Jeden z případů použití filtrovaného indexu zmíněný v Books Online se týká sloupce, který obsahuje většinou NULLs hodnoty. Cílem je vytvořit filtrovaný index, který vylučuje NULLs Výsledkem je menší neklastrovaný index, který vyžaduje méně údržby než ekvivalentní nefiltrovaný index. Další oblíbené použití filtrovaných indexů je filtrování NULLs z UNIQUE index, který dává chování, které uživatelé jiných databázových strojů mohou očekávat od výchozího UNIQUE index nebo omezení:jedinečnost je vynucena pouze pro neNULLs hodnoty.
Optimalizátor dotazů má bohužel omezení, pokud jde o filtrované indexy. Tento příspěvek se zabývá několika méně známými příklady.
Ukázkové tabulky
Použijeme dvě tabulky (A a B), které mají stejnou strukturu:náhradní seskupený primární klíč, většinou -NULLs sloupec, který je jedinečný (bez ohledu na NULLs ) a výplňový sloupec, který představuje ostatní sloupce, které mohou být ve skutečné tabulce.
Sloupec zájmu je většinou -NULLs jeden, který jsem deklaroval jako SPARSE . Řídká možnost není vyžadována, jen ji zahrnuji, protože nemám moc příležitostí ji použít. V každém případě SPARSE pravděpodobně dává smysl v mnoha scénářích, kde se očekává, že data sloupce budou většinou NULLs . Pokud chcete, můžete atribut sparse z příkladů odstranit.
CREATE TABLE dbo.TableA( pk integer PRIMÁRNÍ KLÍČ IDENTITY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x); CREATE TABLE dbo.TableB( pk integer PRIMÁRNÍ KLÍČ IDENTITY, data bigint SPARSE NULL, padding binary(250) NOT NULL DEFAULT 0x);
Každá tabulka obsahuje čísla od 1 do 2 000 v datovém sloupci a dalších 40 000 řádků, kde je datový sloupec NULLs :
-- Čísla 1 – 2 000 INSERT dbo.TableA S (TABLOCKX) (data)SELECT TOP (2000) ŘÁDEK_ČÍSLO() NAD (ORDER BY (SELECT NULL))FROM sys.columns AS cCROSS JOIN sys.columns AS c2ORDER BY ROW_NUMBER() OVER (ORDER BY (SELECT NULL)); -- NULLsINSERT TOP (40000) dbo.TableA WITH (TABLOCKX) (data)SELECT CONVERT(bigint, NULL)FROM sys.columns AS cCROSS JOIN sys.columns AS c2; -- Zkopírujte do TableBINSERT dbo.TableB WITH (TABLOCKX) (data)SELECT ta.dataFROM dbo.TableA AS ta;
Obě stoly mají UNIQUE filtrovaný index pro 2 000 non-NULLs datové hodnoty:
VYTVOŘENÍ UNIKÁTNÍHO NENCLUSTEROVANÉHO INDEXU uqAON dbo.TableA (data) KDE data NENÍ NULL; VYTVOŘTE UNIKÁTNÍ NEZAHRNUTÝ INDEX uqBON dbo.TableB (data) KDE data NENÍ NULL;
Výstup DBCC SHOW_STATISTICS shrnuje situaci:
DBCC SHOW_STATISTICS (tabulkaA, uqA) SE STAT_HEADER;DBCC SHOW_STATISTICS (tabulkaB, uqB) SE STAT_HEADER;

Ukázkový dotaz
Dotaz níže provede jednoduché spojení dvou tabulek – představte si, že tabulky jsou v nějakém vztahu rodič-dítě a mnoho cizích klíčů má hodnotu NULL. Každopádně něco v tom smyslu.
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data;
Výchozí plán provádění
S SQL Serverem ve výchozí konfiguraci si optimalizátor vybere plán provádění s paralelním spojením vnořených smyček:
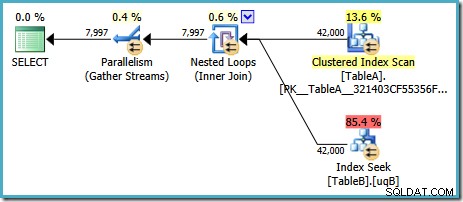
Tento plán má odhadovanou cenu 7,7768 jednotky pro optimalizaci magie™.
Tento plán má však několik podivných věcí. Hledání indexu používá náš filtrovaný index v tabulce B, ale dotaz je řízen skenováním klastrovaného indexu tabulky A. Predikát spojení je test rovnosti na datových sloupcích, který odmítne NULLs (bez ohledu na ANSI_NULLS nastavení). Mohli jsme doufat, že optimalizátor provede nějakou pokročilou úvahu založenou na tomto pozorování, ale ne. Tento plán čte každý řádek z tabulky A (včetně 40 000 NULLs ), provede pro každý z nich vyhledávání filtrovaného indexu v tabulce B, přičemž se spoléhá na skutečnost, že NULLs nebude odpovídat NULLs v tom hledání. To je ohromné plýtvání úsilím.
Zvláštní je, že optimalizátor si musel uvědomit, že spojení odmítá NULLs aby bylo možné vybrat filtrovaný index pro vyhledávání tabulky B, ale nenapadlo jej filtrovat NULLs nejprve z tabulky A – nebo ještě lépe, jednoduše naskenujte NULLs -free filtrovaný index v tabulce A. Možná se ptáte, zda se jedná o rozhodnutí založené na nákladech, možná statistiky nejsou příliš dobré? Možná bychom si měli vynutit použití filtrovaného indexu nápovědou? Tipování filtrovaného indexu v tabulce A má za následek stejný plán s obrácenými rolemi – skenování tabulky B a vyhledávání do tabulky A. Vynucení filtrovaného indexu pro obě tabulky způsobí chybu 8622 :procesor dotazů nemohl vytvořit plán dotazů.
Přidání predikátu NOT NULL
Podezření na příčinu, že má něco společného s předpokládaným NULLs -zamítnutí predikátu spojení, přidáme explicitní NOT NULL predikát na ON klauzule (nebo WHERE klauzule, chcete-li, zde jde o totéž):
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data NENÍ NULL;
Přidali jsme NOT NULL zkontrolujte sloupec tabulky A, protože původní plán naskenoval seskupený index této tabulky místo použití našeho filtrovaného indexu (vyhledávání do tabulky B bylo v pořádku – používal filtrovaný index). Nový dotaz je sémanticky úplně stejný jako předchozí, ale plán provádění je jiný:
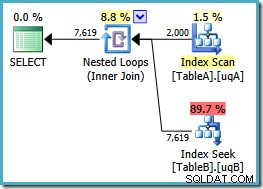
Nyní máme očekávané skenování filtrovaného indexu v tabulce A, výsledkem je 2 000 non-NULLs řádků pro řízení vnořených smyček do tabulky B. Obě tabulky využívají naše filtrované indexy nyní zřejmě optimálně:nový plán stojí pouhých 0,362835 jednotek (pokles ze 7,7768). Můžeme to však udělat lépe.
Přidání dvou predikátů NOT NULL
Nadbytečné NOT NULL predikát pro tabulku A dokázal zázraky; co se stane, když přidáme jedničku i pro tabulku B?
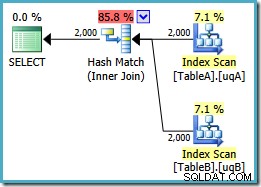
VYBERTE ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data NENÍ NULL A tb.data NENÍ NULL;
Tento dotaz je stále logicky stejný jako dva předchozí pokusy, ale plán provádění je opět odlišný:
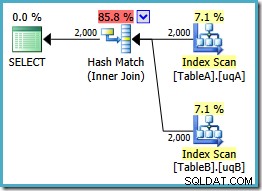
Tento plán vytvoří hašovací tabulku pro 2 000 řádků z tabulky A, poté hledá shody pomocí 2 000 řádků z tabulky B. Odhadovaný počet vrácených řádků je mnohem lepší než předchozí plán (všimli jste si tam odhadu 7 619?) a odhadované náklady na provedení opět klesly, z 0,362835 na 0,0772056 .
Můžete zkusit vynutit spojení hash pomocí nápovědy k původnímu nebo jednoduchému-NOT NULL dotazy, ale nezískáte výše uvedený nízkonákladový plán. Optimalizátor prostě nemá schopnost plně zdůvodnit NULLs -odmítnutí chování spojení, protože se vztahuje na naše filtrované indexy bez obou redundantních predikátů.
Můžete se tím nechat překvapit – i když je to jen myšlenka, že jeden redundantní predikát nestačil (jistě pokud ta.data je NOT NULL a ta.data = tb.data , z toho vyplývá, že tb.data je také NOT NULL , že?)
Stále to není dokonalé
Je trochu překvapivé, že tam vidíte spojení hash. Pokud jste obeznámeni s hlavními rozdíly mezi třemi fyzickými operátory spojení, pravděpodobně víte, že hash join je nejlepším kandidátem, kde:
- Předtříděný vstup není k dispozici
- Vstup sestavení hash je menší než vstup sondy
- Vstup sondy je poměrně velký
Žádná z těchto věcí zde není pravda. Naším očekáváním by bylo, že nejlepším plánem pro tento dotaz a sadu dat by bylo sloučení spojení využívající uspořádaný vstup dostupný z našich dvou filtrovaných indexů. Můžeme se pokusit naznačit sloučení spojení a ponechat dvě nadbytečné ON větné predikáty:
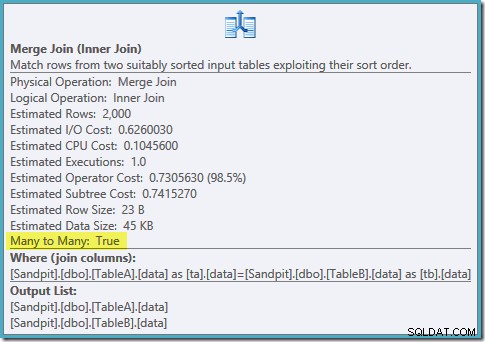
SELECT ta.data, tb.dataFROM dbo.TableA AS taJOIN dbo.TableB AS tb ON ta.data =tb.data AND ta.data NENÍ NULL A tb.data NENÍ NULLOPTION (MERGE JOIN);Tvar plánu je takový, jak jsme doufali:
Seřazený sken obou filtrovaných indexů, skvělé odhady mohutnosti, fantastické. Jen jeden malý problém:tento plán provádění je mnohem horší; odhadovaná cena vyskočila z 0,0772056 na 0,741527 . Důvod skokového nárůstu odhadovaných nákladů je odhalen kontrolou vlastností operátoru sloučení:
Toto je drahé spojení many-to-many, kde prováděcí modul musí sledovat duplikáty z vnějšího vstupu v pracovní tabulce a podle potřeby je přetáčet. duplikáty? Skenujeme unikátní index! Ukázalo se, že optimalizátor neví, že filtrovaný jedinečný index vytváří jedinečné hodnoty (připojit položku zde). Ve skutečnosti se jedná o spojení typu one-to-one, ale optimalizátor to stojí, jako by to bylo many-to-many, což vysvětluje, proč preferuje plán spojení hash.
Alternativní strategie
Zdá se, že při používání filtrovaných indexů zde stále narážíme na omezení optimalizátoru (přestože se jedná o zvýrazněný případ použití v Books Online). Co se stane, když místo toho zkusíme použít zobrazení?
Použití zobrazení
Následující dva pohledy pouze filtrují základní tabulky, aby zobrazily řádky, kde je datový sloupec
NOT NULL:CREATE VIEW dbo.VAWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableWHERE data NOT NULL;GOCREATE VIEW dbo.VBWITH SCHEMABINDING ASSELECT pk, data, paddingFROM dbo.TableBWHERE data NOT NULL;Přepsání původního dotazu pro použití zobrazení je triviální:
SELECT v.data, v2.dataFROM dbo.VA AS vJOIN dbo.VB AS v2 ON v.data =v2.data;Pamatujte si, že tento dotaz původně vytvořil plán paralelních vnořených smyček za cenu 7,7768 Jednotky. S odkazy na zobrazení získáme tento plán provádění:
Toto je přesně stejný plán spojení hash, který jsme museli přidat nadbytečné
NOT NULLpredikáty získat s filtrovanými indexy (cena je 0,0772056 jednotky jako dříve). To se očekává, protože vše, co jsme zde v podstatě udělali, je vložit extraNOT NULLpredikáty z dotazu do pohledu.Indexování zobrazení
Můžeme se také pokusit zhmotnit pohledy vytvořením jedinečného seskupeného indexu ve sloupci pk:
VYTVOŘTE UNIKÁTNÍ KLUSTEROVÝ INDEX cuq NA dbo.VA (pk);VYTVOŘTE UNIKÁTNÍ KLUSTEROVÝ INDEX cuq NA dbo.VB (pk);Nyní můžeme do sloupce filtrovaných dat v indexovaném zobrazení přidat jedinečné indexy bez seskupení:
VYTVOŘTE UNIKÁTNÍ NENEKLUSTROVANÝ INDEX ix NA dbo.VA (data);VYTVOŘTE UNIKÁTNÍ NENCLUSTEROVANÝ INDEX ix NA dbo.VB (data);Všimněte si, že filtrování se provádí v zobrazení, tyto neseskupené indexy nejsou samy filtrovány.
Dokonalý plán
Nyní jsme připraveni spustit dotaz proti zobrazení pomocí
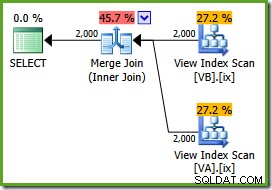
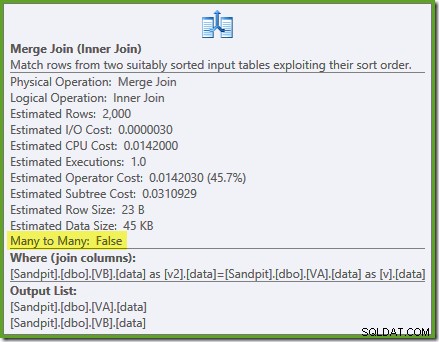
NOEXPANDnápověda k tabulce:SELECT v.data, v2.dataFROM dbo.VA AS v WITH (NOEXPAND) PŘIPOJTE SE dbo.VB AS v2 WITH (NOEXPAND) ON v.data =v2.data;Prováděcí plán je:
Optimalizátor vidí nefiltrované indexy neklastrovaného zobrazení jsou jedinečné, takže sloučení typu many-to-many není potřeba. Tento konečný plán realizace má odhadované náklady 0,0310929 jednotek – ještě nižší než plán spojení hash (0,0772056 jednotek). To potvrzuje naše očekávání, že sloučení by mělo mít nejnižší odhadované náklady na tento dotaz a ukázkovou sadu dat.
NOEXPANDrady jsou potřeba i v Enterprise Edition, aby se zajistilo, že optimalizátor použije záruku jedinečnosti poskytovanou indexy zobrazení.Shrnutí
Tento příspěvek zdůrazňuje dvě důležitá omezení optimalizátoru s filtrovanými indexy:
- K porovnání filtrovaných indexů mohou být nutné redundantní predikáty spojení
- Filtrované jedinečné indexy neposkytují optimalizátoru informace o jedinečnosti
V některých případech může být praktické jednoduše přidat redundantní predikáty ke každému dotazu. Alternativou je zapouzdřit požadované implikované predikáty do neindexovaného pohledu. Plán shody hash v tomto příspěvku byl mnohem lepší než výchozí plán, i když optimalizátor by měl být schopen najít o něco lepší plán spojení sloučení. Někdy může být nutné indexovat zobrazení a použít NOEXPAND rady (požadované pro instance Standard Edition). Za ještě jiných okolností nebude žádný z těchto přístupů vhodný. Omlouvám se za to :)