Když byl SQL Server 2012 stále ve verzi beta, napsal jsem blog o novém FORMAT() funkce:SQL Server v.Next (Denali) :CTP3 Vylepšení T-SQL :FORMAT().
V té době jsem byl z nové funkcionality tak nadšený, že mě ani nenapadlo provádět nějaké testování výkonu. Řešil jsem to v novějším příspěvku na blogu, ale výhradně v souvislosti s odstraňováním času z data a času:Oříznutí času z data a času – následná činnost.
Minulý týden mě můj dobrý přítel Jason Horner (blog | @jasonhorner) tweetoval těmito tweety:
| |
Můj problém je právě v tom FORMAT() vypadá pohodlně, ale ve srovnání s jinými přístupy je extrémně neefektivní (aha a to AS VARCHAR věc je taky špatná). Pokud to děláte jednou za dva a pro malé sady výsledků, moc bych se tím netrápil; ale v měřítku to může být pěkně drahé. Dovolte mi to ilustrovat na příkladu. Nejprve vytvořte malou tabulku s 1000 pseudonáhodnými daty:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Nyní naplníme mezipaměť daty z této tabulky a ilustrujme tři běžné způsoby, jakými lidé mají tendenci prezentovat právě čas:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Nyní proveďte jednotlivé dotazy, které používají tyto různé techniky. Spustíme je každý 5krát a spustíme následující varianty:
- Výběr všech 1 000 řádků
- Výběr TOP (1) seřazený podle seskupeného indexového klíče
- Přiřazení k proměnné (což vynutí úplné skenování, ale zabrání tomu, aby vykreslování SSMS narušovalo výkon)
Zde je skript:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Nyní můžeme měřit výkon pomocí následujícího dotazu (můj systém je docela tichý; na vašem možná budete muset provést pokročilejší filtrování než jen execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
Výsledky v mém případě byly poměrně konzistentní:
| Dotaz (zkrácený) | Trvání (mikrosekundy) | |||
|---|---|---|---|---|
| total_elapsed | avg_elapsed | total_clr | ||
| VYBERTE 1 000 řádků | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time výstup (kliknutím zvětšíte):
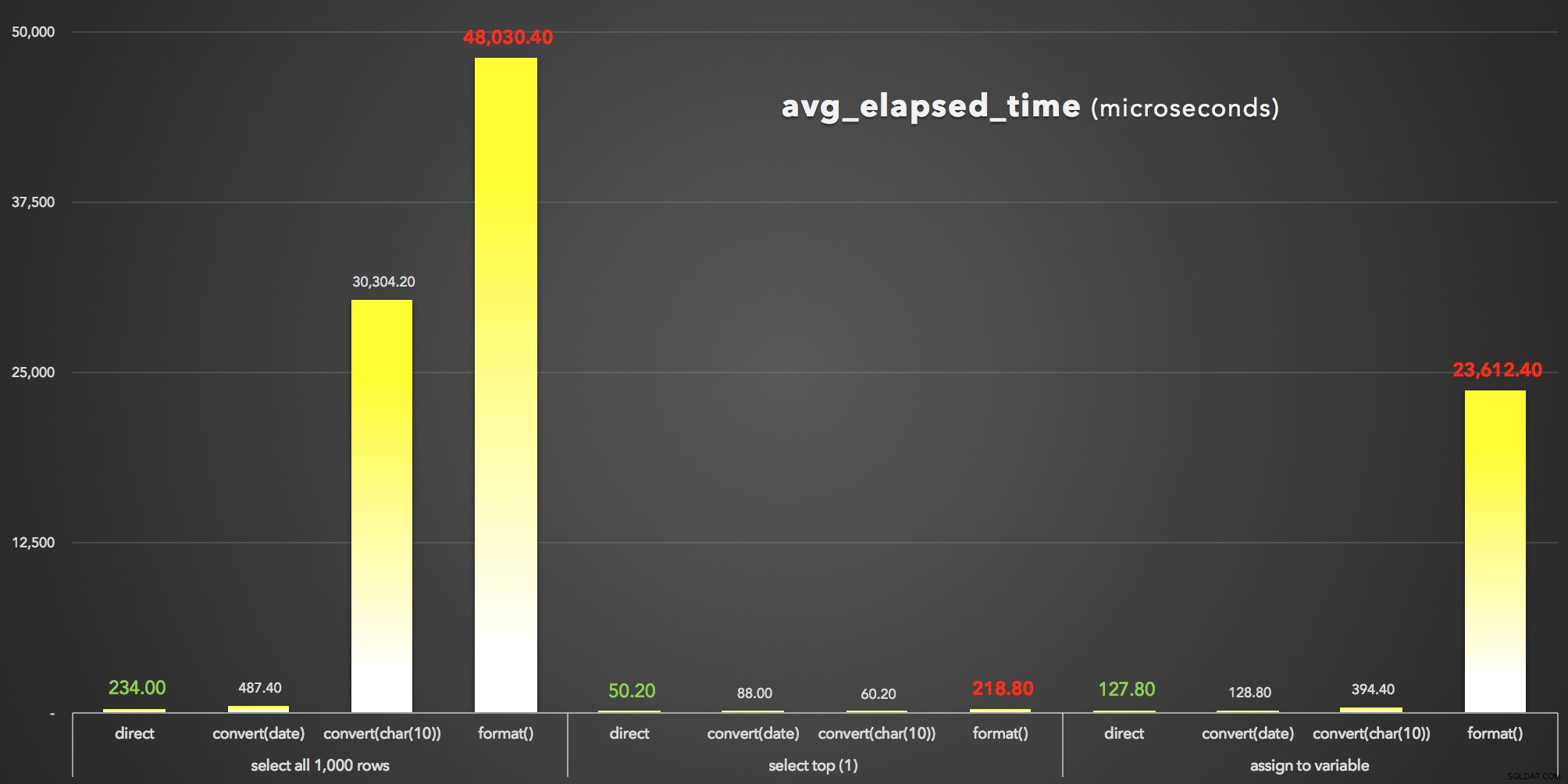 FORMAT() jednoznačně prohrává:výsledky avg_elapsed_time (mikrosekundy)
FORMAT() jednoznačně prohrává:výsledky avg_elapsed_time (mikrosekundy)
Co se můžeme z těchto výsledků (opět) naučit:
- V první řadě
FORMAT()je drahý . FORMAT()může samozřejmě poskytnout větší flexibilitu a poskytnout intuitivnější metody, které jsou konzistentní s těmi v jiných jazycích, jako je C#. Nicméně kromě jeho režie a zároveňCONVERT()čísla stylů jsou záhadná a méně vyčerpávající, možná budete muset stejně použít starší přístup, protožeFORMAT()je platný pouze pro SQL Server 2012 a novější.- Dokonce i v pohotovostním režimu
CONVERT()metoda může být drasticky drahá (i když jen silně v případě, kdy SSMS musel vykreslit výsledky - jasně zpracovává řetězce jinak než hodnoty data). - Pouze vytažení hodnoty datetime přímo z databáze bylo vždy nejefektivnější. Měli byste si vyprofilovat, kolik času navíc zabere vaší aplikaci na formátování data podle potřeby v prezentační vrstvě – je vysoce pravděpodobné, že nebudete chtít, aby se SQL Server vůbec zapojoval do zkrášlujícího formátu (a ve skutečnosti by mnozí argumentovali že sem ta logika vždy patří).
Mluvíme zde pouze o mikrosekundách, ale také mluvíme pouze o 1000 řádcích. Přizpůsobte to skutečným velikostem tabulky a dopad nesprávného přístupu k formátování může být zničující.
Pokud si chcete tento experiment vyzkoušet na svém vlastním počítači, nahrál jsem vzorový skript:FormatIsNiceAndAllBut.sql_.zip