V posledním měsíci jsem jednal s mnoha zákazníky, kteří měli problémy s implicitní konverzí na straně sloupců spojené s jejich pracovní zátěží OLTP. Při dvou příležitostech byl nahromaděný účinek implicitních převodů na straně sloupců základní příčinou celkového problému s výkonem pro kontrolovaný SQL Server a bohužel neexistuje žádná magická možnost nastavení nebo konfigurace, kterou bychom mohli vylepšit, abychom situaci zlepšili. když tomu tak je. I když můžeme nabídnout návrhy na opravu jiných, níže visících plodů, které by mohly ovlivňovat celkový výkon, účinek implicitních konverzí na straně sloupců je něco, co vyžaduje buď opravu návrhu schématu, nebo změnu kódu, aby se zabránilo vzniku sloupců. postranní konverze se zcela neprovede proti aktuálnímu schématu databáze.
Implicitní převody jsou výsledkem toho, že databázový stroj porovnává hodnoty různých datových typů během provádění dotazu. Seznam možných implicitních převodů, které by mohly nastat uvnitř databázového stroje, lze nalézt v tématu Books Online Data Type Conversion (Database Engine). K implicitním převodům dochází vždy na základě priorit datových typů pro datové typy, které jsou během operace porovnávány. Pořadí priorit datových typů lze nalézt v tématu Books Online Precedence datových typů (Transact-SQL). Nedávno jsem blogoval o implicitních konverzích, které vedou ke skenování indexu, a poskytl jsem grafy, které lze použít také k určení nejproblematičtějších implicitních konverzí.
Nastavení testů
Abych demonstroval režii výkonu spojenou s implicitními převody na straně sloupců, které vedou ke skenování indexu, provedl jsem řadu různých testů proti databázi AdventureWorks2012 pomocí tabulky Sales.SalesOrderDetail k vytvoření testovacích tabulek a sad dat. Nejběžnější implicitní konverze na straně sloupce, kterou vidím jako konzultant, nastává, když je typ sloupce char nebo varchar a kód aplikace předá parametr, který je nchar nebo nvarchar, a filtruje sloupec char nebo varchar. Pro simulaci tohoto typu scénáře jsem vytvořil kopii tabulky SalesOrderDetail (s názvem SalesOrderDetail_ASCII) a změnil sloupec CarrierTrackingNumber z nvarchar na varchar. Navíc jsem do původní tabulky SalesOrderDetail přidal neshlukovaný index do sloupce CarrierTrackingNumber a také do nové tabulky SalesOrderDetail_ASCII.
USE [AdventureWorks2012]
GO
-- Add CarrierTrackingNumber index to original Sales.SalesOrderDetail table
IF NOT EXISTS
(
SELECT 1 FROM sys.indexes
WHERE [object_id] = OBJECT_ID(N'Sales.SalesOrderDetail')
AND name=N'IX_SalesOrderDetail_CarrierTrackingNumber'
)
BEGIN
CREATE INDEX IX_SalesOrderDetail_CarrierTrackingNumber
ON Sales.SalesOrderDetail (CarrierTrackingNumber);
END
GO
IF OBJECT_ID('Sales.SalesOrderDetail_ASCII') IS NOT NULL
BEGIN
DROP TABLE Sales.SalesOrderDetail_ASCII;
END
GO
CREATE TABLE Sales.SalesOrderDetail_ASCII
(
SalesOrderID int NOT NULL,
SalesOrderDetailID int NOT NULL IDENTITY (1, 1),
CarrierTrackingNumber varchar(25) NULL,
OrderQty smallint NOT NULL,
ProductID int NOT NULL,
SpecialOfferID int NOT NULL,
UnitPrice money NOT NULL,
UnitPriceDiscount money NOT NULL,
LineTotal AS (isnull(([UnitPrice]*((1.0)-[UnitPriceDiscount]))*[OrderQty],(0.0))),
rowguid uniqueidentifier NOT NULL ROWGUIDCOL,
ModifiedDate datetime NOT NULL
);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII ON;
GO
INSERT INTO Sales.SalesOrderDetail_ASCII
(
SalesOrderID, SalesOrderDetailID, CarrierTrackingNumber,
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
)
SELECT
SalesOrderID, SalesOrderDetailID, CONVERT(varchar(25), CarrierTrackingNumber),
OrderQty, ProductID, SpecialOfferID, UnitPrice,
UnitPriceDiscount, rowguid, ModifiedDate
FROM Sales.SalesOrderDetail WITH (HOLDLOCK TABLOCKX);
GO
SET IDENTITY_INSERT Sales.SalesOrderDetail_ASCII OFF;
GO
ALTER TABLE Sales.SalesOrderDetail_ASCII ADD CONSTRAINT
PK_SalesOrderDetail_ASCII_SalesOrderID_SalesOrderDetailID
PRIMARY KEY CLUSTERED (SalesOrderID, SalesOrderDetailID);
CREATE UNIQUE NONCLUSTERED INDEX AK_SalesOrderDetail_ASCII_rowguid
ON Sales.SalesOrderDetail_ASCII (rowguid);
CREATE NONCLUSTERED INDEX IX_SalesOrderDetail_ASCII_ProductID
ON Sales.SalesOrderDetail_ASCII (ProductID);
CREATE INDEX IX_SalesOrderDetail_ASCII_CarrierTrackingNumber
ON Sales.SalesOrderDetail_ASCII (CarrierTrackingNumber);
GO Nová tabulka SalesOrderDetail_ASCII má 121 317 řádků a má velikost 17,5 MB a bude použita k vyhodnocení režie malé tabulky. Také jsem vytvořil tabulku, která je desetkrát větší, pomocí upravené verze skriptu Enlarging the AdventureWorks Sample Databases z mého blogu, která obsahuje 1 334 487 řádků a má velikost 190 MB. Testovacím serverem je stejný virtuální počítač se 4 vCPU se 4 GB RAM, se systémem Windows Server 2008 R2 a SQL Server 2012, s aktualizací Service Pack 1 a kumulativní aktualizací 3, který jsem použil v předchozích článcích, takže tabulky se zcela vejdou do paměti. , což eliminuje režii disku I/O z ovlivnění spouštěných testů.
Testovací zátěž byla vygenerována pomocí řady skriptů PowerShell, které vyberou seznam CarrierTrackingNumbers z tabulky SalesOrderDetail vytvořením ArrayList, a poté náhodně vyberou CarrierTrackingNumber z ArrayList pro dotaz na tabulku SalesOrderDetail_ASCII pomocí parametru varchar a poté parametru nvarchar, a pak dotaz na tabulku SalesOrderDetail pomocí parametru nvarchar, aby bylo možné porovnat, kde jsou sloupec i parametr nvarchar. Každý z jednotlivých testů spustí příkaz 10 000krát, aby bylo možné měřit režii výkonu při trvalé zátěži.
#No Implicit Conversions
$loop = 10000;
Write-Host "Small table no conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::VarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table no conversion end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table implicit conversions
$loop = 10000;
Write-Host "Small table implicit conversions start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail_ASCII "
"WHERE CarrierTrackingNumber = @CTNumber;";
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table implicit conversions end time:"
[DateTime]::Now
Sleep -Seconds 10;
#Small table unicode no implicit conversions
$loop = 10000;
Write-Host "Small table unicode no implicit conversion start time:"
[DateTime]::Now
$query = @"SELECT * FROM Sales.SalesOrderDetail "
"WHERE CarrierTrackingNumber = @CTNumber;"
while($loop -gt 0)
{
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = $query;
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CTNumber", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::NVarChar;
$SqlParameter.Size = 30;
$SqlCmd.ExecuteNonQuery() | Out-Null;
$loop--;
}
Write-Host "Small table unicode no implicit conversion end time:"
[DateTime]::Now Druhá sada testů byla spuštěna proti tabulkám SalesOrderDetailEnlarged_ASCII a SalesOrderDetailEnlarged pomocí stejné parametrizace jako první sada testů, aby se ukázal rozdíl v režii, protože velikost dat uložených v tabulce se postupem času zvyšuje. Poslední sada testů byla také spuštěna s tabulkou SalesOrderDetail s použitím sloupce ProductID jako sloupce filtru s typy parametrů int, bigint a smallint, aby bylo možné porovnat režii implicitních konverzí, které nevedou ke skenování indexu. pro srovnání.
Poznámka:Všechny skripty jsou připojeny k tomuto článku, aby bylo možné reprodukovat implicitní převodní testy pro další vyhodnocení a srovnání.
Výsledky testu
Během každého spouštění testu byl nástroj Performance Monitor nakonfigurován tak, aby spouštěl sadu kolekcí dat, která zahrnovala čítače Processor\% času procesoru a SQL Server:SQLStatisitics\Batch Requests/s pro sledování režie výkonu pro každý z testů. Kromě toho byly Extended Events nakonfigurovány tak, aby sledovaly událost rpc_completed, aby bylo možné sledovat průměrnou dobu trvání, cpu_time a logická čtení pro každý z testů.
Small Table CarrierTrackingNumber Výsledky
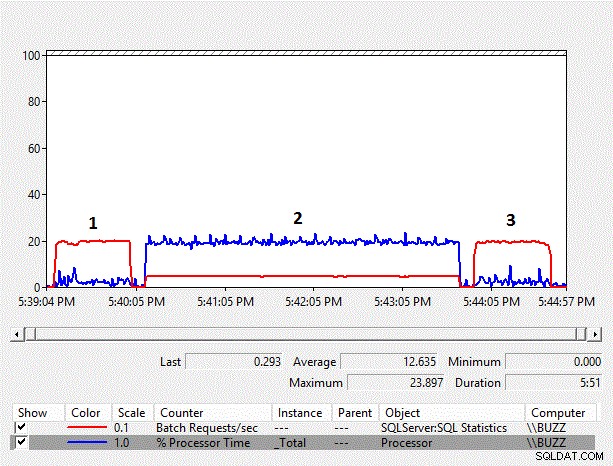
Obrázek 1 – Tabulka počítadel pro sledování výkonu
| TestID | Typ dat sloupce | Typ dat parametru | Prům. % času procesoru | Prům. dávkové požadavky/s | Trvání h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 2.5 | 192,3 | 0:00:51 |
| 2 | Varchar | Nvarchar | 19.4 | 46,7 | 0:03:33 |
| 3 | Nvarchar | Nvarchar | 2.6 | 192,3 | 0:00:51 |
Tabulka 2 – Průměrné údaje sledování výkonu
Z výsledků můžeme vidět, že implicitní převod na straně sloupců z varchar na nvarchar a výsledné skenování indexu má významný dopad na výkon zátěže. Průměrný % času procesoru pro test implicitního převodu na straně sloupce (TestID =2) je téměř desetkrát delší než u ostatních testů, kde nedocházelo k implicitnímu převodu na straně sloupce, jehož výsledkem je prohledávání indexu. Navíc průměrný počet požadavků na dávku/s pro test implicitní konverze na straně sloupce byl těsně pod 25 % ostatních testů. Trvání testů, kde nedocházelo k implicitním převodům, trvalo 51 sekund, i když byla data v testu číslo 3 uložena jako nvarchar pomocí datového typu nvarchar, což vyžadovalo dvojnásobný úložný prostor. To se očekává, protože tabulka je stále menší než fond vyrovnávacích pamětí.
| TestID | Prům. cpu_time (µs) | Průměrná doba trvání (µs) | Prům. logická_čtení |
|---|---|---|---|
| 1 | 40,7 | 154,9 | 51,6 |
| 2 | 15 640,8 | 15 760,0 | 385,6 |
| 3 | 45,3 | 169,7 | 52,7 |
Tabulka 3 – Průměry rozšířených událostí
Data shromážděná událostí rpc_completed v Extended Events ukazují, že průměrný cpu_time, trvání a logická čtení spojená s dotazy, které neprovádějí implicitní převod na straně sloupce, jsou zhruba ekvivalentní, kde implicitní převod na straně sloupce zatěžuje značné množství CPU. režii a také delší průměrné trvání s výrazně logičtějším čtením.
Výsledky rozšířené tabulky CarrierTrackingNumber
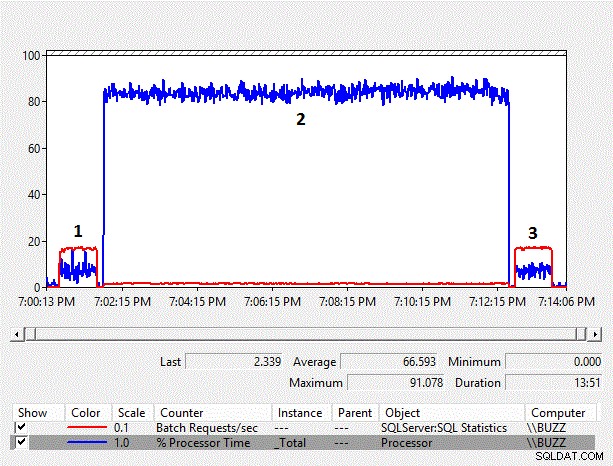
Obrázek 4 – Tabulka počítadel pro sledování výkonu
| TestID | Typ dat sloupce | Typ dat parametru | Prům. % času procesoru | Prům. dávkové požadavky/s | Trvání h:mm:ss |
|---|---|---|---|---|---|
| 1 | Varchar | Varchar | 7.2 | 164,0 | 0:01:00 |
| 2 | Varchar | Nvarchar | 83,8 | 15.4 | 0:10:49 |
| 3 | Nvarchar | Nvarchar | 7.0 | 166,7 | 0:01:00 |
Tabulka 5 – Průměrné údaje sledování výkonu
S rostoucí velikostí dat se také zvyšuje výkonová režie implicitního převodu na straně sloupců. Průměrný % času procesoru pro test implicitního převodu na straně sloupce (TestID =2) je opět téměř desetkrát delší než u ostatních testů, kde nedocházelo k implicitnímu převodu na straně sloupce, jehož výsledkem je skenování indexu. Navíc průměrný počet požadavků na dávku/s pro test implicitní konverze na straně sloupce byl těsně pod 10 % ostatních testů. Trvání testů, kde nedocházelo k implicitním konverzím, trvalo jednu minutu, zatímco test implicitní konverze na straně sloupce vyžadoval provedení téměř jedenáct minut.
| TestID | Prům. cpu_time (µs) | Průměrná doba trvání (µs) | Prům. logická_čtení |
|---|---|---|---|
| 1 | 728,5 | 1 036,5 | 569,6 |
| 2 | 214 174,6 | 59 519,1 | 4 358,2 |
| 3 | 821,5 | 1 032,4 | 553,5 |
Tabulka 6 – Průměry rozšířených událostí
Výsledky Extended Events skutečně začínají ukazovat režii výkonu způsobenou implicitními převody na straně sloupců pro pracovní zátěž. Průměrný cpu_time na provedení vyskočí na více než 214 ms a je více než 200krát vyšší než cpu_time pro příkazy, které nemají implicitní převody na straně sloupců. Trvání je také téměř 60krát delší než u příkazů, které nemají implicitní konverze na straně sloupců.
Shrnutí
Vzhledem k tomu, že velikost dat neustále narůstá, režie spojená s implicitními konverzemi na straně sloupců, které vedou k indexovému skenování pro pracovní zátěž, bude také nadále růst, a důležité je zapamatovat si, že v určitém okamžiku nebude žádné množství hardwaru bude schopen zvládnout režii výkonu. Implicitním převodům lze snadno zabránit, pokud existuje dobrý návrh schématu databáze a vývojáři dodržují dobré techniky kódování aplikací. V situacích, kdy postupy kódování aplikací vedou k parametrizaci, která využívá parametrizaci nvarchar, je lepší přizpůsobit návrh schématu databáze parametrizaci dotazu, než používat v návrhu databáze sloupce varchar a způsobovat režii výkonu z implicitního převodu na straně sloupců.
Stáhněte si ukázkové skripty:Implicit_Conversion_Tests.zip (5 KB)