V mém posledním příspěvku ("Ty vole, kdo vlastní tu #temp tabulku?") jsem navrhl, že v SQL Server 2012 a novějších byste mohli použít Extended Events ke sledování vytváření #temp tabulek. To by vám umožnilo korelovat konkrétní objekty zabírající velké množství místa v databázi tempdb s relací, která je vytvořila (například určit, zda lze relaci zabít, abyste se pokusili uvolnit místo). O čem jsem nemluvil, je režie tohoto sledování – očekáváme, že Extended Events budou lehčí než sledování, ale žádné monitorování není zcela zdarma.
Protože většina lidí nechává výchozí trasování povolené, necháme to na místě. Obě hromady otestujeme pomocí SELECT INTO (které výchozí trasování nebude shromažďovat) a seskupené indexy (což bude) a načasujeme dávku samotnou jako základní linii a poté dávku spustíme znovu se spuštěnou relací Extended Events. Budeme také testovat proti SQL Server 2012 a SQL Server 2014. Samotná dávka je docela jednoduchá:
SET NOCOUNT ON; SELECT SYSDATETIME();GO -- spusťte tuto část pouze pro dávku haldy:SELECT TOP (100) [id_objektu] INTO #foo FROM sys.all_objects ORDER BY [id_objektu];DROP TABLE #foo; -- spusťte tuto část pouze pro dávku CIX:CREATE TABLE #bar(id INT PRIMÁRNÍ KLÍČ);INSERT #bar(id) SELECT TOP (100) [id_objektu] FROM sys.all_objects ORDER BY [id_objektu];DROP TABLE #bar; GO 100000 SELECT SYSDATETIME();
Obě instance mají tempdb nakonfigurovanou se čtyřmi datovými soubory a povolenými TF 1117 a TF 1118 ve virtuálním počítači se čtyřmi CPU, 16 GB paměti a pouze SSD. Záměrně jsem vytvořil malé #temp tabulky, abych zesílil jakýkoli pozorovaný dopad na samotnou dávku (což by se utopilo, pokud by vytváření tabulek #temp trvalo dlouho nebo způsobilo nadměrné události automatického růstu).
Spustil jsem tyto dávky v každém scénáři a zde jsou výsledky měřené v trvání dávky v sekundách:
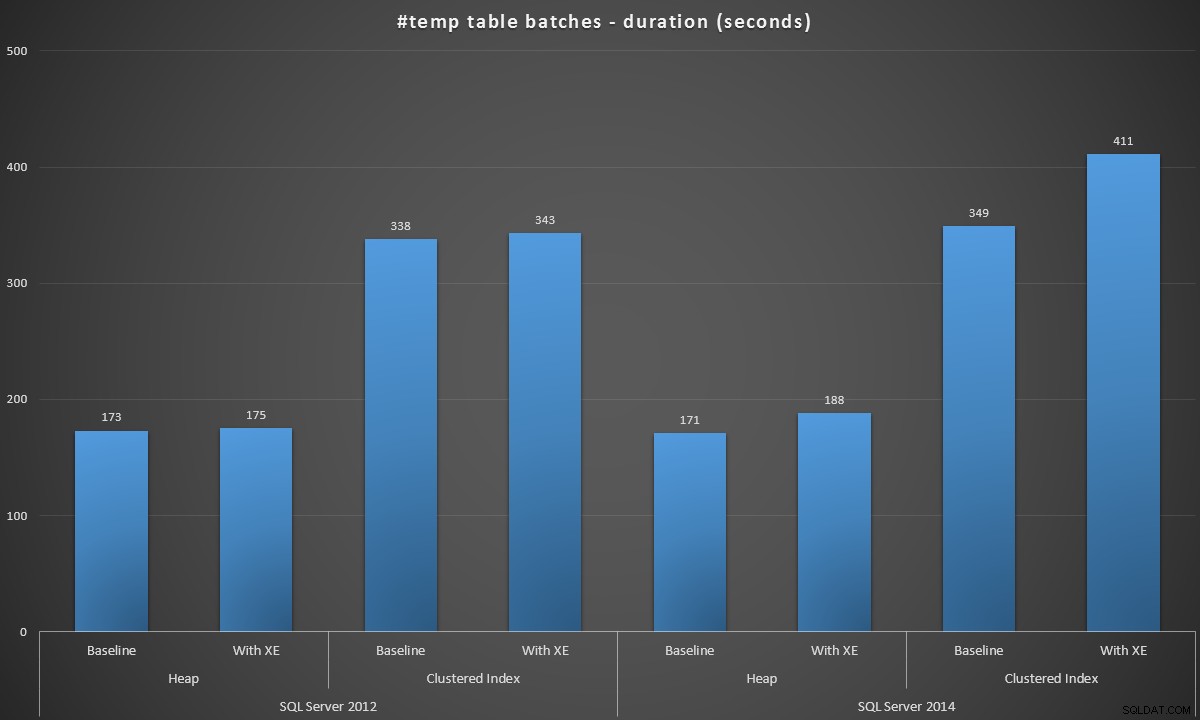
Trvání dávky v sekundách pro vytvoření 100 000 #temp tabulek
Vyjádříme-li data trochu jinak, vydělíme-li 100 000 délkou trvání, můžeme ukázat počet #temp tabulek, které můžeme vytvořit za sekundu v každém scénáři (čti:propustnost). Zde jsou tyto výsledky:
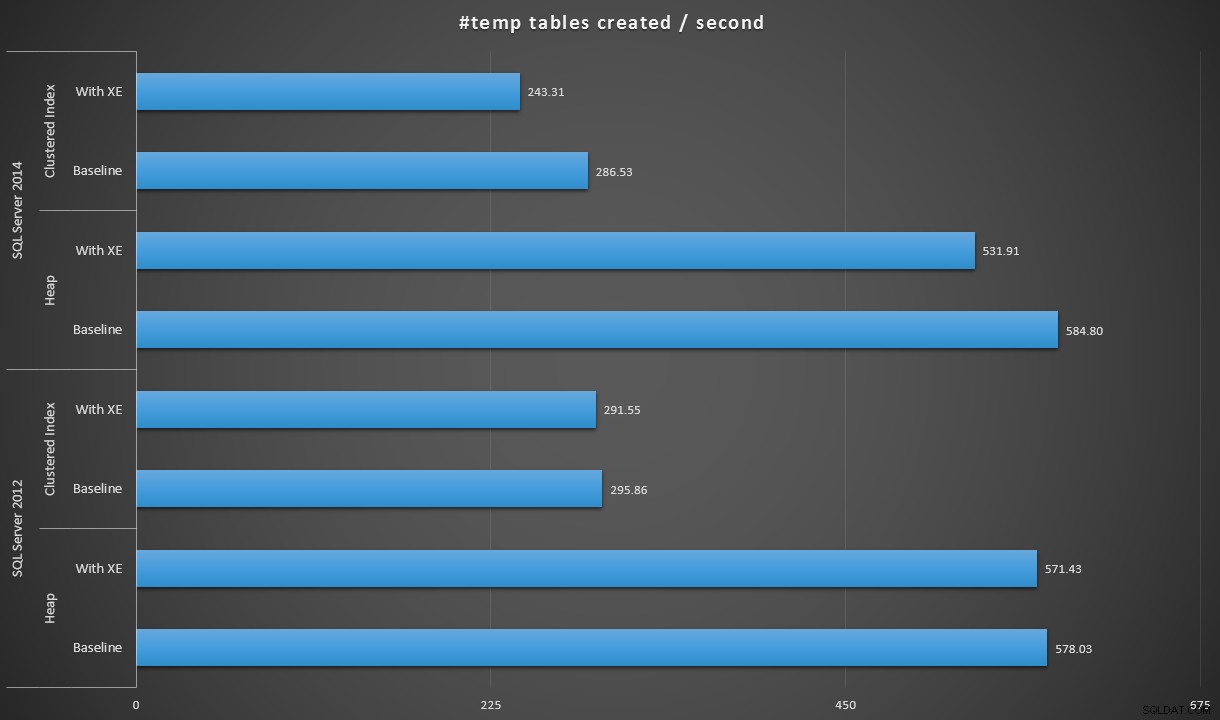
#temp tabulky vytvořené za sekundu v každém scénáři
Výsledky pro mě byly trochu překvapivé – očekával jsem, že díky vylepšením logiky horlivého zápisu SQL Server 2014 bude populace haldy běžet přinejmenším mnohem rychleji. Hromada v roce 2014 byla o dvě sekundy rychlejší než v roce 2012 při základní konfiguraci, ale Extended Events čas dost navýšily (zhruba 10% nárůst oproti základní hodnotě); zatímco doba seskupeného indexu byla srovnatelná s rokem 2012 na základní úrovni, ale vzrostla téměř o 18 % s povolenými rozšířenými událostmi. V roce 2012 byly delty pro haldy a seskupené indexy mnohem skromnější – 1,1 % a 1,5 %. (A aby bylo jasno, během žádného z testů nedošlo k žádným událostem autogrow.)
Tak mě napadlo, co kdybych vytvořil štíhlejší a méněcennou relaci Extended Events? Některé z těchto sloupců akcí bych určitě mohl odstranit – možná potřebuji pouze přihlašovací jméno a spid a mohu ignorovat název aplikace, název hostitele a potenciálně drahý sql_text. Možná bych mohl upustit od dalšího filtru proti odevzdání (shromažďování dvakrát tolik událostí, ale méně CPU vynaložené na filtrování) a umožnit ztrátu více událostí, aby se snížil potenciální dopad na pracovní zátěž. Tato štíhlejší relace vypadá takto:
VYTVOŘIT RELACI UDÁLOSTI [TempTableCreation2014_LeanerMeaner] NA SERVER PŘIDAT UDÁLOST sqlserver.object_created( ACTION ( sqlserver.server_principal_name, sqlserver.session_id ) WHERE ( sqlserver.like_session_id ) WHERE ( sqlserver.like_package_i_uction%TARG) package_0. ( SET FILENAME ='c:\temp\TempTableCreation2014_LeanerMeaner.xel', MAX_FILE_SIZE =32 768, MAX_ROLLOVER_FILES =10)WITH ( EVENT_RETENTION_MODE =ONa ALLOW_MULTIPLE_EVable> ALLOW_MULTIPLE_EVable> 0 Me;Bohužel ne, stejné výsledky. Něco málo přes tři minuty pro haldu a těsně pod sedm minut pro seskupený index. Abych se hlouběji ponořil do toho, kde se trávil čas navíc, sledoval jsem instanci 2014 s SQL Sentry a spustil jsem pouze dávku clusterovaného indexu bez nakonfigurovaných relací Extended Events. Poté jsem dávku spustil znovu, tentokrát s nakonfigurovanou lehčí XE relací. Časy dávek byly 5:47 (347 sekund) a 6:55 (415 sekund) – tedy hodně v souladu s předchozí dávkou (s radostí jsem viděl, že naše sledování nepřispělo dále k trvání :-)) . Ověřil jsem, že nebyly vypuštěny žádné události a znovu, že nenastaly žádné události automatického růstu.
Podíval jsem se na řídicí panel SQL Sentry v režimu historie, což mi umožnilo rychle zobrazit metriky výkonu obou dávek vedle sebe:
Hlavní panel SQL Sentry, v režimu historie, zobrazující obě dávkyObě dávky byly prakticky identické, pokud jde o síť, CPU, transakce, kompilace, vyhledávání klíčů atd. Existuje určitý mírný rozdíl v čekání – špičky během první dávky byly výhradně WRITELOG, zatímco v druhá várka. Moje pracovní teorie dlouho po půlnoci je, že možná velká část pozorovaného zpoždění byla způsobena přepínáním kontextu způsobeným procesem Extended Events. Protože nemáme žádný přehled o tom, co přesně XE dělá pod pokličkou, ani nevíme, jaké základní mechaniky se v XE mezi lety 2012 a 2014 změnily, je to příběh, kterého se zatím budu držet, dokud nebudu pohodlnější s xperf a/nebo WinDbg.
Závěr
V každém případě je jasné, že sledování vytváření #temp tabulky není zdarma a cena se může lišit v závislosti na typu #temp tabulek, které vytváříte, množství informací, které shromažďujete ve svých relacích XE, a dokonce i na verzi SQL Server, který používáte. Můžete tedy provést podobné testy, jaké jsem provedl zde, a rozhodnout, jak cenné je shromažďování těchto informací ve vašem prostředí.