Typické dotazy ve formátu tabulky SELECT * FROM někdy nestačí. Když data pro dotaz nejsou v jedné tabulce, ale v několika, nebo když je potřeba zadat několik parametrů výběru najednou, budete potřebovat sofistikovanější dotazy.
Tento článek vysvětlí, jak sestavit takové dotazy, a poskytne příklady složitých SQL dotazů.
Jak vypadá složitý dotaz?
Nejprve si definujme podmínky pro sestavení SQL dotazu. Zejména budete muset použít následující parametry výběru:
- názvy tabulek, ze kterých chcete extrahovat data;
- hodnoty polí, které se musí po provedení změn v databázi vrátit na původní;
- vztahy mezi tabulkami;
- podmínky vzorkování;
- pomocná výběrová kritéria (omezení, způsoby prezentace informací, typ řazení).
Pro lepší pochopení tématu uvažujme příklad, který používá následující čtyři jednoduché tabulky. První řádek je název tabulky, která ve složitých dotazech funguje jako cizí klíč. Dále to podrobně zvážíme na příkladu:
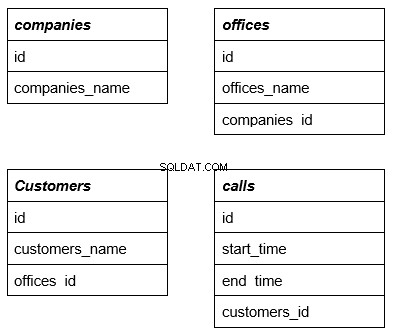
Každá tabulka má řádky související s jinými tabulkami. Proč je to nutné, vysvětlíme dále.
Nyní se podívejme na základní SQL dotaz:
SELECT * FROM companies WHERE companies_name %STARTSWITH 'P';%STARTSWITH predikát vybere řádky začínající zadaným znakem/znaky.
Výsledek vypadá takto:

Nyní se podívejme na složitý SQL dotaz:
SELECT
companies.companies_name,
SUM(CASE WHEN call.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
HAVING AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) > (SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls)
ORDER BY calls DESC, companies.id ASC;
Výsledkem je následující tabulka:

V tabulce jsou uvedeny společnosti, odpovídající počet telefonních hovorů a jejich přibližná délka
Dále uvádí pouze ty názvy společností, kde je průměrná délka hovoru delší než průměrná délka hovoru v jiných společnostech.
Jaká jsou hlavní pravidla pro vytváření komplexních SQL dotazů?
Zkusme vytvořit víceúčelový algoritmus pro skládání složitých dotazů.
Nejprve se musíte rozhodnout pro tabulky obsahující data, která se účastní dotazu.
Výše uvedený příklad zahrnuje společnosti a hovory tabulky. Pokud tabulky s požadovanými údaji spolu přímo nesouvisí, musíte také zahrnout přechodné tabulky, které je spojují.
Z tohoto důvodu propojujeme i stoly, jako jsou kanceláře a zákazníci , pomocí cizích klíčů. Proto jakýkoli výsledek dotazu s tabulkami z tohoto příkladu bude vždy obsahovat následující řádky:
SELECT
...
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
...;
After that, you must test the correctness of the behavior in the following part of the query:
SELECT * FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id;
Kombinovaná tabulka naznačuje tři nejdůležitější body:
- Věnujte pozornost seznamu polí po SELECT. Operace čtení dat ze spojených tabulek vyžaduje, abyste v name uvedli název tabulky, která se má spojit. pole.
- Váš komplexní dotaz bude mít vždy hlavní tabulku (společnosti ). Většina polí se z něj čte. Přiložená tabulka v našem příkladu používá tři tabulky – kanceláře , zákazníci a hovory . Název je určen podle operátoru JOIN.
- Kromě zadání názvu druhé tabulky nezapomeňte zadat podmínku pro provedení spojení. Tuto podmínku probereme dále.
- Dotaz zobrazí tabulku s velkým počtem řádků. Není třeba jej zde zveřejňovat, protože zobrazuje mezivýsledky. Jeho výstup si však můžete vždy sami zkontrolovat. To je velmi důležité, protože to pomáhá vyhnout se chybám v konečném výsledku.
Nyní se podívejme na část dotazu, která porovnává trvání hovorů v každé společnosti a mezi všemi společnostmi. Musíme vypočítat průměrnou dobu trvání všech hovorů. Použijte následující dotaz:
SELECT AVG(DATEDIFF(SECOND, calls.start_time, calls.end_time)) FROM calls
Všimněte si, že jsme použili DATEDIFF funkce, která zobrazuje rozdíl mezi zadanými obdobími. V našem případě je průměrná délka hovoru 335 sekund.
Nyní do dotazu přidejte data o hovorech od všech společností.
SELECT
companies.companies_name,
SUM(CASE WHEN calls.id IS NOT NULL THEN 1 ELSE 0 END) AS calls,
AVG(ISNULL(DATEDIFF(SECOND, calls.start_time, calls.end_time),0)) AS avgdifference
FROM companies
LEFT JOIN offices ON offices.companies_id = companies.id
LEFT JOIN customers ON offices.id = customers.offices_id
LEFT JOIN calls ON calls.customers_id = customers.id
GROUP BY
companies.id,
companies.companies_name
ORDER BY calls DESC, companies.id ASC;
V tomto dotazu
- SUM (PŘÍPAD, KDYŽ calls.id NENÍ NULL TAK 1 ELSE 0 END) – abychom předešli zbytečným operacím, shrnujeme pouze existující hovory – když počet hovorů ve firmě není nulový. To je velmi důležité ve velkých tabulkách s možnými hodnotami null.
- AVG (ISNULL (DATEDIFF (SECOND, calls.start_time, calls.end_time), 0)) – dotaz je shodný s dotazem AVG výše. Zde však používáme ISNULL operátora, který nahrazuje NULL 0. Je to nutné pro společnosti, které vůbec nevolají.
Naše výsledky:
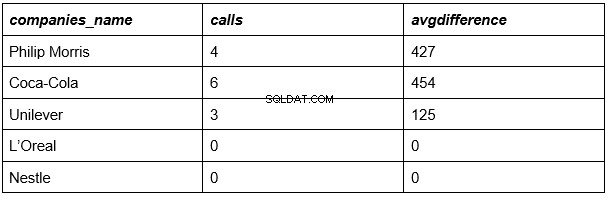
Už jsme skoro hotovi. Výše uvedená tabulka uvádí seznam společností, odpovídající počet hovorů pro každou z nich a průměrnou dobu trvání hovorů v každé z nich.
Nezbývá než porovnat čísla z posledního sloupce s průměrnou délkou všech hovorů od všech společností (335 sekund).
Pokud zadáte dotaz, který jsme uvedli na začátku, stačí přidat HAVING část, dostanete, co potřebujete.
Důrazně doporučujeme přidat komentáře na každý řádek, abyste v budoucnu nebyli zmateni, když budete potřebovat opravit některé stávající složité SQL dotazy.
Poslední myšlenky
Ačkoli každý složitý SQL dotaz vyžaduje individuální přístup, některá doporučení jsou vhodná pro přípravu většiny takových dotazů.
- určit, které tabulky se budou dotazu účastnit;
- vytvářet složité dotazy z jednodušších částí;
- kontrolovat přesnost dotazů postupně, po částech;
- otestujte přesnost svého dotazu pomocí menších tabulek;
- na každý řádek obsahující operand napište podrobné komentáře pomocí symbolů „-“.
Díky speciálním nástrojům je tato práce mnohem jednodušší. Mezi nimi bychom doporučili použít Query Builder – vizuální nástroj, který umožňuje vytvářet i ty nejsložitější dotazy mnohem rychleji ve vizuálním režimu. Tento nástroj je k dispozici jako samostatné řešení nebo jako součást víceúčelového dbForge Studio pro SQL Server.
Doufáme, že vám tento článek pomohl objasnit tento konkrétní problém.