Vztahy jedna k mnoha jsou jedním z nejběžnějších databázových vztahů. Pokud se chcete dozvědět, kdy a jak používat vztahy one-to-many, pak je tento článek skvělým výchozím bodem.
Vztahy jedna ku mnoha jistě využijete k ukládání informací v jakékoli relační databázi, ať už navrhujete software na podnikové úrovni, nebo jen vytváříte jednoduchou databázi pro sledování sbírky známek vašeho strýce.
Stručný úvod do relačního modelu
Relační databáze jsou základní součástí každé moderní transakční aplikace. Relační model se skládá z tabulek (data uspořádaná do řádků a sloupců), které mají alespoň jeden jedinečný klíč, který identifikuje každý řádek. Každá tabulka představuje entitu. To je znázorněno na následujícím příkladu, velmi jednoduché verzi tabulky představující objednávky zákazníků:

Výše uvedený diagram, který jsem vytvořil online pomocí Vertabelo, má jednu tabulku. Každý řádek v tabulce představuje jednu objednávku a každý sloupec (známý také jako atribut ) představuje každou jednotlivou informaci obsaženou v objednávce.
Pro ty, kteří ještě neznají návrhový nástroj Vertabelo, článek Jaké jsou symboly používané v ER diagramech? vysvětluje použité symboly a konvence. Můžete se také chtít dozvědět více o relačních modelech a databázích pomocí našeho kurzu modelování databází.
Co jsou vztahy a proč je potřebujeme?
Pokud se hlouběji podíváme na tabulku použitou v předchozím příkladu, uvidíme, že ve skutečnosti nepředstavuje úplnou objednávku. Nemá všechny informace, které byste od něj očekávali. Všimnete si, že neobsahuje žádná data týkající se zákazníka, který provedl objednávku, ani neobsahuje nic o objednaných produktech nebo službách.
Co bychom měli udělat, abychom dokončili tento návrh pro uložení dat objednávky? Měli bychom do Objednávky přidat informace o zákazníkovi a produktu stůl? To by vyžadovalo přidání nových sloupců (atributů) pro jména zákazníků, daňové identifikátory, adresy atd., jak je uvedeno níže:
| "OrderID" | "Datum objednávky" | "OrderAmount" | Zákazník | „Adresa zákazníka“ | „Telefon zákazníka“ | "TaxIdentifier" |
|---|---|---|---|---|---|---|
| 1 | 23. června | 10 248,15 $ | International Services Ltd | 1247 St River Blvd, Charlotte, NC | (555) 478-8741 | IS789456 |
| 2 | 27. června | 14 785,45 $ | World Master Importing Inc. | 354 Mountain Hill Rd, Los Angeles, CA | (555) 774-8888 | WM321456 |
| 3 | červenec-01 | 7 975,00 $ | First State Provisioning Llc | 444 North Highway, Houston, TX | (555) 698-7411 | FS947561 |
| 4 | červenec-03 | 6 784,25 $ | International Services Ltd | 1247 St River Blvd, Charlotte, NC | (555) 478-8741 | IS789456 |
| 5 | červenec-07 | 21 476,10 $ | World Master Importing Inc. | 354 Mountain Hill Rd, Los Angeles, CA | (555) 774-8888 | WM321456 |
| 6 | 12. července | 9 734,00 $ | First State Provisioning Llc | 444 North Highway, Houston, TX | (555) 698-7411 | FS947561 |
| 7 | 17. července | 14 747,45 $ | World Master Importing Inc. | 354 Mountain Hill Rd, Los Angeles, CA | (555) 774-8888 | WM321456 |
| 8 | 21. července | 19 674,85 $ | International Services Ltd | 1247 St River Blvd, Charlotte, NC | (555) 478-8741 | IS789456 |
Pokud to uděláme, brzy se dostaneme do problémů. Většina zákazníků zadává více než jednu objednávku, takže tento systém bude ukládat informace o zákaznících mnohokrát, jednou pro každou objednávku každého zákazníka. To nevypadá jako chytrý tah.
Navíc, co se stane, když si zákazník změní telefonní číslo? Pokud někdo potřebuje zavolat zákazníkovi, může najít staré číslo u předchozích objednávek – pokud někdo neaktualizuje stovky (nebo dokonce tisíce) stávajících objednávek novými informacemi. A totéž by platilo pro jakoukoli jinou změnu.
Relační model vyžaduje, abychom definovali každou entitu jako samostatnou tabulku a vytvořili mezi nimi vztahy. Ukládání všech informací do jedné tabulky prostě nefunguje.
Mezi tabulkami existuje několik typů vztahů, ale pravděpodobně nejběžnější je vztah one-to-many, který se často píše jako 1:N. Tento druh vztahu znamená, že jeden řádek v tabulce (obvykle nazývaný nadřazená tabulka) může mít vztah s mnoha řádky v jiné tabulce (obvykle nazývané podřízená tabulka). Některé běžné příklady vztahů typu one-to-many jsou:
- Výrobce automobilů vyrábí mnoho různých modelů, ale konkrétní model automobilu vyrábí pouze jeden výrobce automobilů.
- Jeden zákazník může provést několik nákupů, ale každý nákup provede jeden zákazník.
- Jedna společnost může mít mnoho telefonních čísel, ale jedno telefonní číslo patří jedné společnosti.
Existují také další typy vztahů mezi tabulkami; pokud se o nich chcete dozvědět více, podívejte se na tento článek o vztazích mnoho k mnoha.
Vraťme se k našemu počátečnímu příkladu objednávky, Customer tabulka by byla nadřazená tabulka a Order stůl dítě; zákazník může mít mnoho objednávek, zatímco objednávka může patřit jedinému zákazníkovi.
Pamatujte, že definice one-to-many umožňuje, aby byl řádek v nadřazené tabulce přidružen k mnoha řádkům v každé podřízené tabulce, ale nevyžaduje to. Konstrukce ve skutečnosti umožňuje zákazníkovi mít nulové objednávky (tj. nový zákazník, který ještě neuskutečnil svůj první nákup), jednu objednávku (relativně nový zákazník, který provedl jediný nákup) nebo mnoho objednávek (častý zákazník).
Zobrazení vztahů jedna ku mnoha v diagramu ER
Podívejme se na úplnější příklad jednoduchého systému objednávání zákazníků pomocí diagramu ER (nebo vztahu mezi entitami). (Pokud se chcete o těchto diagramech dozvědět více, Vertabelo Features:Logical Diagrams je skvělým výchozím bodem.) Zde je model:
Toto je realističtější design. Všimnete si, že v diagramu jsou nové entity (tabulky), které nyní obsahují tabulky Customer , Order , Order Detail a Product . Nejdůležitější věcí, které si však všimnete, je, že nyní existují vztahy mezi stoly .
V databázovém modelu jsou vztahy reprezentovány čarami spojujícími dvě entity. Charakteristiky těchto vztahů jsou reprezentovány různými konektory:
- Pokud existuje jedna svislá čára, má entita nejblíže ke spojnici pouze jeden řádek ovlivněný vztahem. Je to „jeden“ v jednom k mnoha.
- Pokud existuje víceřádkový konektor, který vypadá jako vrána, entita nejblíže ke konektoru má více řádků ovlivněných vztahem; je to ‚mnoho‘.
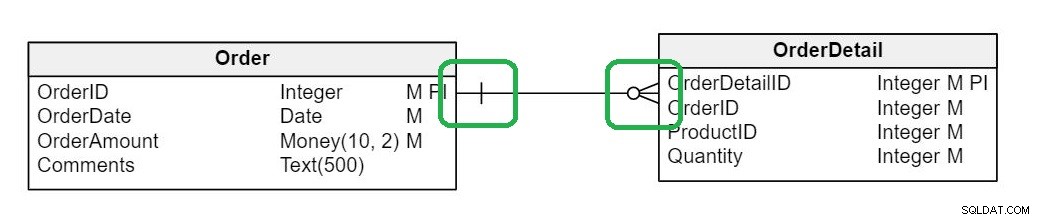
Při pohledu na obrázek a znalosti notace je snadné pochopit, že diagram definuje, že každá Order může mít mnoho Order Details a že každý Order Detail patří k jedné Order .
Implementace vztahu jedna k mnoha mezi tabulkami
Chcete-li definovat vztah jedna k mnoha mezi dvěma tabulkami, musí podřízená tabulka odkazovat na řádek v nadřazené tabulce. Kroky potřebné k jeho definování jsou:
- Přidejte do podřízené tabulky sloupec, který bude uchovávat hodnotu primárního identifikátoru. (Většina databázových strojů umožňuje, aby to byl jakýkoli jedinečný klíč z nadřazené tabulky, nikoli pouze primární klíč.) Sloupec lze definovat jako povinný v závislosti na vašich obchodních potřebách; i tak se obvykle dělají sloupce cizího klíče
Poznámka: Je vhodné ponechat názvy odkazujících sloupců stejné jako v odkazované (nadřazené) tabulce. Díky tomu je ještě jednodušší porozumět vztahu.
- Přidejte cizí klíč omezení na podřízené tabulce. To znamená, že každá hodnota uložená v tomto novém sloupci odkazuje na řádek v nadřazené tabulce.
Omezení cizího klíče jsou funkce dostupná v relační databázi, která vynucuje toto:
- Když do podřízené tabulky přidáte řádek, hodnota odkazujícího sloupce se musí shodovat s jednou (a pouze jednou) hodnotou v nadřazené tabulce. (Proto je třeba odkazovat na sloupec nebo sadu sloupců, které tvoří primární klíč nebo jedinečný klíč).
- Pokud se někdo pokusí odstranit řádek z nadřazené tabulky nebo se pokusí upravit hodnoty jedinečného/primárního klíče použitého jako reference a existuje podřízená tabulka, která odkazuje na tento řádek, operace se nezdaří.
Tyto dvě funkce zajišťují, že si databáze zachová svou integritu. Neexistuje žádná šance na vytvoření objednávek odkazujících na neexistujícího zákazníka ani na smazání zákazníka, který již objednávky má.
Vytvoření cizího klíče
Syntaxe cizího klíče obvykle závisí na cílovém databázovém stroji. Jakmile nadefinujete svůj logický model, můžete použít funkci „Generovat fyzický model…“ v logických diagramech Vertabelo k transformaci vašeho (databázového agnostického) modelu na fyzický model, který odpovídá vašemu poskytovateli databáze. Vertabelo také vygeneruje požadovaný SQL skript, který vám umožní vytvářet tabulky a vztahy ve vaší cílové databázi.
Některé praktické příklady vztahů 1:N
Nyní se podíváme na několik příkladů skutečných vztahů typu one-to-many.
Vztah jeden k mnoha pomocí primárních klíčů
Toto je pravděpodobně nejběžnější scénář při definování vztahu typu one-to-many. Podřízená tabulka používá k navázání vztahu hodnotu primárního klíče nadřazené tabulky.
Tento příklad popisuje základní online streamovací službu. Podívejme se, co je uloženo v každé z tabulek a jak souvisí s ostatními tabulkami v našem modelu:
- Každý
ServiceTypedefinuje, jak se účet „chová“ (např. kolik uživatelů se může současně připojit k systému, má-li účet povoleno Full HD atd.). Má jeden vztah s jinými entitami:- Vztah jeden k mnoha s
Account, což znamená, že každý typ služby může mít mnoho účtů tohoto typu.
- Vztah jeden k mnoha s
- Každý
Accountuchovává informace o jednom zákazníkovi. Má dva přímé vztahy k jiným entitám:- Každý účet patří k jednomu
ServiceType, jak je vysvětleno výše. - Tato tabulka má vztah jedna k mnoha s
Profiletabulka, což znamená, že se k našemu systému může pomocí stejného účtu připojit více než jeden uživatel.
- Každý účet patří k jednomu
- Každý
Profilepředstavuje uživatele v našem systému. Má dva vztahy k jiným entitám:- Každý profil patří k jednomu
Account. To umožňuje všem členům rodiny (nebo možná skupině přátel) sdílet stejný účet, přičemž každý z nich má své vlastní osobní atributy (např. název profilu). - Každý profil má jedinečného
Avatar.
- Každý profil patří k jednomu
- Každý
Avatarje obrázek, který nám umožňuje rychle identifikovat každého uživatele účtu. Má jeden vztah s jinou entitou:- Vztah jeden k mnoha s
Profile, což znamená, že jeden avatar může být přiřazen k profilům na různých účtech.
- Vztah jeden k mnoha s
Vztahy jeden k mnoha s přirozenými nebo náhradními jedinečnými klíči
Použití náhradních primárních klíčů je široce přijímaný způsob modelování tabulek. (Náhradní primární klíče jsou generovány databází a nemají žádnou skutečnou obchodní hodnotu.) Tato metoda vytváří klíče, které se snáze používají a přidává určitou flexibilitu, pokud jsou vyžadovány změny.
Jsou však situace – např. když potřebujeme komunikovat s externími systémy – kde použití klíče vygenerovaného v naší databázi je špatný přístup. Pro tyto scénáře je obvykle lepší použít přirozené klíče, což jsou jedinečné hodnoty, které jsou součástí ukládané entity a nejsou automaticky generovány naší databází.
Následující příklad představuje základní datový model organizace, která sleduje vozidla (tj. značku, model, barvu a rok auta), jejich vlastníky a všechny související přestupky v tranzitu. Když jsme to definovali, použili jsme náhradní primární klíče k vytvoření vztahů mezi vozidly a značkami, modely a vlastníky, protože všechny tyto informace jsou interně zpracovávány naším systémem.
Jak může v tomto systému policista v jiném městě nahlásit nezákonně zaparkované auto pomocí našeho primárního klíče vozidla (VehicleID )? Takové informace nejsou na zaparkovaném vozidle přirozeně dostupné, ale SPZ tam je. To znamená, že nejjednodušším způsobem, jak přijímat a spojovat informace z externího zdroje (v tomto příkladu z jakéhokoli policejního oddělení v zemi), je použití přirozeného jedinečného klíče namísto náhradního primárního klíče.
Fyzická implementace tohoto logického diagramu pro SQL Server je k dispozici zde:
Vztahy jeden k mnoha na stejném stole
Předchozí příklady se zaměřovaly na vztahy mezi dvěma nebo více tabulkami, ale existují také scénáře, kdy ke vztahu dochází mezi řádky stejné tabulky. Tento druh vztahu jeden k mnoha se také nazývá hierarchický vztah; používá se v mnoha systémech k reprezentaci stromových struktur, tj. organizačního diagramu, účtu hlavní knihy nebo produktu a jeho součástí.
Když budete potřebovat vytvořit tento druh struktury poprvé, budete v pokušení definovat tabulku pro každou z úrovní ve vaší hierarchii, jak ukazuje následující diagram:
Tento přístup má mnoho problémů:
- Všechny tabulky jsou téměř totožné a obsahují stejné informace.
- Pokud vaše organizace přidá novou úroveň, budete muset upravit datový model a přidat novou tabulku, nové cizí klíče atd.
- Pokud zaměstnanec obdrží povýšení, musíte jej odstranit z jedné tabulky a vložit do jiné.
Nejlepším způsobem, jak modelovat tento druh struktury, je proto použití jediné tabulky, která odkazuje sama na sebe, jak ukazuje tento diagram:
Zde vidíme jediného Employee tabulka a sloupec s názvem EmployeeID_Manager . Tento sloupec odkazuje na jiného zaměstnance ve stejné organizaci, který je nadřízeným/manažerem aktuálního zaměstnance.
Přidal jsem _Manager přípona pro rozlišení mezi ID aktuálního řádku a ID manažera. (Mohli bychom použít ManagerID místo toho, ale dávám přednost zachování původního názvu odkazovaného sloupce a v případech, kdy jsou oba ve stejné tabulce, přidat příponu, která vysvětluje roli, kterou ve skutečnosti má).
Pochopení hierarchických vztahů je složitější než jiné vztahy typu one-to-many. Pokud ale zapomenete na tabulku, kde jsou uloženy všechny informace, a představíte si, že ve skutečnosti existují různé tabulky, z nichž každá představuje úroveň v hierarchii, je to o něco jednodušší na vizualizaci. Představte si, že vytvoříte vztah mezi dvěma entitami a poté je spojíte do jedné entity.
Co bude dál?
Uvedené příklady vám pomohou identifikovat různé scénáře, které vyžadují vztah jeden k mnoha. Můžete začít navrhovat svou vlastní databázovou strukturu pomocí Vertabelo Database Modeler, webového nástroje, který vám umožní nejen vygenerovat logický model, ale také vytvořit jeho fyzickou verzi pro poskytovatele databáze, kterého potřebujete.
Nyní je řada na vás – použijte sekci komentářů a sdělte nám svůj názor na tento článek, položte další otázky nebo se podělte o své zkušenosti s modelováním databáze.