Tento článek je pátou částí série o chybách, úskalích a osvědčených postupech T-SQL. Dříve jsem se zabýval determinismem, poddotazy, spojeními a vytvářením oken. Tento měsíc pokrývám pivotování a unpivoting. Díky Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Miloš Radivojevič, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man a Paul White za sdílení vašich návrhů!
Ve svých příkladech použiji ukázkovou databázi s názvem TSQLV5. Skript, který vytváří a naplňuje tuto databázi, najdete zde a její ER diagram zde.
Implicitní seskupování pomocí PIVOT
Když lidé chtějí pivotovat data pomocí T-SQL, použijí buď standardní řešení se seskupeným dotazem a CASE výrazy, nebo proprietární operátor PIVOT tabulky. Hlavní výhodou operátora PIVOT je, že má tendenci vést ke kratšímu kódu. Tento operátor má však několik nedostatků, mezi které patří neodmyslitelná past na design, která může mít za následek chyby ve vašem kódu. Zde popíšu past, potenciální chybu a osvědčený postup, který této chybě zabrání. Popíšu také návrh na vylepšení syntaxe operátoru PIVOT způsobem, který pomůže vyhnout se chybě.
Při pivotování dat jsou v řešení zahrnuty tři kroky se třemi přidruženými prvky:
- Seskupit na základě prvku seskupení/na řádcích
- Rozpětí založené na prvku spreading/on cols
- Agregovat na základě agregačního/datového prvku
Následuje syntaxe operátoru PIVOT:
SELECTFROM PIVOT( ( ) FOR IN( ) ) AS ;
Návrh operátoru PIVOT vyžaduje, abyste explicitně specifikovali prvky agregace a šíření, ale umožňuje serveru SQL Server implicitně zjistit prvek seskupení eliminací. Bez ohledu na to, které sloupce se objeví ve zdrojové tabulce, která je poskytnuta jako vstup operátoru PIVOT, stanou se implicitně prvkem seskupení.
Předpokládejme například, že se chcete dotazovat na tabulku Sales.Orders ve vzorové databázi TSQLV5. Chcete vracet ID odesílatelů na řádcích, dodané roky na sloupcích a počet objednávek na odesílatele a rok jako souhrn.
Mnoho lidí má problém zjistit syntaxi operátora PIVOT, což často vede k seskupování dat podle nežádoucích prvků. Jako příklad naší úlohy předpokládejme, že si neuvědomujete, že prvek seskupení je určen implicitně, a přijdete s následujícím dotazem:
SELECT shipperid, [2017], [2018], [2019]FROM Sales. Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT(COUNT(shippeddate) FOR shipyear IN([2017]) , [2018], [2019]) ) AS P;
V datech jsou pouze tři odesílatelé s ID odesílatele 1, 2 a 3. Očekáváte tedy, že ve výsledku uvidíte pouze tři řádky. Skutečný výstup dotazu však zobrazuje mnohem více řádků:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 1 0 01 1 0 02 1 0 01 1 0 02 1 0 02 1 0 02 1 0 03 1 0 02 1 0 03 1 0 0...3 0 1 03 0 1 03 0 1 03 0 0 1 03 0 0 01 0 1 03 0 1 03 0 1 03 0 1 01 0 1 0...3 0 0 11 0 0 12 0 0 11 0 0 12 0 0 11 0 0 13 0 0 13 0 0 12 0 1 0...(830 dotčených řádků)
Co se stalo?
Nápovědu, která vám pomůže odhalit chybu v kódu, najdete v plánu dotazů na obrázku 1.
 Obrázek 1:Plán pro pivotní dotaz s implicitním seskupením
Obrázek 1:Plán pro pivotní dotaz s implicitním seskupením
Nenechte se zmást použitím operátoru CROSS APPLY s klauzulí VALUES v dotazu. To se provádí jednoduše pro výpočet výsledného sloupce shippedyear na základě sloupce source shippeddate a je zpracováno prvním operátorem Compute Scalar v plánu.
Vstupní tabulka pro operátor PIVOT obsahuje všechny sloupce z tabulky Sales.Orders plus sloupec výsledků shippedyear. Jak bylo zmíněno, SQL Server určuje prvek seskupení implicitně eliminací na základě toho, co jste neurčili jako prvky agregace (shippeddate) a šíření (shippedyear). Možná jste intuitivně očekávali, že sloupec shipperid bude sloupcem seskupení, protože se objevuje v seznamu SELECT, ale jak můžete vidět v plánu, v praxi jste získali mnohem delší seznam sloupců, včetně orderid, což je sloupec primárního klíče v zdrojovou tabulku. To znamená, že místo toho, abyste získali řádek na odesílatele, získáte řádek na objednávku. Vzhledem k tomu, že jste v seznamu SELECT zadali pouze sloupce shipperid, [2017], [2018] a [2019], zbytek nevidíte, což přispívá ke zmatku. Ale zbytek se implicitního seskupení účastnil.
Co by mohlo být skvělé, je, kdyby syntaxe operátoru PIVOT podporovala klauzuli, kde můžete explicitně označit prvek seskupení/na řádcích. Něco jako toto:
SELECTFROM PIVOT( ( ) FOR IN( ) ON ROWS ) AS ;
Na základě této syntaxe byste ke zpracování našeho úkolu použili následující kód:
SELECT shipperid, [2017], [2018], [2019]FROM Sales. Orders CROSS APPLY( VALUES(YEAR(shippeddate)) ) AS D(shippedyear) PIVOT(COUNT(shippeddate) FOR shipyear IN([2017]) , [2018], [2019]) ON ROWS shipperid ) AS P;
Zde najdete položku zpětné vazby s návrhem na vylepšení syntaxe operátora PIVOT. Chcete-li, aby se toto vylepšení stalo nezlomnou změnou, může být tato klauzule volitelná, přičemž výchozím nastavením je stávající chování. Existují další návrhy, jak zlepšit syntaxi operátora PIVOT tím, že bude dynamičtější a že bude podporovat více agregátů.
Mezitím existuje osvědčený postup, který vám může pomoci vyhnout se chybě. Použijte tabulkový výraz, jako je CTE nebo odvozená tabulka, kde promítnete pouze tři prvky, které musíte zapojit do kontingenční operace, a poté použijte tabulkový výraz jako vstup pro operátor PIVOT. Tímto způsobem plně ovládáte prvek seskupení. Zde je obecná syntaxe podle tohoto osvědčeného postupu:
WITHAS( SELECT , , FROM )SELECT FROM PIVOT( ( ) FOR IN( ) ) AS ;
Při použití našeho úkolu použijete následující kód:
WITH C AS( SELECT dodací lhůta, ROK(datum odeslání) AS rok odeslání, datum odeslání FROM Sales.Orders)SELECT dodací doba, [2017], [2018], [2019]OD C PIVOT( COUNT(datum odeslání) PRO rok odeslání IN([ 2017], [2018], [2019]) ) AS P;
Tentokrát podle očekávání získáte pouze tři řádky výsledků:
shipperid 2017 2018 2019----------- ----------- ----------- ---------- -3 51 125 731 36 130 792 56 143 116
Další možností je použít staré a klasické standardní řešení pro pivotování pomocí seskupeného dotazu a výrazů CASE, například:
SELECT shipperid, COUNT(CASE WHEN shippedyear =2017 THEN 1 END) AS [2017], COUNT(CASE WHEN shippedyear =2018 THEN 1 END) AS [2018], COUNT(CASE, AS WHEN shippedyear =2019 THEN 1 END) [2019]OD Sales.Orders CROSS APPLY( VALUES(YEAR(datum expedice)) ) AS D(shippedyear)WHELDDatam NENÍ NULLGROUP BY shipperid;
S touto syntaxí musí být v kódu explicitně uvedeny všechny tři kroky otáčení a jejich přidružené prvky. Pokud však máte velký počet rozložených hodnot, bývá tato syntaxe podrobná. V takových případech lidé často raději používají operátor PIVOT.
Implicitní odstranění hodnot NULL pomocí UNPIVOT
Další položka v tomto článku je spíše úskalí než chyba. Má co do činění s proprietárním operátorem T-SQL UNPIVOT, který vám umožňuje uvolnit data ze stavu sloupců do stavu řádků.
Jako vzorová data použiji tabulku s názvem CustOrders. K vytvoření, naplnění a dotazu na tuto tabulku použijte následující kód, abyste zobrazili její obsah:
DROP TABLE IF EXISTS dbo.CustOrders;GO WITH C AS( SELECT custid, YEAR(orderdate) AS orderyear, val FROM Sales.OrderValues)SELECT custid, [2017], [2018], [2019]INTO dbo.CustOrdersF C PIVOT( SUM(val) FOR orderyearyear IN([2017], [2018], [2019]) ) AS P; SELECT * FROM dbo.CustOrders;
Tento kód generuje následující výstup:
custid 2017 2018 2019------- ---------- ---------- -----------1 NULL 2022,50 2250,502 88,80 799,75 514.403 403.20 5960.78 660.004 1379.00 6406.90 5604.755 4324.40 13849.02 6754.166 NULL 1079.80 2160.007 9986.20 7817.88 730.008 982.00 3026.85 224.009 4074.28 11208.36 6680.6110 1832.80 7630.25 11338.5611 479.40 3179.50 2431.0012 NULL 238.00 1576.8013 100.80 NULL NULL14 1674.22 6516.40 4158.2615 2169.00 1128.00 513.7516 NULL 787.60 931.5017 533.60 420.00 2809.6118 268.80 487.00 860.1019 950.00 4514,35 9296,6920 15568,07 48096,27 41210,65...
Tato tabulka obsahuje celkové hodnoty objednávek na zákazníka a rok. Hodnoty NULL představují případy, kdy zákazník v cílovém roce nevykazoval žádnou objednávku.
Předpokládejme, že chcete uvolnit data z tabulky CustOrders a vrátit řádek na zákazníka a rok se sloupcem výsledku nazvaným val obsahujícím celkovou hodnotu objednávky pro aktuálního zákazníka a rok. Jakýkoli unpivoting úkol obecně zahrnuje tři prvky:
- Názvy stávajících zdrojových sloupců, které rozdělujete:[2017], [2018], [2019] v našem případě
- Název, který přiřadíte cílovému sloupci a který bude obsahovat názvy zdrojových sloupců:v našem případě orderyear
- Název, který přiřadíte cílovému sloupci a který bude obsahovat hodnoty zdrojového sloupce:v našem případě val
Pokud se rozhodnete ke zpracování úlohy unpivoting použít operátor UNPIVOT, musíte nejprve zjistit výše uvedené tři prvky a poté použít následující syntaxi:
SELECT, , Z UNPIVOT( FOR IN( ) ) AS ;
Při použití našeho úkolu použijete následující dotaz:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;
Tento dotaz generuje následující výstup:
rok objednávky zákazníka val------- ---------- ----------1 2018 2022,501 2019 2250,502 2017 88,802 2018 799,752 2019 3146 2017 1379,004 2018 6406.904 2019 5604.755 2017 4324.405 2018 13849.025 2019 6754.166 2018 1079.806 2019 2160,007 2017 9986.207 2018 7817.887 2019 730,00 ...
Při pohledu na zdrojová data a výsledek dotazu si všimnete, co chybí?
Návrh operátoru UNPIVOT zahrnuje implicitní odstranění řádků výsledků, které mají ve sloupci hodnot hodnotu NULL – v našem případě hodnotu. Když se podíváte na plán provádění tohoto dotazu zobrazený na obrázku 2, můžete vidět, že operátor Filter odstraňuje řádky s hodnotami NULL ve sloupci val (v plánu je Expr1007).
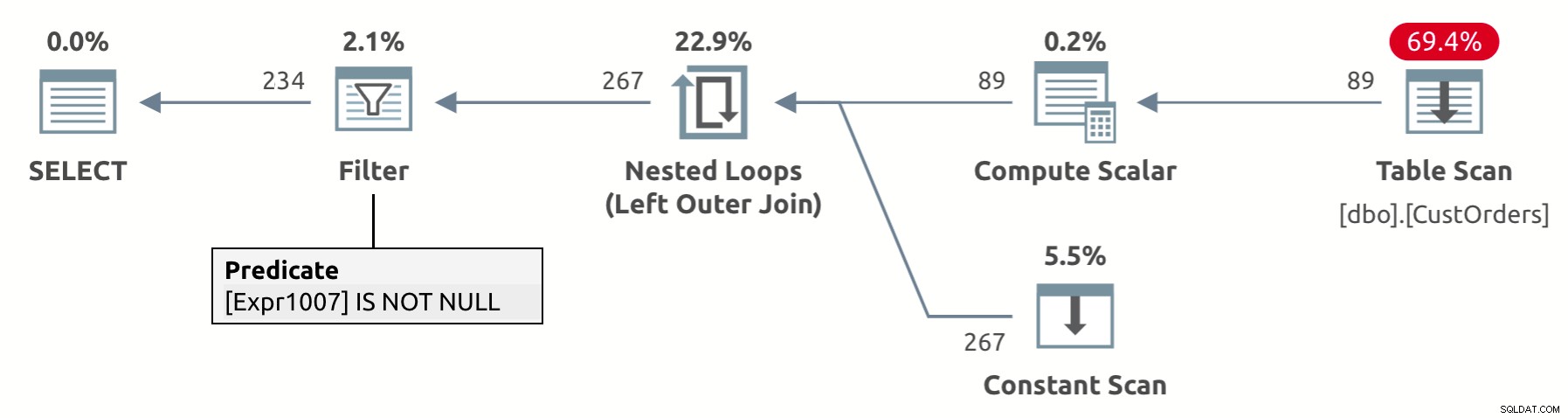 Obrázek 2:Plán pro unpivot dotaz s implicitním odstraněním hodnot NULL
Obrázek 2:Plán pro unpivot dotaz s implicitním odstraněním hodnot NULL
Někdy je toto chování žádoucí a v takovém případě nemusíte dělat nic zvláštního. Problém je v tom, že někdy chcete ponechat řádky s hodnotami NULL. Úskalí je, když chcete zachovat hodnoty NULL a ani si neuvědomujete, že operátor UNPIVOT je navržen tak, aby je odstranil.
Co by mohlo být skvělé, je, kdyby měl operátor UNPIVOT volitelnou klauzuli, která by vám umožnila určit, zda chcete odstranit nebo zachovat hodnoty NULL, přičemž první z nich je výchozí pro zpětnou kompatibilitu. Zde je příklad toho, jak by tato syntaxe mohla vypadat:
SELECT, , FROM UNPIVOT( PRO IN( ) [ODSTRANIT NULOVÉ | PONECHAT NULLS] ) JAKO ; Pokud byste chtěli zachovat hodnoty NULL, na základě této syntaxe byste použili následující dotaz:
SELECT custid, orderyear, valFROM dbo.CustOrders UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) KEEP NULLS ) AS U;Položku zpětné vazby s návrhem na vylepšení syntaxe operátora UNPIVOT tímto způsobem naleznete zde.
Mezitím, pokud chcete zachovat řádky s hodnotami NULL, musíte přijít s řešením. Pokud trváte na použití operátoru UNPIVOT, musíte použít dva kroky. V prvním kroku definujete tabulkový výraz na základě dotazu, který pomocí funkce ISNULL nebo COALESCE nahradí hodnoty NULL ve všech neotočných sloupcích hodnotou, která se normálně v datech nemůže objevit, např. v našem případě -1. Ve druhém kroku použijete funkci NULLIF ve vnějším dotazu proti sloupci hodnot k nahrazení -1 zpět hodnotou NULL. Zde je úplný kód řešení:
WITH C AS( SELECT custid, ISNULL([2017], -1.0) AS [2017], ISNULL([2018], -1.0) AS [2018], ISNULL([2019], -1.0) AS [2019 ] FROM dbo.CustOrders)SELECT custid, orderyear, NULLIF(val, -1.0) AS valFROM C UNPIVOT( val FOR orderyear IN([2017], [2018], [2019]) ) AS U;Zde je výstup tohoto dotazu, který ukazuje, že řádky s hodnotami NULL ve sloupci val jsou zachovány:
20.01.02 0.0.2017 2017 2019 2250 502 2017 88 802 2018 3991952 ---------- -----------1 2017 NULL1 2018 2022,501 2019 2250,502 2017 88,802 2018 39919527 2019 660,004 2017 1379,004 2018 6406.904 2019 5604,755 2017 4324,405 2018 13849.025 2019 6754.166 NULL6 2018 2018 1079.806 2019 2160.007 2017 9986.207 2018 7817.887 2019 730.00 ...
Tento přístup je nepříjemný, zvláště když máte velký počet sloupců, které je třeba uvolnit.
Alternativní řešení používá kombinaci operátoru APPLY a klauzule VALUES. Vytvoříte řádek pro každý neotočný sloupec, přičemž jeden sloupec představuje sloupec cílových jmen (v našem případě rok objednávky) a další sloupec představuje sloupec cílových hodnot (v našem případě val). Zadáte konstantní rok pro sloupec názvů a příslušný korelovaný zdrojový sloupec pro sloupec hodnot. Zde je úplný kód řešení:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val);Hezká věc je, že pokud nemáte zájem o odstranění řádků s NULL ve sloupci val, nemusíte dělat nic zvláštního. Není zde žádný implicitní krok, který by odstranil řádky s NULLS. Navíc, protože je alias sloupce val vytvořen jako součást klauzule FROM, je přístupný pro klauzuli WHERE. Pokud tedy máte zájem o odstranění hodnot NULL, můžete to výslovně uvést v klauzuli WHERE přímou interakcí s aliasem sloupce hodnot, například takto:
SELECT custid, orderyear, valFROM dbo.CustOrders CROSS APPLY ( VALUES(2017, [2017]), (2018, [2018]), (2019, [2019]) ) AS A(orderyear, val)WHERE val IS NOT NULL;Jde o to, že tato syntaxe vám dává kontrolu nad tím, zda chcete zachovat nebo odstranit hodnoty NULL. Jiným způsobem je flexibilnější než operátor UNPIVOT a umožňuje vám zpracovávat více neotočných opatření, jako je hodnota a množství. V tomto článku jsem se však zaměřil na úskalí zahrnující NULL, takže jsem se do tohoto aspektu nedostal.
Závěr
Návrh operátorů PIVOT a UNPIVOT někdy vede k chybám a úskalím ve vašem kódu. Syntaxe operátoru PIVOT vám neumožňuje explicitně označit prvek seskupení. Pokud si to neuvědomíte, můžete skončit s nežádoucími prvky seskupení. Jako osvědčený postup se doporučuje použít tabulkový výraz jako vstup do operátoru PIVOT, a proto explicitně řídit, co je seskupovací prvek.
Syntaxe operátoru UNPIVOT vám neumožňuje řídit, zda chcete odstranit nebo zachovat řádky s NULL ve sloupci výsledných hodnot. Jako náhradní řešení použijete buď nepříjemné řešení s funkcemi ISNULL a NULLIF, nebo řešení založené na operátoru APPLY a klauzuli VALUES.
Zmínil jsem také dvě položky zpětné vazby s návrhy na vylepšení operátorů PIVOT a UNPIVOT s explicitnějšími možnostmi kontroly chování operátora a jeho prvků.