Čas od času vidím někoho vyjádřit požadavek na vytvoření náhodného čísla pro klíč. Obvykle se jedná o vytvoření nějakého typu náhradního CustomerID nebo UserID, které je jedinečným číslem v určitém rozsahu, ale nevydává se postupně, a je proto mnohem méně uhodnutelné než IDENTITY hodnotu.
NEWID() řeší problém s hádáním, ale trest za výkon obvykle naruší dohodu, zvláště když je seskupený:mnohem širší klíče než celá čísla a rozdělení stránek kvůli nesekvenčním hodnotám. NEWSEQUENTIALID() řeší problém rozdělení stránky, ale stále jde o velmi široký klíč a znovu zavádí problém, že můžete odhadnout další hodnotu (nebo nedávno vydané hodnoty) s určitou úrovní přesnosti.
V důsledku toho chtějí techniku generování náhodných a jedinečné celé číslo. Generování náhodného čísla samo o sobě není obtížné pomocí metod jako RAND() nebo CHECKSUM(NEWID()) . Problém nastává, když musíte detekovat kolize. Pojďme se rychle podívat na typický přístup, za předpokladu, že chceme hodnoty CustomerID mezi 1 a 1 000 000:
DECLARE @rc INT =0, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1; -- nebo ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1; -- nebo CONVERT(INT, RAND() * 1000000) + 1;WHILE @rc =0BEGIN IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID =@CustomerID) BEGIN INSERT dbo.Customers(CustomerID) SELECT @CustomerID; SET @rc =1; KONEC ELSE ZAČÁTEK VYBRAT @ID zákazníka =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @rc =0; ENDEND
Jak se tabulka zvětšuje, nejenže se zdražuje kontrola duplikátů, ale zvyšuje se i vaše šance na vytvoření duplikátu. Takže se může zdát, že tento přístup funguje dobře, když je stůl malý, ale mám podezření, že to časem musí bolet víc a víc.
Jiný přístup
Jsem velkým fanouškem pomocných stolů; O kalendářových tabulkách a tabulkách čísel píšu veřejně už deset let a používám je mnohem déle. A to je případ, kdy si myslím, že předvyplněná tabulka by se mohla opravdu hodit. Proč se spoléhat na generování náhodných čísel za běhu a řešení potenciálních duplikátů, když můžete všechny tyto hodnoty naplnit předem a víte – se 100% jistotou, pokud své tabulky ochráníte před neoprávněným DML – že další hodnota, kterou vyberete, nikdy nebyla používané dříve?
CREATE TABLE dbo.RandomNumbers1( RowID INT, Hodnota INT, --UNIQUE, PRIMÁRNÍ KLÍČ (RowID, Hodnota));;WITH x AS ( SELECT TOP (1000000) s1.[object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id])INSERT dbo.RandomNumbers(RowID, ValueW_NUMBER)(r =ROW_NUMBER) ) OVER (ORDER BY [object_id]), n =ROW_NUMBER() OVER (ORDER BY NEWID())OD xORDER BY r;
Vytvoření této populace trvalo 9 sekund (ve virtuálním počítači na notebooku) a zabíralo přibližně 17 MB na disku. Data v tabulce vypadají takto:
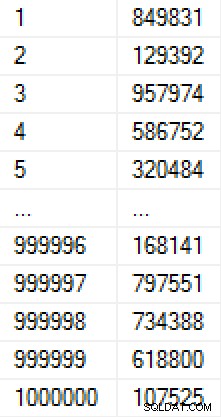
(Pokud bychom se obávali, jak se čísla zaplňují, mohli bychom přidat jedinečné omezení do sloupce Hodnota, díky kterému by tabulka měla velikost 30 MB. Pokud bychom použili kompresi stránky, byla by 11 MB, respektive 25 MB. )
Vytvořil jsem další kopii tabulky a naplnil jsem ji stejnými hodnotami, abych mohl otestovat dvě různé metody odvození další hodnoty:
CREATE TABLE dbo.RandomNumbers2( RowID INT, Hodnota INT, -- UNIKÁTNÍ PRIMÁRNÍ KLÍČ (RowID, Hodnota)); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Nyní, kdykoli budeme chtít nové náhodné číslo, můžeme jedno vyjmout z hromádky existujících čísel a smazat ho. To nám brání v tom, abychom si dělali starosti s duplikáty, a umožňuje nám vytahovat čísla – pomocí seskupeného indexu –, která jsou ve skutečnosti již v náhodném pořadí. (Přísně vzato, nemusíme mazat čísla, jak je používáme; mohli bychom přidat sloupec označující, zda byla hodnota použita – to by usnadnilo obnovení a opětovné použití této hodnoty v případě, že zákazník bude později smazán nebo se něco pokazí mimo tuto transakci, ale ještě předtím, než budou plně vytvořeny.)
DECLARE @holding TABLE(CustomerID INT); DELETE TOP (1) dbo.Náhodná čísla1OUTPUT smazáno.Hodnota INTO @holding; INSERT dbo.Customers(CustomerID, ...další sloupce...) SELECT CustomerID, ...další parametry... FROM @holding;
Použil jsem proměnnou tabulky k uchování mezivýstupu, protože u komposovatelného DML existují různá omezení, která mohou znemožnit vkládání do tabulky Zákazníci přímo z DELETE (například přítomnost cizích klíčů). Přesto, uznávám, že to nebude vždy možné, chtěl jsem také otestovat tuto metodu:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...další parametry... INTO dbo.Customers(CustomerID, ...další sloupce...);
Všimněte si, že žádné z těchto řešení skutečně nezaručuje náhodné pořadí, zejména pokud má tabulka náhodných čísel jiné indexy (například jedinečný index ve sloupci Hodnota). Neexistuje způsob, jak definovat objednávku pro DELETE pomocí TOP; z dokumentace:
Takže pokud chcete zaručit náhodné řazení, můžete místo toho udělat něco takového:
DECLARE @holding TABLE(CustomerID INT);;WITH x AS ( SELECT TOP (1) Value FROM dbo.RandomNumbers2 ORDER BY RowID)DELETE x OUTPUT delete.Value INTO @holding; INSERT dbo.Customers(CustomerID, ...další sloupce...) SELECT CustomerID, ...další parametry... FROM @holding;
Dalším hlediskem je, že pro tyto testy mají tabulky Customers seskupený primární klíč ve sloupci CustomerID; to jistě povede k rozdělení stránek při vkládání náhodných hodnot. V reálném světě, pokud byste měli tento požadavek, pravděpodobně byste skončili shlukování na jiném sloupci.
Všimněte si, že jsem zde také vynechal transakce a zpracování chyb, ale i ty by měly být v produkčním kódu zohledněny.
Testování výkonu
Abych nakreslil realistická srovnání výkonu, vytvořil jsem pět uložených procedur, které představují následující scénáře (rychlost testování, distribuce a frekvence kolizí různých náhodných metod a také rychlost použití předdefinované tabulky náhodných čísel):
- Generování runtime pomocí
CHECKSUM(NEWID()) - Generování runtime pomocí
CRYPT_GEN_RANDOM() - Generování runtime pomocí
RAND() - Předdefinovaná tabulka čísel s proměnnou tabulky
- Předdefinovaná tabulka čísel s přímým vkládáním
Ke sledování trvání a počtu kolizí používají protokolovací tabulku:
CREATE TABLE dbo.CustomerLog( LogID INT IDENTITY(1,1) PRIMÁRNÍ KLÍČ, pid INT, kolize INT, trvání INT -- mikrosekundy);
Následuje kód procedur (kliknutím zobrazíte/skryjete):
/* Runtime pomocí CHECKSUM(NEWID()) */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 ZAČNĚTE, POKUD NEEXISTUJE ( SELECT 1 FROM dbo.Customers_Runtime_Checksum WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID; SET @rc =1; KONEC ELSE ZAČÁTEK VYBRAT @ID zákazníka =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @kolize +=1, @rc =0; END END SELECT @duration =DATEDIFF(MIKROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kolize, trvání) SELECT 1, @kolize, @duration;ENDGO /* runtime using CRYPT_GEN_RANDOM() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 ZAČÁTE, POKUD NEEXISTUJE ( SELECT 1 FROM dbo.Customers_Runtime_CryptGen WHERE CustomerID =@CustomerID ) ZAČNĚTE INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @duration =DATEDIFF(MIKROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kolize, trvání) SELECT 2, @kolize, @trvání;ENDGO /* runtime pomocí RAND() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =CONVERT(INT, RAND() * 1000000) + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 ZAČNĚTE, POKUD NEEXISTUJE ( SELECT 1 FROM dbo.Customers_Runtime_Rand WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =CONVERT(INT, RAND() * 1000000) + 1, @kolize +=1, @rc =0; END END SELECT @duration =DATEDIFF(MIKROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, kolize, trvání) SELECT 3, @kolize, @trvání;ENDGO /* předdefinováno pomocí proměnné tabulky */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; DECLARE @holding TABLE(CustomerID INT); DELETE TOP (1) dbo.RandomNumbers1 VÝSTUP smazán.Hodnota INTO @holding; INSERT dbo.Customers_Predefined_TableVariable(CustomerID) SELECT CustomerID FROM @holding; SELECT @trvání =DATEDIFF(MIKROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, trvání) SELECT 4, @duration;ENDGO /* předdefinováno pomocí přímého vložení */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]ASBEGIN SET NOCOUNT ON; DECLARE @start DATETIME2(7) =SYSDATETIME(), @duration INT; DELETE TOP (1) dbo.RandomNumbers2 VÝSTUP odstraněn.Hodnota INTO dbo.Customers_Predefined_Direct; SELECT @trvání =DATEDIFF(MIKROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, trvání) SELECT 5, @duration;ENDGO
A abych to otestoval, spustil bych každou uloženou proceduru 1 000 000krát:
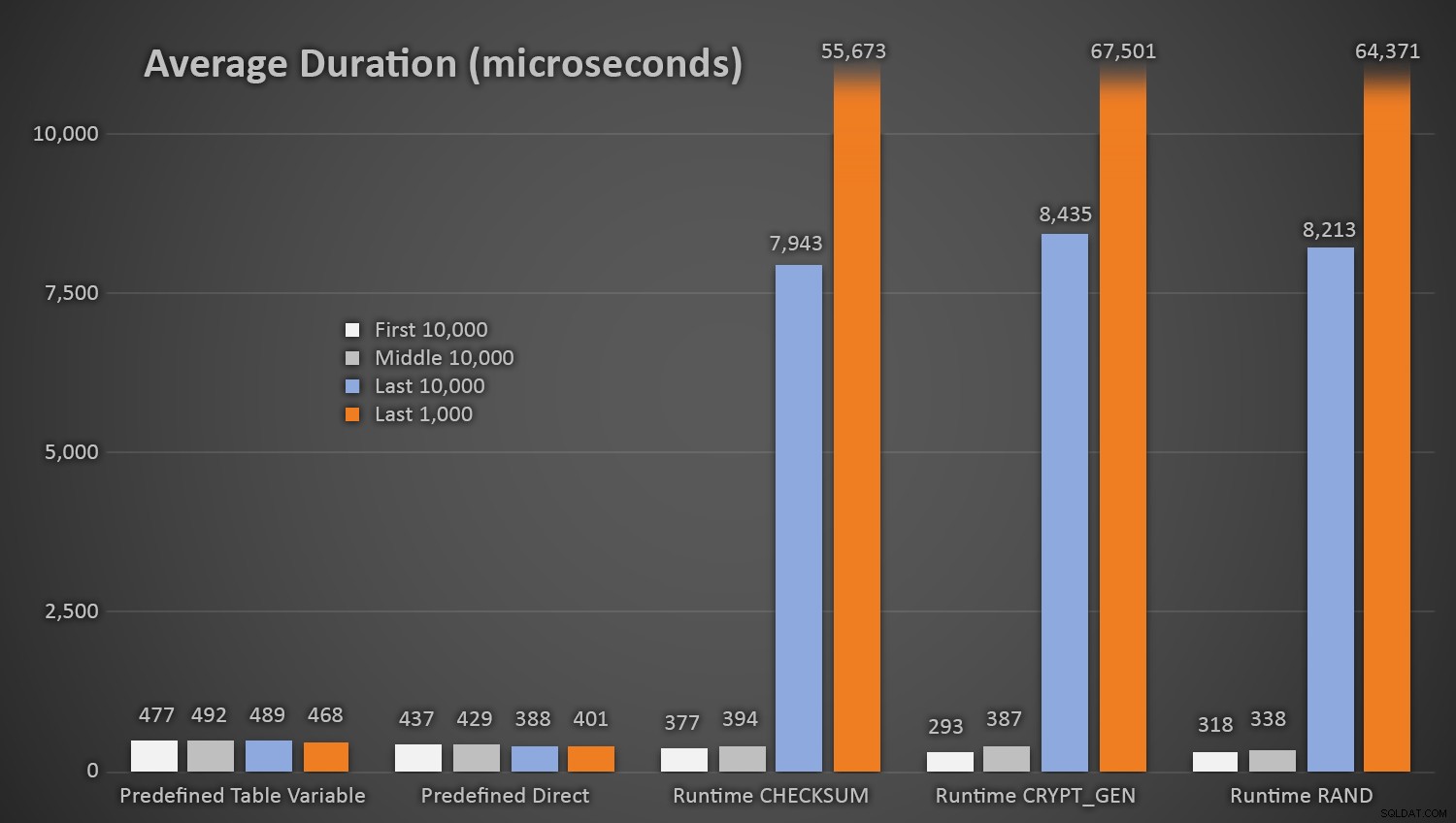
EXEC dbo.AddCustomer_Runtime_Checksum;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;AddCustomer;dgoD_0.0Není překvapením, že metody využívající předdefinovanou tabulku náhodných čísel trvaly *na začátku testu* o něco déle, protože musely pokaždé provádět I/O čtení i zápis. Mějte na paměti, že tato čísla jsou v mikrosekundách , zde jsou průměrné doby trvání pro každý postup v různých intervalech na cestě (průměr za prvních 10 000 poprav, prostředních 10 000 poprav, posledních 10 000 poprav a posledních 1000 poprav):
Průměrná doba trvání (v mikrosekundách) náhodného generování pomocí různých přístupůTo funguje dobře pro všechny metody, když je v tabulce Zákazníci málo řádků, ale jak se tabulka zvětšuje a zvětšuje, náklady na kontrolu nového náhodného čísla oproti stávajícím datům pomocí runtime metod se podstatně zvyšují, a to jak kvůli zvýšenému I /O a také proto, že počet kolizí stoupá (což vás nutí zkoušet to znovu). Porovnejte průměrnou dobu trvání v následujících rozsazích počtu kolizí (a pamatujte, že tento vzor ovlivní pouze běhové metody):
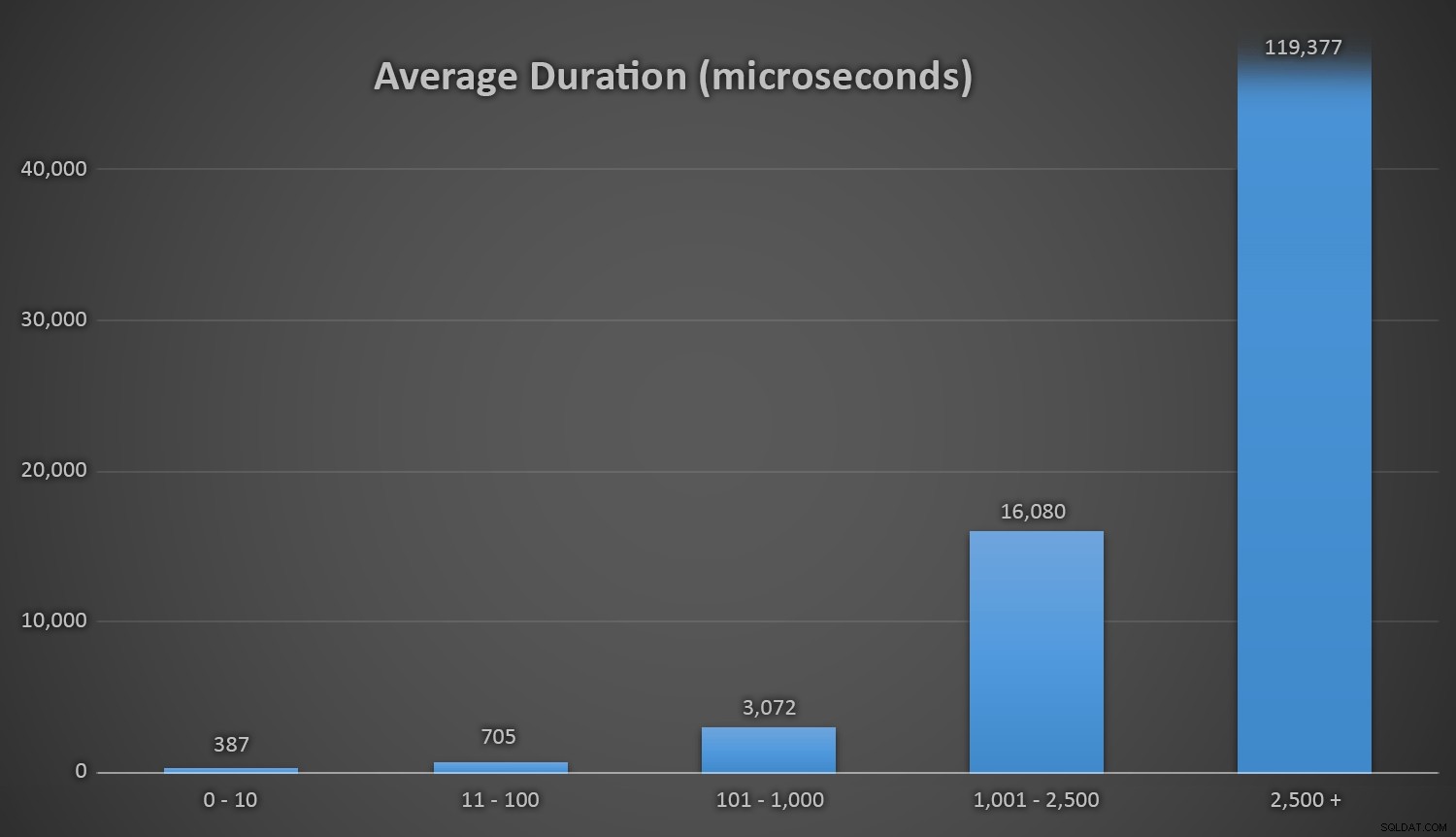
Průměrná doba trvání (v mikrosekundách) během různých rozsahů kolizíPřál bych si, aby existoval jednoduchý způsob, jak zobrazit graf trvání proti počtu kolizí. Nechám vás s touto lahůdkou:na posledních třech insertech musely následující runtime metody provést tolik pokusů, než konečně narazily na poslední jedinečné ID, které hledaly, a takhle dlouho to trvalo:
| Počet kolizí | Trvání (mikrosekundy) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 3. až poslední řádek | 63 545 | 639 358 |
| 2. až poslední řádek | 164 807 | 1 605 695 | |
| Poslední řádek | 30 630 | 296 207 | |
| CRYPT_GEN_RANDOM() | 3. až poslední řádek | 219 766 | 2 229 166 |
| 2. až poslední řádek | 255 463 | 2 681 468 | |
| Poslední řádek | 136 342 | 1 434 725 | |
| RAND() | 3. až poslední řádek | 129 764 | 1 215 994 |
| 2. až poslední řádek | 220 195 | 2 088 992 | |
| Poslední řádek | 440 765 | 4 161 925 | |
Příliš dlouhé trvání a kolize na konci řádku
Je zajímavé poznamenat, že poslední řádek není vždy ten, který přináší nejvyšší počet kolizí, takže to může začít být skutečný problém dlouho předtím, než spotřebujete více než 999 000 hodnot.
Další úvaha
Možná budete chtít zvážit nastavení nějakého druhu výstrahy nebo upozornění, když se tabulka RandomNumbers začne dostávat pod určitý počet řádků (v tomto okamžiku můžete tabulku znovu naplnit novou sadou například 1 000 001 – 2 000 000). Něco podobného byste museli udělat, pokud byste generovali náhodná čísla za chodu – pokud to udržujete v rozsahu 1 – 1 000 000, pak byste museli změnit kód tak, aby generoval čísla z jiného rozsahu, jakmile spotřeboval jsem všechny tyto hodnoty.
Pokud používáte metodu náhodného čísla za běhu, můžete se této situaci vyhnout neustálou změnou velikosti fondu, ze kterého náhodné číslo losujete (což by také mělo stabilizovat a výrazně snížit počet kolizí). Například místo:
DECLARE @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Fond můžete založit na počtu řádků již v tabulce:
DECLARE @total INT =1000000 + ISNULL( (SELECT SUM(počet_řádků) FROM sys.dm_db_partition_stats WHERE [id_objektu] =OBJECT_ID('dbo.Customers') AND index_id =1),0);
Nyní máte jedinou skutečnou starost, když se přiblížíte k horní hranici INT …
Poznámka:Nedávno jsem o tom také napsal tip na MSSQLTips.com.