Velká část produkčního T-SQL kódu je napsána s implicitním předpokladem, že základní data se během provádění nezmění. Jak jsme viděli v předchozím článku této série, je to nebezpečný předpoklad, protože data a položky indexu se pod námi mohou pohybovat, dokonce i během provádění jediného příkazu.
Pokud si je programátor T-SQL vědom druhů problémů se správností a integritou dat, které mohou nastat v důsledku souběžných úprav dat jinými procesy, nejčastěji nabízeným řešením je zabalit zranitelné příkazy do transakce. Není jasné, jak by se stejný druh uvažování použil na případ jednoho příkazu, který je již ve výchozím nastavení zabalen do transakce automatického potvrzení.
Ponecháme-li to na vteřinu stranou, myšlenka ochrany důležité oblasti kódu T-SQL pomocí transakce se zdá být založena na nepochopení ochrany, kterou nabízejí vlastnosti transakce ACID. Důležitým prvkem této zkratky pro tuto diskuzi je Isolace vlastnictví. Myšlenka je taková, že použití transakce automaticky poskytuje úplnou izolaci od účinků jiných souběžných aktivit.
Pravda je taková, že transakce pod SERIALIZABLE uveďte pouze stupeň izolace, která závisí na aktuálně účinné úrovni izolace transakce. Abychom pochopili, co to všechno znamená pro náš každodenní T Při kódování SQL se nejprve podrobně podíváme na úroveň serializovatelné izolace.
Serializovatelná izolace
Serializovatelný je nejizolovanější ze standardních úrovní izolace transakcí. Je také výchozí úroveň izolace specifikovaná standardem SQL, i když SQL Server (jako většina komerčních databázových systémů) se v tomto ohledu od standardu liší. Výchozí úroveň izolace na serveru SQL Server je potvrzena čtením, což je nižší úroveň izolace, kterou prozkoumáme později v sérii.
Definice serializovatelné úrovně izolace ve standardu SQL-92 obsahuje následující text (důraz):
Serializovatelné provádění je definováno jako provádění operací souběžného provádění transakcí SQL, které má stejný efekt jako některé sériové provádění stejných SQL transakcí. Sériové spuštění je takové, při kterém se každá transakce SQL provede do dokončení před zahájením další transakce SQL.
Zde je důležité rozlišovat mezi skutečně serializovanými provedení (kde každá transakce skutečně probíhá výhradně do dokončení před zahájením další) a serializovatelná izolace, kde se požaduje, aby transakce měly pouze stejné účinky jako kdyby byly provedeny sériově (v nějakém nespecifikovaném pořadí).
Jinými slovy, skutečný databázový systém se může fyzicky překrývat provádění serializovatelných transakcí v čase (čímž se zvyšuje souběžnost), pokud účinky těchto transakcí stále odpovídají nějakému možnému pořadí sériového provádění. Jinými slovy, serializovatelné transakce jsou potenciálně serializovatelné spíše než být ve skutečnosti serializován .
Logicky serializovatelné transakce
Ponechte na chvíli stranou všechny fyzické aspekty (jako je zamykání) a zamyslete se pouze nad logickým zpracováním dvou souběžných serializovatelných transakcí.
Uvažujme tabulku, která obsahuje velký počet řádků, z nichž pět splňuje nějaký zajímavý predikát dotazu. Serializovatelná transakce T1 začne počítat počet řádků v tabulce, které odpovídají tomuto predikátu. Nějaký čas po T1 začne, ale před potvrzením druhá serializovatelná transakce T2 začíná. Transakce T2 přidá do tabulky čtyři nové řádky, které také splňují predikát dotazu, a potvrdí. Níže uvedený diagram ukazuje časovou posloupnost událostí:

Otázkou je, kolik řádků by měl mít dotaz v serializovatelné transakci T1 počítat? Pamatujte, že zde uvažujeme čistě o logických požadavcích, takže nepřemýšlejte o tom, které zámky by mohly být použity a tak dále.
Obě transakce se časově fyzicky překrývají, což je v pořádku. Serializovatelná izolace pouze vyžaduje, aby výsledky těchto dvou transakcí odpovídaly nějakému možnému sériovému provedení. Existují jasně dvě možnosti pro logický sériový rozvrh transakcí T1 a T2 :
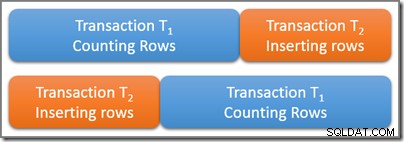
Pomocí prvního možného sériového plánu (T1 pak T2 ) T1 počítacím dotazem by bylo vidět pět řádků , protože druhá transakce nezačne, dokud se nedokončí ta první. Pomocí druhého možného logického plánu, T1 dotaz by napočítal devět řádků , protože čtyřřádková vložka byla logicky dokončena před zahájením transakce počítání.
Obě odpovědi jsou logicky správné pod serializovatelnou izolací. Navíc není možná žádná jiná odpověď (takže transakce T1 nemohl například napočítat sedm řádků). Který ze dvou možných výsledků bude skutečně pozorován, závisí na přesném načasování a řadě podrobností implementace specifických pro používaný databázový stroj.
Všimněte si, že nedocházíme k závěru, že transakce jsou ve skutečnosti nějak v čase přeřazeny. Fyzické provádění se může volně překrývat, jak je znázorněno na prvním diagramu, pokud databázový stroj zajistí, že výsledky odrážejí to, co by se stalo, kdyby byly provedeny v jedné ze dvou možných sériových sekvencí.
Serializovatelné a fenomény souběžnosti
Kromě logické serializace standard SQL také zmiňuje, že transakce fungující na úrovni serializovatelné izolace nesmí zaznamenat určité jevy souběžnosti. Nesmí číst nepotvrzená data (žádná špinavá čtení ); a jakmile jsou data přečtena, opakování stejné operace musí vrátit přesně stejnou sadu dat (opakovatelné čtení bez přízraků ).
Norma uvádí, že tyto jevy souběžnosti jsou vyloučeny na úrovni serializovatelné izolace jako přímý důsledek požadavku, aby transakce byla logicky serializovatelná. Jinými slovy, požadavek na serializaci je sám o sobě dostačující abyste se vyhnuli jevu špinavého čtení, neopakovatelného čtení a fantomové souběžnosti. Naproti tomu samotné vyhýbání se třem jevům souběžnosti nestačí abychom zaručili serializovatelnost, jak brzy uvidíme.
Intuitivně se serializovatelné transakce vyhýbají všem jevům souvisejícím se souběžností, protože se od nich vyžaduje, aby se chovaly, jako by byly provedeny v úplné izolaci. V tomto smyslu se serializovatelná úroveň izolace transakcí docela shoduje s běžnými očekáváními programátorů T-SQL.
Serializovatelné implementace
SQL Server náhodou používá zamykací implementaci úrovně serializovatelné izolace, kde jsou získávány a drženy fyzické zámky do konce transakce (proto zastaralá nápověda tabulky HOLDLOCK jako synonymum pro SERIALIZABLE ).
Tato strategie nestačí k poskytnutí technické záruky plné serializace, protože nová nebo změněná data se mohou objevit v řadě řádků dříve zpracovaných transakcí. Tento fenomén souběžnosti je známý jako fantom a může mít za následek efekty, které by nemohly nastat v žádném sériovém plánu.
Aby byla zajištěna ochrana proti fenoménu fantomové souběžnosti, mohou zámky přijaté SQL Serverem na úrovni serializovatelné izolace také obsahovat uzamykání rozsahu klíčů abyste zabránili zobrazení nových nebo změněných řádků mezi dříve zkoumanými hodnotami klíče indexu. Zámky rozsahu nejsou vždy získané na úrovni serializovatelné izolace; vše, co můžeme obecně říci, je, že SQL Server vždy získá dostatečné zámky, aby splnil logické požadavky na úroveň serializovatelné izolace. Ve skutečnosti implementace zamykání poměrně často získávají více a přísnějších zámků, než je skutečně potřeba k zajištění serializace, ale to odbočím.
Uzamčení je pouze jednou z možných fyzických implementací úrovně serializovatelné izolace. Měli bychom být opatrní, abychom mentálně oddělili specifické chování implementace zamykání serveru SQL od logické definice serializovatelného.
Jako příklad alternativní fyzické strategie viz implementace izolace serializovatelných snímků v PostgreSQL, i když je to jen jedna alternativa. Každá různá fyzická implementace má samozřejmě své silné a slabé stránky. Kromě toho poznamenejte, že Oracle stále neposkytuje plně vyhovující implementaci úrovně serializovatelné izolace. Má úroveň izolace pojmenovaný serializovatelný, ale skutečně nezaručuje, že transakce budou prováděny podle nějakého možného sériového plánu. Oracle místo toho poskytuje izolaci snímku když se požaduje serializovatelný snímek, podobně jako to dělal PostgreSQL před izolací serializovatelných snímků (SSI ) byl implementován.
Izolace snímků nezabrání anomáliím souběžnosti, jako je zkreslení zápisu, což není možné při skutečně serializovatelné izolaci. Pokud vás to zajímá, můžete na výše uvedeném odkazu SSI najít příklady zkreslení zápisu a dalších souběžných efektů, které umožňuje izolace snímků. Dále v této sérii probereme implementaci úrovně izolace snímků na serveru SQL Server.
Přehled k určitému okamžiku?
Jedním z důvodů, proč jsem strávil čas mluvením o rozdílech mezi logickou serializací a fyzicky serializovaným prováděním, je to, že je jinak snadné odvodit záruky, které by ve skutečnosti nemusely existovat. Pokud například serializovatelné transakce považujete za skutečně při provádění jedné po druhé můžete usuzovat, že serializovatelná transakce nezbytně uvidí databázi tak, jak existovala na začátku transakce, což poskytuje pohled k určitému okamžiku.
Ve skutečnosti se jedná o detail specifický pro implementaci. Připomeňme si předchozí příklad, kde serializovatelná transakce T1 může oprávněně počítat pět nebo devět řádků. Pokud je vrácen počet devět, první transakce jasně vidí řádky, které v okamžiku zahájení transakce neexistovaly. Tento výsledek je možný v SQL Server, ale ne v PostgreSQL SSI, ačkoli obě implementace splňují logické chování specifikované pro úroveň serializovatelné izolace.
Na serveru SQL Server nemusí serializovatelné transakce nutně vidět data tak, jak existovala na začátku transakce. Podrobnosti implementace SQL Server spíše znamenají, že serializovatelná transakce vidí nejnovější potvrzená data od okamžiku, kdy byla data poprvé uzamčena pro přístup. Navíc je zaručeno, že sada naposledy přečtených dat nezmění své členství před ukončením transakce.
Příště
Další část této série zkoumá úroveň izolace opakovatelného čtení, která poskytuje slabší záruky izolace transakcí než serializovatelná.
[ Viz rejstřík pro celou sérii ]