování začíná při výměně sběrných proudů.
- Volání rané fáze nadřazené úlohy sestupují ze stromu skenování k hledání indexu v uzlu 9 a pak sestupují zpět k výměně rozdělení v uzlu 5.
- Nadřazená úloha spouští paralelní úlohy pro větev C , pak počká, než načtou všechny dostupné řádky do blokovacích operátorů řazení v uzlu 7.
- Volání rané fáze stoupají ke slučovacímu spojení, poté sestupují vnitřním vstupem do ústředny v uzlu 11.
- Úkoly pro Pobočku D jsou spuštěny stejně jako pro větev C, zatímco nadřazená úloha čeká v uzlu 11.
- Volání rané fáze se vracejí z uzlu 11 až do sběrných datových proudů. Předčasná fáze končí zde.
- Nadřazená úloha vytváří paralelní úlohy pro větev B a čeká, dokud nebude dokončeno otevření větve B.
- Úkoly větve B se dostanou do uzlových 5 proudů rozdělení, synchronizují se, dokončí výměnu a uvolní úlohy větve C, aby se mohly začít agregovat řádky z řazení.
- Když úkoly větve B dosáhnou toků rozdělení uzlu 12, synchronizují se, dokončí výměnu a uvolní úkoly větve D, aby se mohly začít agregovat řádky z řazení.
- Úkoly větve B se vracejí k výměně a synchronizaci shromažďovacích proudů a uvolňují nadřazenou úlohu z čekání. Nadřazená úloha je nyní připravena zahájit proces vracení řádků klientovi.
Možná byste chtěli sledovat provádění tohoto plánu v Sentry One Plan Explorer. Nezapomeňte povolit možnost „S profilem živého dotazu“ pro shromažďování aktuálního plánu. Pěkná věc na provádění dotazu přímo v Průzkumníkovi plánu je, že budete moci procházet několika zachyceními svým vlastním tempem a dokonce i přetáčet. Zobrazí také grafické shrnutí I/O, CPU a čekání synchronizované s aktuálními daty profilování dotazů.
Další poznámky
Vzestup stromu skenování dotazů během zpracování rané fáze nastavuje první a poslední aktivní časy v každém iterátoru profilování pro nadřazenou úlohu, ale nesčítá uplynulý čas ani čas CPU. Vzestup ve stromu během Open a GetRow volání paralelní úlohy nastavuje poslední aktivní čas a akumuluje uplynulý čas a čas CPU v každém iterátoru profilování na úlohu.
Zpracování rané fáze je specifické pro paralelní plány v režimu řádků. Je nutné zajistit, aby výměny byly inicializovány ve správném pořadí a všechny paralelní stroje fungovaly správně.
Nadřazená úloha ne vždy provádí celé zpracování rané fáze. Rané fáze začínají na kořenové výměně, ale to, jak tato volání procházejí stromem, závisí na iterátorech, se kterými se setkáte. Pro toto demo jsem zvolil slučovací spojení, protože náhodou vyžaduje zpracování rané fáze pro oba vstupy.
Rané fáze při (například) paralelním spojení hash se šíří pouze na vstupu sestavení. Když spojení hash přejde do fáze sondy, otevře se iterátory na tomto vstupu, včetně všech výměn. Je zahájeno další kolo zpracování rané fáze, které má na starosti (přesně) jedna z paralelních úloh, která hraje roli nadřazené úlohy.
Když zpracování rané fáze narazí na paralelní větev obsahující blokující iterátor, spustí další paralelní úlohy pro tuto větev a čeká, až tito producenti dokončí svou otevírací fázi. Tato větev může mít také podřízené větve, se kterými se zachází stejným způsobem, rekurzivně.
Některé větve v paralelním plánu v režimu řádků mohou vyžadovat spuštění na jednom vláknu (např. kvůli globálnímu agregaci nebo vrcholu). Tyto „sériové zóny“ také běží na další „paralelní“ úloze, jediným rozdílem je, že pro tuto větev existuje pouze jedna úloha, kontext provádění a pracovník. Zpracování rané fáze funguje stejně bez ohledu na počet úkolů přiřazených pobočce. Například „sériová zóna“ hlásí časování nadřazeného úkolu (nebo paralelního úkolu, který tuto roli hraje) a také jednoho dalšího úkolu. To se v showplanu projevuje jako data pro „vlákno 0“ (počáteční fáze) a také „vlákno 1“ (další úkol).
Uzavření myšlenek
To vše jistě představuje další vrstvu složitosti. Návratnost této investice spočívá ve využití prostředků za běhu (především vláken a paměti), snížení čekání na synchronizaci, zvýšení propustnosti, potenciálně přesných metrik výkonu a minimalizované šance na paralelní zablokování v rámci dotazu.
Ačkoli paralelismus v režimu řádků byl do značné míry zastíněn modernějším paralelním prováděcím strojem v dávkovém režimu, návrh režimu řádků má stále určitou krásu. Většina iterátorů předstírá, že stále běží v sériovém plánu, přičemž téměř veškerou synchronizaci, řízení toku a plánování řeší burzy. Péče a pozornost evidentní v implementačních detailech, jako je zpracování rané fáze, umožňuje úspěšné provedení i těch největších paralelních plánů, aniž by návrhář dotazů příliš přemýšlel nad praktickými obtížemi.