Pro každou novou databázi vytvořenou na serveru SQL je výchozí hodnota pro možnost Auto Update Statistics povoleno . Mám podezření, že většina správců databází nechává tuto možnost povolenou, protože umožňuje optimalizátoru automaticky aktualizovat statistiky, když jsou zrušeny, a obecně se doporučuje nechat ji povolenou. Statistiky se také aktualizují, když jsou indexy znovu sestaveny, a přestože není neobvyklé, že statistiky jsou dobře spravovány pomocí možnosti automatické aktualizace statistik a přes znovu sestavení indexu, čas od času může správce DBA zjistit, že je nutné nastavit pravidelnou úlohu pro aktualizaci statistika nebo soubor statistik.
Vlastní správa statistik často zahrnuje příkaz UPDATE STATISTICS, který se zdá být docela neškodný. Lze jej spustit pro všechny statistiky pro tabulku nebo indexované zobrazení nebo pro konkrétní statistiku. Lze použít výchozí vzorek, určit konkrétní vzorkovací frekvenci nebo počet řádků k vzorkování nebo můžete použít stejnou hodnotu vzorku, která byla použita dříve. Pokud jsou statistiky aktualizovány pro tabulku nebo indexované zobrazení, můžete se rozhodnout aktualizovat všechny statistiky, pouze statistiky indexu nebo pouze statistiky sloupců. A nakonec můžete deaktivovat možnost automatické aktualizace statistik pro statistiku.
Pro většinu správců databází může být největším hlediskem kdy ke spuštění příkazu UPDATE STATISTICS. Ale správci databází také rozhodují, ať už vědomě nebo ne, velikost vzorku pro aktualizaci. Vybraná velikost vzorku může ovlivnit výkon aktuální aktualizace a také výkon dotazů.
Porozumění účinkům velikosti vzorku
Výchozí velikost vzorku pro UPDATE STATISTICS pochází z nelineárního algoritmu a velikost vzorku se zmenšuje, jak se zvětšuje velikost tabulky, jak ukázal Joe Sack ve svém příspěvku Auto-Update Stats Default Sampling Test. V některých případech nemusí být velikost vzorku dostatečně velká, aby zachytila dostatek zajímavých informací, nebo správně informace pro statistický histogram, jak poznamenal Conor Cunningham ve svém příspěvku Statistics Sample Races. Pokud výchozí vzorek nevytváří dobrý histogram, správci databází se mohou rozhodnout aktualizovat statistiky s vyšší vzorkovací frekvencí až do FULLSCAN (prohledávání všech řádků v tabulce nebo indexovaném zobrazení). Jak ale Conor zmínil ve svém příspěvku, skenování více řádků něco stojí a DBA se musí rozhodnout, zda spustit FULLSCAN a pokusit se vytvořit „nejlepší“ histogram, nebo odebrat vzorek menšího procenta, aby se minimalizoval dopad na výkon. aktualizace.
Abych se pokusil pochopit, v jakém okamžiku vzorek trvá déle než FULLSCAN, provedl jsem následující příkazy proti kopiím tabulky SalesOrderDetail, které byly zvětšeny pomocí skriptu Jonathana Kehayiase:
| ID výpisu | Prohlášení AKTUALIZACE STATISTIKY |
|---|---|
| 1 | AKTUALIZACE STATISTIKY [Prodej].[SalesOrderDetailEnlarged] POMOCÍ FULLSCAN; |
| 2 | AKTUALIZACE STATISTIKY [Prodeje].[SalesOrderDetailEnlarged]; |
| 3 | AKTUALIZACE STATISTIKY [Prodeje].[SalesOrderDetailEnlarged] S VZOREM 10 PROCENT; |
| 4 | AKTUALIZOVAT STATISTIKY [Prodeje].[SalesOrderDetailEnlarged] U VZORKU 25 PROCENT; |
| 5 | AKTUALIZACE STATISTIKY [Prodeje].[SalesOrderDetailEnlarged] S VZOREM 50 PROCENT; |
| 6 | AKTUALIZOVAT STATISTIKY [Prodeje].[SalesOrderDetailEnlarged] U VZORKU 75 PROCENT; |
Měl jsem tři kopie tabulky SalesOrderDetailEnlarged s následujícími charakteristikami*:
| Počet řádků | Počet stránek | MAXDOP | Max. paměť | Úložiště | Stroj |
|---|---|---|---|---|---|
| 23 899 449 | 363 284 | 4 | 8 GB | SSD_1 | Laptop |
| 607 312 902 | 7 757 200 | 16 | 54 GB | SSD_2 | Testovací server |
| 607 312 902 | 7 757 200 | 16 | 54 GB | 15 kB | Testovací server |
*Další podrobnosti o hardwaru jsou na konci tohoto příspěvku.
Všechny kopie tabulky měly následující statistiky a žádná ze tří statistik indexu neobsahovala sloupce:
| Statistika | Typ | Sloupce v klíči |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Index | SalesOrderID, SalesOrderDetailID |
| AK_SalesOrderDetailEnlarged_rowguid | Index | rowguid |
| IX_SalesOrderDetailEnlarged_ProductID | Index | ID produktu |
| user_CarrierTrackingNumber | Sloupec | CarrierTrackingNumber |
Výše uvedené příkazy UPDATE STATISTICS jsem spustil čtyřikrát každý proti tabulce SalesOrderDetailEnlarged na mém notebooku a dvakrát proti tabulkám SalesOrderDetailEnlarged na TestServeru. Příkazy byly spouštěny pokaždé v náhodném pořadí a mezipaměť procedur a mezipaměť vyrovnávací paměti byly vymazány před každým příkazem aktualizace. Doba trvání a využití databáze tempdb pro každou sadu příkazů (průměrné) jsou v grafech níže:
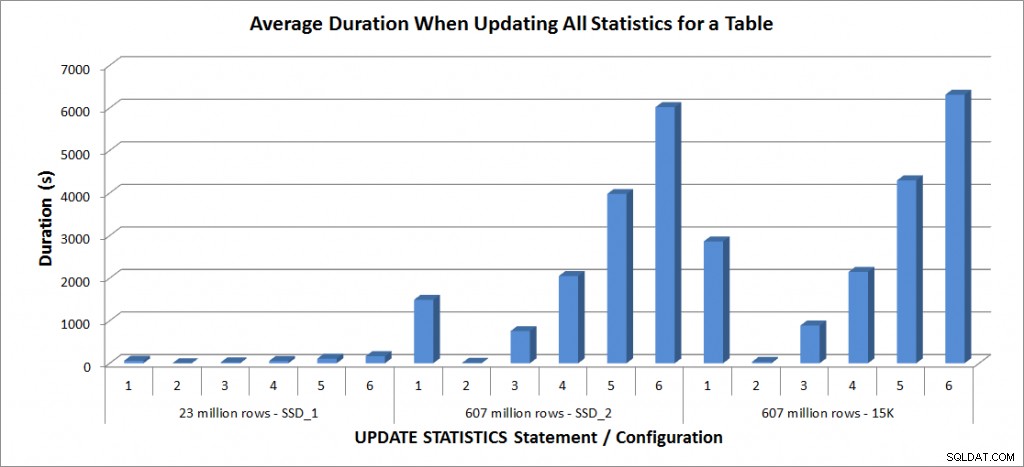
Průměrná doba trvání – aktualizace všech statistik pro SalesOrderDetailEnlarged
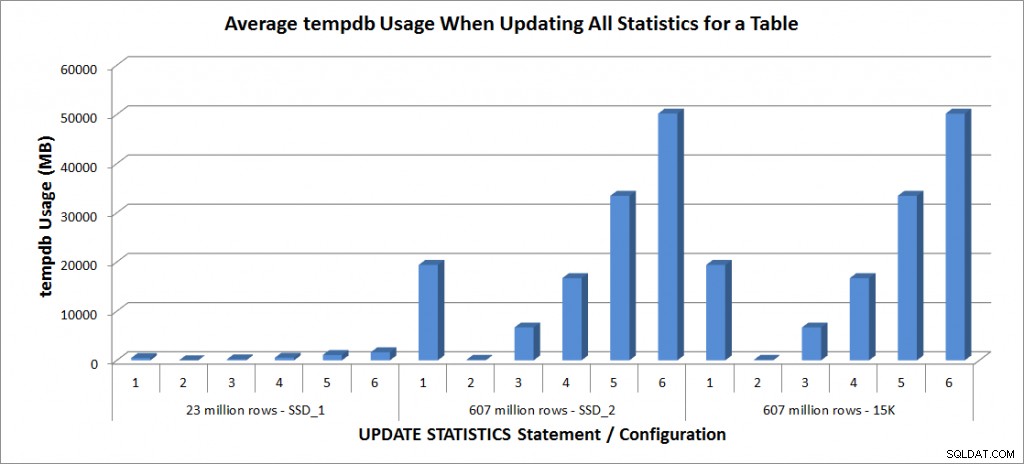
Využití tempdb – aktualizace všech statistik pro SalesOrderDetailEnlarged
Doba trvání pro tabulku s 23 miliony řádků byla kratší než tři minuty a jsou podrobněji popsány v další části. U tabulky na discích SSD_2 trval příkaz FULLSCAN 1492 sekund (téměř 25 minut) a aktualizace s 25% vzorkem trvala 2051 sekund (přes 34 minut). Naproti tomu na 15K discích trval příkaz FULLSCAN 2864 sekund (přes 47 minut) a aktualizace s 25% vzorkem trvala 2147 sekund (téměř 36 minut) – méně než čas FULLSCAN. Aktualizace s 50% vzorkem však trvala 4296 sekund (přes 71 minut).
Využití tempdb je mnohem konzistentnější, vykazuje stálý nárůst s rostoucí velikostí vzorku a využívá více prostoru tempdb než FULLSCAN někde mezi 25 % a 50 %. Zde je pozoruhodné, že AKTUALIZACE STATISTIKY dělá použít tempdb, což je důležité si pamatovat při dimenzování databáze tempdb pro prostředí SQL Server. Použití Tempdb je uvedeno v položce BOL AKTUALIZACE STATISTIC:
UPDATE STATISTICS může použít tempdb k seřazení vzorku řádků pro vytváření statistik.“
A účinek je zdokumentován v příspěvku Linchi Shea, Performance impact:tempdb and update statistics. Během diskusí o dimenzování tempdb to však není vždy zmíněno. Pokud máte velké tabulky a provádíte aktualizace pomocí FULLSCAN nebo vysokých vzorových hodnot, uvědomte si využití databáze tempdb.
Výkon selektivních aktualizací
Dále jsem se rozhodl otestovat příkazy UPDATE STATISTICS pro ostatní statistiky v tabulce, ale omezil jsem své testy na kopii tabulky s 23 miliony řádků. Výše uvedených šest variant příkazu UPDATE STATISTICS bylo opakováno čtyřikrát pro následující jednotlivé statistiky a poté porovnány s aktualizací pro celou tabulku:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Všechny testy byly spuštěny s výše uvedenou konfigurací na mém notebooku a výsledky jsou v grafu níže:
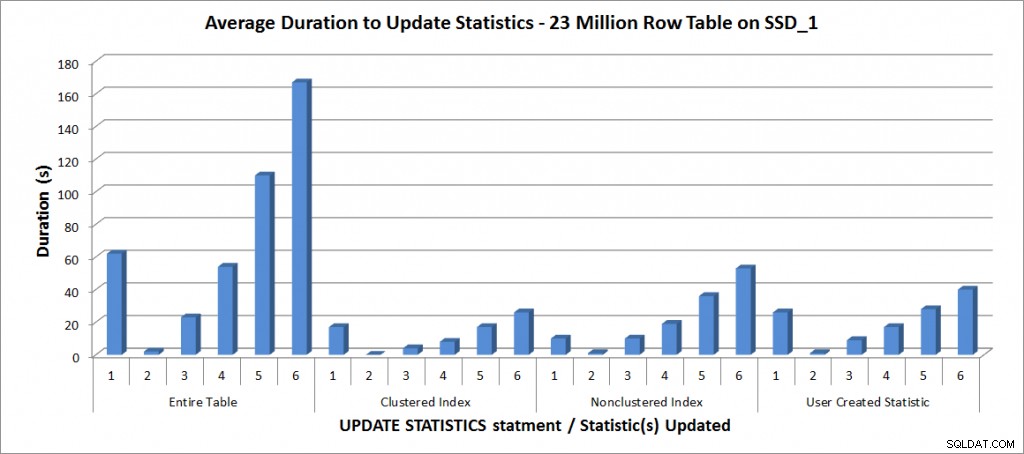
Průměrná doba trvání AKTUALIZACE STATISTIKY – všechny statistiky vs. vybrané
Jak se očekávalo, aktualizace jednotlivých statistik trvaly kratší dobu než aktualizace všech statistik pro tabulku. Hodnota, při které aktualizace vzorku trvala déle než FULLSCAN, se lišila:
| příkaz UPDATE | FULLSCAN trvání (s) | První AKTUALIZACE, která trvala déle |
|---|---|---|
| Celá tabulka | 62 | 50 % – 110 sekund |
| Shlukovaný index | 17 | 75 % – 26 sekund |
| Neshlukovaný index | 10 | 25 % – 19 sekund |
| Statistika vytvořená uživatelem | 26 | 50 % – 28 sekund |
Závěr
Na základě těchto údajů a údajů FULLSCAN z 607 milionů řádkových tabulek neexistuje žádný konkrétní bod zlomu, kdy aktualizace vzorku trvá déle než FULLSCAN; tento bod závisí na velikosti tabulky a dostupných zdrojích. Data však stále stojí za to, protože ukazují, že existují bod, kdy může zachycení nasamplované hodnoty trvat déle než FULLSCAN. Opět jde o znalost vašich dat. To je důležité nejen pro pochopení toho, zda tabulka potřebuje vlastní správu statistik, ale také pro pochopení ideální velikosti vzorku pro vytvoření užitečného histogramu a také pro optimalizaci využití zdrojů.
Specifikace
Specifikace notebooku:Dell M6500, 1 Intel i7 (2,13 GHz 4 jádra a HT je povoleno, takže 8 logických jader), 32 GB paměti, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), databázové soubory uložené na 265GB Samsung SSD PM810Specifikace testovacího serveru:Dell R720, 2 Intel E5-2670 (2,6 GHz 8 jader a HT je povoleno, takže 16 logických jader na soket), 64 GB paměti, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), databázové soubory pro jedna tabulka je umístěna na dvou 640GB Fusion-io Duo MLC kartách, databázové soubory pro druhou tabulku jsou na devíti 15K RPM discích v poli RAID5