Dlouho jsem zastáncem výběru správného datového typu. O některých příkladech jsem mluvil v předchozím příspěvku na blogu „Bad Habits“, ale tento víkend na SQL Saturday #162 (Cambridge, UK), téma používání DATETIME standardně přišel. V konverzaci po mé prezentaci T-SQL:Bad Habits and Best Practices uživatel uvedl, že používá pouze DATETIME i když potřebují pouze granularitu na minutu nebo den, tímto způsobem jsou sloupce data a času v jejich podniku vždy stejného datového typu. Naznačil jsem, že by to mohlo být plýtvání a že ta konzistence nemusí stát za to, ale dnes jsem se rozhodl svou teorii dokázat.
Verze TL;DR
Mé testování níže odhaluje, že určitě existují scénáře, kdy možná budete chtít zvážit použití tenčího datového typu místo toho, abyste zůstali u DATETIME všude. Ale je důležité vidět, kam mé testy ukázaly jinou cestu, a je také důležité otestovat tyto scénáře proti vašemu schématu ve vašem prostředí s hardwarem a daty, které jsou co nejvěrnější produkci. Vaše výsledky se mohou a téměř jistě budou lišit.
Tabulky cílů
Uvažujme případ, kdy je granularita důležitá pouze pro den (nezajímají nás hodiny, minuty, sekundy). K tomu bychom mohli zvolit DATETIME (jako uživatel navrhl), nebo SMALLDATETIME nebo DATE na SQL Server 2008+. Existují také dva různé typy dat, které jsem chtěl zvážit:
- Data, která by byla vkládána zhruba sekvenčně v reálném čase (např. události, které se právě dějí);
- Údaje, které by byly vkládány náhodně (např. data narození nových členů).
Začal jsem se 2 tabulkami jako je tato, pak jsem vytvořil 4 další (2 pro SMALLDATETIME, 2 pro DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime( ID INT IDENTITY(1,1) PRIMÁRNÍ KLÍČ, dt DATETIME NOT NULL); CREATE TABLE dbo.EventsSequential_Datetime( ID INT IDENTITY(1,1) PRIMÁRNÍ KLÍČ, dt DATETIME NOT NULL); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt);CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Poté opakujte pro DATE a SMALLDATETIME.
A mým cílem bylo otestovat výkon dávkového vkládání těmito dvěma různými způsoby, stejně jako dopad na celkovou velikost úložiště a fragmentaci a nakonec výkon dotazů na rozsah.
Ukázková data
Abych vygeneroval nějaká ukázková data, použil jsem jednu ze svých šikovných technik pro generování něčeho smysluplného z něčeho, co není:pohledy katalogu. V mém systému to vrátilo 971 různých hodnot data/času (celkem 1 000 000 řádků) za přibližně 12 sekund:
;WITH y AS ( SELECT TOP (1000000) d =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101')) FROM ( SELECT s1.[object_id] % 1000 FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ) AS x(x) ORDER BY NEWID()) SELECT DISTINCT d FROM y;
Vložil jsem tyto miliony řádků do tabulky, abych mohl simulovat sekvenční/náhodné vkládání pomocí různých metod přístupu pro přesně stejná data ze tří různých oken relace:
CREATE TABLE dbo.Staging( ID INT IDENTITY(1,1) PRIMÁRNÍ KLÍČ, zdrojové_datum DATETIME NOT NULL);;WITH Staging_Data AS ( SELECT TOP (1000000) dt =DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101')) FROM ( SELECT s1.[id_object] % 1000 FROM sys.all_object AS s1 CROSS JOIN sys.all_objects AS s2 ) AS sd(x) ORDER BY NEWID())INSERT dbo.Staging(source_date) SELECT dt FROM y ORDER BY dt;
Dokončení tohoto procesu trvalo o něco déle (20 sekund). Potom jsem vytvořil druhou tabulku pro ukládání stejných dat, ale distribuovaných náhodně (abych mohl opakovat stejnou distribuci ve všech vložkách).
CREATE TABLE dbo.Staging_Random( ID INT IDENTITY(1,1) PRIMÁRNÍ KLÍČ, zdrojové_datum DATETIME NOT NULL); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Dotazy k naplnění tabulek
Dále jsem napsal sadu dotazů k naplnění ostatních tabulek těmito daty pomocí tří oken dotazů k simulaci alespoň trochu souběžnosti:
WAITFOR TIME '13:53';GO DECLARE @d DATETIME2 =SYSDATETIME(); INSERT dbo.{table_name}(dt) -- v závislosti na metodě / datovém typu SELECT source_date FROM dbo.Staging[_Random] -- v závislosti na cíli WHERE ID % 3 =<0,1,2> -- v závislosti na okně dotazu ORDER DLE ID; SELECT DATEDIFF(MILISECOND, @d, SYSDATETIME()); Stejně jako v mém posledním příspěvku jsem předem rozšířil databázi, abych zabránil tomu, aby jakýkoli typ událostí automatického růstu datových souborů interferoval s výsledky. Uvědomuji si, že není zcela reálné provádět vkládání milionů řádků v jednom průchodu, protože nemohu zabránit rušení aktivity protokolu u tak velké transakce, ale mělo by to dělat konzistentně u každé metody. Vzhledem k tomu, že hardware, se kterým testuji, je zcela odlišný od hardwaru, který používáte, neměly by být absolutní výsledky klíčovým bodem, ale pouze relativním srovnáním.
(V budoucím testu to také zkusím se skutečnými dávkami přicházejícími ze souborů protokolu s relativně smíšenými daty a s použitím částí zdrojové tabulky v cyklech – myslím, že by to byly také zajímavé experimenty. A samozřejmě přidání stlačení do směsi.)
Výsledky:
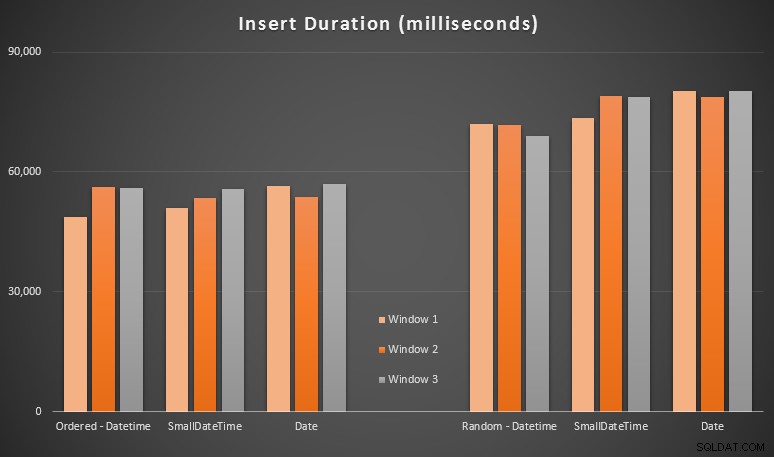
Tyto výsledky pro mě nebyly až tak překvapivé – vkládání v náhodném pořadí vedlo k delší době běhu než vkládání sekvenčně, což je něco, co můžeme všichni vrátit ke kořenům pochopení toho, jak fungují indexy na serveru SQL a jak může dojít k většímu „špatnému“ rozdělení stránek. tento scénář (v tomto cvičení jsem konkrétně nesledoval rozdělení stránek, ale je to něco, o čem budu uvažovat v budoucích testech).
Všiml jsem si, že na náhodné straně mohly mít implicitní konverze příchozích dat dopad na načasování, protože se zdály o něco vyšší než nativní DATETIME -> DATETIME vložky. Rozhodl jsem se tedy vytvořit dvě nové tabulky obsahující zdrojová data:jednu pomocí DATE a jeden pomocí SMALLDATETIME . To by do určité míry simulovalo správný převod vašeho datového typu před jeho předáním do příkazu insert, takže během vkládání není vyžadována implicitní konverze. Zde jsou nové tabulky a způsob jejich naplnění:
CREATE TABLE dbo.Staging_Random_SmallDatetime( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL); CREATE TABLE dbo.Staging_Random_Date( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
To nemělo účinek, v který jsem doufal – načasování bylo ve všech případech podobné. Tak to byla divoká honička.
Využitý prostor a fragmentace
Spustil jsem následující dotaz, abych zjistil, kolik stránek bylo rezervováno pro každou tabulku:
SELECT name ='dbo.' + OBJECT_NAME([id_objektu]), stránky =SUM(počet_rezervovaných_stránek)FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([id_objektu])ORDER BY stránek;
Výsledky:
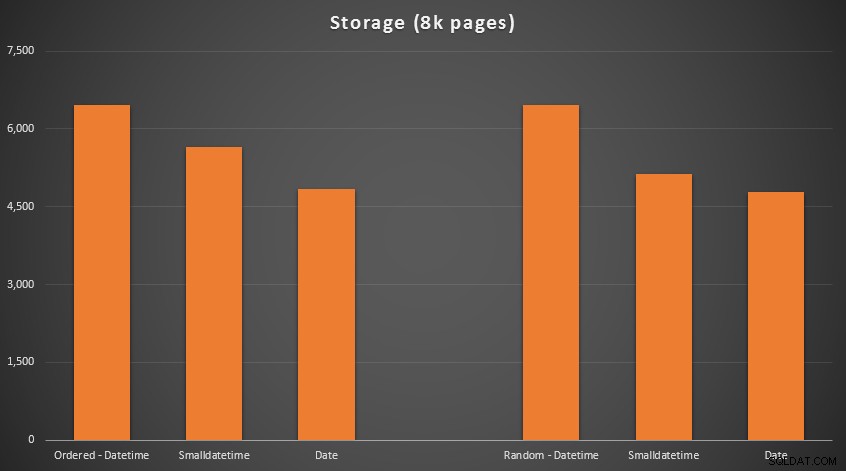
Žádná raketová věda zde; použijte menší datový typ, měli byste použít méně stránek. Přepínání z DATETIME do DATE konzistentně přinášelo 25% snížení počtu použitých stránek, zatímco SMALLDATETIME snížil požadavek o 13–20 %.
Nyní k fragmentaci a hustotě stránek u indexů bez seskupení (u indexů seskupených byl velmi malý rozdíl):
SELECT '{table_name}', index_id avg_page_space_used_in_percent, avg_fragmentation_in_percent FROM sys.dm_db_index_physical_stats ( DB_ID(), OBJECT_ID('{table_name}'), NULL, NULL, 'DETAILOVANÁ_úroveň_0' =index 'DETAILED 2; <) /před>
Výsledky:
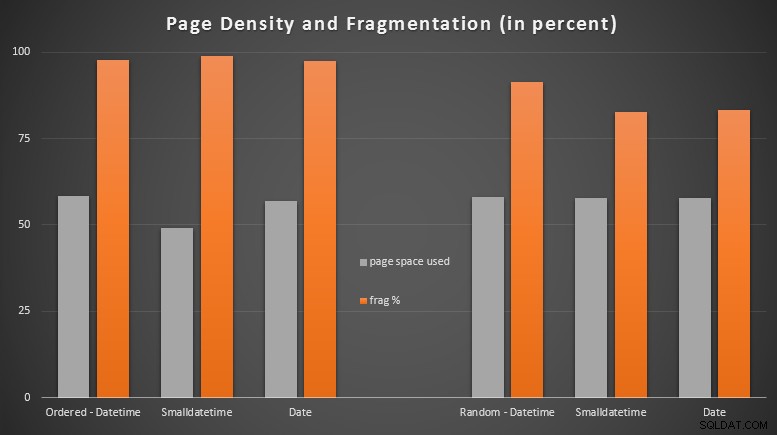
Byl jsem docela překvapen, když jsem viděl, že objednaná data jsou téměř úplně fragmentovaná, zatímco data, která byla vkládána náhodně, ve skutečnosti skončila s mírně lepším využitím stránky. Poznamenal jsem, že to vyžaduje další prošetření mimo rozsah těchto specifických testů, ale může to být něco, co budete chtít zkontrolovat, pokud máte indexy bez klastrů, které se spoléhají převážně na sekvenční vkládání.
[Online přestavba neklastrovaných indexů na všech 6 tabulkách proběhla za 7 sekund, čímž se hustota stránek vrátila zpět na rozsah 99,5 % a fragmentace se snížila pod 1 %. Ale nespustil jsem to, dokud jsem neprovedl níže uvedené testy dotazů…]
Test dotazu na rozsah
Nakonec jsem chtěl vidět dopad na běhová prostředí pro jednoduché dotazy na časové období proti různým indexům, a to jak s vlastní fragmentací způsobenou činností zápisu typu OLTP, tak na čistý index, který je přestavěn. Samotný dotaz je docela jednoduchý:
VYBRAT TOP (200000) dt FROM dbo.{table_name} WHERE dt>='20110101' ORDER BY dt;
Zde jsou výsledky před přestavěním indexů pomocí SQL Sentry Plan Explorer:
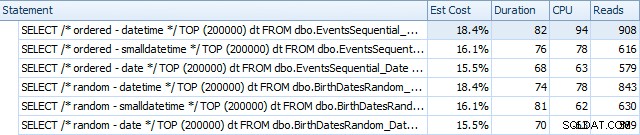
A po přestavbách se mírně liší:
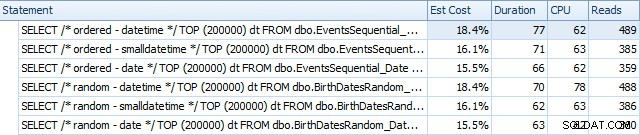
V podstatě vidíme mírně vyšší trvání a čtení pro verze DATETIME, ale velmi malý rozdíl v CPU. A rozdíly mezi SMALLDATETIME a DATE jsou ve srovnání s tím zanedbatelné. Všechny dotazy měly zjednodušené plány dotazů, jako je tento:

(Vyhledávání je samozřejmě uspořádané skenování rozsahu.)
Závěr
I když jsou tyto testy dosti vymyšlené a mohly by těžit z více permutací, ukazují zhruba to, co jsem očekával, že uvidím:největší dopady na tuto konkrétní volbu jsou na prostor obsazený neshlukovaným indexem (kde výběr tenčího datového typu určitě přínosem) a na čas potřebný k provedení vkládání v libovolném, nikoli sekvenčním pořadí (kde DATETIME má pouze okrajovou hranu).
Rád bych slyšel vaše nápady, jak podřídit volby typu dat, jako jsou tyto, důkladnějšími a trestuhodnějšími testy. Mám v plánu jít do dalších podrobností v budoucích příspěvcích.