[ Část 1 | Část 2 | Část 3 | Část 4 ]
V první části této série jsme viděli, jak se Halloweenský problém vztahuje na UPDATE dotazy. Abychom to stručně shrnuli, problém byl v tom, že index používaný k vyhledání záznamů k aktualizaci měl své klíče upravené samotnou operací aktualizace (další dobrý důvod pro použití zahrnutých sloupců v indexu namísto rozšíření klíčů). Optimalizátor dotazů zavedl operátor Eager Table Spool, který odděluje strany pro čtení a zápis v prováděcím plánu, aby se předešlo problému. V tomto příspěvku uvidíme, jak může stejný základní problém ovlivnit INSERT a DELETE prohlášení.
Vložit prohlášení
Nyní víme trochu o podmínkách, které vyžadují ochranu Halloween, je docela snadné vytvořit INSERT příklad, který zahrnuje čtení a zápis do klíčů stejné indexové struktury. Nejjednodušším příkladem je duplikování řádků v tabulce (kde přidání nových řádků nevyhnutelně změní klíče seskupeného indexu):
CREATE TABLE dbo.Demo
(
SomeKey integer NOT NULL,
CONSTRAINT PK_Demo
PRIMARY KEY (SomeKey)
);
INSERT dbo.Demo
SELECT SomeKey FROM dbo.Demo; Problém je v tom, že na nově vložené řádky může narazit čtecí strana prováděcího plánu, což může mít za následek smyčku, která přidává řádky navždy (nebo alespoň do dosažení určitého limitu zdrojů). Optimalizátor dotazů toto riziko rozpozná a přidá Eager Table Spool, aby zajistil potřebné oddělení fází :
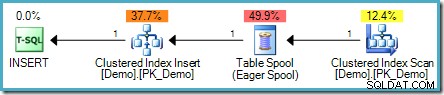
Realističtější příklad
Pravděpodobně často nepíšete dotazy pro duplikování každého řádku v tabulce, ale pravděpodobně zapisujete dotazy, kde cílová tabulka pro INSERT se také objeví někde v SELECT doložka. Jedním příkladem je přidání řádků z pracovní tabulky, které v cíli ještě neexistují:
CREATE TABLE dbo.Staging
(
SomeKey integer NOT NULL
);
-- Sample data
INSERT dbo.Staging
(SomeKey)
VALUES
(1234),
(1234);
-- Test query
INSERT dbo.Demo
SELECT s.SomeKey
FROM dbo.Staging AS s
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Demo AS d
WHERE d.SomeKey = s.SomeKey
); Prováděcí plán je:
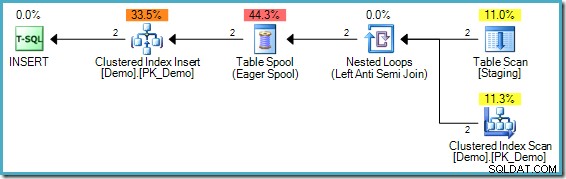
Problém v tomto případě je mírně odlišný, i když stále jde o příklad stejného základního problému. V cílové demo tabulce není žádná hodnota ‚1234‘, ale tabulka Staging obsahuje dvě takové položky. Bez oddělení fází by byla první nalezená hodnota „1234“ úspěšně vložena, ale druhá kontrola by zjistila, že hodnota „1234“ nyní existuje a nepokusí se ji znovu vložit. Příkaz jako celek by byl úspěšně dokončen.
To může v tomto konkrétním případě přinést žádoucí výsledek (a může se dokonce zdát intuitivně správný), ale není to správná implementace. Standard SQL vyžaduje, aby se dotazy na úpravu dat prováděly tak, jako by tři fáze omezení čtení, zápisu a kontroly probíhaly zcela odděleně (viz část jedna).
Při hledání všech řádků k vložení jako jedné operace bychom měli vybrat oba řádky ‚1234‘ z tabulky Staging, protože tato hodnota v cíli ještě neexistuje. Prováděcí plán by se proto měl pokusit vložit obě „1234“ řádků z pracovní tabulky, což má za následek porušení primárního klíče:
Msg 2627, Level 14, State 1, Line 1Porušení omezení PRIMARY KEY 'PK_Demo'.
Nelze vložit duplicitní klíč do objektu 'dbo.Demo'.
Duplicitní hodnota klíče je ( 1234).
Výpis byl ukončen.
Oddělení fází poskytované tabulkou Spool zajišťuje, že všechny kontroly existence jsou dokončeny před provedením jakýchkoli změn v cílové tabulce. Pokud spustíte dotaz na serveru SQL Server s ukázkovými daty výše, zobrazí se (správná) chybová zpráva.
Halloweenská ochrana je vyžadována pro příkazy INSERT, kde je cílová tabulka také odkazována v klauzuli SELECT.
Smazat výpisy
Můžeme očekávat, že Halloweenský problém se nebude vztahovat na DELETE příkazy, protože by ve skutečnosti nemělo záležet na tom, jestli se pokusíme smazat řádek vícekrát. Náš příklad pracovní tabulky můžeme upravit na odstranit řádky z ukázkové tabulky, které v Stagingu neexistují:
TRUNCATE TABLE dbo.Demo;
TRUNCATE TABLE dbo.Staging;
INSERT dbo.Demo (SomeKey) VALUES (1234);
DELETE dbo.Demo
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Staging AS s
WHERE s.SomeKey = dbo.Demo.SomeKey
); Zdá se, že tento test potvrzuje naši intuici, protože v prováděcím plánu není žádná tabulka Spool:
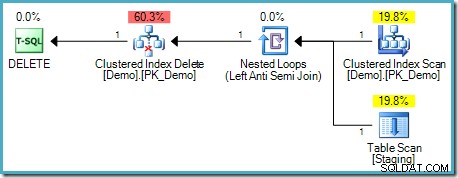
Tento typ DELETE nevyžaduje oddělení fází, protože každý řádek má jedinečný identifikátor (RID, pokud je tabulka hromada, seskupený indexový klíč (klíče) a případně uniquifikátor jinak). Tento jedinečný lokátor řádků je stabilní klíč – neexistuje žádný mechanismus, kterým by se to mohlo změnit během provádění tohoto plánu, takže Halloweenský problém nevzniká.
SMAZAT Halloweenskou ochranu
Přesto existuje alespoň jeden případ, kdy DELETE vyžaduje halloweenskou ochranu:když plán odkazuje na jiný řádek v tabulce než na ten, který se odstraňuje. To vyžaduje vlastní spojení, které se běžně vyskytuje při modelování hierarchických vztahů. Níže je uveden zjednodušený příklad:
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', 'A'),
('C', 'B'),
('D', 'C');
Zde by skutečně měla být definována reference cizího klíče se stejnou tabulkou, ale pomiňme na chvíli, že návrh selže – struktura a data jsou přesto platné (a je bohužel docela běžné najít cizí klíče v reálném světě vynechané). Úkolem je každopádně smazat každý řádek s ref sloupec ukazuje na neexistující pk hodnota. Přirozené DELETE dotaz odpovídající tomuto požadavku je:
DELETE dbo.Test
WHERE NOT EXISTS
(
SELECT 1
FROM dbo.Test AS t2
WHERE t2.pk = dbo.Test.ref
); Plán dotazů je:
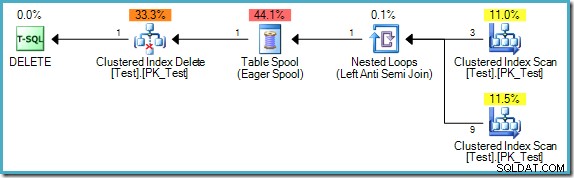
Všimněte si, že tento plán nyní obsahuje nákladnou Eager Table Spool. Zde je vyžadováno oddělení fází, protože jinak by výsledky mohly záviset na pořadí, ve kterém jsou řádky zpracovávány:
Pokud prováděcí stroj začíná řádkem, kde pk =B, nenajde žádný odpovídající řádek (ref =A a není zde žádný řádek pk =A). Pokud se provedení přesune na řádek pk =C, bude také odstraněn, protože jsme právě odstranili řádek B, na který ukazuje jeho ref sloupec. Konečným výsledkem by bylo, že iterativní zpracování v tomto pořadí by smazalo všechny řádky z tabulky, což je zjevně nesprávné.
Na druhou stranu, pokud prováděcí modul zpracoval řádek s pk =D nejprve najde odpovídající řádek (ref =C). Za předpokladu, že provádění pokračuje obráceně pk řádu, bude z tabulky odstraněn pouze řádek s pk =B. Toto je správný výsledek (pamatujte, že dotaz by se měl provést, jako kdyby fáze čtení, zápisu a ověřování probíhaly postupně a bez překrývání).
Oddělení fází pro ověření omezení
Kromě toho můžeme vidět další příklad oddělení fází, pokud k předchozímu příkladu přidáme omezení cizího klíče stejné tabulky:
DROP TABLE dbo.Test;
CREATE TABLE dbo.Test
(
pk char(1) NOT NULL,
ref char(1) NULL,
CONSTRAINT PK_Test
PRIMARY KEY (pk),
CONSTRAINT FK_ref_pk
FOREIGN KEY (ref)
REFERENCES dbo.Test (pk)
);
INSERT dbo.Test
(pk, ref)
VALUES
('B', NULL),
('C', 'B'),
('D', 'C'); Plán provádění pro INSERT je:
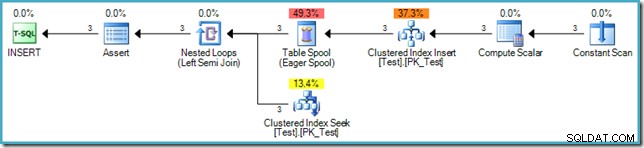
Samotný insert nevyžaduje halloweenskou ochranu, protože plán nečte ze stejné tabulky (zdrojem dat je in-memory virtuální tabulka reprezentovaná operátorem Constant Scan). Standard SQL však vyžaduje, aby fáze 3 (kontrola omezení) nastala po dokončení fáze zápisu. Z tohoto důvodu je do plánu po přidána fázová separace Eager Table Spool index Clustered Index a těsně před každým řádkem se kontroluje, aby bylo zajištěno, že omezení cizího klíče zůstává platné.
Pokud si začínáte myslet, že překlad deklarativního SQL modifikačního dotazu založeného na množinách na robustní iterativní plán fyzického provádění je složitá záležitost, začínáte chápat, proč je zpracování aktualizací (jehož Halloween Protection je jen velmi malou součástí) nejsložitější část procesoru dotazů.
Příkazy DELETE vyžadují ochranu Halloween, kde je přítomno vlastní spojení cílové tabulky.
Shrnutí
Halloween Protection může být drahá (ale nezbytná) funkce v prováděcích plánech, které mění data (kde „změna“ zahrnuje veškerou syntaxi SQL, která přidává, mění nebo odebírá řádky). Pro UPDATE je vyžadována Halloweenská ochrana plány, kde se klíče společné indexové struktury čtou i upravují, pro INSERT plány, kde se odkazuje na cílovou tabulku na straně čtení plánu, a pro DELETE plány, kde se provádí vlastní připojení k cílové tabulce.
Další část této série se bude zabývat některými speciálními optimalizacemi Halloweenského problému, které se vztahují pouze na MERGE prohlášení.
[ Část 1 | Část 2 | Část 3 | Část 4 ]