Tento článek je 7. částí série o pojmenovaných tabulkových výrazech. V části 5 a části 6 jsem pokryl koncepční aspekty běžných tabulkových výrazů (CTE). Tento měsíc a příští měsíc se zaměřím na úvahy o optimalizaci CTE.
Začnu tím, že se rychle vrátím k neuhnízděnému konceptu pojmenovaných tabulkových výrazů a ukážu jeho použitelnost na CTE. Poté se zaměřím na úvahy o vytrvalosti. Budu mluvit o aspektech persistence rekurzivních a nerekurzivních CTE. Vysvětlím, kdy má smysl držet se CTE a kdy má vlastně větší smysl pracovat s dočasnými tabulkami.
Ve svých příkladech budu nadále používat vzorové databáze TSQLV5 a PerformanceV5. Skript, který vytváří a naplňuje TSQLV5, najdete zde a jeho ER diagram zde. Skript, který vytváří a naplňuje PerformanceV5, najdete zde.
Nahrazení/rozpojení
Ve 4. části série, která se zaměřila na optimalizaci odvozených tabulek, jsem popsal proces rozkládání/substituce tabulkových výrazů. Vysvětlil jsem, že když SQL Server optimalizuje dotaz zahrnující odvozené tabulky, aplikuje transformační pravidla na počáteční strom logických operátorů vytvořených analyzátorem, což může posouvat věci kolem toho, co byly původně hranice výrazu tabulky. To se stává do té míry, že když porovnáte plán pro dotaz pomocí odvozených tabulek s plánem pro dotaz, který jde přímo proti základním tabulkám, kde jste sami použili logiku rozpojení, vypadají stejně. Také jsem popsal techniku, jak zabránit rozkládání pomocí filtru TOP s velmi velkým počtem řádků jako vstupu. Ukázal jsem několik případů, kdy byla tato technika docela užitečná – jeden, kde bylo cílem vyhnout se chybám, a další z důvodů optimalizace.
Verze TL;DR nahrazení/rozpojení CTE je, že proces je stejný jako u odvozených tabulek. Pokud jste s tímto tvrzením spokojeni, můžete tuto část přeskočit a přejít rovnou k další části o Perzistenci. Nezmeškáte nic důležitého, co jste ještě nečetli. Pokud jste však jako já, pravděpodobně budete chtít důkaz, že tomu tak skutečně je. Pak budete pravděpodobně chtít pokračovat ve čtení této části a otestovat kód, který používám, když znovu navštívím klíčové příklady rozpojení, které jsem dříve demonstroval s odvozenými tabulkami, a převést je na použití CTE.
V části 4 jsem demonstroval následující dotaz (nazýváme ho Dotaz 1):
POUŽÍVEJTE TSQLV5; SELECT orderid, orderdate FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' . WHERE datum objednávky>='20180401';
Dotaz zahrnuje tři úrovně vnoření odvozených tabulek plus vnější dotaz. Každá úroveň filtruje jiný rozsah dat objednávek. Plán pro Dotaz 1 je znázorněn na obrázku 1.
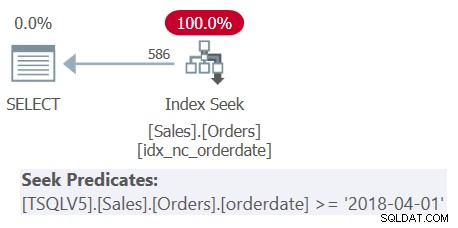 Obrázek 1:Plán provádění pro dotaz 1
Obrázek 1:Plán provádění pro dotaz 1
Plán na obrázku 1 jasně ukazuje, že k odstranění vnoření odvozených tabulek došlo, protože všechny predikáty filtru byly sloučeny do jediného zahrnujícího predikátu filtru.
Vysvětlil jsem, že procesu zrušení vnoření můžete zabránit použitím smysluplného filtru TOP (na rozdíl od TOP 100 PERCENT) s velmi velkým počtem řádků jako vstup, jak ukazuje následující dotaz (nazýváme ho Dotaz 2):
SELECT orderid, orderdate FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854772036854775'O207) *1ders FROM Sales WRE01.0207 order>1ders FROM Sales AS'RE01.0207) 20180201' ) AS D2 WHERE datum objednávky>='20180301' ) AS D3 WHERE datum objednávky>='20180401';
Plán pro Dotaz 2 je znázorněn na obrázku 2.
 Obrázek 2:Plán provádění pro dotaz 2
Obrázek 2:Plán provádění pro dotaz 2
Plán jasně ukazuje, že k odstranění hnízda nedošlo, protože můžete efektivně vidět odvozené hranice tabulky.
Zkusme stejné příklady pomocí CTE. Zde je Dotaz 1 převedený na použití CTE:
WITH C1 AS ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE orderdate>=' 20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Dostanete přesně stejný plán, který je znázorněn dříve na obrázku 1, kde můžete vidět, že došlo k odstranění hnízd.
Zde je Dotaz 2 převedený na použití CTE:
WITH C1 AS ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE datum objednávky>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * OD21 (datum C1 SELECT'08 WHERE03) TOP (9223372036854775807) * Z C2 WHERE datum objednávky>='20180301' ) VYBERTE ID objednávky, datum objednávky OD C3 WHERE datum objednávky>='20180401';
Získáte stejný plán, jaký je znázorněn dříve na obrázku 2, kde můžete vidět, že k odstranění hnízda nedošlo.
Dále se vraťme ke dvěma příkladům, které jsem použil, abych demonstroval praktičnost techniky k zabránění rozkládání – tentokrát pouze pomocí CTE.
Začněme s chybným dotazem. Následující dotaz se pokouší vrátit řádky objednávky se slevou, která je větší než minimální sleva a kde je převrácená hodnota slevy větší než 10:
VYBERTE ID objednávky, id produktu, slevu FROM Sales.OrderDetails WHERE sleva> (SELECT MIN(sleva) Z Sales.OrderDetails) A 1,0 / sleva> 10,0;
Minimální sleva nemůže být záporná, spíše je nulová nebo vyšší. Pravděpodobně si tedy myslíte, že pokud má řádek nulový diskont, první predikát by měl být vyhodnocen jako nepravdivý a že zkrat by měl zabránit pokusu o vyhodnocení druhého predikátu, čímž se zabrání chybě. Když však spustíte tento kód, dostanete chybu dělení nulou:
Zpráva 8134, úroveň 16, stav 1, řádek 99 Chyba dělení nulou.
Problém je v tom, že i když SQL Server podporuje koncept zkratu na úrovni fyzického zpracování, neexistuje žádná záruka, že vyhodnotí predikáty filtru v písemném pořadí zleva doprava. Běžným pokusem, jak se vyhnout takovým chybám, je použití pojmenovaného tabulkového výrazu, který zpracovává část logiky filtrování, kterou chcete vyhodnotit jako první, a nechat vnější dotaz zpracovat logiku filtrování, kterou chcete vyhodnotit jako druhou. Zde je pokus o řešení pomocí CTE:
WITH C AS ( SELECT * FROM Sales.OrderDetails WHERE sleva> (SELECT MIN(sleva) FROM Sales.OrderDetails) ) SELECT orderid, productid, sleva FROM C WHERE 1.0 / sleva> 10.0;
Bohužel však zrušení vnoření tabulkového výrazu vede k logickému ekvivalentu původního dotazu na řešení a při pokusu o spuštění tohoto kódu se znovu zobrazí chyba dělení nulou:
Zpráva 8134, úroveň 16, stav 1, řádek 108 Chyba dělení nulou.
Pomocí našeho triku s filtrem TOP ve vnitřním dotazu zabráníte rozkládání tabulkového výrazu, například takto:
WITH C AS ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE sleva> (SELECT MIN(sleva) FROM Sales.OrderDetails) ) SELECT orderid, productid, sleva FROM C WHERE 1.0 / sleva> 10,0>Tentokrát kód běží úspěšně bez jakýchkoli chyb.
Pokračujme příkladem, kde použijete techniku k zabránění rozkládání z důvodů optimalizace. Následující kód vrací pouze odesílatele s maximálním datem objednávky, které je 1. ledna 2018 nebo později:
USE PerformanceV5; WITH C AS ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid, maxod FROM C WHERE maxod> ='20180101';Pokud vás zajímá, proč nepoužít mnohem jednodušší řešení se seskupeným dotazem a filtrem HAVING, souvisí to s hustotou sloupce shipperid. Tabulka Objednávky obsahuje 1 000 000 objednávek a zásilky těchto objednávek zpracovalo pět odesílatelů, což znamená, že v průměru každý odesílatel vyřídil 20 % objednávek. Plán pro seskupený dotaz počítající maximální datum objednávky na odesílatele by prohledal všech 1 000 000 řádků, což by vedlo k tisícům přečtení stránek. Pokud skutečně zvýrazníte pouze vnitřní dotaz CTE (nazýváme ho Dotaz 3) počítající maximální datum objednávky na odesílatele a zkontrolujete jeho plán realizace, dostanete plán zobrazený na obrázku 3.
Obrázek 3:Plán provádění pro dotaz 3
Plán prohledá pět řádků v seskupeném indexu na Shippers. Na jednoho odesílatele plán aplikuje vyhledávání proti krycímu indexu na objednávkách, kde (shipperid, orderdate) jsou hlavní klíče indexu, jdoucí přímo na poslední řádek v každé sekci odesílatele na úrovni listu, aby se vytáhlo maximální datum objednávky pro aktuální přepravce. Protože máme pouze pět odesílatelů, existuje pouze pět operací vyhledávání indexů, což vede k velmi efektivnímu plánu. Zde jsou míry výkonu, které jsem získal, když jsem provedl vnitřní dotaz CTE:
trvání:0 ms, CPU:0 ms, čtení:15Když však spustíte kompletní řešení (nazýváme ho Dotaz 4), získáte úplně jiný plán, jak ukazuje obrázek 4.
Obrázek 4:Plán provádění pro dotaz 4
Stalo se to, že SQL Server zrušil vnoření tabulkového výrazu, čímž převedl řešení na logický ekvivalent seskupeného dotazu, což vedlo k úplnému prohledání indexu na Orders. Zde jsou čísla výkonu, která jsem pro toto řešení získal:
délka:316 ms, CPU:281 ms, čtení:3854Co zde potřebujeme, je zabránit tomu, aby došlo k odstranění vnoření tabulkového výrazu, aby se vnitřní dotaz optimalizoval pomocí vyhledávání proti indexu na Objednávkách a aby vnější dotaz vedl pouze k přidání operátoru Filtr do plán. Toho dosáhnete pomocí našeho triku přidáním TOP filtru do vnitřního dotazu, jako je tento (toto řešení budeme nazývat Dotaz 5):
WITH C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers ASid ) SELECT shipper ASID , maxod FROM C WHERE maxod>='20180101';Plán tohoto řešení je znázorněn na obrázku 5.
Obrázek 5:Plán provádění pro dotaz 5
Plán ukazuje, že bylo dosaženo požadovaného efektu, a proto to potvrzují i výkonová čísla:
trvání:0 ms, CPU:0 ms, čtení:15Naše testování tedy potvrzuje, že SQL Server zvládá nahrazování/rozpojování CTE stejně jako u odvozených tabulek. To znamená, že byste neměli upřednostňovat jedno před druhým kvůli optimalizačním důvodům, spíše kvůli koncepčním rozdílům, na kterých vám záleží, jak je uvedeno v části 5.
Trvalost
Obvyklá mylná představa týkající se CTE a pojmenovaných tabulkových výrazů obecně je, že slouží jako nějaký druh prostředku persistence. Někteří si myslí, že SQL Server přetrvává sadu výsledků vnitřního dotazu do pracovní tabulky a že vnější dotaz skutečně interaguje s touto pracovní tabulkou. V praxi se běžné nerekurzivní CTE a odvozené tabulky neuchovávají. Popsal jsem logiku rozpojování, kterou SQL Server používá při optimalizaci dotazu zahrnujícího tabulkové výrazy, což vede k plánu, který přímo interaguje s podkladovými základními tabulkami. Všimněte si, že optimalizátor se může rozhodnout použít pracovní tabulky k zachování přechodných sad výsledků, pokud to dává smysl buď z důvodů výkonu, nebo z jiných důvodů, jako je například ochrana před Halloweenem. Když tak učiní, uvidíte v plánu operátory Spool nebo Index Spool. Takové volby však nesouvisí s použitím tabulkových výrazů v dotazu.
Rekurzivní CTE
Existuje několik výjimek, ve kterých SQL Server přetrvává data výrazu tabulky. Jedním z nich je použití indexovaných zobrazení. Pokud vytvoříte seskupený index v pohledu, SQL Server zachová sadu výsledků vnitřního dotazu v seskupeném indexu pohledu a bude ji synchronizovat se všemi změnami v podkladových základních tabulkách. Další výjimkou je použití rekurzivních dotazů. SQL Server potřebuje uchovat mezilehlé výsledkové sady kotevních a rekurzivních dotazů ve spoolu, aby mohl při každém spuštění rekurzivního člena přistupovat k výsledkové sadě posledního kola představované rekurzivním odkazem na název CTE.
Abych to demonstroval, použiji jeden z rekurzivních dotazů z části 6 v seriálu.
Pomocí následujícího kódu vytvořte tabulku Zaměstnanci v databázi tempdb, naplňte ji ukázkovými daty a vytvořte podpůrný index:
SET NOCOUNT ON; USE tempdb; DROP TABULKU, POKUD EXISTUJE dbo.Zaměstnanci; GO CREATE TABLE dbo.Employees ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMÁRNÍ KLÍČ, mgrid INT NULL CONSTRAINT FK_Employees_Employees ODKAZY dbo.Employees,Employees, empname 25) NOTem mg plat (NULLMON, VAR. INSERT INTO dbo.Employees(empid, mgrid, empname, plat) VALUES(1, NULL, 'David' , 10000,00 USD), (2, 1, 'Eitan' , 7000,00 USD), (3, 1, 'Ina' 0.0 000,00 USD) , (4, 2, 'Seraph' , 5000,00 USD), (5, 2, 'Jiru' , 5500,00 USD), (6, 2, 'Steve' , 4500,00 USD), (7, 3, 'Aaron' , 5000,00 USD), ( 8, 5, 'Lilach' , 3500,00 USD), (9, 7, 'Rita' , 3000,00 USD), (10, 5, 'Sean' , 3000,00 USD), (11, 7, 'Gabriel', 3000,00 USD), (12, 9, 'Emilia' , 2 000,00 USD), (13, 9, 'Michael', 2 000,00 USD), (14, 9, 'Didi' , 1 500,00 USD); CREATE UNIQUE INDEX idx_unc_mgrid_empid ON dbo.Employees(mgrid, empid) INCLUDE(jméno, plat); GOPoužil jsem následující rekurzivní CTE k vrácení všech podřízených kořenového správce vstupního podstromu, přičemž v tomto příkladu jsem jako správce vstupu použil zaměstnance 3:
DECLARE @root AS INT =3; WITH C AS ( VYBERTE empid, mgrid, empname FROM dbo.Zaměstnanci WHERE empid =@root UNION VŠECHNY VYBERTE S.empid, S.mgrid, S.empname Z C AS M VNITŘNÍ PŘIPOJENÍ k dbo.Zaměstnanci JAKO S NA S.mgrid =M .empid ) SELECT empid, mgrid, empname FROM C;Plán pro tento dotaz (nazýváme ho Dotaz 6) je znázorněn na obrázku 6.
Obrázek 6:Plán provádění pro dotaz 6
Všimněte si, že úplně první věc, která se stane v plánu, napravo od kořenového uzlu SELECT, je vytvoření pracovní tabulky založené na B-stromu reprezentované operátorem Index Spool. Horní část plánu zpracovává logiku kotevního členu. Vytáhne vstupní řádky zaměstnanců z seskupeného indexu na Zaměstnanci a zapíše je do zařazování. Spodní část plánu představuje logiku rekurzivního člena. Provádí se opakovaně, dokud nevrátí prázdnou sadu výsledků. Vnější vstup do operátoru Nested Loops získává manažery z předchozího kola ze spoolu (Table Spool operator). Vnitřní vstup používá operátor Index Seek proti neshlukovanému indexu vytvořenému na Zaměstnanci (mgrid, empid) k získání přímých podřízených manažerů z předchozího kola. Výsledná sada každého provedení spodní části plánu je také zapsána do indexové cívky. Všimněte si, že celkem bylo do cívky zapsáno 7 řádků. Jeden vrácený kotevním členem a 6 dalších vrácených všemi provedeními rekurzivního člena.
Kromě toho je zajímavé si všimnout, jak plán zpracovává výchozí limit maximální rekurze, který je 100. Všimněte si, že spodní operátor Compute Scalar neustále zvyšuje interní čítač nazvaný Expr1011 o 1 s každým provedením rekurzivního člena. Potom operátor Assert nastaví příznak na nulu, pokud tento čítač překročí 100. Pokud k tomu dojde, SQL Server zastaví provádění dotazu a vygeneruje chybu.
Kdy nepřetrvávat
Zpět k nerekurzivním CTE, které se normálně neukládají, je na vás, abyste z hlediska optimalizace zjistili, kdy je dobré je použít oproti skutečným nástrojům pro perzistenci, jako jsou dočasné tabulky a proměnné tabulky. Uvedu několik příkladů, abych ukázal, kdy je každý přístup optimálnější.
Začněme příkladem, kde CTE fungují lépe než dočasné tabulky. To je často případ, kdy nemáte více hodnocení stejného CTE, spíše možná jen modulární řešení, kde je každý CTE vyhodnocen pouze jednou. Následující kód (nazýváme ho Dotaz 7) se dotazuje na tabulku Objednávky v databázi Performance, která má 1 000 000 řádků, aby vrátil roky objednávky, ve kterých objednávky zadalo více než 70 různých zákazníků:
USE PerformanceV5; S C1 AS ( VYBERTE ROK (datum objednávky) JAKO rok objednávky, odběratel OD dbo.Objednávky ), C2 AS ( VYBERTE rok objednávky, COUNT (DISTINCT custid) AS numcusty ZE SKUPINY C1 PODLE roku objednávky ) VYBERTE rok objednávky, numcusty OD C2 WHERE 70;<> 70 /před>Tento dotaz generuje následující výstup:
počet objednávek ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Spustil jsem tento kód pomocí SQL Server 2019 Developer Edition a získal jsem plán zobrazený na obrázku 7.
Obrázek 7:Plán provádění pro dotaz 7
Všimněte si, že zrušení vnoření CTE vedlo k plánu, který stahuje data z indexu v tabulce Objednávky a nezahrnuje žádné zařazování vnitřní sady výsledků dotazu CTE. Při provádění tohoto dotazu na mém počítači jsem získal následující čísla výkonu:
délka:265 ms, CPU:828 ms, čtení:3970, zápis:0Nyní zkusme řešení, které používá dočasné tabulky místo CTE (budeme to nazývat řešení 8), například takto:
VYBERTE ROK(datum objednávky) JAKO rok objednávky, custid DO #T1 OD dbo.Orders; VYBERTE rok objednávky, POČÍTAJTE (DISTINCT custid) JAKO numcusty DO #T2 ZE #T1 GROUP BY orderyear; SELECT rok objednávky, numcusty FROM #T2 WHERE numcusty> 70; DROP TABLE #T1, #T2;Plány tohoto řešení jsou znázorněny na obrázku 8.
Obrázek 8:Plány řešení 8
Všimněte si, že operátory vkládání tabulek zapisují sady výsledků do dočasných tabulek #T1 a #T2. První z nich je obzvláště drahý, protože zapisuje 1 000 000 řádků do #T1. Zde jsou čísla výkonu, která jsem získal pro toto provedení:
délka:454 ms, CPU:1517 ms, čtení:14359, zápis:359Jak vidíte, řešení s CTE je mnohem optimálnější.
Kdy trvat
Je to tedy tak, že modulární řešení, které zahrnuje pouze jediné vyhodnocení každého CTE, je vždy upřednostňováno před použitím dočasných tabulek? Ne nutně. V řešeních založených na CTE, která zahrnují mnoho kroků a vedou k propracovaným plánům, kde optimalizátor potřebuje použít velké množství odhadů mohutnosti v mnoha různých bodech plánu, můžete skončit s nahromaděnými nepřesnostmi, které vedou k neoptimálním volbám. Jednou z technik, jak se pokusit řešit takové případy, je uchovat si některé soubory mezivýsledků do dočasných tabulek a v případě potřeby na nich dokonce vytvořit indexy, což optimalizátoru poskytne nový začátek s novými statistikami a zvýší pravděpodobnost kvalitnějších odhadů mohutnosti. doufejme, že povede k optimálnějším volbám. Zda je to lepší než řešení, které nepoužívá dočasné tabulky, je něco, co budete muset otestovat. Někdy se vyplatí kompenzace dodatečných nákladů za trvalé sady mezivýsledků za účelem získání kvalitnějších odhadů mohutnosti.
Dalším typickým případem, kdy je preferovaným přístupem použití dočasných tabulek, je situace, kdy řešení založené na CTE má více vyhodnocení stejného CTE a vnitřní dotaz CTE je poměrně drahý. Zvažte následující řešení založené na CTE (budeme ho nazývat Dotaz 9), které každému roku a měsíci objednávky odpovídá jinému roku a měsíci objednávky, který má nejbližší počet objednávek:
S Počet objednávek JAKO ( VYBERTE ROK (datum objednávky) JAKO rok objednávky, MĚSÍC (datum objednávky) JAKO měsíc objednávky, POČET (*) JAKO počet OD dbo. Objednávky SKUPINA PODLE ROKŮ (datum objednávky), MĚSÍC (datum objednávky) ) VYBERTE O1.rok objednávky, O1 .obj.měsíc, O1.čísla, O2.rok objednávky JAKO rok objednávky2, O2.měsíc objednávky JAKO měsíc objednávky2, O2.čísla JAKO poč.2 OD Počtu Obj. JAKO O1 KŘÍŽEM POUŽIJTE ( VYBERTE NAHORU (1) O2.rok, O2.měsíc objednávky, O2.čísla OD Počet Obj. O2 KDE O2.obj.rok <> O1.obj.rok NEBO O2.obj.měsíc <> O1.obj.měsíc OBJEDNÁVKA U ABS(O1.čísla - O2.čísla), O2.obj.rok, O2.obj.měsíc ) JAKO O2;Tento dotaz generuje následující výstup:
orderyear ordermonth numorders orderyear2 ordermonth2 numorders2 ------------ ----------- ----------- --------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 51 2 101 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2 19844 2 19844 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2018 10 21197 2017 2018 10 21119 2017 2018 10 21119 2017 2018 10 21119 2017 2018 10 21119 2017 2018 10 21119 2017 2018 10 21119 2017 2018 10 21119 2017 2018 10 211197 2018 2018 10 211197 2018 2018 10 211197 2018 2018 10 211197 2018 2018 10 21197 2018 2018 10 21197 2018 2018 10 21197 2018 2018 10 21197 2018 2018 10 21197 2017 2018 10 21197 2017 2018 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 2111 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2011 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11; 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 Řádů)Plán pro Dotaz 9 je znázorněn na obrázku 9.
Obrázek 9:Plán provádění pro dotaz 9
Horní část plánu odpovídá instanci OrdCount CTE, která je označena jako O1. Výsledkem této reference je jedno hodnocení CTE OrdCount. Tato část plánu získává řádky z indexu v tabulce Objednávky, seskupuje je podle roku a měsíce a agreguje počet objednávek na skupinu, což má za následek 49 řádků. Spodní část plánu odpovídá korelované odvozené tabulce O2, která je aplikována na řádek z O1, je tedy provedena 49krát. Každé provedení se dotazuje na OrdCount CTE, a proto vede k samostatnému vyhodnocení vnitřního dotazu CTE. Vidíte, že spodní část plánu skenuje všechny řádky z indexu na objednávkách, seskupuje je a agreguje je. V zásadě získáte celkem 50 hodnocení CTE, což má za následek 50krát naskenování 1 000 000 řádků z objednávek, jejich seskupení a agregaci. Nezní to jako příliš efektivní řešení. Zde jsou míry výkonu, které jsem získal při provádění tohoto řešení na svém počítači:
trvání:16 sekund, CPU:56 sekund, čtení:130404, zápisy:0Vzhledem k tomu, že se jedná pouze o několik desítek měsíců, bylo by mnohem efektivnější použít dočasnou tabulku k uložení výsledku jediné aktivity, která seskupuje a agreguje řádky z objednávek, a pak má vnější i vnitřní vstupy operátor APPLY interaguje s dočasnou tabulkou. Zde je řešení (nazýváme ho Řešení 10) pomocí dočasné tabulky namísto CTE:
VYBERTE ROK(datum objednávky) JAKO rok objednávky, MĚSÍC (datum objednávky) JAKO měsíc objednávky, COUNT(*) JAKO numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(datum objednávky), MONTH(datum objednávky); VYBERTE O1.rok objednávky, O1.měsíc objednávky, O1.čísla, O2.rok objednávky AS rok objednávky2, O2.měsíc objednávky AS měsíc objednávky2, O2.čísla JAKO čísla2 OD #Počet objednávek JAKO O1 KŘÍŽEM POUŽIJTE ( VYBERTE NAHORU (1) O2.rok objednávky, O2.měsíc objednávky , O2.čísla OD #Počet objednávek JAKO O2 KDE O2.rok objednávky <> O1.rok objednávky NEBO O2.měsíc objednávky <> O1.měsíc objednávky OBJEDNÁVKA PODLE ABS(O1.čísla - O2.čísla), O2.rok objednávky, O2.měsíc objednávky ) JAKO O2; DROP TABLE #OrdCount;Zde nemá smysl indexovat dočasnou tabulku, protože filtr TOP je založen na výpočtu v jeho specifikaci řazení, a proto je řazení nevyhnutelné. Může se však velmi dobře stát, že v jiných případech s jinými řešeními bude pro vás také důležité zvážit indexování dočasných tabulek. V každém případě je plán tohoto řešení znázorněn na obrázku 10.
Obrázek 10:Plány provádění řešení 10
V horním plánu pozorujte, jak těžké zvedání zahrnující skenování 1 000 000 řádků, jejich seskupování a agregování probíhá pouze jednou. Do dočasné tabulky #OrdCount se zapíše 49 řádků a spodní plán pak interaguje s dočasnou tabulkou pro vnější i vnitřní vstupy operátoru Nested Loops, který zpracovává logiku operátoru APPLY.
Zde jsou čísla výkonu, která jsem získal pro provedení tohoto řešení:
trvání:0,392 sekundy, CPU:0,5 sekundy, čtení:3636, zápisy:3Je řádově rychlejší než řešení založené na CTE.
Co bude dál?
V tomto článku jsem začal pokrývat optimalizační úvahy související s CTE. Ukázal jsem, že proces rozkládání/substituce, který probíhá s odvozenými tabulkami, funguje stejně s CTE. Také jsem diskutoval o skutečnosti, že nerekurzivní CTE se neuchovávají, a vysvětlil jsem, že když je persistence důležitým faktorem pro výkon vašeho řešení, musíte to zvládnout sami pomocí nástrojů, jako jsou dočasné tabulky a proměnné tabulky. Příští měsíc budu v diskuzi pokračovat tím, že se budu věnovat dalším aspektům optimalizace CTE.