Extraction Transformation Load (ETL) je páteří každého datového skladu. Ve světovém datovém skladu jsou data spravována procesem ETL, který se skládá ze tří procesů, Extrakce-Pull/Získání dat ze zdrojů, Transformace-změna dat v požadovaném formátu a Načtení-push dat na místo určení obecně do datového skladu resp. datový trh.
Naučte se SSIS a spusťte bezplatnou zkušební verzi ještě dnes!
SQL Server Integration Services (SSIS) je nástroj z rodiny ETL, který je užitečný pro vývoj a správu podnikového datového skladu. Datový sklad podle své vlastní charakterizace pracuje na obrovském objemu dat a výkon je velkou výzvou při správě velkého objemu dat pro jakéhokoli architekta nebo DBA.
Úvahy o vylepšení ETL
Dnes budu diskutovat o tom, jak snadno můžete zlepšit výkon ETL nebo navrhnout vysoce výkonný systém ETL pomocí SSIS. Pro lepší pochopení rozdělím deset metod do dvou různých kategorií; za prvé, úvahy o době návrhu balíčku SSIS a za druhé konfigurace různých hodnot vlastností komponent dostupných v balíčku SSIS.
Úvahy o návrhu balíčku SSIS v době návrhu
#1 Paralelní extrahování dat:SSIS poskytuje způsob, jak paralelně stahovat data pomocí kontejnerů Sequence v řídicím toku. Balíček můžete navrhnout tak, aby mohl paralelně stahovat data z nezávislých tabulek nebo souborů, což pomůže zkrátit celkovou dobu provádění ETL.
#2 Extrahujte požadovaná data:vytáhněte pouze požadovanou sadu dat z libovolné tabulky nebo souboru. Musíte se vyhnout tendenci vytahovat vše, co je zatím dostupné na zdroji, co budete používat v budoucnu; zabírá šířku pásma sítě, spotřebovává systémové prostředky (I/O a CPU), vyžaduje další úložiště a snižuje celkový výkon systému ETL.
Pokud je váš systém ETL skutečně dynamický a vaše požadavky se často mění, bylo by lepší zvážit jiné přístupy k návrhu, jako je ETL řízené metadaty atd., než navrhnout tak, aby bylo vše vloženo najednou.
#3 Vyhněte se používání komponent asynchronní transformace:SSIS je bohatý nástroj se sadou komponent transformace pro dosažení složitých úkolů během provádění ETL, ale zároveň vás to stojí hodně, pokud tyto komponenty nejsou používány správně.
V SSIS jsou k dispozici dvě kategorie komponent transformace:Synchronní a Asynchronní .
Synchronní transformace jsou ty komponenty, které zpracovávají každý řádek a posouvají dolů na další komponentu/cíl, využívá přidělenou vyrovnávací paměť a nevyžaduje další paměť, protože jde o přímý vztah mezi vstupními/výstupními datovými řádky, které se zcela vejdou do přidělené paměti. Komponenty jako vyhledávání, odvozené sloupce a konverze dat atd. spadají do této kategorie.
Asynchronní transformace jsou ty komponenty, které nejprve ukládají data do vyrovnávací paměti a poté zpracovávají operace jako řazení a agregace. K dokončení úkolu je zapotřebí další vyrovnávací paměť a dokud není vyrovnávací paměť k dispozici, podrží všechna data v paměti a zablokuje transakci, také známou jako blokující transformace. Pro dokončení úkolu SSIS engine (data flow pipeline engine) přidělí extra vyrovnávací paměť, což je opět režie pro ETL systém. Komponenty jako Sort, Aggregate, Merge, Join atd. spadají do této kategorie.
Celkově byste se měli vyhnout asynchronním transformacím, ale přesto, pokud se dostanete do situace, kdy nemáte jinou možnost, musíte si být vědomi toho, jak zacházet s dostupnými hodnotami vlastností těchto komponent. Budu o nich diskutovat později v tomto článku.
#4 Optimální využití událostí v obslužných programech událostí:SSIS poskytuje sadu událostí, aby bylo možné sledovat průběh provádění balíčků nebo provést jakoukoli jinou vhodnou akci u konkrétní události. Události jsou velmi užitečné, ale nadměrné používání událostí bude stát další režii na provádění ETL.
Zde musíte před povolením události v balíčku SSIS ověřit všechny vlastnosti.
#5 Při práci s velkým objemem dat je třeba mít na paměti schéma cílové tabulky. Musíte si to dvakrát rozmyslet, když potřebujete vytáhnout obrovský objem dat ze zdroje a poslat je do datového skladu nebo datového tržiště. Při pokusu o přesunutí velkých dat do cíle pomocí kombinace operací vložení, aktualizace a odstranění (DML) můžete zaznamenat problémy s výkonem, protože může existovat možnost, že cílová tabulka bude mít seskupené nebo neseskupené indexy, což může způsobit mnoho dat se v paměti přesouvá kvůli operacím DML.
Pokud má ETL problémy s výkonem kvůli velkému množství operací DML na tabulce, která má index, musíte provést příslušné změny v návrhu ETL, jako je odstranění existujících seskupených indexů ve fázi před spuštěním a znovu vytvořit všechny indexy. ve fázi po provedení. Můžete najít jiné lepší alternativy k vyřešení problému na základě vaší situace.
Konfigurace vlastností komponent
#6 Ovládejte paralelní provádění úlohy konfigurací MaxConcurrentExecutables a EngineThreads vlastnictví. Úlohy balíčku SSIS a toku dat mají vlastnost pro řízení paralelního provádění úlohy:MaxConcurrentExecutables je vlastnost na úrovni balíčku a má výchozí hodnotu -1 , což znamená, že maximální počet úloh, které lze provést, se rovná celkovému počtu procesorů na počítači plus dva;
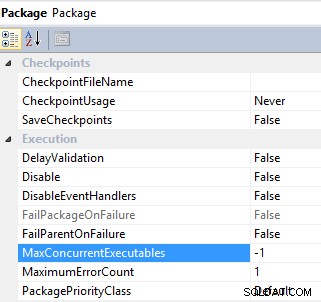
Balík
EngineThreads je vlastnost na úrovni úlohy toku dat a má výchozí hodnotu 10, která udává celkový počet vláken, která lze vytvořit pro provedení úlohy toku dat.
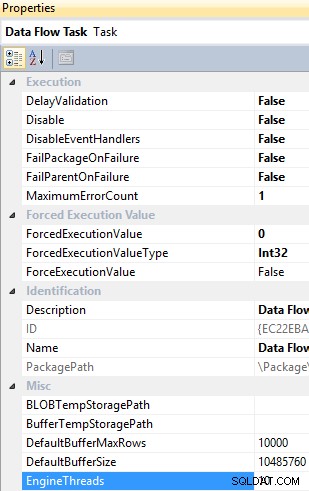
Úloha toku dat
Výchozí hodnoty těchto vlastností můžete změnit podle potřeb ETL a dostupnosti zdrojů.
#7 Možnost konfigurace režimu přístupu k datům v cíli OLEDB. V úloze datového toku SSIS najdeme cíl OLEDB, který poskytuje několik možností, jak vložit data do cílové tabulky, v režimu přístupu k datům; nejprve možnost „Tabulka nebo zobrazení“, která vkládá jeden řádek po druhém; za druhé možnost „Rychlé načítání tabulky nebo zobrazení“, která interně používá příkaz hromadného vložení k odesílání dat do cílové tabulky, což vždy poskytuje lepší výkon ve srovnání s jinými možnostmi. Jakmile zvolíte možnost „rychlé načtení“, získáte větší kontrolu nad chováním cílové tabulky během operace push dat, jako je Keep identity, Keep nulls, Table lock a Check constraints.
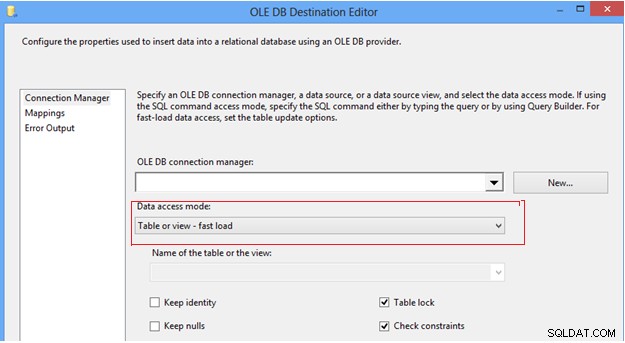
Editor cílů OLE DB
Důrazně doporučujeme, abyste použili možnost rychlého načítání k přenesení dat do cílové tabulky, abyste zlepšili výkon ETL.
#8, Konfigurace řádků na dávku a maximální velikost potvrzení vložení v cíli OLEDB. Tato dvě nastavení jsou důležitá pro řízení výkonu databáze tempdb a protokolu transakcí, protože s danými výchozími hodnotami těchto vlastností vloží data do cílové tabulky v rámci jedné dávky a jedné transakce. Bude to vyžadovat nadměrné používání tembdb a transakčního protokolu, což se změní v problém s výkonem ETL kvůli nadměrné spotřebě paměti a diskového úložiště.
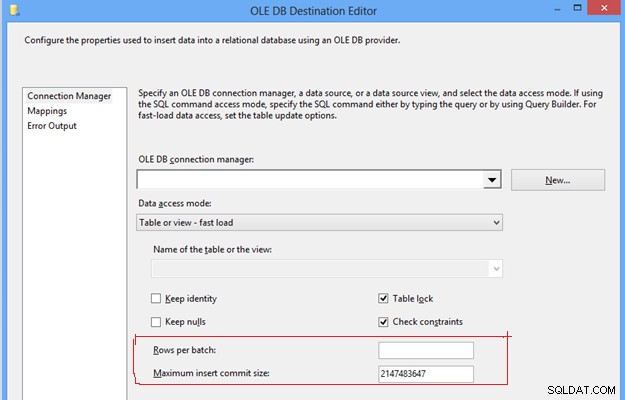
Editor cílů OLE DB
Chcete-li zlepšit výkon ETL, můžete do obou vlastností vložit kladnou celočíselnou hodnotu na základě očekávaného objemu dat, což pomůže rozdělit celou hromadu dat do více dávek a data v dávce se mohou znovu odevzdat do cílové tabulky v závislosti na specifikovaná hodnota. Vyhne se nadměrnému používání databáze tempdb a protokolu transakcí, což pomůže zlepšit výkon ETL.
#9 Použití cíle SQL Server v úloze toku dat. Pokud chcete odeslat data do lokální databáze SQL Server, důrazně se doporučuje použít cíl SQL Server, protože poskytuje mnoho výhod k překonání omezení jiných možností, což vám pomůže zlepšit výkon ETL. Například používá funkci hromadného vkládání, která je integrována do SQL Server, ale dává vám možnost použít transformaci před načtením dat do cílové tabulky. Kromě toho vám dává možnost povolit/zakázat spouštění spouště při načítání dat, což také pomáhá snížit režii ETL.
Komponenta toku dat cílového serveru SQL
#10 Vyhněte se implicitnímu typovému obsazení. Když data pocházejí z plochého souboru, správce připojení plochých souborů považuje všechny sloupce za datový typ řetězce (DS_STR), včetně číselných sloupců. Jak víte, SSIS používá vyrovnávací paměť k uložení celé sady dat a před odesláním dat do cílové tabulky aplikuje požadovanou transformaci. Nyní, když jsou všechny sloupce typu řetězcových dat, bude to vyžadovat více místa ve vyrovnávací paměti, což sníží výkon ETL.
Chcete-li zlepšit výkon ETL, měli byste převést všechny číselné sloupce do vhodného datového typu a vyhnout se implicitnímu převodu, což pomůže enginu SSIS pojmout více řádků v jedné vyrovnávací paměti.
Shrnutí vylepšení výkonu ETL
V tomto článku jsme prozkoumali, jak snadno lze ovládat výkon ETL v libovolném okamžiku. Toto je 10 běžných způsobů, jak zlepšit výkon ETL. Může existovat více metod založených na různých scénářích, pomocí kterých lze zlepšit výkon.
Celkově lze s pomocí kategorizace identifikovat, jak situaci řešit. Pokud jste ve fázi návrhu datového skladu, možná se budete muset soustředit na obě kategorie, ale pokud podporujete jakýkoli starší systém, pak nejprve úzce pracujte na druhé kategorii.