Při dotazování na data pomocí SQL je potřeba manipulovat s výsledky založenými na řetězcích velmi běžná. Pro tento úkol existuje mnoho možností napříč hlavními relačními databázovými systémy. V tomto článku probereme případ použití a funkčnost funkce REPLACE SQL.
Začínáme s REPLACE
Funkce FIND and REPLACE je každému dobře známá, protože přichází s jakýmkoli textovým editorem. ANSI SQL nabízí funkci REPLACE ve formě vestavěné systémové funkce. V tomto článku budu jako RDMS používat SQL Server.
REPLACE Parametry funkcí
REPLACE (řetězcový_výraz, vzor_řetězce, nahrazení_řetězce)
Řetězcový_výraz je řetězec, který bude transformován, může to být jeden řetězec nebo sloupec z příchozího SQL dotazu.
Vzor_řetězce je vyhledávací vzor, který je aplikován na řetězcový výraz, který má být nahrazen.
Náhrada_řetězce je náhradní hodnota použitá na řetězec při řetězci _pattern odpovídá řetězcovému_výrazu .
Podívejme se na několik příkladů, abychom lépe porozuměli funkci REPLACE.
Vytvoření ukázkových dat
Pro tento příklad vytvořím dočasnou tabulku pro použití s funkcí REPLACE. Názvy sloupců budou odpovídat hodnotám parametrů funkce.
IF OBJECT_ID(N'tempdb..#TEMP_REPLACE_DEMO') IS NOT NULL
DROP TABLE #TEMP_REPLACE_DEMO
CREATE TABLE #TEMP_REPLACE_DEMO
(
ID INT IDENTITY(1,1),
STRING_EXPRESSION VARCHAR(2000),
STRING_PATTERN VARCHAR(200),
STRING_REPLACEMENT VARCHAR(200)
)
--REPLACE THE VALUE CAR WITH FOX
INSERT INTO #TEMP_REPLACE_DEMO
VALUES('The red car is the fastest car in the race.','car','fox')
--REPLACE THE VALUE 4 WITH 8
INSERT INTO #TEMP_REPLACE_DEMO
VALUES('There are 4 model ford cars in the parking lot.','4','8')
--REMOVE THE BLANK SPACE CHARACTER
INSERT INTO #TEMP_REPLACE_DEMO
VALUES(' This sentence has irregular spacing . ',' ','')
Jednoduché a dynamické REPLACE Příklady
Nyní, když je tabulka načtena ukázkovými daty, pojďme se podívat, jak NAHRADIT funkci lze aplikovat na data na základní úrovni a poté v dynamičtější kapacitě.
V prvním příkladu jsou parametry pevně zakódovány jako řetězcové hodnoty funkce.
--REPLACE THE VALUE CAR WITH FOX
SELECT REPLACE('The red car is the fastest car in the race.','car','fox') AS RESULT_FOR_SENTENCE

Hodnoty lze také číst z tabulky dynamicky. V tomto případě jsou hodnoty výrazu, vzoru a nahrazení všechny čteny z tabulky přímo, místo toho, aby byly pevně zakódovány.
--DYNAMIC EXAMPLE FOR ALL COLUMNS IN THE TABLE.
SELECT ID,REPLACE(STRING_EXPRESSION,STRING_PATTERN,STRING_REPLACEMENT) AS RESULT_FOR_TABLE
FROM #TEMP_REPLACE_DEMO
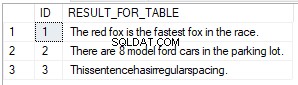
Výsledky pro ID 1 jsou stejné jako v příkladu výše, rozdíl je pouze v tom, že hodnoty byly načteny z jednotlivých sloupců.
Vnořené náhrady
Funkci REPLACE lze také použít ve vnořené kapacitě. To znamená, že výsledky vnitřní funkce REPLACE se mohou stát parametrem STRING_EXPRESSION vnější funkce nahrazení.
Zde je několik příkladů tohoto vzoru na ukázkových datech:
--REPLACE THE VALUE CAR WITH FOX | REPLACE THE VALUE "fastest" WITH "slowest"
SELECT REPLACE(REPLACE('The red car is the fastest car in the race.','car','fox'),'fastest','slowest')
--REMOVE THE BLANK SPACE CHARACTER | REPLACE THE VALUE "irregular" with "no"
SELECT REPLACE(REPLACE(' This sentence has irregular spacing . ',' ',''),'irregular','NO')
Řazení a REPLACE v SQL
Řazení je důležitým faktorem, který je třeba vzít v úvahu při práci s daty řetězce a funkci REPLACE. Porovnání lze nastavit na více úrovních databáze, jako je úroveň účtu nebo instance, databáze, schématu, relace nebo úrovně tabulky. Toto nastavení může ovlivnit fungování funkce REPLACE.
V tomto příkladu nelze očekávat, že bude velké A nahrazeno malým b. Závisí to však na řazení, které se dědí do aktuálního připojení k databázi.
--REPLACEMENT WITHOUT EXPLICIT COLLATION.
SELECT REPLACE('A','a','b') AS DEFAULT_COLLATION
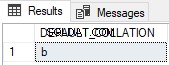
Tento výsledek odpovídá a až A kvůli řazení.
Nastavení řazení v SQL Server lze zkontrolovat na úrovni serveru:
--VIEW CURRENT COLLATION
SELECT CONVERT (varchar(256), SERVERPROPERTY('collation'));
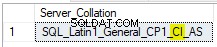
Klíčem je zde CI, což znamená nerozlišovat malá a velká písmena. Chcete-li použít funkci REPLACE v kapacitě rozlišující malá a velká písmena, lze parametr string_expression explicitně seřadit.
-- USE COLLATE TO MATCH CHARACTER CASING FOR REPLACE
SELECT REPLACE('A' COLLATE Latin1_General_CS_AS ,'a','b') as Explicit_Collation;
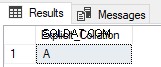
Protože je v tomto příkladu parametr string_expression porovnáván s rozlišením velkých a malých písmen, nenahrazuje funkce REPLACE původní hodnotu.
Shrnutí
Funkce REPLACE je skvělý nástroj pro základní a pokročilou manipulaci s řetězci napříč více relačními databázovými systémy. Tento článek zkoumal základní aplikaci funkce REPLACE, jak ji používat v dynamické kapacitě. Také jsme diskutovali o použití REPLACE jako vnořené funkce a o tom, jak může řazení ovlivnit výsledky, které vrací.