Krátce jsem zmínil, že data v dávkovém režimu jsou normalizována v mém posledním článku Bitmapy v dávkovém režimu na serveru SQL. Všechna data v dávce jsou reprezentována osmibajtovou hodnotou v tomto konkrétním normalizovaném formátu, bez ohledu na základní datový typ.
Toto prohlášení bezpochyby vyvolává některé otázky, v neposlední řadě o tom, jak mohou být data o délce mnohem větší než osm bajtů uložena tímto způsobem. Tento článek se zabývá normalizovanou reprezentací dávkových dat, vysvětluje, proč se ne všechny osmibajtové datové typy vejdou do 64 bitů, a ukazuje příklad, jak to vše ovlivňuje výkon dávkového režimu.
Ukázka
Začnu příkladem, který ukazuje dávkový formát dat, který je důležitým rozdílem v prováděcím plánu. K reprodukci zde uvedených výsledků budete potřebovat SQL Server 2016 (nebo novější) a Developer Edition (nebo ekvivalent).
První věc, kterou budeme potřebovat, je tabulka bigint čísla od 1 do 102 400 včetně. Tato čísla budou brzy použita k naplnění tabulky columnstore (počet řádků je minimum potřebné k získání jednoho komprimovaného segmentu).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Úspěšné rozšíření souhrnu
Následující skript používá tabulku čísel k vytvoření další tabulky obsahující stejná čísla posunutá o určitou hodnotu. Tato tabulka používá pro své primární úložiště columnstore, aby bylo možné později provést spuštění v dávkovém režimu.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Spusťte následující testovací dotazy pro novou tabulku columnstore:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Přidání uvnitř SUM je zabránit přetečení. WHERE můžete přeskočit klauzule (abyste se vyhnuli triviálnímu plánu), pokud používáte SQL Server 2017.
Všechny tyto dotazy těží z agregovaného rozšíření dolů. Agregát se vypočítá na Columnstore Index Scan spíše než v dávkovém režimu Hash Aggregate operátor. Plány po provedení ukazují nula řádků emitovaných skenováním. Všech 102 400 řádků bylo „místně agregováno“.
SUM plán je uveden níže jako příklad:

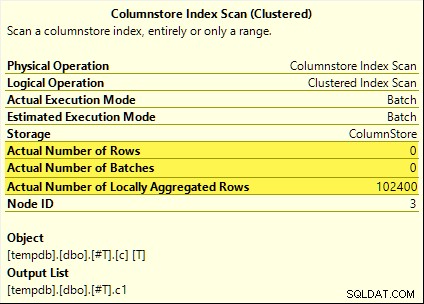
Neúspěšné rozšíření souhrnu
Nyní pusťte a znovu vytvořte testovací tabulku columnstore s offsetem zmenšeným o jedna:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Spusťte přesně stejné agregované dotazy na test rozšíření jako dříve:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Tentokrát pouze COUNT_BIG agregace dosáhne agregovaného snížení (pouze SQL Server 2017). MAX a SUM agregáty ne. Zde je nový SUM plán pro srovnání s tím z prvního testu:

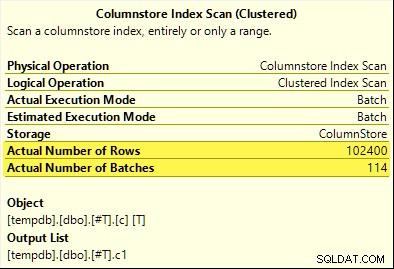
Všech 102 400 řádků (ve 114 dávkách) je vygenerováno Columnstore Index Scan , zpracováno Výpočetním skalárem a odeslány do Hash Aggregate .
Proč ten rozdíl? Vše, co jsme udělali, bylo vyrovnat rozsah čísel uložených v tabulce columnstore o jednu!
Vysvětlení
V úvodu jsem zmínil, že ne všechny osmibajtové datové typy se vejdou do 64 bitů. Tato skutečnost je důležitá protože mnoho optimalizací výkonu columnstore a dávkového režimu pracuje pouze s daty o velikosti 64 bitů. Agregátní snížení je jednou z těchto věcí. Existuje mnoho dalších funkcí výkonu (ne všechny zdokumentované), které fungují nejlépe (nebo vůbec) pouze tehdy, když se data vejdou do 64 bitů.
V našem konkrétním příkladu je agregované rozšíření dolů deaktivováno pro segment columnstore, pokud obsahuje sudy jeden datová hodnota, která se nevejde do 64 bitů. SQL Server to může určit z minimální a maximální hodnoty metadat spojených s každým segmentem bez kontroly všech dat. Každý segment je hodnocen samostatně.
Agregátní rozšíření stále funguje pro COUNT_BIG agregát až ve druhém testu. Toto je optimalizace přidaná v určitém okamžiku v SQL Server 2017 (moje testy byly spuštěny na CU16). Je logické nezakázat agregované rozšíření, když počítáme pouze řádky a neděláme nic s konkrétními hodnotami dat. Nemohl jsem najít žádnou dokumentaci pro toto vylepšení, ale to není v dnešní době tak neobvyklé.
Jako vedlejší poznámku jsem si všiml, že SQL Server 2017 CU16 umožňuje agregované rozšíření pro dříve nepodporované datové typy real , float , datetimeoffset a numeric s přesností větší než 18 — když se data vejdou do 64 bitů. To také není v době psaní tohoto článku zdokumentováno.
Dobře, ale proč?
Možná se ptáte na velmi rozumnou otázku:Proč je jedna sada bigint testovací hodnoty se zjevně vejdou do 64 bitů, ale ostatní ne?
Pokud jste uhodli, že důvod souvisí s NULL , dej si klíště. I když je sloupec testovací tabulky definován jako NOT NULL , SQL Server používá stejné rozložení normalizovaných dat pro bigint zda data umožňují nuly nebo ne. Má to své důvody, které rozbalím kousek po kousku.
Dovolte mi začít několika postřehy:
- Každá hodnota sloupce v dávce je uložena v přesně osmi bytech (64 bitech) bez ohledu na základní datový typ. Toto rozložení s pevnou velikostí vše usnadňuje a urychluje. Spouštění v dávkovém režimu je o rychlosti.
- Šarže má velikost 64 kB a obsahuje 64 až 900 řádků v závislosti na počtu promítaných sloupců. To dává smysl vzhledem k tomu, že velikost dat sloupců je pevně nastavena na 64 bitů. Více sloupců znamená, že se do každé 64kB dávky vejde méně řádků.
- Ne všechny datové typy SQL Serveru se vejdou do 64 bitů, a to ani v principu. Dlouhý řetězec (abych uvedl jeden příklad) by se možná ani nevešel do celé 64kB dávky (pokud by to bylo povoleno), natož do jediné 64bitové položky.
SQL Server řeší tento poslední problém uložením 8bajtového odkazu na data větší než 64 bitů. „Velká“ datová hodnota je uložena jinde v paměti. Toto uspořádání můžete nazvat „mimořádkové“ nebo „mimodávkové“ úložiště. Interně se označuje jako hluboká data .
Osmibajtové datové typy se nyní nemohou vejít do 64 bitů, pokud lze použít hodnotu Null. Vezměte bigint NULL například . Nenulový datový rozsah může vyžadovat celých 64 bitů a my stále potřebujeme další bit, abychom označili hodnotu null nebo ne.
Řešení problémů
Kreativním a efektivním řešením těchto výzev je rezervace nejnižšího významného bitu (LSB) 64bitové hodnoty jako příznak. Příznak označuje v dávce úložiště dat, když je LSB prázdný (nastaveno na nulu). Když je LSB nastaveno (k jedné), může to znamenat jednu ze dvou věcí:
- Hodnota je null; nebo
- Hodnota je uložena mimo dávku (jedná se o hluboká data).
Tyto dva případy se odlišují stavem zbývajících 63 bitů. Když jsou všichni nula , hodnota je NULL . Jinak je „hodnota“ ukazatelem na hluboká data uložená jinde.
Při zobrazení jako celé číslo znamená nastavení LSB, že ukazatele na hluboká data budou vždy liché čísla. Nuly jsou reprezentovány (lichým) číslem 1 (všechny ostatní bity jsou nula). Data v dávce jsou reprezentována sudým čísla, protože LSB je nula.
To není znamená, že SQL Server může ukládat pouze sudá čísla v rámci dávky! Znamená to pouze, že normalizovaná reprezentace Hodnoty základního sloupce budou mít vždy nulovou hodnotu LSB, když jsou uloženy „in-batch“. Za chvíli to bude dávat větší smysl.
Dávková normalizace dat
Normalizace se provádí různými způsoby v závislosti na základním datovém typu. Pro bigint proces je:
- Pokud jsou data null , uložte hodnotu 1 (pouze nastaveno LSB).
- Pokud lze hodnotu vyjádřit v 63 bitech , posuňte všechny bity o jedno místo doleva a vynulujte LSB. Při pohledu na hodnotu jako na celé číslo to znamená zdvojnásobení hodnota. Například
biginthodnota 1 je normalizována na hodnotu 2. V binární podobě, tedy sedm nulových bajtů následovaných00000010. Hodnota LSB nula znamená, že se jedná o data uložená inline. Když SQL Server potřebuje původní hodnotu, posune 64bitovou hodnotu doprava o jednu pozici (vyhodí příznak LSB). - Pokud hodnota nelze být reprezentován v 63 bitech, hodnota je uložena mimo dávku jako hluboká data . Ukazatel v dávce má nastaveno LSB (což je liché číslo).
Proces testování, zda je bigint hodnota, která se vejde do 63 bitů, je:
- Uložte nezpracovaný*
biginthodnotu v registru 64bitového procesorur8. - Uložte dvojnásobnou hodnotu
r8v registrurax. - Posunout bity
raxo jedno místo vpravo. - Otestujte, zda jsou hodnoty v
raxar8jsou si rovni.
* Upozorňujeme, že nezpracovanou hodnotu nelze spolehlivě určit pro všechny datové typy převodem T-SQL na binární typ. Výsledek T-SQL může mít jiné pořadí bajtů a může obsahovat i metadata, např. time přesnost na zlomek sekund.
Pokud test v kroku 4 projde, víme, že hodnotu lze zdvojnásobit a poté snížit na polovinu v rámci 64 bitů – při zachování původní hodnoty.
Snížený rozsah
Výsledkem toho všeho je, že rozsah bigint hodnoty, které lze uložit v dávce, se sníží o jeden bit (protože LSB není k dispozici). Následující včetně rozsahů bigint hodnoty budou uloženy mimo dávku jako hluboká data :
- -4,611,686,018,427,387,905 až -9,223,372,036,854,775,808
- +4,611,686,018,427,387,904 až +9,223,372,036,854,775,807
Na oplátku za souhlas s tím, že tyto bigint omezení rozsahu, normalizace umožňuje SQL Serveru ukládat (většinu) bigint hodnoty, hodnoty null a podrobné datové odkazy v dávce . Je to mnohem jednodušší a prostorově efektivnější než mít samostatné struktury pro možnost nullability a hluboké datové odkazy. Také to značně usnadňuje zpracování dávkových dat pomocí instrukcí procesoru SIMD.
Normalizace jiných datových typů
SQL Server obsahuje normalizaci kód pro každý z datových typů podporovaných prováděním v dávkovém režimu. Každá rutina je optimalizována tak, aby efektivně zvládla příchozí binární rozložení a pouze v případě potřeby vytvářela hluboká data. Normalizace vždy vede k tomu, že LSB je vyhrazeno pro indikaci nulových nebo hlubokých dat, ale rozložení zbývajících 63 bitů se liší podle typu dat.
Vždy v dávce
Normalizovaná data pro následující typy dat se vždy ukládají v dávce protože nikdy nepotřebují více než 63 bitů:
datetime(n)– interně změněno natime(7)datetime2(n)– interně změněno nadatetime2(7)integersmallinttinyintbit– používátinyintimplementace.smalldatetimedatetimerealfloatsmallmoney
Záleží
Následující typy dat mohou být uloženy v dávce nebo hloubková data v závislosti na hodnotě dat:
bigint– jak bylo popsáno dříve.money– stejný rozsah v dávce jakobigintale děleno 10 000.numeric/decimal– 18 desetinných číslic nebo méně v dávce bez ohledu deklarované přesnosti. Napříkladdecimal(38,9)hodnotu -999999999,999999999 lze vyjádřit jako 8bajtové celé číslo -999999999999999999 (f21f494c589c0001hex), který lze zdvojnásobit na -1999999999999999998 (e43e9298b1380002hex) reverzibilně v rámci 64 bitů. SQL Server ví, kam jde desetinná čárka ze stupnice datového typu.datetimeoffset(n)– v dávce, pokud je hodnota za běhu se vejde dodatetimeoffset(2)bez ohledu s deklarovanou přesností ve zlomcích sekund.timestamp– interní formát se liší od zobrazení. Napříkladtimestampzobrazeno z T-SQL jako0x000000000099449Aje interně reprezentováno jako9a449900 00000000(v hex). Tato hodnota je uložena jako hluboká data, protože se po zdvojnásobení nevejde do 64bitů (o jeden bit posunuta doleva).
Vždy hluboká data
Následující údaje jsou vždy uloženy jako hluboká data (kromě hodnot null) :
uniqueidentifiervarbinary(n)– včetně(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnamevčetně(max)– tyto typy mohou také používat slovník (pokud je k dispozici).text/ntext/image/xml– používávarbinary(n)implementace.
Aby bylo jasno, vše má hodnotu null Datové typy kompatibilní s dávkovým režimem se ukládají v dávce jako speciální hodnota ‚one‘.
Závěrečné myšlenky
Při použití datových typů a hodnot, které se vejdou do 64 bitů, můžete očekávat to nejlepší z dostupných optimalizací pro ukládání sloupců a dávkový režim. Budete mít také největší šanci těžit z postupných vylepšení produktu v průběhu času, například nejnovějších vylepšení agregovaného snížení uvedených v hlavním textu. Ne všechny výhody výkonu budou tak viditelné v prováděcích plánech nebo dokonce zdokumentované. Nicméně rozdíly mohou být extrémně významné.
Měl bych také zmínit, že data jsou normalizována, když operátor plánu provádění v režimu řádků poskytuje data nadřazenému v dávkovém režimu nebo když skenování bez úložiště sloupců vytváří dávky (dávkový režim na úložišti řádků). Existuje neviditelný adaptér typu řádek na dávku, který před přidáním do dávky zavolá příslušnou normalizační rutinu pro každou hodnotu sloupce. Vyhýbání se datovým typům s komplikovanou normalizací a hlubokým ukládáním dat může i zde přinést výkonnostní výhody.