Nedávno jsme spustili nový web podpory, kde můžete klást otázky, odesílat zpětnou vazbu k produktu nebo požadavky na funkce nebo otevírat lístky podpory. Součástí cíle bylo centralizovat všechna místa, kde jsme komunitě nabízeli pomoc. To zahrnovalo stránky SQLPerformance.com Q&A, kde Paul White, Hugo Kornelis a mnozí další pomáhali řešit vaše nejsložitější otázky týkající se ladění dotazů a plánu provádění, a to až do února 2013. Se smíšenými pocity vám říkám, že Stránka Q&A byla uzavřena.
Má to ale výhodu. Na novém fóru podpory nyní můžete klást tyto těžké otázky. Pokud hledáte starý obsah, dobře, stále tam je, ale vypadá trochu jinak. Z různých důvodů, kterými se dnes nebudu zabývat, jsme se poté, co jsme se rozhodli zrušit původní web s otázkami a odpověďmi, nakonec rozhodli jednoduše hostit veškerý existující obsah na webu WordPress, který je pouze pro čtení, místo abychom jej migrovali do back-endu. nového webu.
Tento příspěvek není o důvodech tohoto rozhodnutí.
Cítil jsem se opravdu špatně z toho, jak rychle se stránka odpovědí musela dostat do režimu offline, DNS se přepnul a obsah migroval. Vzhledem k tomu, že na webu byl implementován varovný banner, ale AnswerHub jej ve skutečnosti nezviditelnil, byl to pro mnoho uživatelů šok. Chtěl jsem se tedy ujistit, že jsem správně zachoval co nejvíce obsahu, a chtěl jsem, aby to bylo správné. Tento příspěvek je zde, protože jsem si myslel, že by bylo zajímavé mluvit o skutečném procesu, o tom, kolik různých částí technologie bylo spojeno s jeho vytažením, a předvést výsledek. Neočekávám, že kdokoli z vás bude mít prospěch z tohoto end-to-endu, protože se jedná o poměrně nejasnou cestu migrace, ale spíše jako příklad spojení hromady technologií dohromady za účelem splnění úkolu. Slouží mi to také jako dobrá připomínka toho, že mnoho věcí není tak snadné, jak to zní, než začnete.
TL;DR je toto:Strávil jsem spoustu času a úsilí, aby archivovaný obsah vypadal dobře, i když se stále snažím obnovit několik posledních příspěvků, které přišly ke konci. Použil jsem tyto technologie:
- Perl
- SQL Server
- PowerShell
- Přenos (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Odtud název. Pokud chcete velký kus krvavých detailů, tady jsou. Pokud máte nějaké dotazy nebo zpětnou vazbu, kontaktujte nás nebo napište komentář níže.
Služba AnswerHub poskytla soubor výpisu o velikosti 665 MB z databáze MySQL, která hostila obsah otázek a odpovědí. Každý editor, který jsem zkoušel, se tím dusil, takže jsem to nejprve musel rozdělit do souboru podle tabulky pomocí tohoto praktického skriptu v Perlu od Jareda Cheneyho. Potřebné tabulky se jmenovaly network11_nodes (otázky, odpovědi a komentáře), network11_authoritables (uživatelé) a network11_managed_files (všechny přílohy, včetně nahrání plánu):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Ty se nyní v SSMS nenačítaly extrémně rychle, ale alespoň tam jsem mohl použít Ctrl +H změnit (například) toto:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
K tomu:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Poté jsem mohl načíst data na SQL Server, abych s nimi mohl manipulovat. A věřte mi, že jsem to zmanipuloval.
Dále jsem musel získat všechny přílohy. Vidíte, soubor výpisu MySQL, který jsem dostal od dodavatele, obsahoval gazillion INSERT výkazy, ale žádný ze skutečných souborů plánu, které uživatelé nahráli – databáze měla pouze relativní cesty k souborům. Použil jsem T-SQL k vytvoření řady příkazů PowerShell, které by volaly Invoke-WebRequest získat všechny soubory a uložit je lokálně (mnoho způsobů, jak stáhnout tuto kočku z kůže, ale tohle bylo snadné). Z tohoto:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
To přineslo tuto sadu příkazů (spolu s předpříkazem k vyřešení tohoto problému s TLS); celá věc běžela docela rychle, ale tento přístup nedoporučuji pro žádnou kombinaci {masivní sady souborů} a/nebo {nízká šířka pásma}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Tím byly staženy téměř všechny přílohy, ale některé byly při prvotním nahrání vynechány kvůli chybám na starém webu. Takže na novém webu můžete občas vidět odkaz na přílohu, která neexistuje.
Pak jsem použil Panic Transmit 5 k nahrání temp složky na nový web, a když se obsah nahraje, odkazy na /s/temp/1-proc.pesession bude pokračovat v práci.
Dále jsem přešel na SSL. Abychom mohli požádat o certifikát na novém webu WordPress, museli jsme aktualizovat DNS pro answer.sqlperformance.com, aby ukazoval na CNAME na našem hostiteli WordPress, WPEngine. Tady to bylo něco jako slepice a vejce – museli jsme trpět určitým výpadkem u https URL, které by selhaly bez certifikátu na novém webu. To bylo v pořádku, protože platnost certifikátu na starém webu vypršela, takže jsme na tom opravdu nebyli hůř. Také jsem na to musel počkat, dokud si nestáhnu všechny soubory ze starého webu, protože jakmile se DNS překlopí, nebude možné se k nim dostat jinak než nějakými zadními vrátky.
Zatímco jsem čekal, až se DNS rozšíří, začal jsem pracovat na logice, abych všechny otázky, odpovědi a komentáře převedl do něčeho použitelného ve WordPressu. Nejen, že se schémata tabulek lišila od WordPress, ale také typy entit jsou docela odlišné. Mojí vizí bylo spojit každou otázku – a jakékoli odpovědi a/nebo komentáře – do jediného příspěvku.
Záludná část je v tom, že tabulka uzlů obsahuje pouze všechny tři typy obsahu ve stejné tabulce s odkazy na rodiče a původní ("hlavní") rodiče. Jejich front-end kód pravděpodobně používá nějaký druh kurzoru k procházení a zobrazení obsahu v hierarchickém a chronologickém pořadí. Ve WordPressu bych takový luxus neměl, takže jsem musel propojit HTML najednou. Jako příklad uvádíme, jak data vypadala:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Nemohl jsem seřadit podle ID, typu nebo podle rodiče, protože někdy komentář přišel později na dřívější odpověď, první odpověď by nebyla vždy přijatou odpovědí a tak dále. Chtěl jsem tento výstup (kde ++ představuje jednu úroveň odsazení):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Začal jsem psát rekurzivní CTE a
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Výsledky:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Génius. Zkontroloval jsem asi tucet dalších a byl jsem rád, že jsem postoupil k dalšímu kroku. Už jsem Andymu několikrát poděkoval, ale dovolte mi to udělat znovu:Díky Andy!
Nyní, když jsem mohl vrátit celou sadu v pořadí, které se mi líbilo, musel jsem provést nějakou manipulaci s výstupem, abych použil prvky HTML a názvy tříd, které mi umožní smysluplným způsobem označit otázky, odpovědi, komentáře a odsazení. Konečným cílem byl výstup, který vypadal takto (a mějte na paměti, toto je jeden z jednodušších případů):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Nebudu procházet směšným počtem iterací, kterými jsem musel projít, abych se dostal na spolehlivou formu tohoto výstupu pro všech 5 000+ položek (což znamenalo téměř 1 000 příspěvků, jakmile bylo vše slepeno dohromady). Navíc jsem je potřeboval vygenerovat ve tvaru INSERT prohlášení, které jsem pak mohl vložit do phpMyAdmin na webu WordPress, což znamenalo držet se jejich bizarního syntaktického diagramu. Tato prohlášení musela obsahovat další dodatečné informace požadované WordPressem, které však nejsou přítomné nebo přesné ve zdrojových datech (např. post_type ). A tato administrátorská konzole vypršela kvůli příliš velkému množství dat, takže jsem je musel rozdělit na ~750 vložek najednou. Zde je postup, kterým jsem skončil (ve skutečnosti nejde o nic konkrétního, jen o ukázku toho, jak velká manipulace s importovanými daty byla nutná):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO Výstup z toho ještě není kompletní a ještě není připravený nacpat do WordPressu:
 Ukázkový výstup (kliknutím zvětšíte)
Ukázkový výstup (kliknutím zvětšíte)
Potřeboval bych nějakou další pomoc od C#, abych převedl skutečný obsah (včetně markdown) do HTML a CSS, které bych mohl lépe ovládat, a napsal výstup (hromada INSERT příkazy, které náhodou obsahovaly spoustu HTML kódu) do souborů na disku, které jsem mohl otevřít a vložit do phpMyAdmin. Pro HTML, prostý text + markdown, který začínal takto:
VYBERTE něco z dbo.sometable;
[1]:https://jinde
Musí se stát tímto:
Je zde příspěvek na blogu , který o tom mluví, a také tento příspěvek .
VYBERTE něco z dbo.sometable; Abych toho dosáhl, požádal jsem o pomoc MarkdownSharp, knihovnu s otevřeným zdrojovým kódem pocházející ze Stack Overflow, která zpracovává velkou část převodu markdown-to-HTML. Bylo to dobré pro mé potřeby, ale ne dokonalé; Ještě bych musel provést další manipulaci:
- MarkdownSharp neumožňuje věci jako
target=_blank, takže ty bych si po zpracování musel píchnout sám; - kód (cokoli s předponou čtyřmi mezerami) zdědí obaly
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Ano, je to ošklivá snůška kódu, ale nakonec jsem se dostal k sadě výstupů, ze kterých by phpMyAdmin nezvracel a který by WordPress prezentoval pěkně (dost). Jednoduše jsem zavolal program C# několikrát s různými rozsahy parametrů:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Poté jsem otevřel každý ze souborů, vložil je do phpMyAdmin a zmáčkl GO:
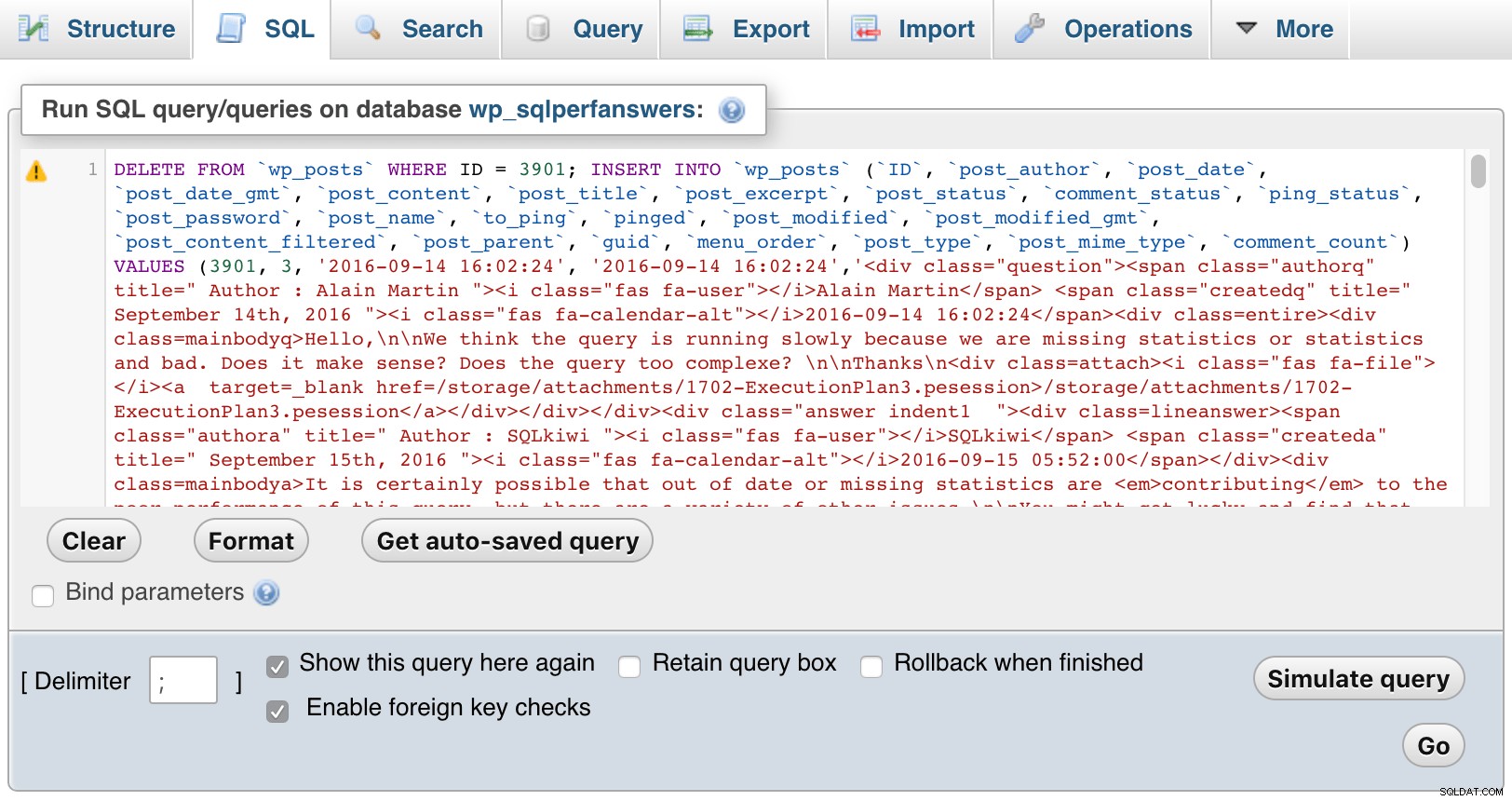 phpMyAdmin (kliknutím zvětšíte)
phpMyAdmin (kliknutím zvětšíte) Samozřejmě jsem musel přidat nějaké CSS do WordPress, abych pomohl rozlišovat mezi otázkami, komentáři a odpověďmi a také odsadit komentáře, aby se zobrazily odpovědi na otázky i odpovědi, vnořit komentáře jako odpovědi na komentáře a tak dále. Zde je návod, jak vypadá úryvek, když si projdete otázky za měsíc:
 Dlaždice s otázkou (kliknutím zvětšíte)
Dlaždice s otázkou (kliknutím zvětšíte) A pak příklad příspěvku, který ukazuje vložené obrázky, více příloh, vnořené komentáře a odpověď:
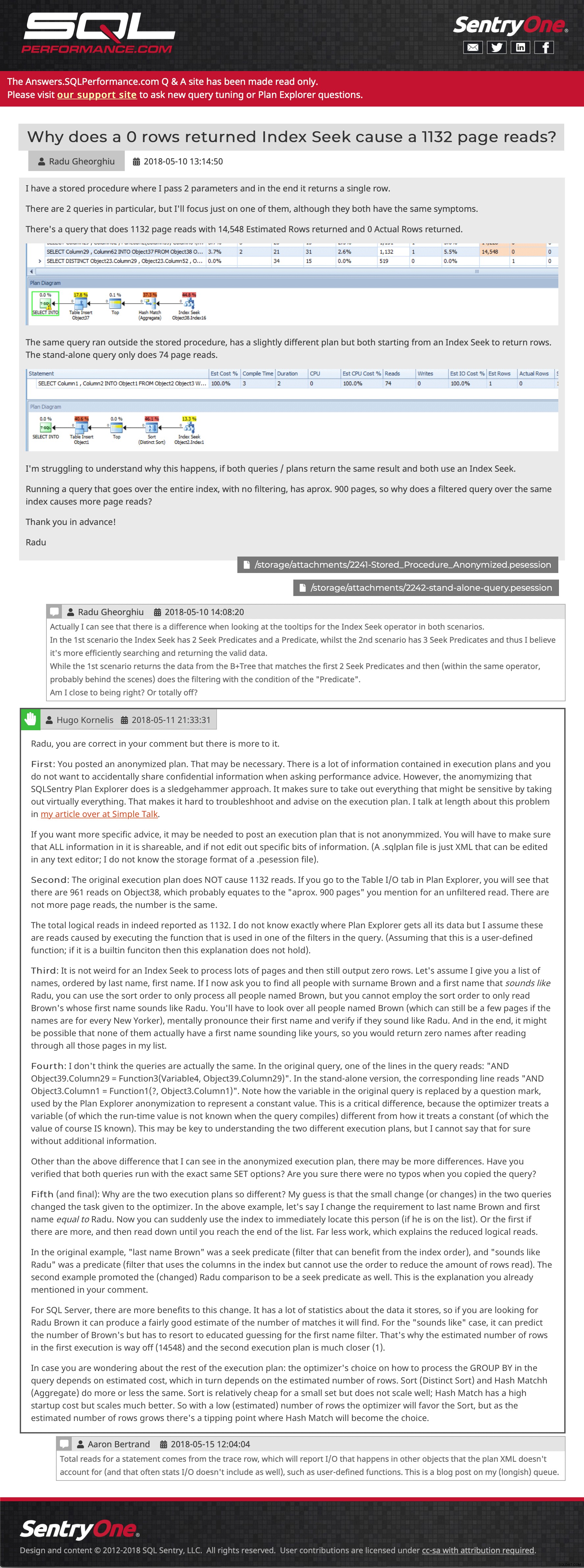 Ukázková otázka a odpověď (kliknutím sem přejdete)
Ukázková otázka a odpověď (kliknutím sem přejdete) Stále se snažím obnovit několik příspěvků, které byly odeslány na web po pořízení poslední zálohy, ale vítám vás, když si je můžete procházet. Dejte nám prosím vědět, pokud si všimnete, že něco chybí nebo není na svém místě, nebo nám jen sdělte, že obsah je pro vás stále užitečný. Doufáme, že znovu zavedeme funkci nahrávání plánu z Průzkumníka plánu, ale bude to vyžadovat nějakou práci s API na novém webu podpory, takže pro vás dnes nemám odhadovaný čas příjezdu.
- Answers.SQLPerformance.com